1 ByteBuf
netty中的ByteBuf主要是为了替换JDK自带的 ByteBuffer。 ByteBuffer有如下缺点:
- ByteBuffer 长度固定,一旦分配完成不能动态扩容缩容。
- ByteBuffer 只有一个标识位置的指针position,读写的时候需要手动调用flip()和rewind()等。开发者必须小心地使用这些API,否则很容易出现程序处理失败
- ByteBuffer 功能有限,一些高级特性不支持,需要开发者自己实现
1.1 工作原理
ByteBuf维护了读指针(readerIndex) 和写指针(writerIndex) 来维护读读写标识位。readerIndex 和 writerIndex 初始值都是0,随着数据的写入,writerIndex 会增加。读数据会使 readerIndex增加。读取数据后,0~readerIndex 这部分数据被视为 discard 的,调用 discardReadBytes 方法可以释放这部分空间。readerIndex 和 writerIndex之间的数据是可读的,writerIndex 和 capacity 之间的数据是可写的。通过读写指针的设计避免了频繁的调用 flip(),简化了缓冲区的读写操作。
- 初始化后的ByteBuf

- 写入N个字节后的 ByteBuf
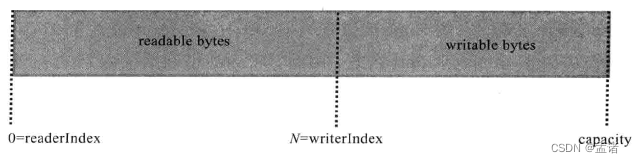
- 读取M个字节后的 ByteBuf
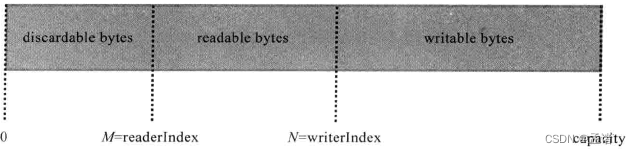
- 调用 discardReadBytes 后的ByteBuf

- 调用 clear 后的 ByteBuf

1.2 ByteBuf功能介绍
1.2.1 顺序读操作
| 方法名称 | 返回值 | 方法说明 |
|---|---|---|
| readBoolean | boolean | 从 readIndex 开始获取 boolean 值,readIndex + 1 |
| readByte/readUnsignedByte | byte | 从 readIndex 开始获取字节值/无符号字节值,readIndex + 1 |
| readShort/readUnsignedShort | short | 从 readIndex 开始获取短整型值/无符号短整型值,readIndex + 2 |
| readInt/readUnsignedInt | int | 从 readIndex 开始获取整型值/无符号整型值,readIndex + 4 |
| readLong | long | 从 readIndex 开始获取长整型值,readIndex + 8 |
| readChar | char | 从 readIndex 开始获取字符值,readIndex + 2 |
| readFloat | float | 从 readIndex 开始获取浮点值,readIndex + 4 |
| readDouble | double | 从 readIndex 开始获取双精度浮点值,readIndex + 8 |
| readBytes(int length) | ByteBuf | 从 readIndex 开始读取 length长度到一个新的 ByteBuf 中 |
| readSlice(int length) | ByteBuf | 从 readIndex 开始读取 length长度到一个新的 ByteBuf 中,子区域与原区域共享缓冲区,但是维护自己的 readIndex 和 writeIndex |
| readBytes(byte[] dest) | ByteBuf | 从 readIndex 开始读取数据到目标byte数组中,读取字节数长度dest.length |
1.2.2 顺序写操作
| 方法名称 | 返回值 | 方法说明 |
|---|---|---|
| writeBoolean(boolean value) | ByteBuf | 将value写入到 ByteBuf 中,writerIndex + 1 |
| writeByte(byte value) | ByteBuf | ByteBuf |
| readShort(short value) | ByteBuf | 将 value 写入到 ByteBuf 中,writerIndex + 2 |
| writeInt(int value) | ByteBuf | 将 value 写入到 ByteBuf 中,writerIndex + 4 |
| writeLong(long value) | ByteBuf | 将 value 写入到 ByteBuf 中,writerIndex + 8 |
| writeChar(char value) | ByteBuf | 将 value 写入到 ByteBuf 中,writerIndex + 2 |
| writeFloat(float value) | ByteBuf | 将 value 写入到 ByteBuf 中,writerIndex + 4 |
| writeDouble(double value) | ByteBuf | 将 value 写入到 ByteBuf 中,writerIndex + 8 |
| writeBytes(ByteBuf src) | ByteBuf | 将 src 中所有可读字节写入到当前 ByteBuf writerIndex + src.readableBytes |
| writeBytes(byte[] src) | ByteBuf | 将 src 中字节写入到当前 ByteBuf writerIndex + src.length |
1.2.3 mark 和 reset
mark 操作会将当前指针备份到 positionIndex 中,reset 会将指针恢复到备份值。ByteBuf 中主要有四个相关的方法:markReaderIndex、markWriterIndex、resetReaderIndex、resetWriterIndex
1.2.4 随机读写
除了顺序读写外,ByteBuf还支持随机读写(getXXX、setXXX),可以任意指定读写位置。随机读写同样会校验索引、长度合法性,但是不会修改 readerIndex 和 writerIndex 的值
1.3 ByteBuf分类
从内存分配来看,ByteBuf可以分为两类
- 堆内存字节缓冲区:优点是内存分配和回收速度快,可以被 JVM 自动回收。缺点是如果进行 IO 操作需要额外做一次内存复制,将堆内存对应的缓冲区复制到内核 channel 中,性能会有一定程度的下降
- 直接内存字节缓冲区:利用堆外内存分配空间,优点是 IO 操作的时候少了一次内存复制。缺点是分配和回收速度会慢一些。
实践表明 IO 通信线程中使用直接内存缓冲区,后端业务消息编解码模块儿使用堆内存字节缓冲区,这样组合可以达到性能最优
从内存回收角度,ByteBuf 也可以分为两类
- 基于对象池的 ByteBuf:优点是维护了一个内存池,可以循环利用创建的 ByteBuf,提升内存使用效率。缺点是内存池管理比较复杂
- 普通 ByteBuf:优点是使用比较简单。缺点是不能循环利用
2 ChannelPipeline
2.1 概述
ChannelPipeline 是 ChannelHandler 的容器,它负责 ChannelHandler 的管理和事件拦截。用户不用自己创建,ServerBootStrap 或 BootStrap 启动的时候会为每个 Channel创建一个独立的 pipeline,使用者只需要将自定义拦截器添加到pipeline中即可
serverBootstrap.group(bossGroup, workGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
List<ChannelHandler> handlers = supplier.get();
for (ChannelHandler handler: handlers) {
socketChannel.pipeline().addLast(handler);
}
}
});
ChannelPipeline 是线程安全的,N 个业务线可以并发操作而不会出现线程安全问题。但是 ChannelHandler 不是线程安全的,需要用户自己保证
2.1 事件处理流程
- 底层 SocketChannel read 方法读取 ByteBuf,触发 channelRead 事件,由 IO 线程 NioEventLoop 调用 ChannelPipeline 的 fireChannelRead 方法,将消息传到 ChannelPipeline 中。
- 消息依次经过 HeadHandler、ChannelHandler1、ChannelHandler2……TailHandler 处理。任何一个处理有异常都会导致消息中断
- 调用 ChannelHandlerContext write 方法发送消息,从 TailHandler 开始到 HeadHandler 最终被添加到消息缓冲区等待消息发送
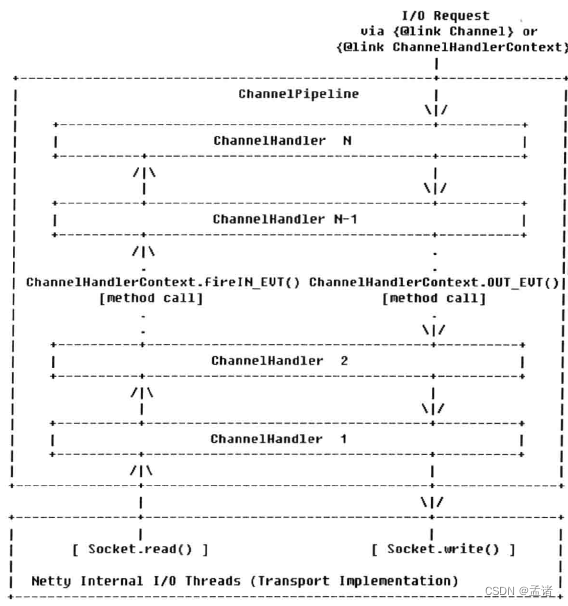
3 ChannelHandler
ChannelHandler 类似于 Servlet 中的 Filter 过滤器,负责对 IO 事件或者 IO 操作进行拦截处理。可以选择自己关注的事件进行处理,也可以透传和终止事件传递。常用的编解码器都是一个个 ChannelHandler
3.1 ByteToMessageDecoder
将 ByteBuf 解码成 POJO 对象,核心代码如下
3.1.1 channelRead入口
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
// 只解析 ByteBuf 数据
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
// 如果 cumulation 为空则说明是第一个消息或者上个消息已经解码完毕
cumulation = data;
} else {
// 如果 cumulation 不为空则表示上个消息没有解析完全,将新收到的消息拼接到后面
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
// 解码
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
// 如果消息已经读取完毕则释放
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
// 如果消息没有读取完成且读取次数超过阈值(默认16)则释放已经度过的数据,避免 OOM
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
ctx.fireChannelRead(msg);
}
}
3.1.2 callDecode解码
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
// 循环读取,直到消息读取完毕
while (in.isReadable()) {
int outSize = out.size();
if (outSize > 0) {
// 将解析后的消息向后传
fireChannelRead(ctx, out, outSize);
out.clear();
// Check if this handler was removed before continuing with decoding.
// If it was removed, it is not safe to continue to operate on the buffer.
//
// See:
// - https://github.com/netty/netty/issues/4635
if (ctx.isRemoved()) {
break;
}
outSize = 0;
}
// 记录旧的读指针,用于后面判断是否继续解析
int oldInputLength = in.readableBytes();
// 调用 decode 方法,由不同的子类来实现
decodeRemovalReentryProtection(ctx, in, out);
// Check if this handler was removed before continuing the loop.
// If it was removed, it is not safe to continue to operate on the buffer.
//
// See https://github.com/netty/netty/issues/1664
if (ctx.isRemoved()) {
break;
}
if (outSize == out.size()) {
// 如果 outSize 大小没有变化则根据不同的情况判断是否继续解析
if (oldInputLength == in.readableBytes()) {
// 经过解码后如果读指针仍未发生变化则直接 break,中断解析
break;
} else {
// 经过解码后如果读指针发生变化则仍需要解析
continue;
}
}
if (oldInputLength == in.readableBytes()) {
throw new DecoderException(
StringUtil.simpleClassName(getClass()) +
".decode() did not read anything but decoded a message.");
}
if (isSingleDecode()) {
break;
}
}
} catch (DecoderException e) {
throw e;
} catch (Exception cause) {
throw new DecoderException(cause);
}
}
3.2 LengthFieldBaseFreamDecoder
3.2.1 核心参数简介
LengthFieldBaseFreamDecoder参数比较多,核心参数如下
- maxFrameLength:最大消息长度
- lengthFieldOffset:表示长度信息的数据偏移量
- lengthFieldLength:表示长度信息的数据长度
- lengthAdjustment:长度调整值。计算公式:lengthAdjustment = [整个消息长度(包含长度位) - 长度位表示长度] - 长度位长度 - 长度位偏移量
通常情况下,长度位表示长度不包含长度位长度,这个时候 整个消息长度(包含长度位) - 长度位表示长度 = 长度位长度,如果长度位偏移量为0,则 lengthAdjustment = 0。该公式可以进一步简化:
- 长度位表示长度不包含长度位长度:- 长度位偏移量
- 长度位表示长度包含长度位长度:- 长度位长度 - 长度位偏移量
- initialBytesToStrip:接收到的发送数据包,去除前initialBytesToStrip位
3.2.2 decode 代码
LengthFieldBaseFreamDecoder 继承了 ByteToMessageDecoder,这里看下 decode 逻辑即可
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
if (discardingTooLongFrame) {
discardingTooLongFrame(in);
}
if (in.readableBytes() < lengthFieldEndOffset) {
// 如果可读字节量 < 长度字节截止位置则直接返回
return null;
}
// 根据长度偏移量计算实际长度偏移量
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
// 获取消息长度值
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
if (frameLength < 0) {
failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset);
}
// 长度值调整
frameLength += lengthAdjustment + lengthFieldEndOffset;
if (frameLength < lengthFieldEndOffset) {
failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset);
}
if (frameLength > maxFrameLength) {
exceededFrameLength(in, frameLength);
return null;
}
// never overflows because it's less than maxFrameLength
int frameLengthInt = (int) frameLength;
if (in.readableBytes() < frameLengthInt) {
return null;
}
if (initialBytesToStrip > frameLengthInt) {
failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip);
}
// 跳过一些字节不解析
in.skipBytes(initialBytesToStrip);
// 解析字节片段
int readerIndex = in.readerIndex();
int actualFrameLength = frameLengthInt - initialBytesToStrip;
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}
3.3 MessageToMessageDecoder
将一个 POJO 转换为另一个POJO
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
CodecOutputList out = CodecOutputList.newInstance();
try {
if (acceptInboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
// 解码
decode(ctx, cast, out);
} finally {
ReferenceCountUtil.release(cast);
}
} else {
out.add(msg);
}
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
// 将解码后的对象传到后面的 Handler
int size = out.size();
for (int i = 0; i < size; i ++) {
ctx.fireChannelRead(out.getUnsafe(i));
}
out.recycle();
}
}
MessageToMessageDecoder 逻辑比较简单,但是要注意拆包、粘包的问题,进入该解码器的消息一定要是整包消息
3.4 MessageToByteEncoder
把 POJO 对象转换为 ByteBuf 以便进行网络传输。
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
// 分配一个字节缓冲区
buf = allocateBuffer(ctx, cast, preferDirect);
try {
// 把对象进行编码
encode(ctx, cast, buf);
} finally {
ReferenceCountUtil.release(cast);
}
if (buf.isReadable()) {
// 写入字节缓冲区
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
if (buf != null) {
buf.release();
}
}
}
3.5 MessageToMessageEncoder
将一个编码对象转换为另一个编码对象
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
CodecOutputList out = null;
try {
if (acceptOutboundMessage(msg)) {
out = CodecOutputList.newInstance();
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
// 把对象进行编码
encode(ctx, cast, out);
} finally {
ReferenceCountUtil.release(cast);
}
if (out.isEmpty()) {
out.recycle();
out = null;
throw new EncoderException(
StringUtil.simpleClassName(this) + " must produce at least one message.");
}
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable t) {
throw new EncoderException(t);
} finally {
if (out != null) {
// 将 list 循环写出,交给后面的handler处理
final int sizeMinusOne = out.size() - 1;
if (sizeMinusOne == 0) {
ctx.write(out.getUnsafe(0), promise);
} else if (sizeMinusOne > 0) {
if (promise == ctx.voidPromise()) {
writeVoidPromise(ctx, out);
} else {
writePromiseCombiner(ctx, out, promise);
}
}
out.recycle();
}
}
}
3.6 LengthFieldPrepender
LengthFieldPrepender 解码器用于在消息前面添加一个长度字节。该解码器继承了MessageToMessageEncoder,流到该编码器的消息一定要是整包消息
@Override
protected void encode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception {
// 计算消息长度
int length = msg.readableBytes() + lengthAdjustment;
if (lengthIncludesLengthFieldLength) {
// 如果长度包括长度字段的长度则增加长度字段的长度
length += lengthFieldLength;
}
checkPositiveOrZero(length, "length");
// 写入长度信息
switch (lengthFieldLength) {
case 1:
if (length >= 256) {
throw new IllegalArgumentException(
"length does not fit into a byte: " + length);
}
out.add(ctx.alloc().buffer(1).order(byteOrder).writeByte((byte) length));
break;
case 2:
if (length >= 65536) {
throw new IllegalArgumentException(
"length does not fit into a short integer: " + length);
}
out.add(ctx.alloc().buffer(2).order(byteOrder).writeShort((short) length));
break;
case 3:
if (length >= 16777216) {
throw new IllegalArgumentException(
"length does not fit into a medium integer: " + length);
}
out.add(ctx.alloc().buffer(3).order(byteOrder).writeMedium(length));
break;
case 4:
out.add(ctx.alloc().buffer(4).order(byteOrder).writeInt(length));
break;
case 8:
out.add(ctx.alloc().buffer(8).order(byteOrder).writeLong(length));
break;
default:
throw new Error("should not reach here");
}
// 添加消息
out.add(msg.retain());
}
最后
以上就是爱撒娇烧鹅最近收集整理的关于Netty学习二-核心类简介1 ByteBuf2 ChannelPipeline3 ChannelHandler的全部内容,更多相关Netty学习二-核心类简介1内容请搜索靠谱客的其他文章。








发表评论 取消回复