无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。
前言
首先来看一下flume官网中对Event的定义
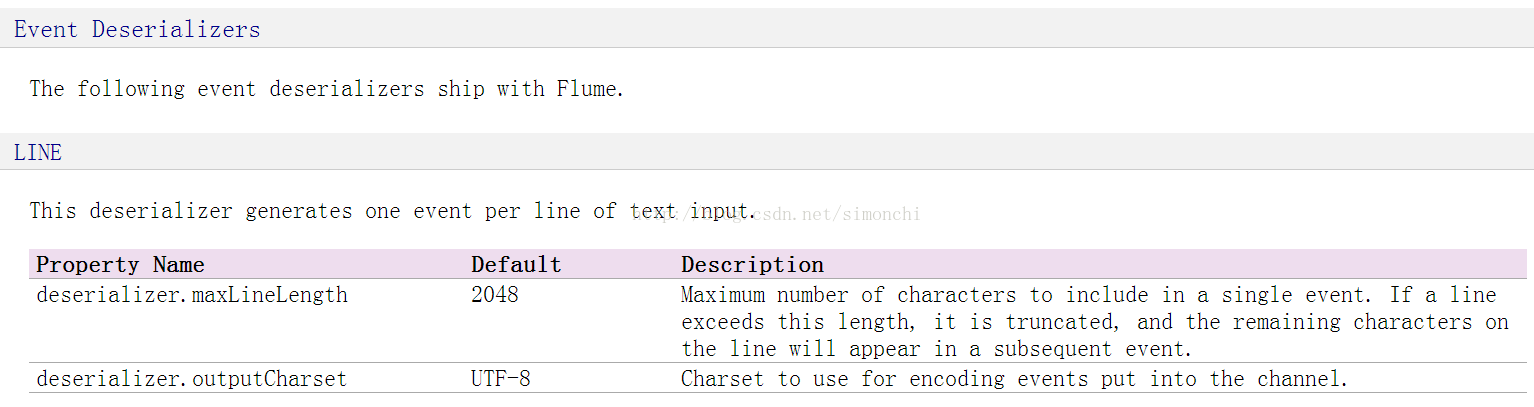
一行文本内容会被反序列化成一个event【序列化是将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据】,event的最大定义为2048字节,超过,则会切割,剩下的会被放到下一个event中,默认编码是UTF-8,这都是统一的。
但是这个解释是针对Avro反序列化系统中的Event的定义,而flume ng中很多event用的不是这个,所以你只要记住event的数据结构即可,上面这个解释可以忽略。
一、Event定义
public interface Event {
/**
* Returns a map of name-value pairs describing the data stored in the body.
*/
public Map<String, String> getHeaders();
/**
* Set the event headers
* @param headers Map of headers to replace the current headers.
*/
public void setHeaders(Map<String, String> headers);
/**
* Returns the raw byte array of the data contained in this event.
*/
public byte[] getBody();
/**
* Sets the raw byte array of the data contained in this event.
* @param body The data.
*/
public void setBody(byte[] body);
}很简单的数据结构
header是一个map,body是一个字节数组,body才是我们实际使用中真正传输的数据,header传输的数据,我们是不会是sink出去的。
二、Event如何产出以及如何分流
while ((line = reader.readLine()) != null) {
synchronized (eventList) {
sourceCounter.incrementEventReceivedCount();
eventList.add(EventBuilder.withBody(line.getBytes(charset)));
if(eventList.size() >= bufferCount || timeout()) {
flushEventBatch(eventList);
}
}
}
public static Event withBody(byte[] body, Map<String, String> headers) {
Event event = new SimpleEvent();
if(body == null) {
body = new byte[0];
}
event.setBody(body);
if (headers != null) {
event.setHeaders(new HashMap<String, String>(headers));
}
return event;
}
这里是单纯的包装了event的body内容,line即是我们真正的数据内容,将其转换成UTF-8编码的字节内容分装到event的body中,它的header是null。
用的是SimpleEvent类。
header的话,就是在分装Event对象的时候,我们可以自定义的设置一些key-value对,这样做的目的,是为了后续的通道多路复用做准备的
在source端产出event的时候,通过header去区别对待不同的event,然后在sink端的时候,我们就可以通过header中的key来将不同的event输出到对应的sink下游去,这样就将event分流出去了,但是这里有一个前提:不建议通过对event的body解析来设置header,因为flume就是一个水槽,水槽是不会在中间对水进行加工的,要加工,等水流出去了再加工
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = host
a1.sources.r1.interceptors.i1.hostHeader = hostname如上,host是你自定义的一个拦截器,hostHeader都是自定义的key,这样你就在event产出的时候,给各个event定义了不同的header,然后再通过多路复用通道的模式进行分流
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4这样你就可以根据event的header中的key将其放入不同的channel中,紧接着,再通过配置多个sink去不同的channel取出event,将其分流到不同的输出端
每个sink配置的通道区别开就行了。
最后
以上就是落后豆芽最近收集整理的关于【Flume】【源码分析】flume中事件Event的数据结构分析以及Event分流的全部内容,更多相关【Flume】【源码分析】flume中事件Event内容请搜索靠谱客的其他文章。








发表评论 取消回复