目录
1 时序逻辑与组合逻辑的区别
2 建立与保持时间
3 亚稳态
4 信号跨时钟域处理CDC
5 状态机种类区别
6 锁存器Latch和触发器DFF区别
7 竞争与冒险
8 同步复位 异步复位
1 时序逻辑与组合逻辑的区别
组合逻辑的特点是任意时刻的输出仅仅取决于该时刻的输入,与电路原本的状态无关,逻辑中不牵涉跳变沿信号的处理,组合逻辑的verilog描述方式有两种:
(1):always @(电平敏感信号列表)
always模块的敏感列表为所有判断条件信号和输入信号,但一定要注意敏感列表的完整性。在always 模块中可以使用if、case 和for 等各种RTL 关键字结构。由于赋值语句有阻塞赋值和非阻塞赋值两类,建议读者使用阻塞赋值语句“=”。always 模块中的信号必须定义为reg 型,不过最终的实现结果中并没有寄存器。这是由于在组合逻辑电路描述中,将信号定义为reg型,只是为了满足语法要求。
(2):assign描述的赋值语句。
信号只能被定义为wire型。
时序逻辑是Verilog HDL 设计中另一类重要应用,其特点为任意时刻的输出不仅取决于该时刻的输入,而且还和电路原来的状态有关。电路里面有存储元件(各类触发器,在FPGA 芯片结构中只有D 触发器)用于记忆信息,从电路行为上讲,不管输入如何变化,仅当时钟的沿(上升沿或下降沿)到达时,才有可能使输出发生变化。
与组合逻辑不同的是:
(1)在描述时序电路的always块中的reg型信号都会被综合成寄存器,这是和组合逻辑电路所不同的。
(2)时序逻辑中推荐使用非阻塞赋值“<=”。
(3)时序逻辑的敏感信号列表只需要加入所用的时钟触发沿即可,其余所有的输入和条件判断信号都不用加入,这是因为时序逻辑是通过时钟信号的跳变沿来控制的。
2 建立与保持时间
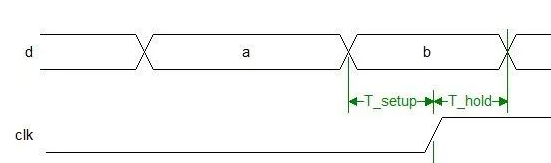
建立时间(Tsu:set up time)
是指在触发器的时钟信号上升沿到来以前,数据稳定不变的时间,如果建立时间不够,数据将不能在这个时钟上升沿被稳定的打入触发器,Tsu就是指这个最小的稳定时间。
保持时间(Th:hold time)
是指在触发器的时钟信号上升沿到来以后,数据稳定不变的时间,如果保持时间不够,数据同样不能被稳定的打入触发器,Th就是指这个最小的保持时间。
3 亚稳态
亚稳态是指触发器无法在某个规定时间段内达到一个可确认的状态。当一个触发器进入亚稳态时,既无法预测该单元的输出电平,也无法预测何时输出才能稳定在某个 正确的电平上。在这个稳定期间,触发器输出一些中间级电平,或者可能处于振荡状态,并且这种无用的输出电平可以沿信号通道上的各个触发器级联式传播下去。
亚稳态产生概率:
概率 = (建立时间 + 保持时间)/ 采集时钟周期
可以看出,亚稳态出现的概率与工作时钟频率以及触发器自身的特性(器件的工艺等因素决定了它的建立/保持时间)有关;所以在异步信号采集过程中,要想减少亚稳态发生的概率可以:
1、降低系统工作时钟,增大系统周期,亚稳态概率就会减小(降低工作频率,不常用);
2、 采用工艺更好的FPGA,也就是Tsu和Th时间较小的FPGA器件;
解决
降低系统时钟(不常见,因为高速率正确处理才是目的)
用反应更快的触发器(工艺相关,受硬件制约)
引入同步机制,防止亚稳态传播(常见的处理方式,即通过一些机制,在现有硬件条件下,最大程度的减少亚稳态发生)
改善时钟质量,用边沿变化快速的时钟信号
同步器(用于控制信号和单比特信号的亚稳态处理)
可以通过在目标域中添加同步器来避免亚稳态问题。同步器允许振荡在足够的时间稳定下来,并确保在目标时钟域获得稳定的输出。一个常用的同步器是一个级联触发器,如下图所示。
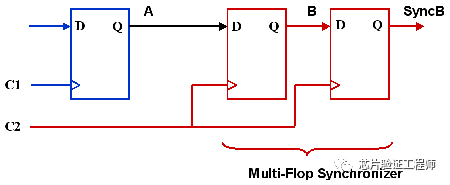
该结构主要用于设计中的控制信号和单比特数据信号。多位的数据信号需要其他类型的同步方案,如MUX recirculation、握手和FIFO。
B.数据丢失
每当生成一个新的源数据时,由于亚稳态性,它可能不会在目标时钟的第一个周期中被目标域捕获。只要源信号上的每个翻转都在目标域中被捕获,数据就不会丢失。为了确保这一点,源数据应在一段最短的时间内保持稳定,以便满足对目标时钟的至少一个边沿的setup 和hold 时间的要求。
如果C1和C2的时钟边沿非常靠近,则在源数据A翻转之后的C2的第一个时钟边沿无法捕获它。该数据最终被时钟C2的第二个时钟边沿捕获,如下图所示。
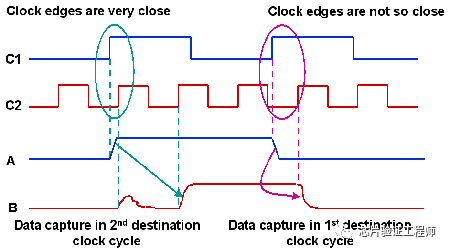
但是,如果在数据A翻转和时钟C2的边沿之间有足够的时间,则在C2的第一个周期捕获数据。因此,源时钟域数据和目标时钟域数据之间可能不会一一对应。无论如何,一般情况下源数据上的每个翻转都应该在目标时钟域中被捕获。
假设源时钟C1的速度是目标时钟C2的两倍,并且这两个时钟之间没有相位差。进一步假设在时钟C1的正边沿生成的输入数据序列“A”为“00110011”。在时钟C2的正边沿捕获的数据B将为“0101”。在这里,由于信号A上的所有翻转都被B捕获了,所以数据不会丢失。
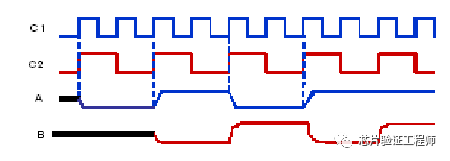
但是,如果输入序列为“00101111”,则目标域中的输出将为“0011”。这里输入序列中的第三个数据值“1”丢失。
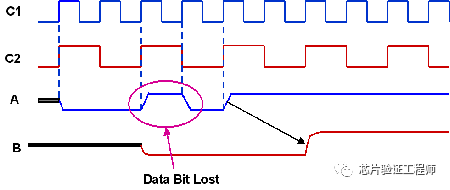
为了防止数据丢失,数据应该在源时钟域中保持足够长的时间不变,以便在目标时钟域中正确捕获。换句话说,在源数据上的每次转换之后,至少有一个目标时钟边沿应该到达没有违反setup或hold的地方,以便在目标时钟域中正确地捕获源数据。
C. 数据一致性(控制总线格雷编码)
如前一节所示,每当在源时钟域中生成新数据时,可能需要1个或多个目标时钟周期来捕获它。考虑这样一种情况,即多个信号从一个时钟域传输到另一个时钟域,并且每个信号使用多级触发器同步器分别进行同步。如果所有信号同时发生变化,并且源时钟和目标时钟边沿接近,那么一些信号可能在第一个时钟周期中在目标域中被捕获,而另一些信号可能通过亚稳态在第二个时钟周期中被捕获。这可能会导致目标端信号上的值组合无效。也就是说,在这种情况下,数据的一致性已经丢失了。
如果这些信号一起控制着设计的某些功能,那么这种无效的状态可能会导致功能错误。
例如:假设“00”和“11”是由时钟C1生成的信号X[0:1]的两个有效值。最初在X的两个位上都有一个从1->0的过渡。这两个转变在第一个周期本身都被时钟C2捕获。因此,信号Y变成了“00”。
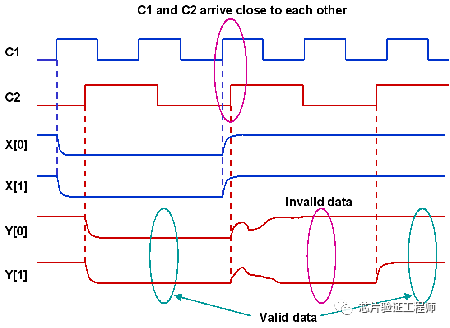
接下来,在信号X的两个比特位上都有一个从0->1的转换。在这里,时钟C2的上升沿接近于信号X的翻转。X[0]上的翻转在第一个时钟周期中被捕获,而X[1]上的翻转在C2的第二个时钟周期中被捕获。这将导致Y[0:1]上的一个中间值为“10”,这是一个无效的状态。在这种情况下,数据的一致性丢失了。
在上面的示例中,问题的原因是所有比特没有在相同的目标时钟周期中捕获。如果所有比特在同一周期中保留其原始值或更新值,则设计要么保持原始状态,要么进入正确的新状态(参考异步FIFO)。
如果电路的设计方式是,在将设计从一种状态更改到另一种状态时,只需要更改一个位,那么该位将更改为一个新值或者保留原始值。由于所有其他位在这两种状态下都有相同的值,所以在这种情况下,完整的总线要么变为新值,要么保留原始值。
这反过来又意味着,如果总线是格雷编码的,那么这个问题将会得到解决,并且将永远不会得到一个无效的状态。
但是,这仅适用于控制总线,因为无法对数据总线进行格雷编码。在这种情况下,可以使用握手、FIFO和MUX recirculation(如下图)等其他技术来生成一个公共的控制逻辑来正确地传输数据。
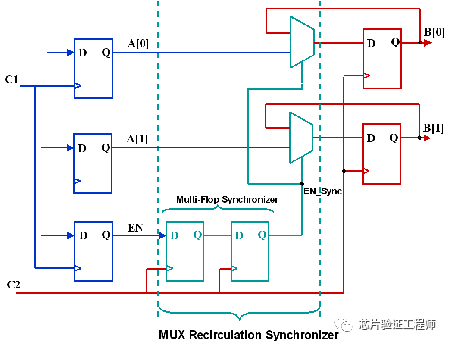
这里,在源时钟域中产生的控制信号EN使用多级触发器同步器在目标域中进行同步。同步控制信号EN_Sync驱动mux的选择引脚,从而控制总线A所有位的数据传输。通过这种方式,总线的各个位不会单独同步,因此不存在数据不一致性。但是,重要的是要确保当控制信号被激活时,源域数据A[0:1]应保持不变。
4 信号跨时钟域处理CDC
5 状态机种类区别
Moore 状态机的输出仅与当前状态值有关, 且只在时钟边沿到来时才会有状态变化。
Mealy 状态机的输出不仅与当前状态值有关, 而且与当前输入值有关
体现在状态转移图上就是,moore机的输出在状态圆圈内,mealy机的输出在转移曲线上
体现在verilog代码中就是,moore机的最后输出逻辑只判断state,mealy机的输出逻辑中判断state && input
从它们的特征来看,Mealy状态机要比Moore状态机少一个状态。
以一个序列检测器为例,检测到输入信号11时输出z为1,其他时候为0。用Moore型FSM实现需要用到三个状态(A,B,C)。而用Mealy型FSM实现则只需要两个状态(A,B)。这是因为Moore型FSM的输出只由状态变量决定,要想输出z=1,必须有C状态形成,即寄存器中的两个1都打进去后才可以,输出z=1会在下一个有效沿到来的时候被赋值。而Mealy型FSM的输出是由输入和状态变量共同决定的。状态在B的时候如果输入为1,则直接以组合电路输出z=1,不需要等到下个有效沿到来,从而也就不需要第三个状态C。
状态机的设计基本上采取 always 块加上 case 语句的结构,一般分为三种描述方式,即一段式、二段式、三段式。
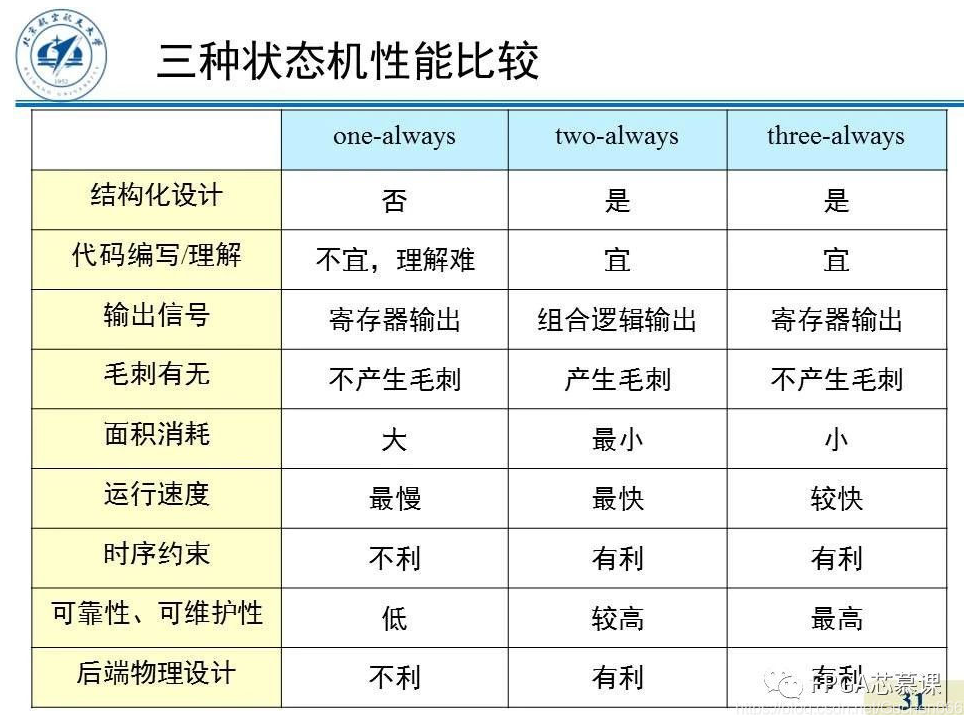
Q:两段式建模和三段式建模的关系
从代码上看,三段式建模的前两段与两段式建模完全相同,仅仅多了一段寄存器 FSM 输出。一般来说,使用寄存器输出可以改善输出的时序条件,还能避免组合电路的毛刺,所以是更为推荐的描述方式。但是电路设计不是一成不变的,在某些情况下,两段式结构比三段式结构更有优势。请大家再分析一下两段式和三段式的结构图,细心的读者会发现,两段式用状态寄存器分割了两部分组合逻辑(状态转移条件组合逻辑和输出组合逻辑);而三段式结构中,从输入到寄存器状态输出的路径上,要经过两部分组合逻辑(状态转移条件组合逻辑和输出组合逻辑),从时序上,这两部分组合逻辑完全可以看为一体。这样这条路径的组合逻辑就比较繁杂,该路径的时序相对紧张。也就是说,两段式建模中用状态寄存器分割了组合逻辑,而三段式将寄存器移到组合逻辑的最后端。如果寄存器前的组合逻辑过于复杂,势必会成为整个设计的关键路径,此时就不宜再使用三段式建模,而要使用两段式建模。解决两段式建模组合逻辑输出产生毛刺的方法是,额外的在 FSM 后级电路插入寄存器,调整时序,完成功能。
Q:状态编码
状态机所包含的N种状态通常需要用某种编码方式来表示,即状态编码。
常用的编码方式有:
顺序二进制编码
二进制编码是最紧密的编码,优点在于它使用状态向量的位数最少,因此需要的触发器也就少,节约了逻辑资源,但在实际应用中,往往需要较多组合逻辑对状态向量进行解码以产生输出,因此节约资源的效果并不明显。
缺点就是从一个状态转换到另一个状态时,可能有多个bit位发生变化,瞬变次数多,容易产生毛刺。
格雷码编码
格雷码编码在相邻状态的转换中,每次只有一个bit位发生变化,减少了产生毛刺和一些暂态的可能,但当有很多状态跳转时,需要合理的分配状态编码并保证每个状态跳转与状态编码唯一对应。
独热码编码
独热码是指对任意给定的状态,状态向量中仅有一位为"1"而其余位都为"0",因此在状态比较时仅仅需要比较一个 bit,一定程度上简化了比较逻辑,减少了毛刺产生的概率。独热码状态机的速度与其状态数量无关,仅仅取决于状态跳转的数量。独热码状态机还具有设计简单,修改灵活,易于调试,易于综合,易于寻找关键路径,易于进行静态时序分析等优点。
在物理实现时,N状态的状态机需要N个触发器,虽然增加了触发器的使用量,但由于状态译码简单,节省和简化了组合逻辑电路。FPGA器件由于寄存器数量多而逻辑资源紧张,采用独热码编码可以有效提高FPGA资源的利用率和电路的速度。
独热码有很多无效状态,应确保状态机一旦进入无效状态时,可以立即跳转到确定的已知状态以避免死锁现象的出现。
Q:需要注意的点
1:n 段式 FSM描述方法强调的是一种建模思路,绝不是简单的 always 语法块个数。
2:一个完备的状态机(健壮性强)应该具备初始化状态和默认状态。当芯片加电或者复位后,状态机应该能够自动将所有判断条件复位,并进入初始化状态。
3:状态编码的定义可以用 parameter 定义,但是不推荐使用`define 宏定义的方式,因为’define 宏定义在编译时自动替换整个设计中所定义的宏,而parameter 仅仅定义模块内部的参数,定义的参数不会与模块外的其他状态机混淆。
4:如果使用 2 段式 FSM 描述 Mealy 状态机,输出逻辑可以用"?语句"描述,或者使用 case 语句判断转移条件与输入信号即可。如果输出条件比较复杂,而且多个状态共用某些输出,则建议使用 task/endtask 将输出封装起来,达到模块复用的目的。
5:为了避免不必要的竞争冒险,不论是做两段式还是三段式 FSM 描述时,必须遵循时序逻辑 always 模块使用非阻塞赋值“<=”,即当前状态向下一状态时序转移,和寄存 FSM 输出等时序 always 模块中都要使用非阻塞赋值;而组合逻辑 always 模块使用阻塞赋值“=”,即状态转移条件判断,组合逻辑输出等always 模块中都要使用阻塞赋值。
6:Full Case 与 Parallel Case 综合属性
所谓 Full Case 是指:FSM 的所有编码向量都可以与 case 结构的某个分支或 default 默认情况匹配起来。如果+
一个 FSM 的状态编码是 8bit,则对应的256 个状态编码(全状态编码是 n 2 个)都可以与 case 的某个分支或者 default映射起来。
所谓 Parallel Case 是指:在 case 结构中,每个 case 的判断条件表达式,有且仅有唯一的 case 语句的分支(与之对应,即两者关系是一一对应关系。
目前知名综合器如 Synplify Pro、Precision RTL 和 Synopys 综合工具等都支持“ synthesis full_case”和“ synthesis parallel_case”这些综合约束属性,合理使用 Full Case 约束属性,可以增强设计的安全性;合理使用 Parallel Case约束属性,可以改善状态机译码逻辑。但是设计者必须具体情况具体分析,对于有的设计,不当使用这两条语句,会占用大量逻辑资源,并恶化 FSM 的时序表现。
Q:状态机典型题目
序列检测器
售货机
交通信号灯
6 锁存器Latch和触发器DFF区别
Latch:电平触发;
DFF:上升沿触发;
都具备记忆功能
7 竞争与冒险
8 同步复位 异步复位
9 两段式建模和三段式建模的关系
从代码上看,三段式建模的前两段与两段式建模完全相同,仅仅多了一段寄存器 FSM 输出。一般来说,使用寄存器输出可以改善输出的时序条件,还能避免组合电路的毛刺,所以是更为推荐的描述方式。但是电路设计不是一成不变的,在某些情况下,两段式结构比三段式结构更有优势。请大家再分析一下两段式和三段式的结构图,细心的读者会发现,两段式用状态寄存器分割了两部分组合逻辑(状态转移条件组合逻辑和输出组合逻辑);而三段式结构中,从输入到寄存器状态输出的路径上,要经过两部分组合逻辑(状态转移条件组合逻辑和输出组合逻辑),从时序上,这两部分组合逻辑完全可以看为一体。这样这条路径的组合逻辑就比较繁杂,该路径的时序相对紧张。也就是说,两段式建模中用状态寄存器分割了组合逻辑,而三段式将寄存器移到组合逻辑的最后端。如果寄存器前的组合逻辑过于复杂,势必会成为整个设计的关键路径,此时就不宜再使用三段式建模,而要使用两段式建模。解决两段式建模组合逻辑输出产生毛刺的方法是,额外的在 FSM 后级电路插入寄存器,调整时序,完成功能。
最后
以上就是轻松菠萝最近收集整理的关于数字IC面试整理9 两段式建模和三段式建模的关系的全部内容,更多相关数字IC面试整理9内容请搜索靠谱客的其他文章。








发表评论 取消回复