PR曲线及F1 score
- Pecision 和 Recall
- PR曲线
- PR曲线的绘制
- PR曲线的性能比较
- F1 score
- F1 的一般形式
- macro-F1
- micro-F1
Pecision 和 Recall
首先,我们把数据和对应的标签称为一个example。
在二分类问题中,example可分为真正例(true positive),假正例(fake positive),真反例(true negative),假反例(fake negative)
下面这个矩阵称为混淆矩阵。
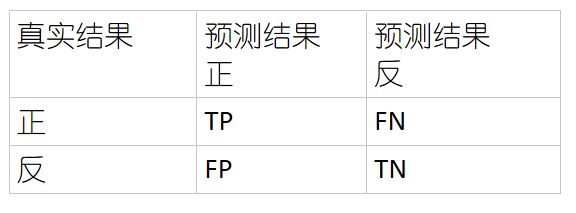
precision 和 recall的计算公式如下:

PR曲线
PR曲线的绘制
- 预测结果按照最有可能是正例的样本到最不可能是正例的样本的顺序排序。
- 把每个样本作为正例进行预测,计算出P和R。
- 以R作为横轴,P为纵轴
对上述进行解释:
a) 设置一个从高到低的阈值,大于等于阈值的认为正例,小于阈值的认为负例。
b) 有n个样本, score是分类器对于样本属于正例的可能性的打分。
c) n个阈值,就得到n种标注结果,n对(P,R)。
d) 将n对(P,R)在图上表示出来,就是PR曲线。
PR曲线如下图所示,但实际上PR曲线是非单调的,不平滑的,在局部有很多波动。
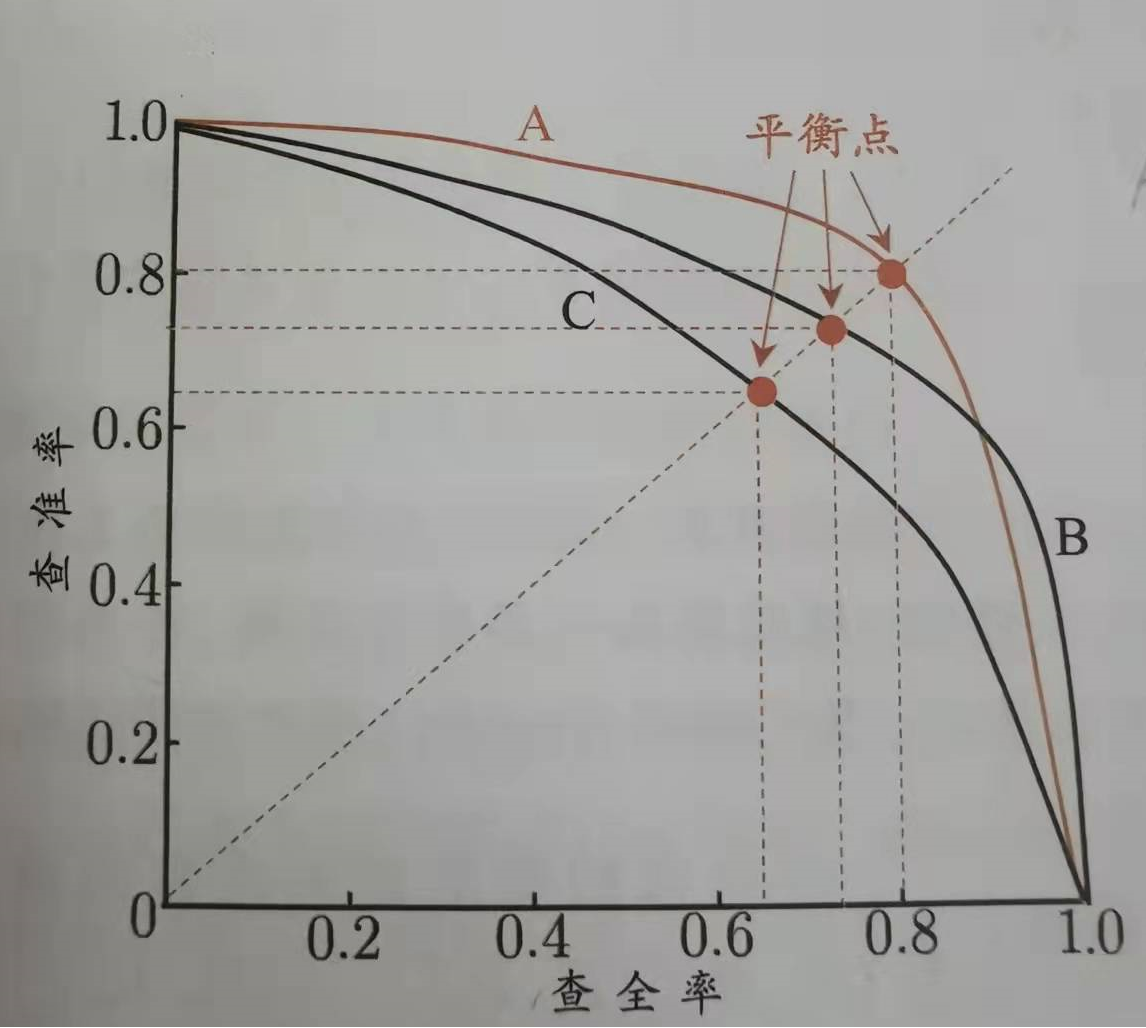
PR曲线的性能比较
不同的方法得到的PR曲线不同。
由上图可以看到A的性能好于C,A和B发生交叉,只通过曲线不好判断,要在具体的P或R下进行比较。
为了综合评价性能,提出两种度量方法:
- 平衡点(P=R),可见A的平衡点高于B,因此A>B
- F1 score
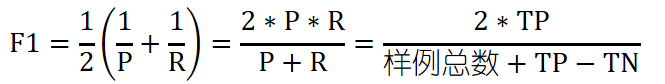
这个公式称为F1是标准形式。
F1 score
F1 的一般形式
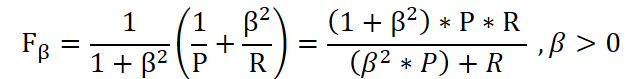
不同的应用对P,R的重视程度不同,F1的表现形式也会的发生变化。
其中 β 度量R对P的相对重要性。
- β=1 F1的标准形式
- β>1 R的影响大
- β<1 P的影响大
macro-F1
进行多次训练测试时,每次得到一个混淆矩阵,或者执行多分类任务时,估计算法的全局性能。
总之,在n个二分类混淆矩阵上综合考察PR。
计算每个混淆矩阵的P,R,这样就得到(P1, R1 ),(P2,R2 ),…,(Pn, Rn )
计算平均值,就得到了macro-P, macro-R,macro-F1
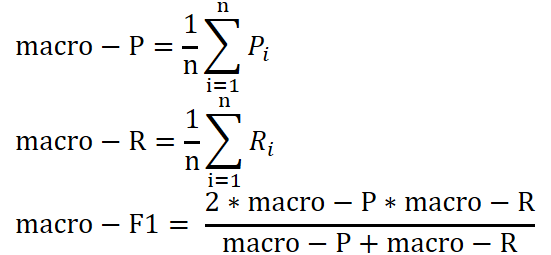
micro-F1

最后
以上就是细腻皮带最近收集整理的关于机器学习:PR曲线及F1 scorePecision 和 RecallPR曲线F1 score的全部内容,更多相关机器学习:PR曲线及F1内容请搜索靠谱客的其他文章。








发表评论 取消回复