GitChat 作者:兜哥
原文: 基于机器学习的 Webshell 发现技术探索
关注公众号:GitChat 技术杂谈,一本正经的讲技术
第十一章WebShell检测
WebShell就是以ASP、PHP、JSP或者CGI等文件形式存在的一种命令执行环境,也可以将其称做为一种网页后门。黑客在入侵了一个网站后,通常会将ASP或PHP后门文件与网站服务器web目录下正常的网页文件混在一起,然后就可以使用浏览器来访问ASP或者PHP后门,得到一个命令执行环境,以达到控制网站服务器的目的。顾名思义,“web”的含义是显然需要服务器开放web服务,“shell”的含义是取得对服务器某种程度上操作权限。WebShell常常被称为入侵者通过网站端口对网站服务器的某种程度上操作的权限。由于WebShell其大多是以动态脚本的形式出现,也有人称之为网站的后门工具。
在攻击链模型中,整个攻击过程分为以下几个步骤:
Reconnaissance(踩点)
Weaponization(组装)
Delivery(投送)
Exploitation(攻击)
Installation(植入)
C2(控制)
Actions (行动
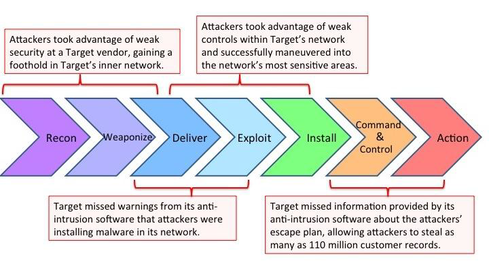
攻击链模型
在针对网站的攻击中,通常是利用上传漏洞,上传WebShell,然后通过WebShell进一步控制web服务器,对应攻击链模型是Install和C2环节。
常见的WebShell检测方法主要有以下几种:
静态检测,通过匹配特征码,特征值,危险函数函数来查找WebShell的方法,只能查找已知的WebShell,并且误报率漏报率会比较高,但是如果规则完善,可以减低误报率,但是漏报率必定会有所提高。
动态检测,执行时刻表现出来的特征,比如数据库操作、敏感文件读取等。
语法检测,根据PHP语言扫描编译的实现方式,进行剥离代码、注释,分析变量、函数、字符串、语言结构的分析方式,来实现关键危险函数的捕捉方式。这样可以完美解决漏报的情况。但误报上,仍存在问题。
统计学检测,通过信息熵、最长单词、重合指数、压缩比等检测。
本章主要以常见的WebShell数据集为例子介绍基于WebShell文件特征的检测技术。 介绍WebShell检测使用的数据集以及对应的特征提取方法,介绍使用的模型以及对应的验证结果,包括朴素贝叶斯和深度学习的MLP、CNN。基于WebShell文件访问特征的检测方法不在本章范围内。
数据集
数据集包含WebShell样本2616个,开源软件PHP文件9035个。
WebShell数据来自互联网上常见的WebShell样本,数据来源来自github上相关项目,为了演示方便,全部使用了基于PHP的WebShell样本。
github上WebShell相关项目
白样本主要使用常见的基于PHP的开源软件,主要包括以下几种。
WordPress
WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站。也可以把 WordPress当作一个内容管理系统(CMS)来使用。
WordPress是一款个人博客系统,并逐步演化成一款内容管理系统软件,它是使用PHP语言和MySQL数据库开发的。用户可以在支持 PHP 和 MySQL数据库的服务器上使用自己的博客。
WordPress有许多第三方开发的免费模板,安装方式简单易用。不过要做一个自己的模板,则需要你有一定的专业知识。比如你至少要懂的标准通用标记语言下的一个应用HTML代码、CSS、PHP等相关知识。WordPress官方支持中文版,同时有爱好者开发的第三方中文语言包,如wopus中文语言包。WordPress拥有成千上万个各式插件和不计其数的主题模板样式。
项目地址为:https://wordpress.org/
WordPress主页
PHPCMS
PHPCMS是一款网站管理软件。该软件采用模块化开发,支持多种分类方式,使用它可方便实现个性化网站的设计、开发与维护。它支持众多的程序组合,可轻松实现网站平台迁移,并可广泛满足各种规模的网站需求,可靠性高,是一款具备文章、下载、图片、分类信息、影视、商城、采集、财务等众多功能的强大、易用、可扩展的优秀网站管理软件。
PHPCMS由国内80后知名创业者钟胜辉(网名:淡淡风)于2005年创办,是国内知名的站长建站工具。2009年,PHPCMS创办人钟胜辉离开PHPCMS,创办国内针对媒体领域的CMS产品CmsTop(思拓合众)。
项目地址为:http://www.phpcms.cn/
phpcms主页
phpMyAdmin
phpMyAdmin 是一个以PHP为基础,以Web-Base方式架构在网站主机上的MySQL的数据库管理工具,让管理者可用Web接口管理MySQL数据库。借由此Web接口可以成为一个简易方式输入繁杂SQL语法的较佳途径,尤其要处理大量资料的汇入及汇出更为方便。其中一个更大的优势在于由于phpMyAdmin跟其他PHP程式一样在网页服务器上执行,但是您可以在任何地方使用这些程式产生的HTML页面,也就是于远端管理MySQL数据库,方便的建立、修改、删除数据库及资料表。也可借由phpMyAdmin建立常用的php语法,方便编写网页时所需要的sql语法正确性。
项目地址为:https://www.phpMyAdmin.net/

phpMyAdmin主页
Smarty
Smarty是一个使用PHP写出来的模板引擎,是目前业界最著名的PHP模板引擎之一。它分离了逻辑代码和外在的内容,提供了一种易于管理和使用的方法,用来将原本与HTML代码混杂在一起PHP代码逻辑分离。简单的讲,目的就是要使PHP程序员同前端人员分离,使程序员改变程序的逻辑内容不会影响到前端人员的页面设计,前端人员重新修改页面不会影响到程序的程序逻辑,这在多人合作的项目中显的尤为重要。
项目地址为:https://github.com/smarty-php/smarty
Yii
Yii是一个基于组件的高性能PHP框架,用于开发大型Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从 MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主题化,I18N和L10N,Yii提供了今日Web 2.0应用开发所需要的几乎一切功能。事实上,Yii是最有效率的PHP框架之一。
Yii是一个高性能的PHP5的web应用程序开发框架。通过一个简单的命令行工具 yiic 可以快速创建一个web应用程序的代码框架,开发者可以在生成的代码框架基础上添加业务逻辑,以快速完成应用程序的开发。
项目地址为:http://www.yiiframework.com/
Yii主页
特征提取
方法一:词袋&TF-IDF模型
我们使用最常见的词袋模型&TF-IDF提取文件特征。
把一个PHP文件作为一个完整的字符串处理,定义函数load_one_file加载文件到一个字符串变量中返回。
def load_one_file(filename):
x=""
with open(filename) as f:
for line in f:
line = line.strip('r')
x+=line
return x由于开源软件中包含大量图片、js等文件,所以遍历目录时需要排除非php文件。另外开源软件的目录结构相对复杂,不像前面章节的垃圾邮件、垃圾短信等是平面目录结构,所以要求我们递归访问指定目录并加载指定文件。
def load_files_re(dir):
files_list = []
g = os.walk(dir)
for path, d, filelist in g:
for filename in filelist:
if filename.endswith('.php'):
fulepath =
os.path.join(path, filename)
print "Load %s"
% fulepath
t = load_file(fulepath)
files_list.append(t)
return files_list加载搜集到的WebShell样本,并统计样本个数,将WebShell样本标记为1。
WebShell_files_list = load_files_re(WebShell_dir)
y1=[1]*len(WebShell_files_list)
black_count=len(WebShell_files_list)加载搜集到的开源软件样本,并统计样本个数,将开源软件样本标记为0。
wp_files_list =load_files_re(whitefile_dir)
y2=[0]*len(wp_files_list)
white_count=len(wp_files_list)将WebShell样本和开源软件样本合并。
x=WebShell_files_list+wp_files_list
y=y1+y2使用2-gram提取词袋模型,并使用TF-IDF进行处理。
CV = CountVectorizer(ngram_range=(2, 2),
decode_error="ignore",max_features=max_features,
token_pattern = r'bw+b',min_df=1, max_df=1.0)
x=CV.fit_transform(x).toarray()
transformer = TfidfTransformer(smooth_idf=False)
x_tfidf = transformer.fit_transform(x)
x = x_tfidf.toarray()所谓的2-gram是词袋模型的一个细分类别,也有的机器学习书籍里面单独把2-gram或者说n-gram作为单独的模型介绍。n-gram基于这样一种假设,第n个单词只和它前面的n-1个词有关联,每n个单词作为一个处理单元。
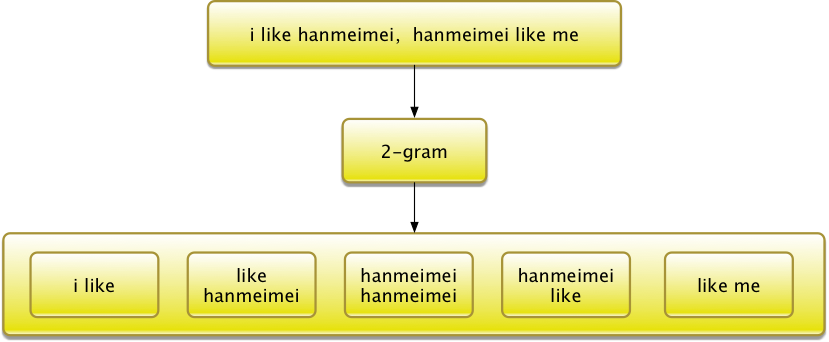
2-gram举例
通过设置CountVectorizer函数的ngram_range参数和token_pattern即可实现n-gram,其中ngram_range表明n-gram的n取值范围,如果是2-gram设置成(2,2)即可。token_pattern表明词切分的规则,通常设置为r'bw+b'即可。
划分训练集与测试集,测试集的比例为40%。
x_train, x_test, y_train,y_test = train_test_split(x, y, test_size=0.4, random_state=0)方法二:opcode&n-gram模型
opcode是计算机指令中的一部分,用于指定要执行的操作, 指令的格式和规范由处理器的指令规范指定。除了指令本身以外通常还有指令所需要的操作数,可能有的指令不需要显式的操作数。这些操作数可能是寄存器中的值,堆栈中的值,某块内存的值或者IO端口中的值等等。通常opcode还有另一种称谓:字节码(byte codes)。 例如Java虚拟机(JVM),.NET的通用中间语言(CIL: Common Intermeditate Language)等等。PHP中的opcode则属于前面介绍中的后着,PHP是构建在Zend虚拟机(Zend VM)之上的。
PHP的opcode就是Zend虚拟机中的指令,常见的opcode如下图所示。
PHP常见opcode
通常可以通过PHP的VLD(Vulcan Logic Dumper,逻辑代码展现)是扩展来查看PHP文件对应的opcode。
wget http://pecl.php.net/get/vld-0.13.0.tgz
tar zxvf vld-0.13.0.tgz
cd ./vld-0.13.0
/configure--with-php-config=/usr/local/php/bin/php-config --enable-vld
make && makeinstall然后在php.ini配置文件中添加extension=vld.so 用于激活VLD,其中php.ini默认位置位于lib目录中。VLD还可以从github上下载并安装,步骤为:
git clone https://github.com/derickr/vld.git
cd vld
phpize
./configure
make && makeinstallVLD项目的主页为:
http://pecl.php.net/package/vld
VLD扩展下载主页
以PHP文件hello.php为例:
<?php
echo"Hello World";
$a = 1 +1;
echo $a;
?>通过使用PHP的VLD扩展查看对应的opcode,其中vld.active=1表示激活VlD,vld.execute=0表示只解析不执行。
php -dvld.active=1 -dvld.execute=0hello.php显示结果为:
function name: (null)
number of ops: 5
compiled vars: !0 = $a
line #* E I O op fetch ext return operands
-----------------------------------------------------------------------------
2 0 E > ECHO 'Hello+World'
3 1 ADD ~0 1, 1
2 ASSIGN !0, ~0
4 3 ECHO !0
6 4 > RETURN 1
branch: # 0; line: 2- 6; sop: 0; eop: 4; out1: -2
path #1: 0,对应的opcode为:
ECHO
ADD
ASSIGN
ECHO 以一个常见的一句话木马为例:
<?php
echo $_GET['r'];
?>通过VLD查看的结果为:
function name: (null)
number of ops: 5
compiled vars: none
line #* E I O op fetch ext return operands
-------------------------------------------------------------------------------------
2 0 E > FETCH_R global $0 '_GET'
1 FETCH_DIM_R $1 $0, 'r'
2 ECHO $1
4 3 ECHO '+%0A'
4 > RETURN 1
branch: # 0; line: 2- 4; sop: 0; eop: 4; out1: -2
path #1: 0, 对应的opcode为:
FETCH_R
FETCH_DIM_R
ECHO
ECHO
RETURN 使用2-gram对opcode进行分组,结果为:
(FETCH_R, FETCH_DIM_R) (FETCH_DIM_R, ECHO) (ECHO, ECHO) (ECHO, RETURN)完整的处理流程为:
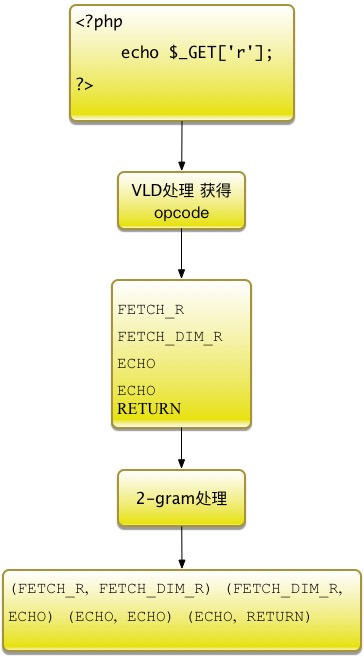
PHP代码处理流程图
代码实现方面,首先使用VLD处理PHP文件,把处理的结果保存在字符串中。
t=""
cmd=php_bin+" -dvld.active=1 -dvld.execute=0 "+file_path
output=commands.getoutput(cmd)PHP的opcode都是由大写字母和下划线组成的单词,使用findall函数从字符串中提取全部满足条件的opcode,并以空格连接成一个新字符串。
t=output
tokens=re.findall(r's(b[A-Z_]+b)s',output)
t=" ".join(tokens)遍历读取指定目录下全部PHP文件,保存其对应的opcode字符串。
def
load_files_opcode_re(dir):
files_list = []
g = os.walk(dir)
for path, d, filelist in g:
for filename in filelist:
if filename.endswith('.php')
:
fulepath =
os.path.join(path, filename)
print "Load %s
opcode" % fulepath
t =
load_file_opcode(fulepath)
files_list.append(t)
return files_list依次读取保存WebShell样本以及正常PHP文件的目录,加载对应的opcode字符串,其中标记WebShell为1,正常PHP文件为0。
WebShell_files_list
= load_files_re(WebShell_dir)
y1=[1]*len(WebShell_files_list)
black_count=len(WebShell_files_list)
wp_files_list =load_files_re(whitefile_dir)
y2=[0]*len(wp_files_list)
white_count=len(wp_files_list)使用2-gram处理opcode字符串,其中通过设置ngram_range=(2, 2)就可以达到使用2-gram的目的,同理如果使用3-gram设置ngram_range=(3, 3)即可。
CV
= CountVectorizer(ngram_range=(2, 2), decode_error="ignore",max_features=max_features,
token_pattern = r'bw+b',min_df=1, max_df=1.0)
x=CV.fit_transform(x).toarray()使用TF-IDF进一步处理。
transformer
= TfidfTransformer(smooth_idf=False)
x_tfidf = transformer.fit_transform(x)
x = x_tfidf.toarray()另外,开发调试阶段会频繁解析相同的PHP文件获取对应的opcode,可以使用PHP的opcode缓存技术提高效率。opcode缓存技术[6]可以有效减少不必要的编译步骤,减少cpu和内存的消耗。正常情况下PHP代码的执行过程会经历文本扫描、语法解析、创建opcode、执行opcode这几部。

未使用opcode缓存的情况下PHP代码执行过程
使用了opcode缓存技术后,对于曾经解析过的PHP文件,opcode会缓存下来,遇到同样内容的PHP文件就可以直接进入opcode执行阶段。
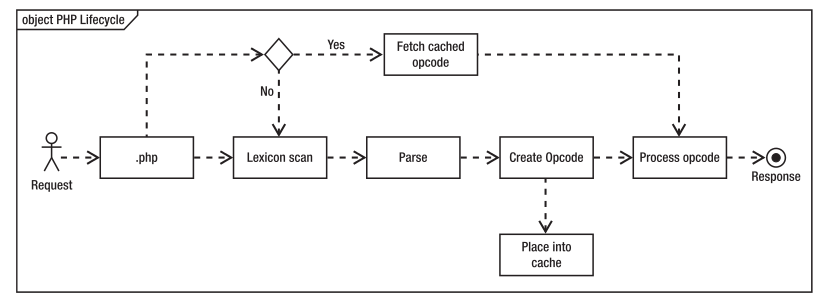
使用opcode缓存的情况下PHP代码执行过程.
开启opcode的缓存功能非常方便,PHP 5.5.0以后在编译PHP源码的时候开启–enable-opcache,编译选型为:
./configure--prefix=/opt/php --enable-opcache
config.status:creating php5.spec
config.status:creating main/build-defs.h
config.status:creating scripts/phpize
config.status:creating scripts/man1/phpize.1
config.status:creating scripts/php-config
config.status:creating scripts/man1/php-config.1
config.status:creating sapi/cli/php.1
config.status:creating sapi/cgi/php-cgi.1
config.status:creating ext/phar/phar.1
config.status:creating ext/phar/phar.phar.1
config.status:creating main/php_config.h
config.status:executing default commands编译安装
make-j4 & make install修改配置文件php.ini,加载对应的动态库。
zend_extension=/full/path/to/opcache.so配置opcode缓存对应的配置选项,典型的配置内容如下所示。
engine= On
zend_extension=/lib/php/extensions/no-debug-non-zts-20131226/opcache.so
opcache.memory_consumption=128
opcache.interned_strings_buffer=8
opcache.max_accelerated_files=4000
opcache.revalidate_freq=60
opcache.fast_shutdown=1
opcache.enable_cli=1
opcache.enable=1方法三:opcode调用序列模型
在opcode&n-gram模型中,我们假设第n个opcode之与前n-1个opcode有关联,现在我们以一个更加长的时间范围来看opcode的调用序列,把整个PHP的opcode当成一个调用序列来分析,为了便于程序处理,截取整个文件opcode的固定长度的opcode序列分析,超过固定长度的截断,不足的使用0补齐。以一个常见的一句话木马为例:
<?php
echo $_GET['r'];
?>
图11-13 解析PHP文件获取opcode调用序列的过程
该文件通过VLD处理获得对应的opcode为:
FETCH_R
FETCH_DIM_R
ECHO
ECHO
RETURN 获得对应的opcode序列为:
(FETCH_R,FETCH_DIM_R,ECHO,ECHO,RETURN )模型训练与验证
方法一:朴素贝叶斯算法
使用朴素贝叶斯算法,特征提取使用词袋&TF-IDF模型,完整的处理流程为:
将WebShell样本以及常见PHP开源软件的文件提取词袋。
使用TF-IDF处理。
随机划分为训练集和测试集。
使用朴素贝叶斯算法在训练集上训练,获得模型数据。
使用模型数据在测试集上进行预测。
验证朴素贝叶斯算法预测效果。
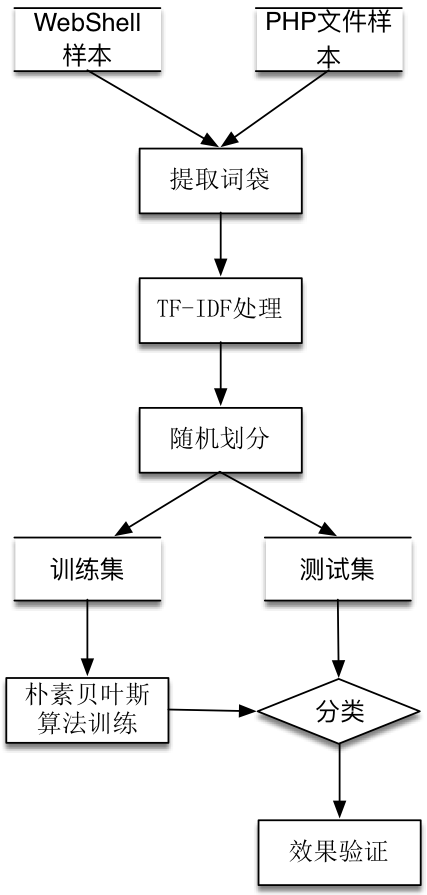
特征提取使用词袋&TF-IDF模型算法使用朴素贝叶斯的流程图
实例化朴素贝叶斯算法,并在训练集上训练数据,针对测试集进行预测。
gnb = GaussianNB()
gnb.fit(x_train,y_train)
y_pred=gnb.predict(x_test)评估结果的准确度和TP、FP、TN、FN四个值。
print metrics.accuracy_score(y_test, y_pred)
print metrics.confusion_matrix(y_test, y_pred)在词袋最大特征数为15000的情况下,使用词袋&TF-IDF模型时,TP、FP、TN、FN矩阵如下表所示。
表1-1 基于词袋&TF-IDF模型的朴素贝叶斯验证结果
| 类型名称** | 相关** | 不相关** |
|---|---|---|
| 检索到 | 3566 | 52 |
| 未检索到 | 71 | 972 |
整个系统的准确率为94.92%,召回率为93.19%。
完整输出结果为:
metrics.accuracy_score:
0.97361081313
metrics.confusion_matrix:
[[3566 52]
[ 71 972]]
metrics.precision_score:
0.94921875
metrics.recall_score:
0.931927133269
metrics.f1_score:
0.940493468795方法二:深度学习算法之MLP
使用MLP算法,隐含层设计为2层,每次节点数分别为5和2。
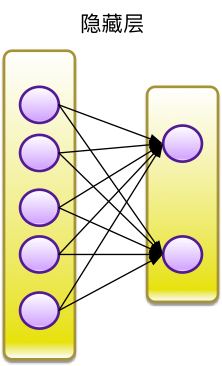
MLP隐藏层设计
使用MLP算法,特征提取使用词袋&TF-IDF模型,完整的处理流程为:
将WebShell样本以及常见PHP开源软件的文件提取词袋。
使用TF-IDF处理。
随机划分为训练集和测试集。
使用MLP算法在训练集上训练,获得模型数据。
使用模型数据在测试集上进行预测。
验证MLP算法预测效果。
实例化MLP算法,并在训练集上训练数据,针对测试集进行预测。
clf = MLPClassifier(solver='lbfgs',
alpha=1e-5,
hidden_layer_sizes =
(5, 2),
random_state = 1)
print clf
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)评估结果的TP、FP、TN、FN四个值。
print metrics.accuracy_score(y_test, y_pred)
print metrics.confusion_matrix(y_test, y_pred)评估结果的准确率与召回率以及F1分值。
print "metrics.precision_score:"
print metrics.precision_score(y_test, y_pred)
print "metrics.recall_score:"
print metrics.recall_score(y_test, y_pred)
print "metrics.f1_score:"
print metrics.f1_score(y_test,y_pred)在词袋最大特征数为15000且同时使用TF-IDF模型的情况下, TP、FP、TN、FN矩阵如下表所示。
表1-2 基于词袋和TF-IDF模型的MLP验证结果
| 类型名称** | 相关** | 不相关** |
|---|---|---|
| 检索到 | 3583 | 35 |
| 未检索到 | 51 | 992 |
准确率为96.59%,召回率为95.11%。
完整输出结果为:
metrics.confusion_matrix:
[[3583 35]
[ 51 992]]
metrics.precision_score:
0.965920155794
metrics.recall_score:
0.951102588686
metrics.f1_score:
0.95845410628使用MLP算法,特征提取使用特征提取使用opcode&n-gram,完整的处理流程为:
将WebShell样本以及常见PHP开源软件的文件提取opcode.
使用n-gram处理。
随机划分为训练集和测试集。
使用MLP算法在训练集上训练,获得模型数据。
使用模型数据在测试集上进行预测。
验证MLP算法预测效果。
特征提取使用opcode&n-gram,n取4,最大特征数取2000的情况下,TP、FP、TN、FN矩阵如下表所示。
表1-3 基于opcode&n-gram模型的MLP验证结果
| 类型名称** | 相关** | 不相关** |
|---|---|---|
| 检索到 | 2601 | 97 |
| 未检索到 | 20 | 484 |
准确率为83.30%,召回率为96.03%。
完整输出结果为:
0.963460337289
metrics.confusion_matrix:
[[2601 97]
[ 20 484]]
metrics.precision_score:
0.833046471601
metrics.recall_score:
0.960317460317
metrics.f1_score:
0.892165898618方法三:深度学习算法之CNN
使用方法二中生成的opcode&n-gram数据,算法使用CNN,完整的处理流程为:
将WebShell样本以及常见PHP开源软件的文件提取opcode.
使用n-gram处理。
随机划分为训练集和测试集。
使用CNN算法在训练集上训练,获得模型数据。
使用模型数据在测试集上进行预测。
验证CNN算法预测效果。
使用方法二中生成的opcode&n-gram数据,获得训练数据集和测试数据集。
x, y = get_feature_by_opcode()
x_train, x_test, y_train, y_test = train_test_split(x, y,test_size = 0.4, random_state = 0)将训练和测试数据进行填充和转换,不到最大长度的数据填充0,由于是二分类问题,把标记数据二值化。定义输入参数的最大长度为文档的最大长度。
trainX = pad_sequences(trainX, maxlen=max_document_length,
value=0.)
testX = pad_sequences(testX, maxlen=max_document_length, value=0.)
# Converting labels to binary vectors
trainY = to_categorical(trainY, nb_classes=2)
testY = to_categorical(testY, nb_classes=2)
network = input_data(shape=[None,max_document_length],name='input')定义CNN模型,使用3个数量为128,长度分别为3、4、5的一维卷积函数处理数据。
network = tflearn.embedding(network, input_dim=1000000,
output_dim=128)
branch1 = conv_1d(network, 128, 3, padding='valid', activation='relu',
regularizer="L2")
branch2 = conv_1d(network, 128, 4, padding='valid', activation='relu',
regularizer="L2")
branch3 = conv_1d(network, 128, 5, padding='valid', activation='relu',
regularizer="L2")
network = merge([branch1, branch2, branch3], mode='concat', axis=1)
network = tf.expand_dims(network, 2)
network = global_max_pool(network)
network = dropout(network, 0.8)
network = fully_connected(network, 2, activation='softmax')
network = regression(network, optimizer='adam', learning_rate=0.001,
loss='categorical_crossentropy', name='target')实例化CNN对象并进行训练数据,一共训练5轮。
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(trainX, trainY,
n_epoch=5, shuffle=True,
validation_set=0.1,
show_metric=True,
batch_size=100,run_id="webshell")完整的CNN结构如下图所示。
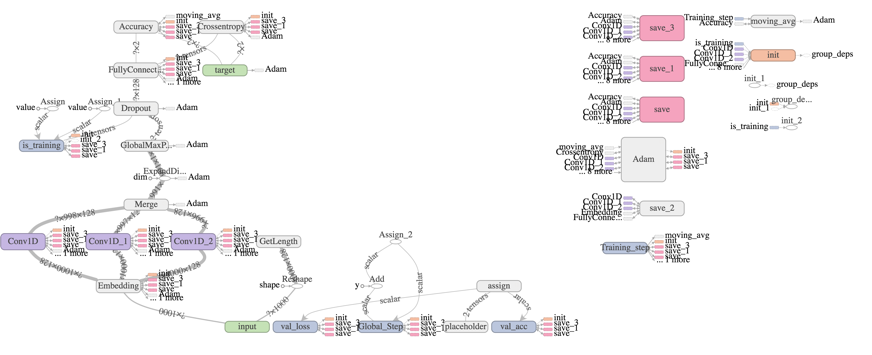
用于识别WebShell的CNN结构图
考核CNN对应的准确率、召回率,误报数和漏报数。
print "metrics.accuracy_score:"
print metrics.accuracy_score(y_test, y_pred)
print "metrics.confusion_matrix:"
print metrics.confusion_matrix(y_test, y_pred)
print "metrics.precision_score:"
print metrics.precision_score(y_test, y_pred)
print "metrics.recall_score:"
print metrics.recall_score(y_test, y_pred)
print "metrics.f1_score:"
print metrics.f1_score(y_test,y_pred)运行程序,经过5轮训练,在的情况下,使用opcode&n-gram模型时,n取4,TP、FP、TN、FN矩阵如下表所示。
表1-4 基于opcode&n-gram模型的CNN验证结果
| 类型名称** | 相关** | 不相关** |
|---|---|---|
| 检索到 | 2669 | 29 |
| 未检索到 | 367 | 137 |
整个系统的准确率为82.53%,召回率为27.18%。
完整输出结果为:
metrics.accuracy_score:
0.87632729544
metrics.confusion_matrix:
[[2669 29]
[ 367 137]]
metrics.precision_score:
0.825301204819
metrics.recall_score:
0.271825396825
metrics.f1_score:
0.408955223881使用方法三中生成的opcode序列数据,算法使用CNN,完整的处理流程为:
将WebShell样本以及常见PHP开源软件的文件提取opcode.
使用词袋处理,针对opcode进行编号,生成opcode序列。
随机划分为训练集和测试集。
使用CNN算法在训练集上训练,获得模型数据。
使用模型数据在测试集上进行预测。
验证CNN算法预测效果。
使用方法三中opcode调用序列编码后的数据,获得训练数据集和测试数据集。
x_train, x_test, y_train, y_test= get_feature_by_opcode ()运行程序,经过5轮训练,在opcode序列长度为3000的情况下,使用opcode序列模型时,TP、FP、TN、FN矩阵如下表所示。
表1-5 基于opcode序列模型的CNN验证结果
| 类型名称** | 相关** | 不相关** |
|---|---|---|
| 检索到 | 2685 | 13 |
| 未检索到 | 89 | 415 |
整个系统的准确率为96.96%,召回率为82.34%。
完整输出结果为:
metrics.accuracy_score:
0.968144909432
metrics.confusion_matrix:
[[2685 13]
[ 89 415]]
metrics.precision_score:
0.969626168224
metrics.recall_score:
0.823412698413
metrics.f1_score:
0.890557939914本章小结
本章基于搜集的PHP的WebShell数据集介绍了WebShell的识别方法。针对PHP的WebShell数据集,特征提取方法有词袋&TF-IDF、opcode&n-gram以及opcode序列三种方法。训练模型介绍了朴素贝叶斯以及深度学习的MLP和CNN算法,其中基于基于词袋和TF-IDF模型的MLP准确率和召回率综合表现最佳,基于opcode序列模型的CNN准确率较高。
http://www.darkreading.com/attacks-breaches/leveraging-the-kill-chain-for-awesome/a/d-id/1317810
http://www.freebuf.com/news/80820.html
http://www.cnxct.com/pecker-scanner-beta-release-support-cloud-confirmation/
http://blog.csdn.net/u011066706/article/details/51175971
http://www.nowamagic.net/librarys/veda/detail/1325
http://www.cnblogs.com/JohnABC/p/4531029.html
实录:《刘焱: 基于机器学习发现 Webshell 实战解析》
彩蛋
重磅 Chat 分享:《一场 Chat 让你搞清 BAT 程序员的技术职级》
分享人:
胜洪宇,一线互联网公司前端技术组长,掘金签约作者,前端博客博主,所讲课程帮助超过20万前端小伙伴学习。
Chat简介:
很多程序员向往进入 BAT 这样的大型互联网公司,但是又不知道他们如何评定技术职级。
- 阿里集团薪资职级如何划分?让你快速得到马云的青睐。
- 在百度明白这些,你将快速晋升。
- 腾讯职级里的小秘密,这样工作你会更强。
一场 Chat 让你搞清 BAT 的技术评价体系,为您进入超级互联网公司指明技术方向,时刻做好准备!如果您希望您的技术团队也像这些互联网巨头一样强大,本场 Chat 我将帮您马上模仿建立有效的技术职级体系。
想要免费参与本场 Chat ?很简单,「GitChat技术杂谈」公众号后台回复「BAT」

最后
以上就是清爽向日葵最近收集整理的关于GitChat · 安全 | 基于机器学习的 Webshell 发现技术探索的全部内容,更多相关GitChat内容请搜索靠谱客的其他文章。
![[python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)







发表评论 取消回复