2.3 pip的使用和虚拟环境的介绍
pip 是一个现代的,通用的 Python 包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能。
官方提供的pip 示例
$ pip install requests
pip 换源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
虚拟环境
在开发过程中,当需要使用python的某些工具包/框架时需要联网安装,如果在一台电脑上,想开发多个不同的项目, 需要用到同一个包的不同版本, 如果使用上面的命令, 在同一个目录下安装或者更新, 新版本会覆盖以前的版本, 其它的项目就无法运行了。
所以为了环境之间的库相互不影响,标准库不受到污染,一般开发过程中,我们会引入虚拟环境。虚拟环境可以搭建独立的Python运行环境,使得单个项目的运行环境与其他项目互不影响。
1.如何搭建虚拟环境?
-
安装虚拟环境及管理工具
pip install virtualenv pip install virtualenvwrapper # linux pip install virtualenvwrapper-win #Windows使用该命令 -
linux(win跳过)
# 1、在~(家目录)下创建目录用来存放虚拟环境 mkdir .virtualenvs # 2、打开~/.bashrc文件,并添加如下: export WORKON_HOME=$HOME/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh # 3、运行 source ~/.bashrc -
virtualenvwrapper基本使用
-
创建虚拟环境 mkvirtualenv
mkvirtualenv venv (venv是虚拟环境的名称) -
基本命令
workon (不加参数查看当前所有的虚拟环境,加具体的虚拟环境则切换至该环境)- 查看虚拟环境
[root@localhost ~]# workon py2 py3- 切换虚拟环境
[root@localhost ~]# workon py3 (py3) [root@localhost ~]#- 退出虚拟环境
(py3) [root@localhost ~]# deactivate [root@localhost ~]#- 删除虚拟环境
rmvirtualenv venv -
2.4 reuqests库介绍
1.为什么要重点学习requests模块,而不是urllib
-
urllib是python中的一个标准库可以用来请求网络资源,但其工序操作比较繁杂。
-
requests库是urllib的一个封装库,操作简单
-
requests在python2 和python3中通用,方法完全一样
-
Requests能够自动帮助我们解压(gzip压缩的等)响应内容
2.第一个爬虫程序(案例一)
- 爬取目标: http://www.baidu.com
- 我们通过 ipython 来进行演示
pip install ipython # 安装ipython
pip install requests # 安装requests库
- 启动 ipython ,通过命令行进入虚拟环境,安装好ipython和requests库后,输入ipython进入ipython环境
In [1]: import requests
In [2]: requests.get("http://www.baidu.com")
Out[2]: <Response [200]>
In [3]: response = requests.get("http://www.baidu.com")
In [4]: response.text
Out[4]: '<!DOCTYPE html>rn<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>çx99¾åº¦ä¸x80ä¸x8bï¼x8cä½xa0å°±çx9f¥éx81x93</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=çx99¾åº¦ä¸x80ä¸x8b class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æx96°éx97»</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>åx9c°åx9b¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§x86é¢x91</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´åx90§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>çx99»å½x95</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">çx99»å½x95</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æx9b´å¤x9a产åx93x81</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>åx85³äºx8eçx99¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使çx94¨çx99¾åº¦åx89x8då¿x85读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æx84x8fè§x81åx8fx8dé¦x88</a> 京ICPè¯x81030173åx8f· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>rn'
步骤:
-
导入requests库 import requests
-
发送请求并接收响应 response = rquests.get(url)
-
解析响应 response.txt
response的常用属性:
response.text响应体 str类型respones.content响应体 bytes类型response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.request.cookies响应对应请求的cookieresponse.cookies响应的cookie(经过了set-cookie动作)
3. response.text 和response.content的区别
response.text- 类型:str
- 解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- 如何修改编码方式:
response.encoding=”gbk”
response.content- 类型:bytes
- 解码类型: 没有指定
- 如何修改编码方式:
response.content.decode(“utf8”)
获取网页源码的通用方式:
response.content.decode()response.content.decode("GBK")response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.decode()的方式获取响应的html页面
案例二:
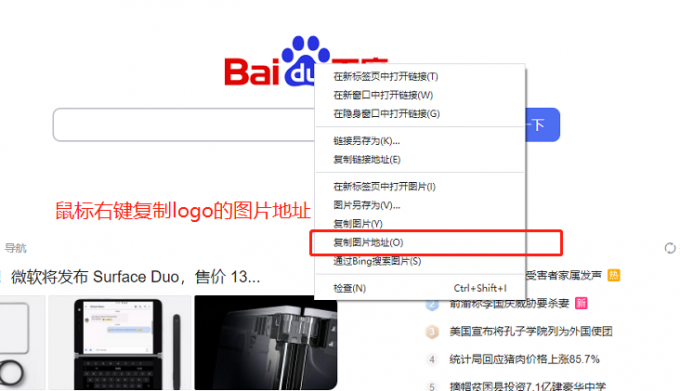
爬取目标:百度的logo
演示使用:pycharm
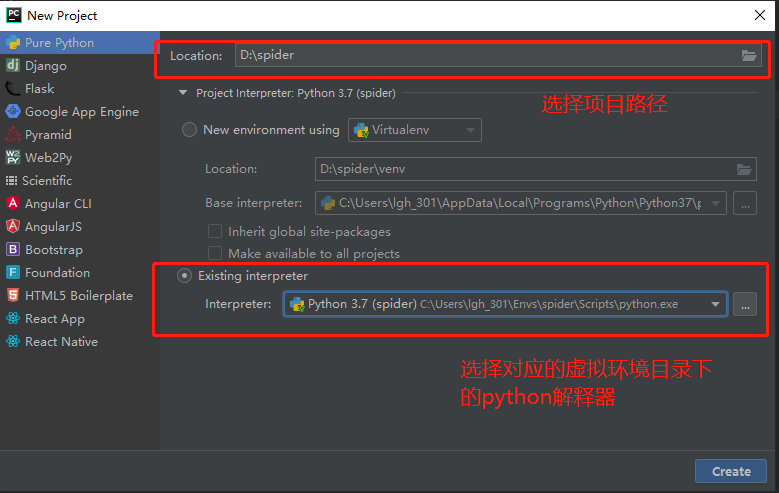
- 查看虚拟环境是否搭载成功
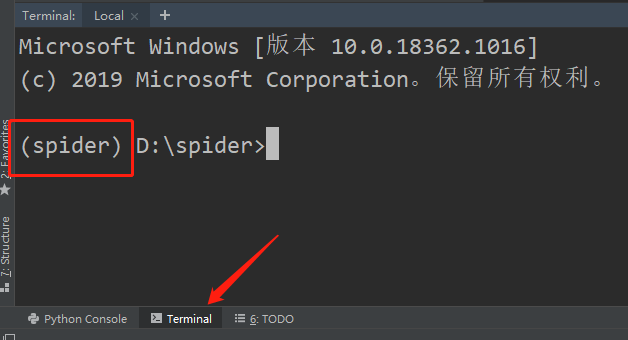
- 根据需要创建目录结构以及文件
-
在虚拟环境中安装requests库

-
编写程序
-
首先我们要确定url
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/8/14 13:45
# @Author : GHong
import requests
url = "https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png" # 确定百度logo的url
response = requests.get(url) # 发送请求接收响应
# 解析响应
img = response.content
# 保存数据资源
with open("../sources/image/baidu_logo.png", "wb") as f:
f.write(img)

最简单爬虫流程总结:
- 确定具体资源url
- 发起请求,接收响应
- 解析响应
- 保存数据
2.5 发送带有header的的请求
1.查看请求头和响应头
import requests
response = requests.get("http://www.baidu.com")
# 查看请求头和响应头
print("请求头:", response.request.headers)
print("=" * 35)
print("响应头:", response.headers)

请求头: {'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
===================================
响应头: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Fri, 14 Aug 2020 06:05:10 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:57 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
‘User-Agent’: ‘python-requests/2.24.0’ # 用户代理
‘Accept-Encoding’: ‘gzip, deflate’ # 编码信息
-
反扒点一:代理反爬
在前面的学习中,我们了解了robots协议,上边规定了哪些用户代理可以获取数据,哪些用户代理不能获取数据,这里的用户代理 (User-Agent) 就是一个重要的参数,很多网站都会用这个来阻止爬虫获取响应。
-
User-Agent 的作用就是告诉服务器,我是用什么浏览器来访问你的网站的,如果对方的服务器中布置了代码对请求的User-Agent进行监控,阻挡了一部分的爬虫程序,一些名字为Spider的爬虫就无法再访问该网站的资源,这个反爬已经被绝大部分开发者所熟知,所以很多网站都不做User-Agent拦截,以免造成真正用户的误伤。
-
User-Agent 伪装 (披着羊皮的狼)
案例三:
import requests
response = requests.get("http://www.baidu.com")
print("伪装前的User-Agent:", response.request.headers["User-Agent"])
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"} # 告诉百度的服务器,我是谷歌浏览器
response = requests.get("http://www.baidu.com", headers=headers)
print("伪装后的User-Agent:", response.request.headers["User-Agent"])
伪装前的User-Agent: python-requests/2.24.0
伪装后的User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36
总结:
header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法
requests.get(url, headers=headers)
通过浏览器检查代开控制台,在抓包出可以看到浏览器的User-Agent,再此处复制过来用即可
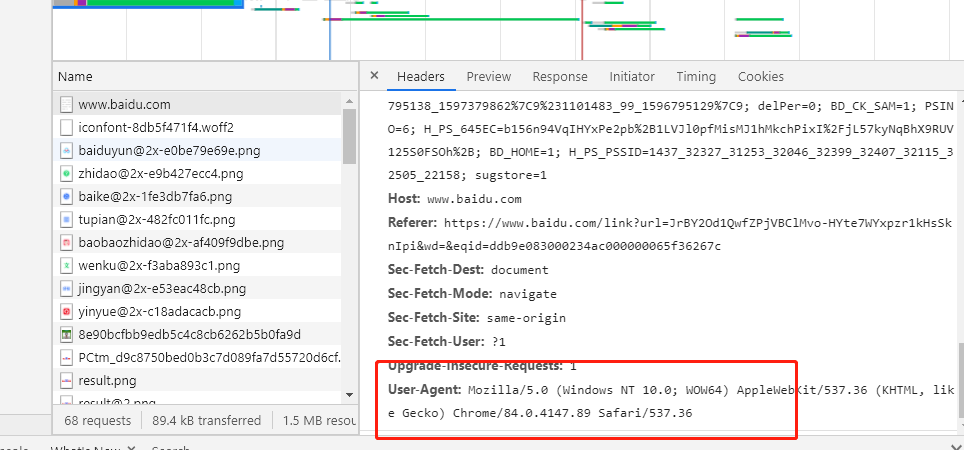
总结:通过headers参数来做伪装欺骗服务器
- headers 的值是一个字典,其内部的属性是一个个的键值对
- 通过headers参数可以将我们的headers传递给请求,披上羊皮就是羊了
2.6 发送带参数的请求
1.参数介绍
我们在使用百度搜索的时候经常发现url地址中会有一个 ?,那么该问号后边的就是请求参数,又叫做查询字符串
[https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=reques%E5%BA%93&oq=python%25E8%2599%259A%25E6%258B%259F%25E7%258E%25AF%25E5%25A2%2583&rsv_pq=dfa9a62100001b21&rsv_t=fa2cqIfxcw0879rrylW9bU0QPR2n1QC1yabVcT66zoeiKvucSugwbmeyJAw&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=11&rsv_sug1=14&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=8345&rsv_sug4=8344]
什么叫做请求参数:
例1: http://www.webkaka.com/tutorial/server/2015/021013/
例2:https://www.baidu.com/s?wd=python&a=c
例1中没有请求参数!例2中?后边的就是请求参数
请求参数的形式:字典
kw = {'wd':'长城'}
请求参数的用法
requests.get(url,params=kw)
关于参数的注意点
在url地址中, 很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除 如何确定那些请求参数有用或者没用:挨个尝试! 对应的,在后续的爬虫中,越到很多参数的url地址,都可以尝试删除参数
没有用的参数尽可能的删除,只要不影响数据的爬取一律删除,保持代码的整洁性,如果所有的参数都是必要的,或者必要参数过多就用字典生成式进行参数字典生成
案例四
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/8/14 14:34
# @Author : GHong
import requests
url = "https://www.baidu.com/s?" # 确定url为百度
# 构建查询参数,通过观察发现其搜索的参数为wd
wd = input("请输入你要查询的信息:")
params = {}
params["wd"] = wd
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"} # 告诉百度的服务器,我是谷歌浏览器
response = requests.get(url, params=params, headers=headers)
# print(response.content.decode())
with open("../sources/file/baidu=%s.html" % wd, "w", encoding="utf8") as f:
f.write(response.content.decode())
- 这个案例中我们首先通过真实的浏览器进行观察发现只有wd是百度搜索的必要关键字
- 随后我们进行了数据尝试爬取,发现百度并没有给我们返回我们想要的数据
- 然后我们加入User-Agent 伪装,然后再次尝试数据爬取
- 这一次百度服务器返回了我们需要的数据,数据抓取成功
- 进行数据保存,为.html文件,打开验证
练习1
- 爬取新浪的首页,以Html的形式保存 【难度:0.5星】
- 爬取百度贴吧,要求实现可以爬取任何贴吧,的任何页数的全部内容【难度 1星】
练习参考答案 提取码:htgy
阶段小结
- requests模块的介绍:能够帮助我们发起请求获取响应
- requests的基本使用:
requests.get(url) - 以及response常见的属性:
response.text响应体 str类型respones.content响应体 bytes类型response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.request._cookies响应对应请求的cookieresponse.cookies响应的cookie(经过了set-cookie动作)
- 掌握 requests.text和content的区别:text返回str类型,content返回bytes类型
- 掌握 解决网页的解码问题:
response.content.decode()response.content.decode("GBK")response.text
- 掌握 requests模块发送带headers的请求:
requests.get(url, headers={}) - 掌握 requests模块发送带参数的get请求:
requests.get(url, params={})
2.7 reuqests的深入使用
-
上一阶段我们学习了如何使用requests发送get请求
-
如何进行用户代理伪装
-
以及如何设置查询参数
-
还有响应的集中类型
-
响应的状态码等
这一节,我们讲解如何使用requests库来发送POST请求,如何爬取需要登录等网站等
- 能够应用requests发送post请求的方法
- 能够应用requests模块使用代理的方法
- 了解代理ip的分类
1.使用requests发送POST请求
思考:哪些地方我们会用到POST请求?
- 登录注册( POST 比 GET 更安全)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
1.1 requests发送post请求语法:
-
用法:
response = requests.post("http://www.baidu.com/", data = data,headers=headers) -
data 的形式:字典
案例五=>百度翻译
第一步找到相关链接:通过浏览器抓包找到目标url
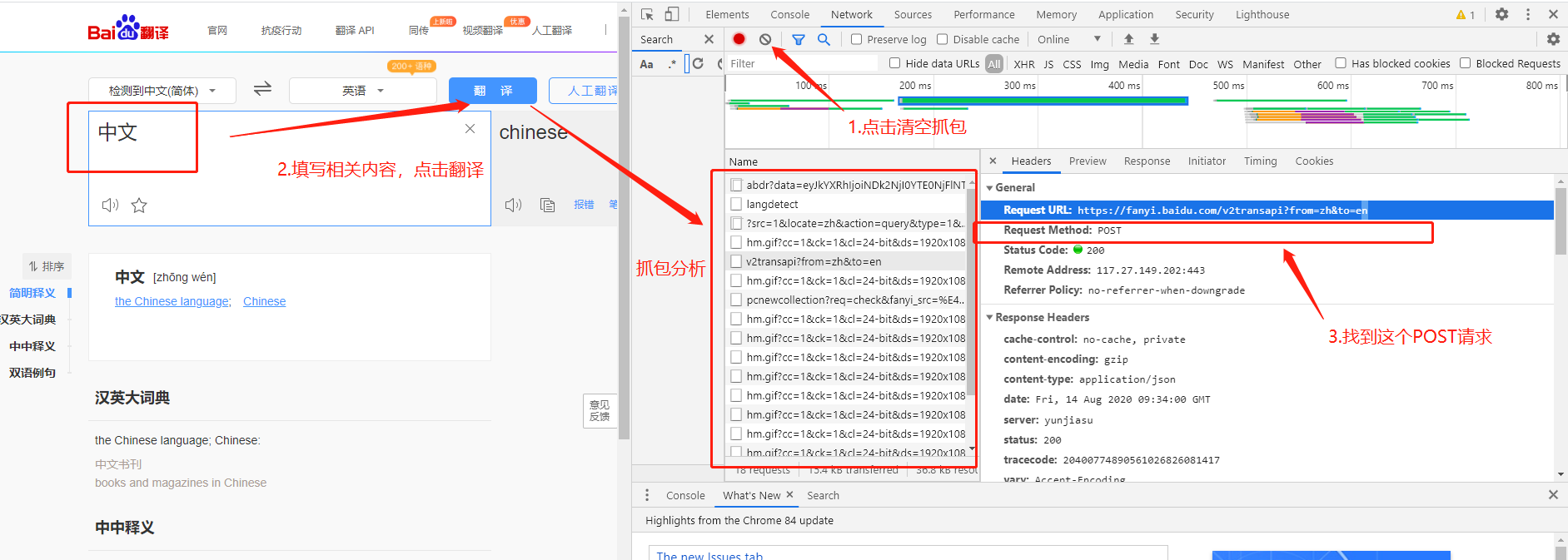
第二步分析数据表单
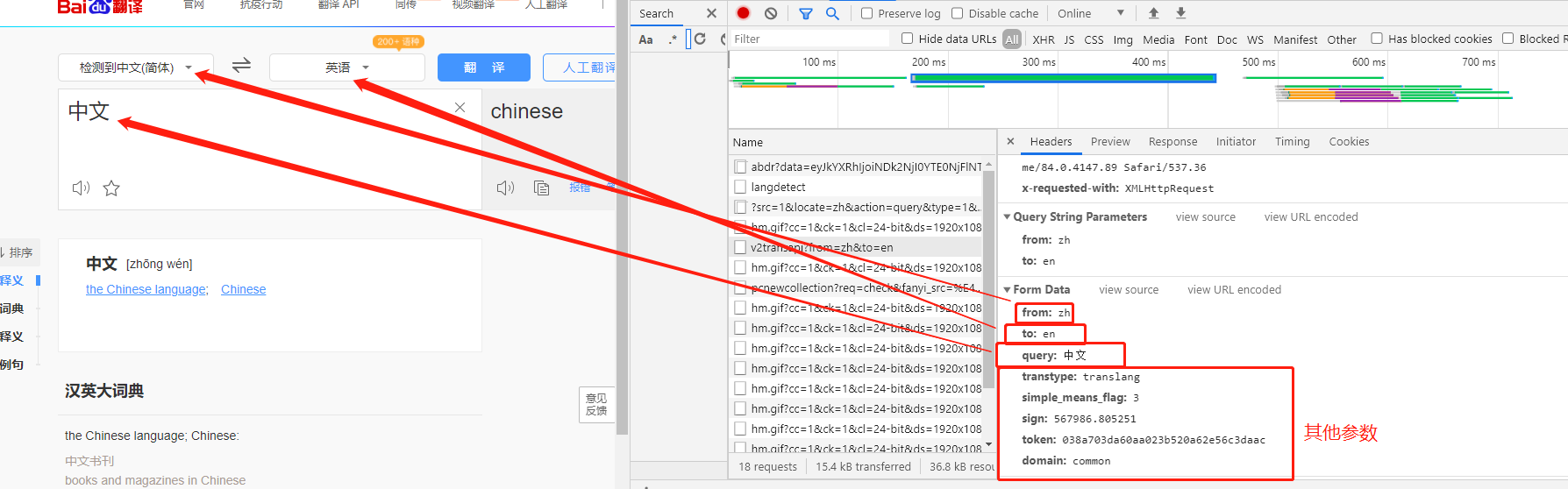
第三步尝试进行爬取
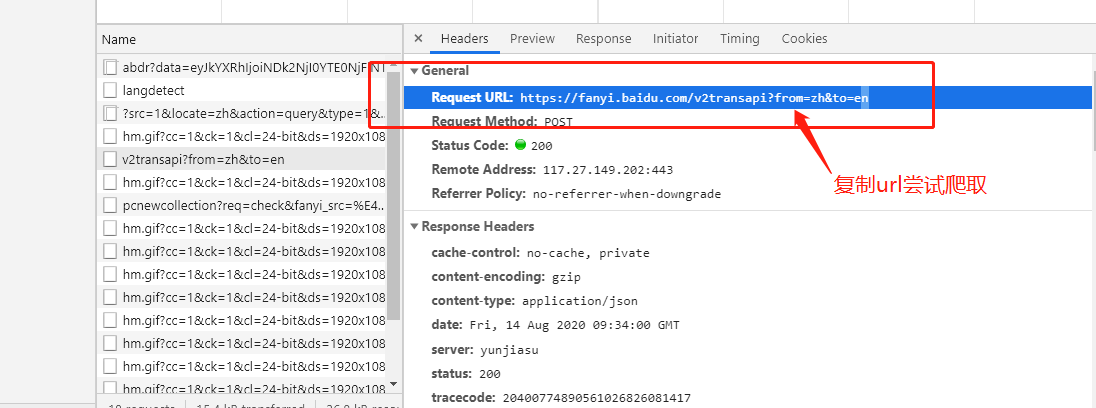
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/8/14 17:44
# @Author : GHong
import requests
# 确定目标url
url = "https://fanyi.baidu.com/v2transapi?from=zh&to=en"
data = {
"from": "zh",
"to": "en",
"query": "中文",
"transtype": "translang",
"simple_means_flag": 3,
"sign": 567986.805251,
"token": "038a703da60aa023b520a62e56c3daac",
"domain": "common"
}
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"cookie": "BIDUPSID=67C436ADF5878B8C8473920E4991735D; PSTM=1583145438; BAIDUID=67C436ADF5878B8CD8FC329F6003854F:FG=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; H_WISE_SIDS=139914_144981_142018_144884_141877_141748_145498_144134_145271_144470_144483_131246_144682_137749_144742_138883_140259_141941_127969_140066_144791_140595_142420_143491_143923_144484_131424_100805_142206_145522_145351_107316_145611_139910_144568_144306_143477_144966_142427_142911_140312_145424_143549_144160_142507_144017_145399_143854_110085; MCITY=-257%3A; BDUSS=TdXNXR2WXl2eEl1a0FxekhhZmJCZmxhVkh-b1J1T3B2d3pDNVJlbmxDdHpJVlpmSVFBQUFBJCQAAAAAAAAAAAEAAACOkPqdvPu57bXEyMtiYrWwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHOULl9zlC5fR; BDUSS_BFESS=TdXNXR2WXl2eEl1a0FxekhhZmJCZmxhVkh-b1J1T3B2d3pDNVJlbmxDdHpJVlpmSVFBQUFBJCQAAAAAAAAAAAEAAACOkPqdvPu57bXEyMtiYrWwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHOULl9zlC5fR; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=6; H_PS_PSSID=1437_32539_32327_31253_32046_32399_32407_32115_32505_32481_22158; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1597395475; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1597397619; __yjsv5_shitong=1.0_7_821f0d690902ea5bc7f01368695d4f62d31b_300_1597397618595_113.65.230.142_172b5b7b; yjs_js_security_passport=753c00e4926b4060ccd3c73a3d2d96a0f9fab9b8_1597397620_js"
}
response = requests.post(url, data=data, headers=headers)
print(response.content.decode())
爬取过程分析:
- 抓包确定url
- 将表单数据构建好,发起请求,发现返回数据不是我们预期的。
- 于是我们第二次加上user-Agent进行伪装,依旧没有返回预期数据
- 第三次我们加入Cookie信息,这次成功获取到了数据
返回数据是个JSON类型,这里我们可以通过
网站进行JSON数据结构分析:传送门
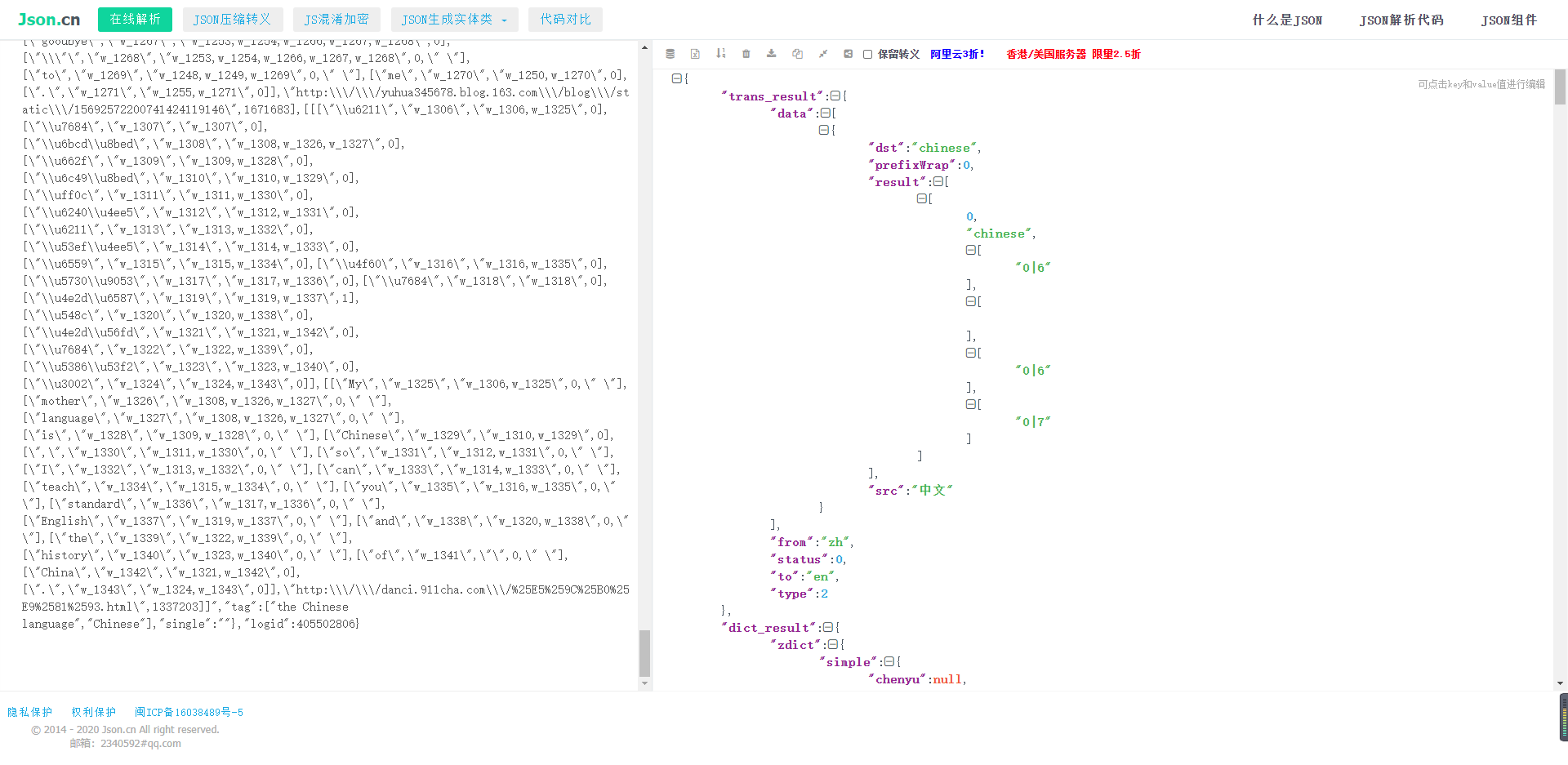
通过对返回结果的数据结构分析,结果如下

- 我们发现我们想要的数据在data下边的dst中
- 这时候我们可以通过JSON这个python内置的标准库进行数据的提取
-
from json import loads # 通过JSON包中导入loads模块
import requests
from json import loads
# 确定目标url
url = "https://fanyi.baidu.com/v2transapi?from=zh&to=en"
data = {
"from": "zh",
"to": "en",
"query": "中文",
"transtype": "translang",
"simple_means_flag": 3,
"sign": 567986.805251,
"token": "038a703da60aa023b520a62e56c3daac",
"domain": "common"
}
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"cookie": "BIDUPSID=67C436ADF5878B8C8473920E4991735D; PSTM=1583145438; BAIDUID=67C436ADF5878B8CD8FC329F6003854F:FG=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; H_WISE_SIDS=139914_144981_142018_144884_141877_141748_145498_144134_145271_144470_144483_131246_144682_137749_144742_138883_140259_141941_127969_140066_144791_140595_142420_143491_143923_144484_131424_100805_142206_145522_145351_107316_145611_139910_144568_144306_143477_144966_142427_142911_140312_145424_143549_144160_142507_144017_145399_143854_110085; MCITY=-257%3A; BDUSS=TdXNXR2WXl2eEl1a0FxekhhZmJCZmxhVkh-b1J1T3B2d3pDNVJlbmxDdHpJVlpmSVFBQUFBJCQAAAAAAAAAAAEAAACOkPqdvPu57bXEyMtiYrWwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHOULl9zlC5fR; BDUSS_BFESS=TdXNXR2WXl2eEl1a0FxekhhZmJCZmxhVkh-b1J1T3B2d3pDNVJlbmxDdHpJVlpmSVFBQUFBJCQAAAAAAAAAAAEAAACOkPqdvPu57bXEyMtiYrWwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHOULl9zlC5fR; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=6; H_PS_PSSID=1437_32539_32327_31253_32046_32399_32407_32115_32505_32481_22158; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1597395475; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1597397619; __yjsv5_shitong=1.0_7_821f0d690902ea5bc7f01368695d4f62d31b_300_1597397618595_113.65.230.142_172b5b7b; yjs_js_security_passport=753c00e4926b4060ccd3c73a3d2d96a0f9fab9b8_1597397620_js"
}
response = requests.post(url, data=data, headers=headers)
json_data = response.content.decode()
dict_data = loads(json_data) # 通过dumps将JSON转换为字典
# print(dict_data["data"]["dst"]) # KeyError: 'data' 第一次尝试他说没有data这个键
# print(dict_data) # 通过观察解析的字典我们发现外边套多了一层 'trans_result'
# print(dict_data["trans_result"]["data"]) # 我们发现这一层是一个列表,取0号位索引
print(dict_data["trans_result"]["data"][0]["dst"]) # 终于拿到了我们想要的结果
爬取案例解析:
- 首先我们要确定真正的URL是哪一个
- 然后开始第一次爬取尝试,构建POST请求表单数据,第一次被反爬
- 加上User-Agent 再次尝试爬取,第二次被反爬
- 加上cookie 成功爬取到相关信息,返回数据格式为JSON
- 在JSON包中导入loads模块进行数据转化,JSON ==> dict 字典
- 分析返回结果JSON的数据结构,经过层层剖析我们发下,最外层是一个字典,通过键 trans_result 获取值
- 第二层是一个字典,通过data关键字取出我们需要的值
- 第三层是一个列表,通过0号位索引取出值
- 第四层就是我们的目标值,到此为止解析完成
- 把表单query关键字改成动态参数传输,一个通过爬虫调用百度翻译的中译英翻译接口**【拿来即用,爬虫有风险使用需谨慎】**
练习2
- 人人网登录爬取练习【难度1星】
- 学校课表爬取,自己爬取自己的课表【华软,难度:3.5 星】
参考答案 提取码:0a0j
小结:
-
网站的url并不一定是我们的真正的目标url
-
POST请求表单数据传输通过data参数
-
简单反反爬技术:
-
第一步:User-Agent伪装
-
第二步:找Cookie
-
第三步:找Referrer
-
第四步:考虑是否存在JS加密
-
-
爬虫流程:
- 确定url
- 获取数据
- 数据解析
- 数据入库
2. 代理的使用
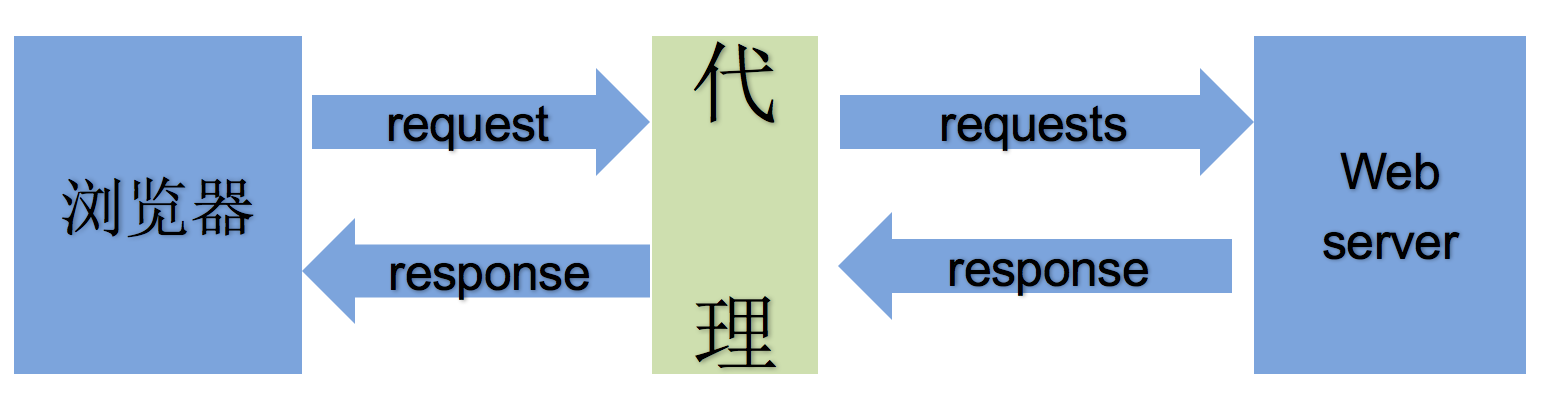
2.1 为什么要使用代理
-
让服务器以为不是同一个客户端在请求
-
防止我们的真实地址被泄露,防止被追究 (你懂的)
2.2 理解正向代理和反向代理的区别
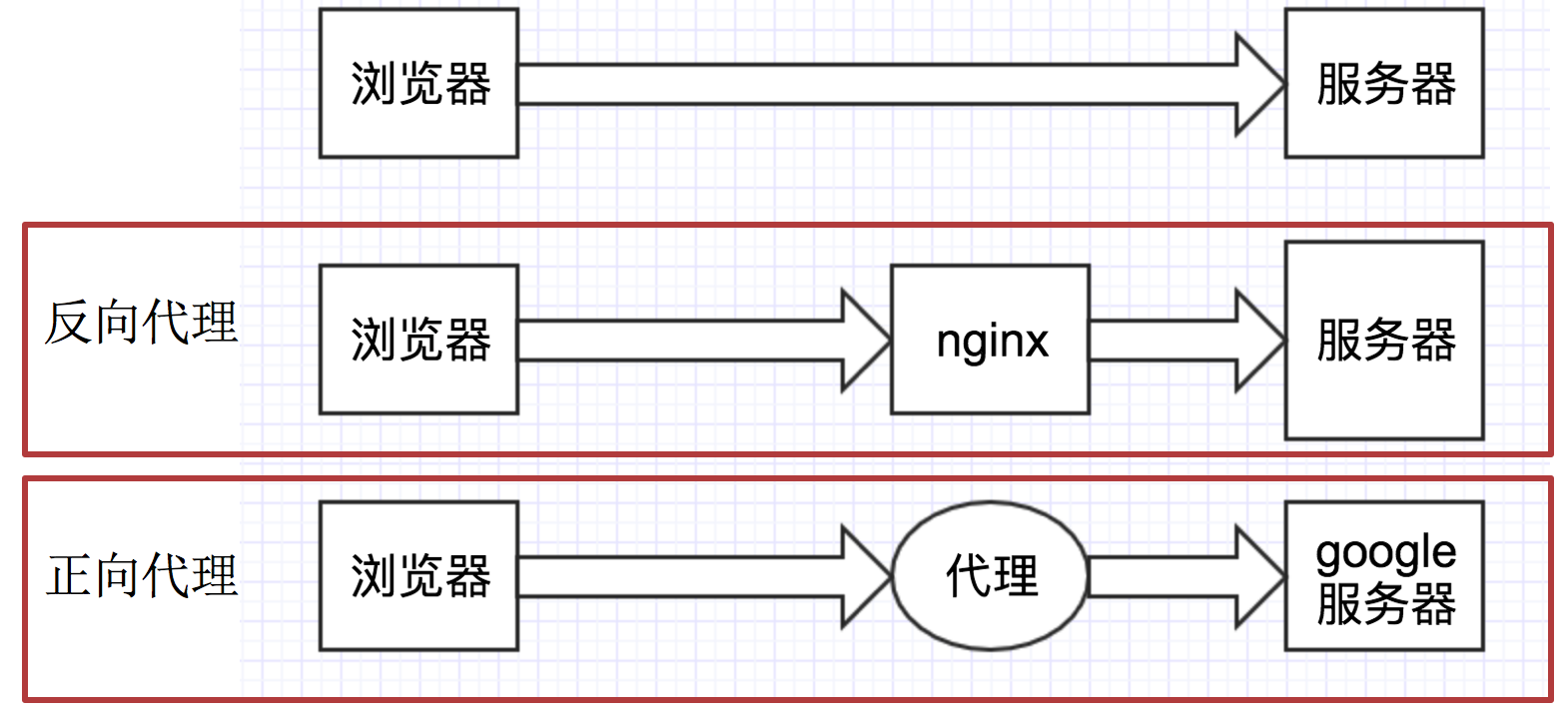
通过上图可以看出:
-
正向代理:对于浏览器知道服务器的真实地址
-
反向代理:浏览器不知道服务器的真实地址
-
(正向代理) ==》 替身术 ,代替我去发请求
-
(反向代理) ==》 多重影分身之术,你访问的任何一个都会把经验数据带回给我本体(服务器)
2.4 代理使用
-
用法:
requests.get("http://www.baidu.com", proxies = proxies) -
proxies的形式:字典
-
例如:
proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", }
案例六 ==> ip查询网址 http://httpbin.org/ip 或 http://mip.chinaz.com/
import requests
# http://httpbin.org/ip
response = requests.get("http://mip.chinaz.com/", proxies={"http": "http://165.225.34.56:10605"})
print(response.content.decode())
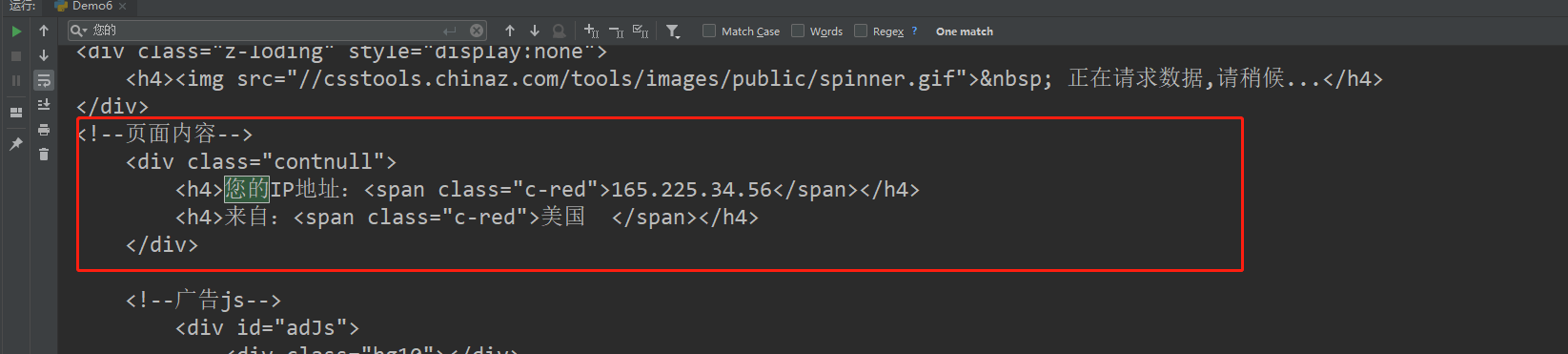
2.5 代理IP的分类
根据代理ip的匿名程度,代理IP可以分为下面四类:
- 透明代理(Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。
- 匿名代理(Anonymous Proxy):使用匿名代理,别人只能知道你用了代理,无法知道你是谁。
- 高匿代理(Elite proxy或High Anonymity Proxy):高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
在使用的使用,毫无疑问使用高匿代理效果最好
从请求使用的协议可以分为:
- http代理
- https代理
- socket代理等
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择
2.6 代理IP使用的注意点
-
反反爬
使用代理ip是非常必要的一种
反反爬的方式但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:
-
一段时间内,检测IP访问的频率,访问太多频繁会屏蔽 【可以使用大量的代理来进行欺骗】
-
检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽 【基本反反爬参数】
-
服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽 【最狗的,两头赚钱】
所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
-
-
代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。
-
好用的高匿代理都是花钱买的,不过网上也有很多免费的代理可以供我们使用,我们可以通过爬虫来爬取这些代理来组建代理池,并定期进行测试,优胜略汰的原则保证代理池中代理的质量。
3. reuqests处理cookie
1 爬虫中使用cookie
为了能够通过爬虫获取到登录后的页面,或者是解决通过cookie的反扒,需要使用request来处理cookie相关的请求
1.1 爬虫中使用cookie的利弊
- 带上cookie的好处
- 能够访问登录后的页面
- 能够实现部分反反爬
- 带上cookie的坏处
- 一套cookie往往对应的是一个用户的信息,请求太频繁有更大的可能性被对方识别为爬虫
- 那么上面的问题如何解决 ?使用多个账号
1.2 requests处理cookie的方法
使用requests处理cookie有三种方法:
- cookie字符串放在headers中
- 把cookie字典放传给请求方法的cookies参数接收
- 使用requests提供的session模块
2 cookie添加在headers中
2.1 headers中cookie的位置
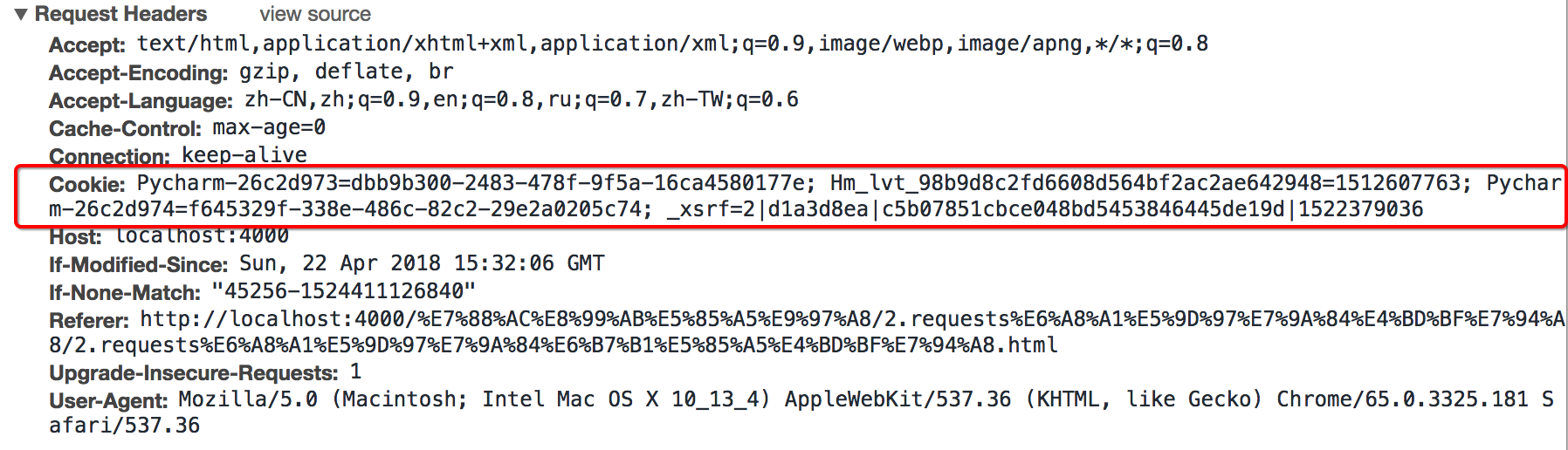
headers中的cookie:[拆分小技巧:字典生成式]
- 使用分号(;)隔开
- 分号两边的类似a=b形式的表示一条cookie
- a=b中,a表示键(name),b表示值(value)
- 在headers中仅仅使用了cookie的name和value
2.2 cookie的具体组成的字段
由于headers中对cookie仅仅使用它的name和value,所以在代码中我们仅仅需要cookie的name和value即可

2.3 在headers中使用cookie
复制浏览器中的cookie到代码中使用,之前的案例中有演示过该用法
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Cookie":" Pycharm-26c2d973=dbb9b300-2483-478f-9f5a-16ca4580177e; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1512607763; Pycharm-26c2d974=f645329f-338e-486c-82c2-29e2a0205c74; _xsrf=2|d1a3d8ea|c5b07851cbce048bd5453846445de19d|1522379036"}
requests.get(url,headers=headers)
注意:
cookie有过期时间 ,所以直接复制浏览器中的cookie可能意味着下一程序继续运行的时候需要替换代码中的cookie,对应的我们也可以通过一个程序专门来获取cookie供其他程序使用;当然也有很多网站的cookie过期时间很长,这种情况下,直接复制cookie来使用更加简单
3 使用cookies参数接收字典形式的cookie
- cookies的形式:字典
cookies = {"cookie的name":"cookie的value"}
- 使用方法:
requests.get(url,headers=headers,cookies=cookie_dict}
4 使用requests.session处理cookie
前面使用手动的方式使用cookie,那么有没有更好的方法在requets中处理cookie呢?
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持
会话保持有两个内涵:
- 保存cookie,下一次请求会带上前一次的cookie
- 实现和服务端的长连接,加快请求速度
4.1 使用方法
session = requests.session()
response = session.get(url,headers)
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
5 小结
- cookie字符串可以放在headers字典中,键为Cookie,值为cookie字符串
- 可以把cookie字符串转化为字典,使用请求方法的cookies参数接收
- 使用requests提供的session模块,能够自动实现cookie的处理,包括请求的时候携带cookie,获取响应的时候保存cookie
练习3 爬取IP代理,组建代理池 url 自选 (3.5星)(百度ip代理,一抓一大把)
代理高匿测试:http://httpbin.org/ip 或 http://mip.chinaz.com/
参考答案爬取ip代理 提取码:9ghy
2.8 requests模块的其他方法
- 掌握requests中cookirJar的处理方法
- 掌握requests解决https证书错误的问题
- 掌握requests中超时参数的使用
- 掌握retrying模块的使用
1 requests中cookirJar的处理方法
使用request获取的resposne对象,具有cookies属性,能够获取对方服务器设置在本地的cookie,但是如何使用这些cookie呢?
1.1 方法介绍
- response.cookies是CookieJar类型
- 使用requests.utils.dict_from_cookiejar,能够实现把cookiejar对象转化为字典
1.2 方法展示
import requests
url = "http://www.baidu.com"
#发送请求,获取resposne
response = requests.get(url)
print(type(response.cookies))
#使用方法从cookiejar中提取数据
cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
输出为:
<class 'requests.cookies.RequestsCookieJar'>
{'BDORZ': '27315'}
注意:
在前面的requests的session类中,我们不需要处理cookie的任何细节,如果有需要,我们可以使用上述方法来解决
2 requests处理证书错误
经常我们在网上冲浪时,经常能够看到下面的提示:
出现这个问题的原因是:ssl的证书不安全导致
2.1 代码中发起请求的效果
那么如果在代码中请求会怎么样呢?
import requests
url = "https://www.12306.cn/mormhweb/" # 目前最新测试已修复
response = requests.get(url)
返回证书错误,如下:
ssl.CertificateError ...
2.2 解决方案
为了在代码中能够正常的请求,我们修改添加一个参数
import requests
url = "https://www.12306.cn/mormhweb/"
response = requests.get(url,verify=False)
3 超时参数的使用
在平时网上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错
3.1 超时参数使用方法如下:
response = requests.get(url,timeout=3)
通过添加timeout参数,能够保证在3秒钟内返回响应,否则会报错
注意:
这个方法还能够拿来检测代理ip的质量,如果一个代理ip在很长时间没有响应,那么添加超时之后也会报错,对应的这个ip就可以从代理ip池中删除
4 retrying模块的使用
使用超时参数能够加快我们整体的请求速度,但是在正常的网页浏览过成功,如果发生速度很慢的情况,我们会做的选择是刷新页面,那么在代码中,我们是否也可以刷新请求呢?
对应的,retrying模块就可以帮助我们解决
4.1 retrying模块的使用
pip install retrying
retrying模块的地址:https://pypi.org/project/retrying/
retrying 模块的使用
- 使用retrying模块提供的retry模块
- 通过装饰器的方式使用,让被装饰的函数反复执行
- retry中可以传入参数
stop_max_attempt_number,让函数报错后继续重新执行,达到最大执行次数的上限,如果每次都报错,整个函数报错,如果中间有一个成功,程序继续往后执行
4.2 retrying和requests的简单封装
实现一个发送请求的函数,每次爬虫中直接调用该函数即可实现发送请求,在其中
- 使用timeout实现超时报错(一般使用这个就够了)
- 使用retrying模块实现重试
代码参考:
# parse.py
import requests
from retrying import retry
headers = {}
#最大重试3次,3次全部报错,才会报错
@retry(stop_max_attempt_number=3)
def _parse_url(url)
#超时的时候回报错并重试
response = requests.get(url, headers=headers, timeout=3)
#状态码不是200,也会报错并重试
assert response.status_code == 200
return response
def parse_url(url)
try: #进行异常捕获
response = _parse_url(url)
except Exception as e:
print(e)
#报错返回None
response = None
return response
练习4 网易新闻|新冠疫情数据(3.5星)
https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
参考答案 提取码:i7z1
最后
以上就是朴素御姐最近收集整理的关于python——网络爬虫快速入门【reuqests篇】的全部内容,更多相关python——网络爬虫快速入门【reuqests篇】内容请搜索靠谱客的其他文章。








发表评论 取消回复