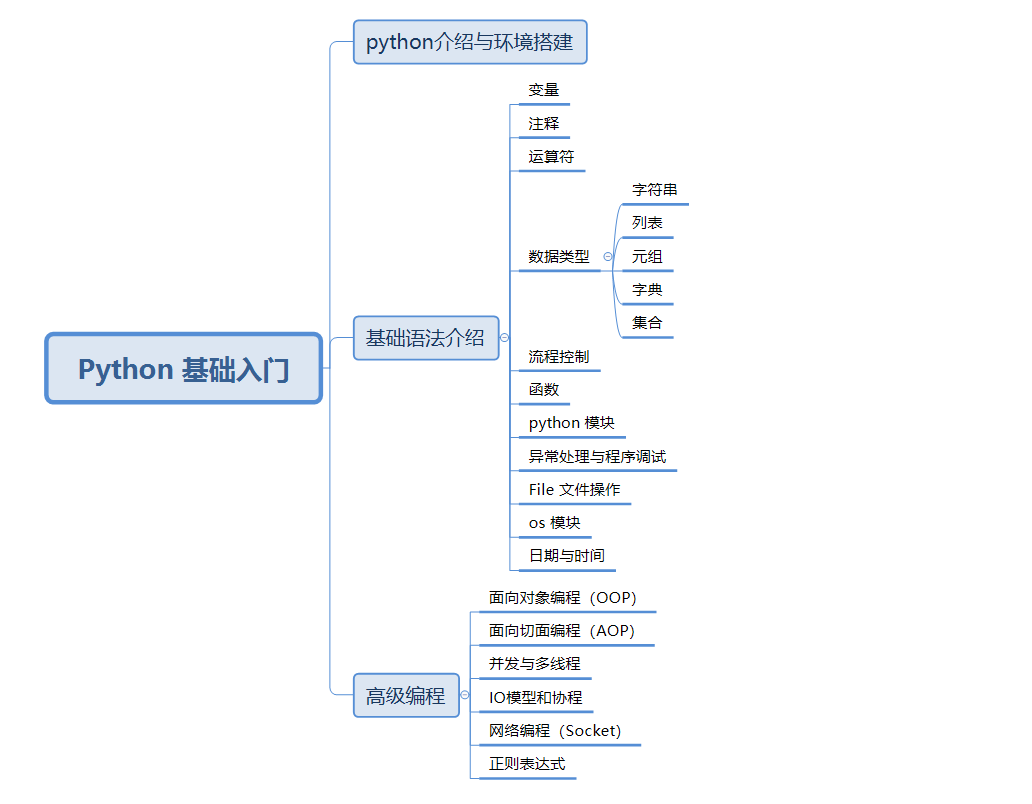
文章目录
- 一、概述
- 二、并发与并行原理
- 1)并行
- 2)并发
- 3)并发和并行区别
- 三、Python 多线程
- 1)进程与线程关系
- 2)Python 多线程GIL介绍
- 3)Python 创建多线程
- 1、thread
- 2、threading(常用)
- 4)守护线程
- 5)线程合并(join)
- 6)线程同步与互斥锁
- 7)可重入锁(递归锁)
- 8)定时器
- 四、Python 多进程
- 1)创建多进程
- 1、直接使用Process
- 2、继承Process来自定义进程类,重写run方法
- 2)多进程通信
- 1、Queue
- 2、Pipe
- 3)进程池
- 4)多线程和多进程如何选择?
- 五、Python 之 signal 模块
- 1)发生信号的原因
- 2)信号处理方式
- 3)规则信号
- 3)signal.alarm(time)
- 4)signal.pasue()
- 5)设置信号处理函数
- 六、并发网络通信模型
- 1)基于fork的多进程网络并发模型
- 2)基于threading的多线程网络并发
一、概述
并发与多线程在任何编程语言中都是非常常用的,也是非常重要的,接下来就细讲python中的并发与多线程原理和实践,如果想了解python基础部分,可以参考我以下几篇文章:
- Python 介绍和环境准备
- Python 基础语法介绍(一)
- Python 基础语法介绍(二)
- Python 高级编程之面向对象(一)
- Python 高级编程之面向切面编程 AOP(二)
二、并发与并行原理
1)并行
当系统有一个以上CPU时,则进程的操作有可能非并发。当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行。
2)并发
当有多个进程在操作时,如果系统只有一个CPU,则它根本不可能真正同时执行一个以上的进程,说白了就是多个进程同时由同一个CPU执行,并发只能把CPU运行时间划分成若干个时间段,再将时间段分配给各个进程执行,在一个时间段的进程代码运行时,其它进程处于挂起状,这种方式我们称之为并发。
3)并发和并行区别
- 并发和并行是即相似又有区别的两个概念,并行是指两个或者多个事件在同一时刻同时执行,而并发是指两个或多个事件通过时间片轮流被执行。
- 在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,但在单核CPU中,同一时刻仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。
- 倘若在计算机中有多个CPU,则这些可以并发执行的程序便可被分配到多个处理机上,实现并行执行,即利用每个处理机来处理一个可并发执行的程序,这样,多个程序便可以同时执行。
三、Python 多线程
1)进程与线程关系
- 线程——线程是一个基本的CPU执行单元。它必须依托于进程存活。一个线程是一个execution context(执行上下文),即一个CPU执行时所需要的一串指令。
- 进程——进程是指一个程序在给定数据集合上的一次执行过程,是系统进行资源分配和运行调用的独立单位。可以简单地理解为操作系统中正在执行的程序。也就说,每个应用程序都有一个自己的进程。
- 每一个进程启动时都会最先产生一个线程,即主线程。然后主线程会再创建其他的子线程。即进程由一个或多个线程组成。
两者的区别
- 线程必须在某个进程中执行。
- 一个进程可包含多个线程,其中有且只有一个主线程。
- 多线程共享同个地址空间、打开的文件以及其他资源。
- 多进程共享物理内存、磁盘、打印机以及其他资源。
线程的因作用可以划分为不同的类型,大致可分为:
- 主线程
- 子线程
- 守护线程(后台线程)
- 前台线程
2)Python 多线程GIL介绍
其他语言,CPU是多核时是支持多个线程同时执行。但在Python中,无论是单核还是多核,同时只能由一个线程在执行。其根源是GIL的存在。GIL的全称是Global Interpreter Lock(全局解释器锁),来源是Python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个Python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。
而目前Python的解释器有多种,例如:
-
CPython:CPython是用C语言实现的Python解释器。 作为官方实现,它是最广泛使用的Python解释器。 -
PyPy:PyPy是用RPython实现的解释器。RPython是Python的子集, 具有静态类型。这个解释器的特点是即时编译,支持多重后端(C, CLI, JVM)。PyPy旨在提高性能,同时保持最大兼容性(参考CPython的实现)。 -
Jython:Jython是一个将Python代码编译成Java字节码的实现,运行在JVM (Java Virtual Machine) 上。另外,它可以像是用Python模块一样,导入并使用任何Java类。 -
IronPython:IronPython是一个针对 .NET 框架的Python实现。它可以用Python和 .NET framework的库,也能将Python代码暴露给 .NET框架中的其他语言。
重点注意事项:
-
GIL只在CPython中才有,而在PyPy和Jython中是没有GIL的。
-
每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。这就导致打印线程执行时长,会发现耗时更长的原因。
-
并且由于GIL锁存在,Python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,Python 的多线程效率并不高的根本原因。
3)Python 创建多线程
Python提供两个模块进行多线程的操作,分别是thread和threading(常用),前者是比较低级的模块,用于更底层的操作,一般应用级别的开发不常用。
1、thread
直接使用threading.Thread()。示例如下:
import threading
# 这个函数名可随便定义
def run(n):
print("current task:", n)
if __name__ == "__main__":
t1 = threading.Thread(target=run, args=("thread 1",))
t2 = threading.Thread(target=run, args=("thread 2",))
t1.start()
t2.start()
2、threading(常用)
继承threading.Thread来自定义线程类,重写run方法。示例如下:
import threading
class MyThread(threading.Thread):
def __init__(self, n):
super(MyThread, self).__init__() # 重构run函数必须要写
self.n = n
def run(self):
print("current task:", self.n)
if __name__ == "__main__":
t1 = MyThread("thread 1")
t2 = MyThread("thread 2")
t1.start()
t2.start()
4)守护线程
守护线程就是主线程执行完,子线程不管有没有执行完,都会跟着主线程结束。早期python版本可以这样设置:setDaemon(True),新版本这样设置:t.daemon=True,默认为False。
示例如下:
import threading
import time
def count(n, c):
while c > 0:
c -= 1
print("线程:{} 在执行n".format(n))
time.sleep(1)
if __name__ == "__main__":
t1 = threading.Thread(target=count, args=("t1", 3))
t2 = threading.Thread(target=count, args=("t2", 3))
t1.daemon = True
t2.daemon = True
t1.start()
t2.start()
# 将 t1 和 t2 加入到主线程中
#t1.join()
#t2.join()
# 主线程
print("主线程执行!")
执行结果如下:
线程:t1 在执行
线程:t2 在执行
主线程执行!
发现子线程并没有执行完就结束了。
5)线程合并(join)
join函数执行顺序是逐个执行每个线程,执行完毕后继续往下执行。主线程结束后,子线程还在运行,join函数使得主线程等到子线程结束时才退出。示例如下:
import threading
import time
def count(n, c):
while c > 0:
c -= 1
print("线程:{} 在执行n".format(n))
time.sleep(1)
if __name__ == "__main__":
t1 = threading.Thread(target=count, args=("t1", 3))
t2 = threading.Thread(target=count, args=("t2", 3))
t1.start()
t2.start()
# 将 t1 和 t2 加入到主线程中
#t1.join()
#t2.join()
# 主线程
print("主线程执行!")
先来看把join去掉之后的输出效果如下:
主线程执行!
线程:t1 在执行
线程:t2 在执行
线程:t1 在执行
线程:t2 在执行
线程:t1 在执行
线程:t2 在执行
加上join之后,效果如下:
线程:t1 在执行
线程:t2 在执行
线程:t2 在执行
线程:t1 在执行
线程:t1 在执行
线程:t2 在执行
主线程执行!
【结论】
- 守护线程(
t1.daemon)——就是主线程结束,子线程不管有没有执行完都会跟着主线程结束。 - 线程合并(
join)——主线程会等待所有子线程执行完之后再继续持续主线程。
6)线程同步与互斥锁
线程之间数据共享的。当多个线程对某一个共享数据进行操作时,就需要考虑到线程安全问题。threading模块中定义了Lock 类,提供了互斥锁的功能来保证多线程情况下数据的正确性。
用法的基本步骤:
#创建锁
mutex = threading.Lock()
#锁定
mutex.acquire([timeout])
#释放
mutex.release()
其中,锁定方法acquire可以有一个超时时间的可选参数timeout。如果设定了timeout,则在超时后通过返回值可以判断是否得到了锁,从而可以进行一些其他的处理。具体用法见示例代码:
import threading
import time
num = 0
mutex = threading.Lock()
class MyThread(threading.Thread):
def run(self):
global num
time.sleep(1)
if mutex.acquire(1):
num = num + 1
msg = self.name + ': num value is ' + str(num)
print(msg)
mutex.release()
if __name__ == '__main__':
for i in range(5):
t = MyThread()
t.start()
输出结果:
Thread-3: num value is 1
Thread-2: num value is 2
Thread-5: num value is 3
Thread-1: num value is 4
Thread-4: num value is 5
7)可重入锁(递归锁)
RLock 可重入锁是指同一个锁可以多次被同一线程加锁而不会死锁。 实现可重入锁的目的是防止递归函数内的加锁行为,或者某些场景内无法获取锁A是否已经被加锁,这时如果不使用可重入锁就会对同一锁多次重复加锁,导致立即死锁。
如果是一把互斥锁(threading.Lock()),那么下面的代码会发生堵塞:
import threading
lock = threading.Lock()
lock.acquire()
for i in range(10):
print('获取第二把锁')
lock.acquire()
print(f'test.......{i}')
lock.release()
lock.release()
输出结果:
获取第二把锁
发现执行上面的代码,会出现死锁状态。这是因为获取第二次锁的时候需要等待释放锁,导致死锁状态了。
再来看使用RLock的示例:
import threading
lock = threading.RLock()
lock.acquire()
for i in range(10):
print('获取第二把锁')
lock.acquire()
print(f'test.......{i}')
lock.release()
lock.release()
输出结果:
获取第二把锁
test.......0
获取第二把锁
test.......1
获取第二把锁
test.......2
获取第二把锁
test.......3
获取第二把锁
test.......4
获取第二把锁
test.......5
获取第二把锁
test.......6
获取第二把锁
test.......7
获取第二把锁
test.......8
获取第二把锁
test.......9
可能我们大部分人都知道,RLock其实底层维护了一个互斥锁和一个计数器,那互斥锁和计数器到底是如何工作的?
当一个线程通过acquire()获取一个锁时,首先会判断拥有锁的线程和调用acquire()的线程是否是同一个线程,如果是同一个线程,那么计数器+1,函数直接返回(return 1),如果两个线程不一致时,那么会通过调用底层锁(_allocate_lock())进行阻塞自己(也可能是获得锁)。
8)定时器
如果需要规定函数在多少秒后执行某个操作,需要用到Timer类。具体用法如下:
from threading import Timer
def show():
print("Pyhton")
if __name__ == "__main__":
# 指定一秒钟之后执行 show 函数
# 等待1s执行show函数
t = Timer(1, show)
t.start()
四、Python 多进程
Python要进行多进程操作,需要用到muiltprocessing库,其中的Process类跟threading模块的Thread类很相似。所以直接看代码熟悉多进程。
1)创建多进程
1、直接使用Process
示例如下:
from multiprocessing import Process
def show(name):
print("Process name is " + name)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.start()
proc.join()
输出结果:
Process name is subprocess
2、继承Process来自定义进程类,重写run方法
示例如下:
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name):
super(MyProcess, self).__init__()
self.name = name
def run(self):
print('process name :' + str(self.name))
time.sleep(1)
if __name__ == '__main__':
for i in range(3):
p = MyProcess(str(i))
p.start()
p.join()
输出结果:
process name :0
process name :1
process name :2
2)多进程通信
进程之间不共享数据的。如果进程之间需要进行通信,则要用到Queue模块或者Pipe模块来实现。
1、Queue
Queue是多进程安全的队列,可以实现多进程之间的数据传递。它主要有三个函数put()、get()和empty()。
-
put()用以插入数据到队列中,put还有两个可选参数:blocked和timeout。- 如果可选的参数block为True且timeout为空对象(默认的情况,阻塞调用,无超时)。
- 如果timeout是个正整数,阻塞调用进程最多timeout秒,如果一直无空空间可用,抛出Full异常(带超时的阻塞调用)。
- 如果block为False,如果有空闲空间可用将数据放入队列,否则立即抛出Full异常。
- 其非阻塞版本为put_nowait等同于put(item, False)。
-
get()可以从队列读取并且删除一个元素。同样get有两个可选参数:blocked和timeout。- 如果blocked为True(默认值),并且 timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。
- 如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常。
-
empty()如果队列为空,返回True,反之返回False·
示例如下:
from multiprocessing import Process, Queue
def put(queue):
queue.put('Queue 用法')
if __name__ == '__main__':
queue = Queue()
pro = Process(target=put, args=(queue,))
pro.start()
print(queue.get())
pro.join()
2、Pipe
多进程还有一种数据传递方式叫做管道(Pipe),和Queue相类似。Pipe可以在进程之间创建一条管道,并返回元组(con1,con2)。其中,con1,con2表示管道两端的连接对象。这里要注意,必须在产生Process对象之前产生管道,具体用法如下:
-
send(obj):通过连接发送对象obj -
recv():接收con2.send(obj)所发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果接收的一端已经关闭连接,则抛出EOFError -
close():关闭连接。如果con1被垃圾回收,将自动调用此方法。 -
fileno():返回连接使用的整数文件描述符 -
poll([timeout]):如果连接上的数据可用,返回True。timeout为指定等待的最长时限,若timeout缺省,方法立即返回结果,不再等待。若timeout值为None,则操作将无限制等待数据到来。 -
send_bytes(buffer[,offset[,size]]):通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,size是要发生的字节数。结果以单条消息的形式发出,然后使用recv_bytes()进行接收。
from multiprocessing import Process, Pipe
def show(conn):
conn.send('Pipe 用法')
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
pro = Process(target=show, args=(child_conn,))
pro.start()
print(parent_conn.recv())
pro.join()
【温馨提示】调用Pipe()返回管道的两端的Connection,因此, Pipe仅仅适用于只有两个进程一读一写的单双工情况,也就是说信息是只向一个方向流动。例如电视、广播,看电视的人只能看,电视台是能播送电视节目。
【总结】
- Pipe的读写效率要高于Queue。
- 进程间的Pipe基于fork机制建立。
- 当主进程创建Pipe的时候,Pipe的两个Connections连接的的都是主进程。
当主进程创建子进程后,Connections也被拷贝了一份。此时有了4个Connections。 - 此后,关闭主进程的一个Out Connection,关闭一个子进程的一个In Connection。那么就建立好了一个输入在主进程,输出在子进程的管道。
3)进程池
创建多个进程,我们不用傻傻地一个个去创建。我们可以使用Pool模块来搞定。Pool 常用的方法如下:
| 方法 | 含义 |
|---|---|
| apply() | 同步执行(串行) |
| apply_async() | 异步执行(并行) |
| terminate() | 立刻关闭进程池 |
| join() | 主进程等待所有子进程执行完毕。必须在close或terminate()之后使用 |
| close() | 等待所有进程结束后,才关闭进程池 |
示例如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import multiprocessing
import time
def func(msg):
print("msg:", msg)
time.sleep(3)
print("end")
if __name__ == "__main__":
# 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool = multiprocessing.Pool(processes = 3)
for i in range(5):
msg = "hello %d" %(i)
# 非阻塞式,子进程不影响主进程的执行,会直接运行到 pool.join()
pool.apply_async(func, (msg, ))
# 阻塞式,先执行完子进程,再执行主进程
# pool.apply(func, (msg, ))
print("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
# 调用join之前,先调用close函数,否则会出错。
pool.close()
# 执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
pool.join()
print("Sub-process(es) done.")
输出结果:
Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~
msg: hello 0
msg: hello 1
msg: hello 2
end
msg: hello 3
end
msg: hello 4
end
end
end
Sub-process(es) done.
- 如上,进程池Pool被创建出来后,即使实际需要创建的进程数远远大于进程池的最大上限,
p.apply_async(test)代码依旧会不停的执行,并不会停下等待;相当于向进程池提交了10个请求,会被放到一个队列中; - 当执行完p1 = Pool(5)这条代码后,5条进程已经被创建出来了,只是还没有为他们各自分配任务,也就是说,无论有多少任务,实际的进程数只有5条,计算机每次最多5条进程并行。
- 当Pool中有进程任务执行完毕后,这条进程资源会被释放,pool会按先进先出的原则取出一个新的请求给空闲的进程继续执行;
- 当Pool所有的进程任务完成后,会产生5个僵尸进程,如果主线程不结束,系统不会自动回收资源,需要调用join函数去回收。
- join函数是主进程等待子进程结束回收系统资源的,如果没有join,主程序退出后不管子进程有没有结束都会被强制杀死;
- 创建Pool池时,如果不指定进程最大数量,默认创建的进程数为系统的内核数量。
4)多线程和多进程如何选择?
在这个问题上,首先要看下你的程序是属于哪种类型的。一般分为两种:CPU密集型和I/O密集型。
-
CPU 密集型(计算型):程序比较偏重于计算,需要经常使用CPU来运算。例如科学计算的程序,机器学习的程序等。(最好使用进程,因为python现在同一时刻只能由一个线程在执行,具体原因看上面解释)
-
I/O 密集型:顾名思义就是程序需要频繁进行输入输出操作。爬虫程序就是典型的I/O密集型程序。(最好使用线程,因为涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少。)
五、Python 之 signal 模块
signal模块负责python程序内部的信号处理;典型的操作包括信号处理函数、暂停并等待信号,以及定时发出SIGALRM等。
尽管signal是python中的模块,但是主要针对UNIX平台(比如Linux,MAC OS),而Windows内核中由于对信号机制的支持不充分,所以在Windows上的Python不能发挥信号系统的功能。
1)发生信号的原因
发送信号一般有两种原因:
- 被动式:内核检测到一个系统事件.例如子进程退出会像父进程发送SIGCHLD信号.键盘按下control+c会发送SIGINT信号。
- 主动式:通过系统调用kill来向指定进程发送信号。
2)信号处理方式
接收信号的进程对不同的信号有三种处理方式:
- 指定处理函数
- 忽略
- 根据系统默认值处理, 大部分信号的默认处理是终止进程
3)规则信号
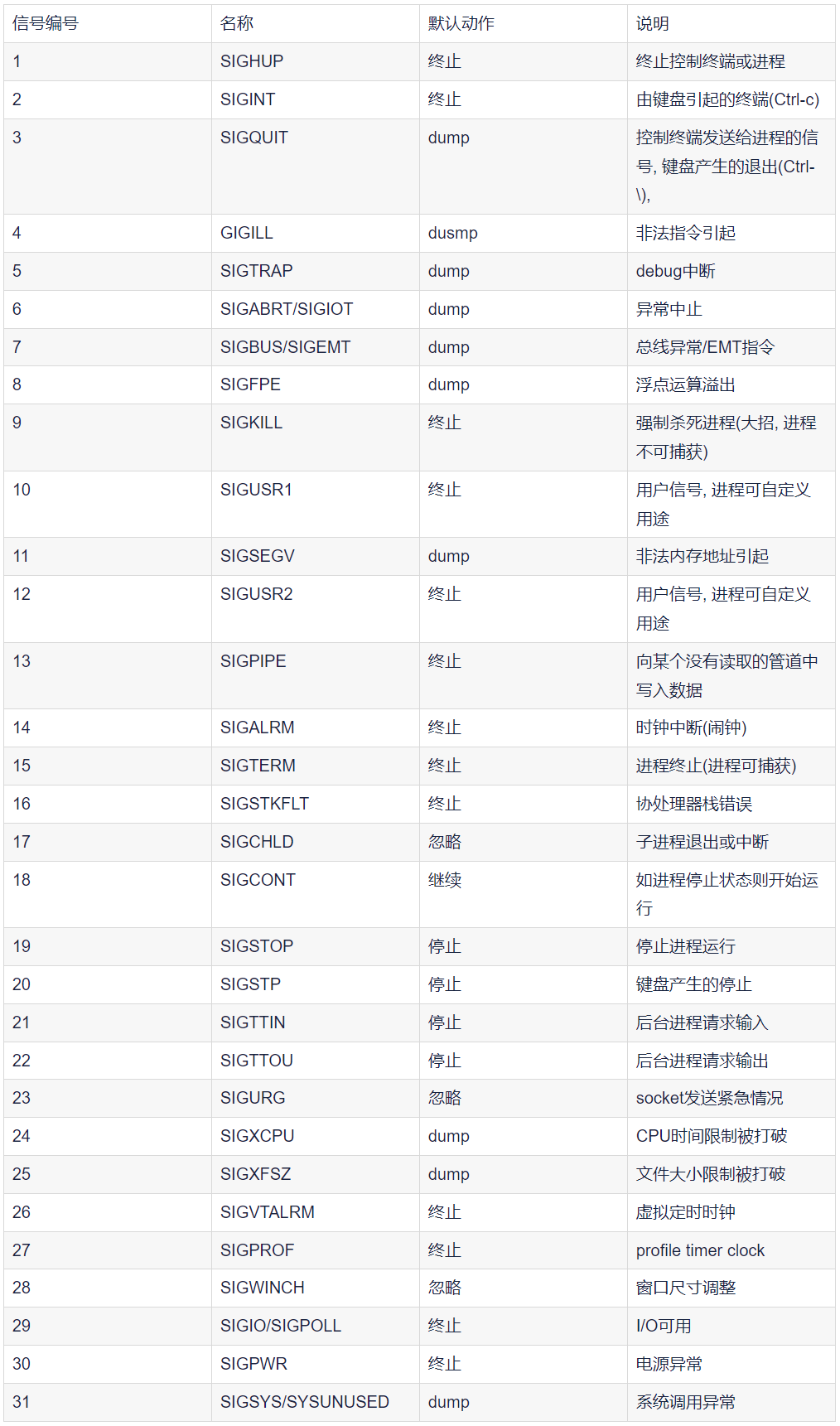
常用的信号:
signal.SIGHUP # 连接挂断;
signal.SIGILL # 非法指令;
signal.SIGINT # 终止进程(ctrl+c);
signal.SIGTSTP # 暂停进程(ctrl+z);
signal.SIGKILL # 杀死进程(此信号不能被捕获或忽略);
signal.SIGQUIT # 终端退出;
signal.SIGTERM # 终止信号,软件终止信号;
signal.SIGALRM # 闹钟信号,由signal.alarm()发起;
signal.SIGCONT # 继续执行暂停进程;
【温馨提示】
- 由于不同系统中同一个数值对应的信号类型不一样, 所以最好使用信号名称。
- 在
wnidows系统中只能调用SIGABRT,SIGFPE,SIGILL, SIGINT,SIGSEGV, orSIGTERM。 - 信号的数值越小, 优先级越高。
3)signal.alarm(time)
-
参数:time为时间参数
-
功能:在time时间后,向进程自身发送
SIGALRM信号
示例如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 注意:在UNIX平台上执行,window没有alarm()方法
import signal
import time
signal.alarm(4)#4s后终止程序
while True:
time.sleep(1)
print("学习python中...")
输出结果:
学习python中...
学习python中...
学习python中...
Alarm clock
4)signal.pasue()
signal.pause() Wait until a signal arrives。让进程进程暂停,以等待信号(什么信号均可);也即阻塞进程进行,接收到信号后使进程停止。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import signal
import time
time.sleep(1)
#阻塞等待信号的发生,如论什么信号都可以
signal.pause()
while True:
time.sleep(1)
print("学习python中...")
5)设置信号处理函数
signal.signal(sig, handler)
功能:按照handler制定的信号处理方案处理函数
参数:
-
sig:拟需处理的信号,处理信号只针对这一种信号起作用sig -
hander:信号处理方案
在信号基础里提到,进程可以无视信号、可采取默认操作、还可自定义操作;当handler为下列函数时,将有如下操作:
-
SIG_IGN:信号被无视(ignore)或忽略 -
SIG_DFL:进程采用默认(default)行为处理
示例如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import signal
#6s后终止程序
signal.alarm(6)
#遇到SIGINT ctrl+c时,忽略SIG_IGN
signal.signal(signal.SIGINT,signal.SIG_IGN)
signal.pause()
运行后6s 打印出: Alarm clock
如果在运行中在键盘中输入CTRL+C也无济于事,此时输出结果 CCCCCCCC闹钟
原因分析:
-
signal.signal(signal.SIGINT, signal.SIG_IGN) 表示遇到信号SIGINT CTRL + C,时,忽略SIG_IGN该信号。所以在程序运行中从键盘输入ctrl+c(在终端上显示 ^C )时无效。
-
当signal.alarm(6)计时6秒后,直接在终端上输出 “Alarm clock” 后退出。
-
signal.pause()是为了阻塞进程,等待信号。如果没有这句话,可以在程序中更变为:
while True:
pass
进程中默认信号方式处理:
import signal
#6s后终止程序
signal.alarm(6)
signal.signal(signal.SIGALRM,signal.SIG_DFL)
signal.pause()
六、并发网络通信模型
常见网络模型:
-
循环服务器模型——循环接受客户端请求,处理请求.同一时刻只能处理一个请求,处理完毕后在处理下一个。
- 优势:实现简单,占用资源少服务器。
- 缺点:没法同时处理多个客户端请求网。
- 适用状况:处理的任务能够很快完成,客户端无需长期占用服务端程序.UDP比TCP更适合循环多线程。
-
多进程/线程网络并发模型——每当一个客户端链接服务器,就建立一个新的进程/线程为该客户端服务,客户端退出时在销毁该进程/线程。
- 优势:能同时知足多个客户端长期占有服务端需求,能够处理各类请求并发。
- 缺点:资源消耗较大异步。
- 适用状况:客户端同时链接量较少,须要处理行为较复杂场景。
-
IO并发模型——利用IO多路复用,异步IO等技术,同时处理多个客户端IO请求
- 优势:资源消耗少,能同时高效处理多个IO行为。
- 缺点:只能处理并发产生的IO事件,没法处理CPU计算函数。
- 适用状况:HTTP请求,网络传输等都是IO行为。
1)基于fork的多进程网络并发模型
实现步骤:
- 建立监听套接字;
- 等待接受客户端请求;
- 客户端链接建立新的进程处理客户端请求;
- 原进程继续等待其余客户端链接;
- 若是客户端退出,则销毁对应的进程。
示例如下:
import socket
import signal
import os
# 全局变量
HOST = "127.0.0.1"
PORT = 9090
ADDR = (HOST, PORT)
def dispose(val):
while True:
data = val.recv(1024)
if not data:
break
print(">>", data.decode())
val.send(b"OK")
val.close()
# 创建套接字
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口立即重用
soc.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定套接字
soc.bind(ADDR)
# 设置监听
soc.listen(5)
# 处理僵尸进程
signal.signal(signal.SIGCHLD, signal.SIG_IGN)
print("Listen the port 9090...")
while True:
# 循环处理客户端连接
try:
c, addr = soc.accept()
print("Connect from", addr)
except KeyboardInterrupt:
os._exit(0)
except Exception as e:
print(e)
continue
# 创建子进程处理客户端事物
pid = os.fork()
if pid == 0:
soc.close()
# 客户端套接字处理具体事物
dispose(c)
# 处理完成销毁子进程
os._exit(0)
else:
# 父进程等待其他用户连接不需要和子进程通信
c.close()
2)基于threading的多线程网络并发
实现步骤
- 建立监听套接字;
- 等待接收客户端请求;
- 客户端链接建立新的线程处理客户端请求;
- 主线程继续等待其余客户端链接;
- 若是客户端退出,则对应分支线程退出。
示例如下:
from socket import *
from threading import Thread
import sys
# 创建监听套接字
HOST = '0.0.0.0'
PORT = 8888
ADDR = (HOST,PORT)
# 处理客户端请求
def handle(c):
while True:
data = c.recv(1024)
if not data:
break
print(data.decode())
c.send(b'OK')
c.close()
s = socket() # tcp套接字
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind(ADDR)
s.listen(3)
print("Listen the port %d..."%PORT)
# 循环等待客户端连接
while True:
try:
c,addr = s.accept()
except KeyboardInterrupt:
sys.exit("服务器退出")
except Exception as e:
print(e)
continue
# 创建线程处理客户端请求
t = Thread(target=handle, args=(c,))
t.setDaemon(True) # 父进程结束则所有进程终止
t.start()
文章篇幅有点长,上面的示例用到了socket,等到讲到socket再详细解释,socket就放到下篇文章介绍了,请小伙伴耐心等待~
Python 高级编程之并发与多线程就先介绍到这里,有疑问的小伙伴欢迎给我留言,后续会持续更新相关技术文章,也可关注我的公众号【大数据与云原生技术分享】深入技术交流~
最后
以上就是风趣超短裙最近收集整理的关于Python 高级编程之并发与多线程(三)的全部内容,更多相关Python内容请搜索靠谱客的其他文章。








发表评论 取消回复