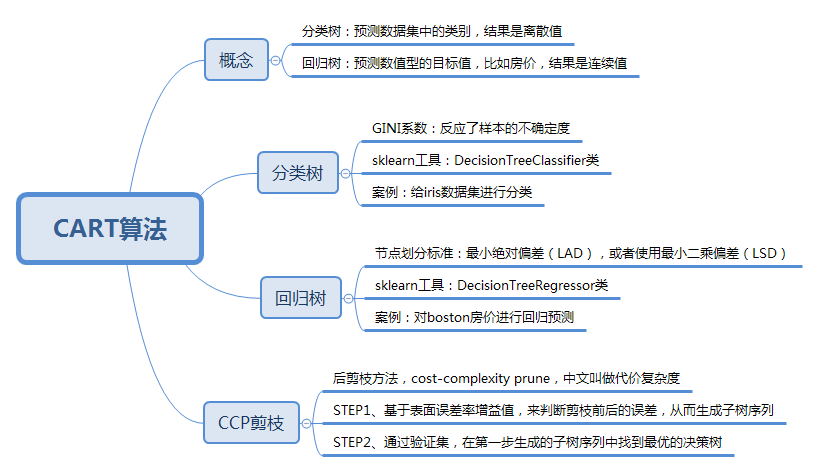
决策树:
- ID3 算法,基于信息增益做判断;
- C4.5 算法,基于信息增益率做判断
- CART算法,基于基尼系数做判断,回归树是基于偏差做判断
以下是cart算法分类和预测的实现过程
- 第一个使用的sklearn的iris 数据集,进行分类
- 第二个使用的sklearn的boston 数据集,进行回归预测
- 第三个使用的sklearn的digits数据集,进行分类
# encoding=utf-8
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 准备数据集
iris=load_iris()
# 获取特征集和分类标识
features = iris.data
labels = iris.target
# 随机抽取 33% 的数据作为测试集,其余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
# 创建 CART 分类树
clf = DecisionTreeClassifier(criterion='gini')
# 拟合构造 CART 分类树
clf = clf.fit(train_features, train_labels)
# 用 CART 分类树做预测
test_predict = clf.predict(test_features)
# 预测结果与测试集结果作比对
score = accuracy_score(test_labels, test_predict)
print("CART 分类树准确率 %.4lf" % score)
# encoding=utf-8
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
from sklearn.tree import DecisionTreeRegressor
# 准备数据集
boston=load_boston()
# 探索数据
print(boston.feature_names)
# 获取特征集和房价
features = boston.data
prices = boston.target
# 随机抽取 33% 的数据作为测试集,其余为训练集
train_features, test_features, train_price, test_price = train_test_split(features, prices, test_size=0.33)
# 创建 CART 回归树
dtr=DecisionTreeRegressor()
# 拟合构造 CART 回归树
dtr.fit(train_features, train_price)
# 预测测试集中的房价
predict_price = dtr.predict(test_features)
# 测试集的结果评价
print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price))
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 8 16:28:43 2019
@author: Administrator
"""
# encoding=utf-8
from sklearn.metrics import accuracy_score # 均方差
from sklearn.model_selection import train_test_split #训练和测试集的划分
from sklearn.datasets import load_digits
#from sklearn.metrics import r2_score,mean_absolute_error
from sklearn.tree import DecisionTreeClassifier
# 准备数据集
digits=load_digits()
# 获取特征集和分类标识
features =digits.data
labels = digits.target
#print(features)
#print(labels)
# 随机抽取 33% 的数据作为测试集,其余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33)
# 创建 CART 分类树
clf = DecisionTreeClassifier()
# 拟合构造 CART 分类树
clf.fit(train_features,train_labels)
# 用 CART 分类树做预测
test_predict = clf.predict(test_features)
#测试集的结果评价
score=accuracy_score(test_labels,test_predict)
print('CART 的准确率 %4lf' % score)
最后
以上就是清新香菇最近收集整理的关于数据分析+python+决策树的全部内容,更多相关数据分析+python+决策树内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复