ASCII,GB2312,GBK,GB18030,Unicode,UTF-8,及python编码
1 概述
学python以来,写脚本程序时遇到读写文件,经常遇到编码问题,中文为乱码的情况。每次遇到此类问题,各种百度,加各种咨询,然而仍然不明其原因,问题的解决情况也是误打误撞,有些能解决,有些解决不了。这样让学写python编程之路变得异常坎坷。终于,下定决心,将编码问题好好学习理解一番。
2 编码介绍
由于计算机只识别0和1,为了使计算机能够支持文字和字母等符号,方便实用操作计算机。于是,字符编码应运而生。
2.1 ASCII编码
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255)。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里(即用一个字节的后七位),也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
随着发展,计算机开始普及,当计算机流传到欧洲时,问题再次出现,原本的ASCII编码只能解决美国人的编码问题,无法将欧洲的文字表示出来。于是乎,欧洲人就把ASCII码中没用到的第一位给用了,即:
(1)ASCII码用一个字节的后七位,表示范围是0-127;
(2)欧洲人把这个字节的第一位也用了,表示范围0-255。除去原本的0-127,剩下128-255.128-159之间为控制字符,160-255位文字符号,其中包括了西欧语言、希腊语、泰语、阿拉伯语、希伯来语。砖家们决定把他们的编码名称叫做Latin1,后面由于欧洲统一制定ISO标准,所以又有了一个ISO的名称,即ISO-8859-1。
2.2 中文编码GB2312,GBK,GB18030
计算机技术传到了亚洲大地,比如中国。原本的一个字节的8个位全都用完了,但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312,GBK,GB18030编码,用来把中文编进去,产生了国标码。
国标码是汉字的国家标准编码,目前主要有GB2312、GBK、GB18030三种。
(1)GB2312编码方案于1980年发布,收录汉字6763个,采用双字节编码。
(2)GBK编码方案于1995年发布,收录汉字21003个,采用双字节编码。
(3)GB18030编码方案于2000年发布第一版,收录汉字27533个;2005年发布第二版,收录汉字70000余个,以及多种少数民族文字。GB18030采用单字节、双字节、四字节分段编码。
由于新版向下兼容旧版,也就是说GBK是在GB2312已有码位基础上增加新码位,GB18030是在GBK已有码位基础上增加新码位,各种编码方案中共有的字符编码相同。现在的中文信息处理应优先采用GB18030编码方案。
2.3 Unicode
全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。于是产生了Unicode编码。
Unicode旨在解决其他国家语言共存的问题而应运而生,俗称万国编码,仅建立在内存中。由于ASCII 用的是 8位也就是说,最多支持 11111111 转换成十进制255个编码。其他语言编码恐怕就远远不够了,例如,中文有几万个。因此后来对于中文就在原来1字节(11111111)基础又加了1个字节。
| ASCII | 英文 | 11111111 | 最高支持255个字符 | 占用1字节 |
| Unicode | 支持中文 | 11111111 11111111 | 100W+ | 占用2-4字节 |
Unicode为了同时兼容8位的ASCII,在原来ASCII的8位基础上统一添加00000000实现了 2个bytes。之所以说unicode定长,是因为所有的字符都是占用2bytes。虽然2**16-1=65535,但unicode却可以存放100w+个字符,因为unicode存放了与其他编码的映射关系。但也存在以下问题:
(1)对于英文的文本来说,Unicode增加了的存储空间,原来ASCII可以编码英文,且只占一个字节,而Unicode编码的固定长度2字节,无疑是多了一倍的空间。
(2)Unicode是一套字符集标准,保证世界上各个国家的文字都按一个字符来处理,它们都有一个唯一的Unicode码,就像ASCII码表一样,但是它只是规定如何编码,并没有规定如何存储、传输这个编码。
于是,UTF-8应运而生。
2.4 UTF-8编码
UTF-8(可变长,全称Unicode Transformation Format),它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。英文用一个字节,中文用三个字节编码。当字符在 ASCII 码的范围时,就用一个字节表示,保留了 ASCII 字符一个字节的编码做为它的一部分。(注意的是 unicode 一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。
可变长这一特点,也是现在大家也都在推行UTF-8的原因之一。UTF-8是在互联网上使用最广的一种 unicode 的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8编码规则:对于n个字节的字符,第一个字节的前n为都设为1,第n+1位设为0,后面字节的前两位都设为10。剩下的二进制位全部用该字符的Unicode码填充。

3 python编码介绍
python版本,目前主要有两种python2和python3版本,它们在字符串语义发生了变化如下图所示:

(1)python2中:
str:表面含义是字符串,实际抽象是一系列连续的字节。最早的编码是ASCII,只包含英文字符,一个字节表示一个字符,那一片连续的字节就等价于一个字符串。
Unicode:支持多国语言,在python内部用Unicode字符编码来表示一个字符,Unicode才是真正含义的字符串。
要把字符存储在文件当中,Unicode不能直接存储在文件当中的,必须以某种编码格式,变成连续字节“str”的形式,才能存储进去。
举例:Unicode与str之间的转换:
s = u'你好'
s.encode('utf8') #采用utf8编码
输出:'xe4xbdxa0xe5xa5xbd'
'xe4xbdxa0xe5xa5xbd'.decode('utf8') #采用utf8解码
输出:你好
(2)python3中:
bytes: 原来python2中的“str”变成了真正意义上的bytes,一系列字节。
str: 原来的Unicode变成了真正含义上的字符串。
举例:定义bytes类型和字符串类型
s = b'asndlfhkjd' # Python对bytes类型的数据用带b前缀的单引号或双引号表示。python2中直接s = 'asndlfhkjd'
s = '你好' #python3中表示Unicode,而 python2中表示Unicode需要在前面加“u”,如s = u'你好'
(3)以下重点介绍python3编码
在最新的Python3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言。这句话的一个重要的地方是:字符串。
例如:print("这句话是使用Unicode编码的,支持多语言,比如English.")
这句话是使用Unicode编码的,支持多语言,比如English,中文可以正常输出。
如果utf-8编码方式输出:"这句话是使用Unicode编码的,支持多语言,比如English.".encode('utf-8')
b'xe8xbfx99xe5x8fxa5xe8xafx9dxe6x98xafxe4xbdxbfxe7x94xa8Unicodexe7xbcx96xe7xa0x81xe7x9ax84xefxbcx8cxe6x94xafxe6x8cx81xe5xa4x9axe8xafxadxe8xa8x80xefxbcx8cxe6xafx94xe5xa6x82English.'
首先,输出是以b开头的,说明这是一段bytes。utf-8是向下兼容ASCII码,输出中的英文Unicode和English就被原样输出,而ASCII码不能识别的中文,则用utf-8编码方式来表示,如xe8,xbf等等。
那Unicode编码方式用得好好的,可以直接混合输出英文和中文等多种语言,换成ctf-8输出后,字符只有英文能让我们看懂,中文变成了难以分辨的十六进制(xe8xbfx99xe5x8fxa5xe8...),主要是为了节省内存。因此,python中的str是以Unicode编码的,如果要在网络上传输,或者保存到磁盘上,就得转换为utf-8编码方式。
utf-8是常见的,有时中文编码也可以用国标码进行编码。
4 python中文编码问题
本节主要针对目前自已在python编码中,遇到的中文编码问题进行汇总。
1、无论在python2还是python3中,采用什么编码格式存储中文,解码时需要采用对应的解码方式。
2、UnicodeEncoderError
将文本转化为字节序列时,若有字符在目标编码中没有定义,则会出现UnicodeEncoderError。如下图所示,由于中文字符在ascii编码中无定义,则会报出编码错误。对于此类问题,需选择合适的编码类型,比如含有中文字符,一般用UTF-8编码类型对unicode字符串编码。

3、UnicodeDecodeError
把二进制序列转化为文本时,遇到无法转换的字节序列,则会发生此异常。比如用UTF-8编码后的二进制序列,用GB2312解码,由于两种编码不兼容,用GB2312不能识别字节序列,则会出现异常,如下图所示。

碰到这种异常,是由于decode使用的编码和字节序列的编码不一致,可以用字符编码侦测包chardet检测字节序列的编码,然后再用此编码解码。如下图所示:
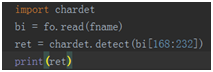
输出为:
![]()
4、python写中文到CSV文件,用excel打开,中文是乱码,而用记事本打开,则为正常中文。
excel打开csv文件,可以识别编码“GB2312”等,但是不能识别“utf-8”,因此中文写入csv,且要用excel打开时要标注GBK或GB2312编码。
5、从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法,但是用decode方法时,如果bytes中包含无法解码的字节,decode()方法会报错,如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节,如下图所示:

最后
以上就是彩色皮带最近收集整理的关于编码格式ASCII,GB2312,GBK,GB18030,Unicode,UTF-8,以及python编码ASCII,GB2312,GBK,GB18030,Unicode,UTF-8,及python编码的全部内容,更多相关编码格式ASCII内容请搜索靠谱客的其他文章。








发表评论 取消回复