论坛系统数据库设计
- 1.引言
- 2.QQ“摆烂式”设计
- 2.1数据表设计猜测
- 2.2分析增删查改实现方法
- 2.3分析QQ"摆烂式"的优缺点
- 2.4改进方法
- 3.“盖楼式”设计
- 3.1数据表设计猜测
- 3.2数据表设计优化
- 4.推荐设计
1.引言
最近,决定将开发的重点还是放在之前的易搭衣橱项目中。刚好,有个好兄弟想用我的作品参加比赛,然后给我提了一些建议,让我写一个论坛系统出来。当时就花了大概两天写了一个一级评论,感觉有一些难度,内部会涉及数据的反复查询,还包括评论点赞功能。于是,还是看了看大佬们的思路,将学到的内容总结如下。
基于现在比较常见的论坛系统,数据库设计主要分为两大类,一种是QQ“摆烂式”设计和“盖楼式”设计。两者组合就成了B站的综合性设计。这里主要是说一下自己的看法和设计上的猜测。由于各个产品的主营业务点不一样,所以对于论坛,在设计上往往存在一些侧重。
2.QQ“摆烂式”设计
这里所说的摆烂不是真的摆烂,QQ主要业务是通信,或者说是趣味通讯,因此像QQ动态这种论坛的占比不是很大,于是就出现了现在的这种设计:
这种设计相对简洁一些,方便快速查看评论内容,但是论坛中的个性化体现的不是充分。
2.1数据表设计猜测
| 数据字段 | 含义 |
|---|---|
| comment_type | 评论类型(dynamic或者comment) |
| source_id | dynamic_id或者comment_id |
| comment_id | 评论唯一编号 |
| content | 评论的具体内容 |
| from_uid | 发起评论的用户的唯一编号 |
| date_time | 评论的具体时间 |
补充说明:comment_type 用来标记数据是哪一一种类型,因为通过分析可以发现,用户的评论无非就是两种,一种是用户对于动态的直接评论,一种是对用户一级评论的回复。所以使用comment_type来标记是哪一种评论。source_id 标记评论是对哪种目标内容发起的,需要和comment_type联合判断,方便直接找到源头。如果评论的内容是一级评论,那么说明是直接针对动态发起的,对应就是dynamic_id;如果评论的内容是二级评论,那么对应的就是一级评论的comment_id。
2.2分析增删查改实现方法
(1)添加数据,正常情况下,考虑之后的多级评论,所以后端给前端传送的数据中必然包含想要的关键信息也就是:dynamic_id或者是comment_id,也就是增加评论直接插入就行;
(2)删除数据,删除非常简单,一般是用于后台或者前端用户直接撤销评论。需要注意一点,如果是一级评论需要先删除一级评论对应的所有二级评论,;
(3)查询数据,相对复杂一些,首先需要根据动态唯一标识dynamic_id获取一级评论,然后根据一级评论嵌套查询二级评论。当然以为这两层循环就完了吗,不还需要将comment_id里面的用户id转化成用户详细信息,比如nickname和avatar(当然QQ直接“摆”,砍掉了头像展示这一块)。
一级循环,dynamic_id=>(comment_id,from_uid)集合;
二级循环,from_uid=>(一级评论者username);同时遍历comment_id的二级评论,
一级comment_id=>(二级comment_id,二级from_uid)
三级循环 ,二级from_uid=>(一级评论者username)
整理,带上content和comment_type两个字段返回给前端(方便前端展示),
形成一个json发给前端。
(4)修改数据,一般不支持修改,只有一种可能,系统查询敏感词,在发布的时候由后端修改关键词,也有的直接敏感词限制发布。
2.3分析QQ"摆烂式"的优缺点
逻辑相对容易,最高只有二级评论,虽然有三层遍历,但是这些都是必要的。一个比较大的优点是,数据表空间利用率100%,单表,容易进行数据迁移。缺点,清晰度可能低一些,逻辑相对需要严谨一些,耦合度有点高,比如souce_id和comment_type的绑定。
2.4改进方法
将数据表一分为二,一个表用来放一级评论,一个表用来放二级评论。这样就可以将souce_id解耦:
一级评论表
| 数据字段 | 含义 |
|---|---|
| dynamic_id | 动态id |
| comment_id | 评论唯一编号 |
| content | 评论的具体内容 |
| from_uid | 发起评论的用户的唯一编号 |
| date_time | 评论的具体时间 |
二级评论表
| 数据字段 | 含义 |
|---|---|
| source_id | 一级comment_id |
| comment_id | 评论唯一编号 |
| content | 评论的具体内容 |
| from_uid | 发起评论的用户的唯一编号 |
| date_time | 评论的具体时间 |
跨表查询,操作起来需要更换数据表,基本逻辑不变。
除此以外,可以将用户的username直接放到评论中,利用少量数据冗余优化性能,这也是数据库性能优化常用方法之一。
3.“盖楼式”设计
什么是盖楼式呢?其实这种设计主要适用于PC端,类似于一种树状图,这里拿的是大佬的图片(找了半天也没有找到这样的网站),估计是这种设计凉了:
为什么说这种设计可能凉了呢,因为我的屏幕只有那么宽,如果是五级评论或者更高,那么这个深一点的楼层就不太方便展示了,特别是应对大规模论坛用户。于是出现了这种舍弃UI,转而关注内容的设计:
这种盖楼式可能是小时候的回忆吧,那个时候论坛大部分都是这样的,这种往往需要用户点击才能查看具体的内容,其实并不利于消息的展示。当时的盖楼式比较流行是因为通讯软件微信和QQ还没有火起来,更别提什么移动端了,手机联网就是牛逼,因此充斥市场的就是PC端论坛。喜欢泡论坛的就不在乎什么点击的,反而觉得这个挺合适的,分类清晰,因为论坛“建起来”了一栋栋“巍巍高楼”。
随着科技的发展,网络基站的建立,联网触手可及。通讯也未必需要依赖于论坛,反而直接使用常用社交软件QQ更便捷,加上丰富的表情包的引入,更能表情达意。这时,论坛逐渐走下坡路,对于软件而言,对于论坛而言,已经不在具有那么高的用户粘性了,取而代之的是需要唯唯诺诺的向用户主动展示信息,而且尽可能美观。
抛开QQ不说,QQ本身就具有强大的用户粘性,而且动态以分享的内容为核心,不是评论区。结合QQ"摆烂式"和最初始的那种“楼盘式”(说的是从大佬那里借来的第一张图片)就有了现在微博和百度这样介于“树形”和“摆烂”的UI设计,这里的设计都来自于网站,但是个人感觉可能是移动端向web端的适配,毕竟移动端已经在论坛占据了主流:
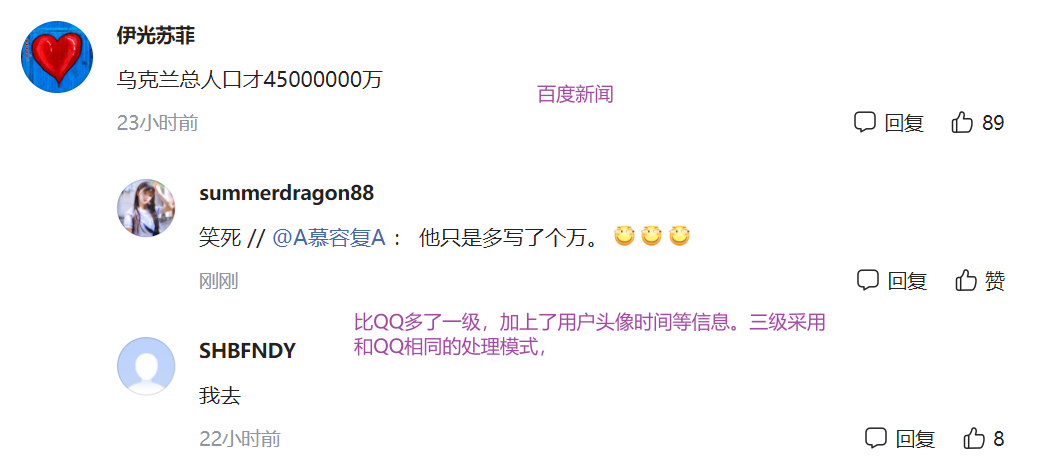
写到这里发现有些偏题了,哈哈哈,没事言归正传,虽然“盖楼式”已经凉了,但是这种以层次为核心的数据库设计方式还是可以了解一下的。
3.1数据表设计猜测
| 数据字段 | 含义 |
|---|---|
| comment_type | 评论类型(dynamic或者comment) |
| source_id | dynamic_id或者comment_id |
| comment_id | 评论唯一编号 |
| content | 评论的具体内容 |
| from_uid | 发起评论的用户的唯一编号 |
| date_time | 评论的具体时间 |
这个表行不行,行!不过有些顶,需要使用递归设计思想,或者改造的循环,算法难度蹭蹭蹭往上涨。咱这里就放个伪代码吧(我算法不好,没写太清楚):
function getcommentList(commnet_id, layer = 1) {//标记是哪一楼的
//一级循环 => (二级comment_id,from_uid)集合;
if ("二级comment_id集合为空 as commentList") {
//处理数据
const jsonExample={
layer:layer+"楼",
//...
}
return resultList;//返回疯转的数据
} else {
//"遍历{二级(其实就是低一级)}comment_id集合,顺带将from_uid转化成用户信息"
for (let i = 0; i < commentList.length; i++) {
getcommentList(comnentList[i].comment_id, ++layer);
}
}
}
getcommentList(dynamic_id);
感觉:反复遍历,算法时间复杂度极高,何况还是对库操作,时间肯定是个问题,抗高并发能力较低,性能较差。增加数据倒还好,删除数据也需要递归删除所有低一层的评论(可能这个时候你不太想删了,哈哈哈,属实性能过差,但是等用户一层层往上差,发现那一层断了就可能影响用户体验)。
3.2数据表设计优化
用华农的话来说就是“还能抢救一下”。这个是根据具体的业务需求,不能说这个设计不好,至少在实现上只要把递归写好了问题基本解决了一大半。优化的话主要有两种方式:
(1)站在数据库查询角度的优化,给每一个评论都加上一个dynamic_id,还是那句话,利用数据用于优化性能,一次性将一个话题(dynamic)有关的评论都抽出来,然后变成一道算法题(从某个角度也证明了算法的重要性);
(2)巧妙利用layer字段标记楼层,为评论表新增一个layer字段标记楼层,如果用户回复上一级的评论,直接上上一层的layer+1写入数据库,查询也可以利用这个layer来辅助查询,快速锁定那一层的数据,然后向评论的上一层扩展换取from_uid进而获取用户个人信息数据。比如,你想拿到第六层的数据,但是你得拿到第五层的数据,因为至少你得知道它是在回复什么内容,@的作者是哪位。这样就能打破递归。
4.推荐设计
目前如果说推荐的论坛设计,当然是B站的论坛设计,使用了点赞的消息聚合等展示优化的功能,虽然算法上复杂一些,但是至少站在用户的角度,获取信息更加直观贴切。下面就简单分析一下B站论坛设计:
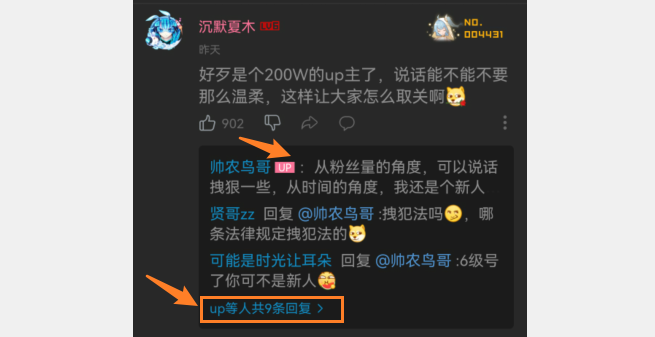
相比于微博,说B站的设计比较“年轻”是不为过的,看起来特别舒服,加上还有UP标识,能够很快找到自己的关注点。下面左下角使用对回复的聚合,当然这些会增加查询的压力,不过用户体验真的好。
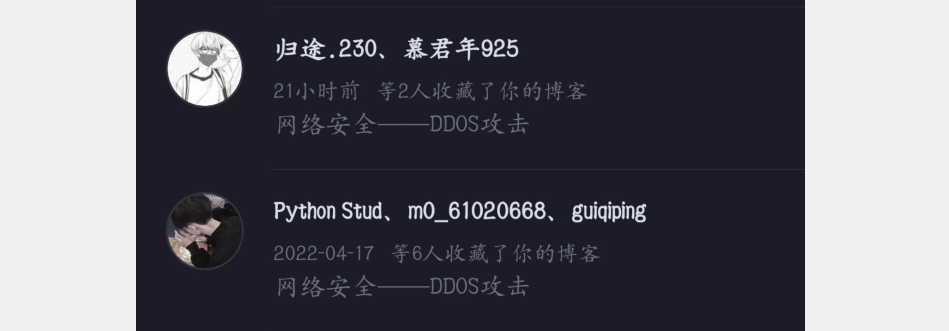
另外一个就是点赞的消息聚合,前面展示前两个最新的点赞用户,然后给出一个点赞总数,但是由于个人长期B站白嫖,所以没有发布作品,这个还是当时因为一些业务了解到的。这里就贴一手CSDN的博客消息系统,效果一样的(嘿嘿,此处意味尽在不言之中):
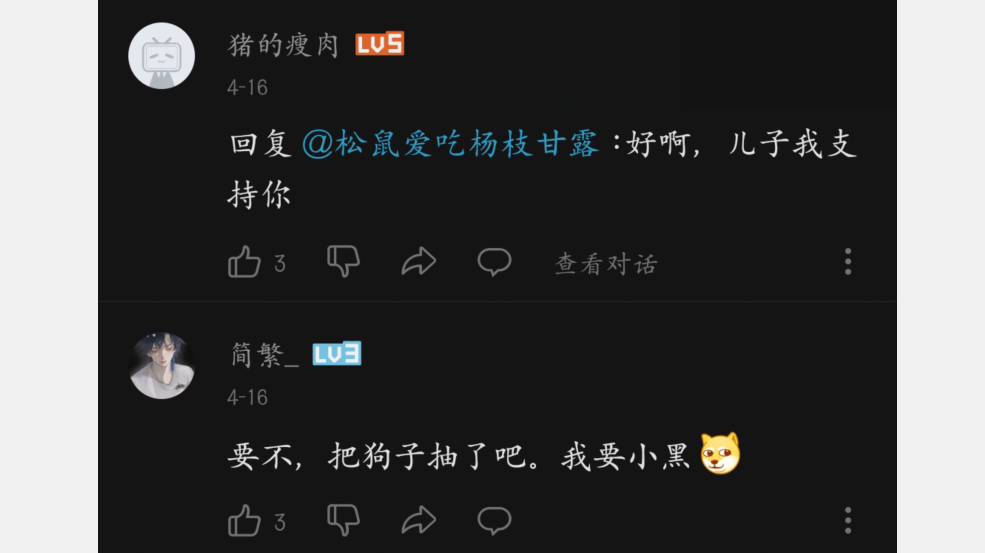
对于评论的展示,点击下面的聚合消息之后,可以看到更多详细的评论,包含点赞和发布时间等,更重要的是一些用户个性化的内容(昵称和头像):
当然有可能是自己长期使用B站,被设计同化了。B站设计上既有树形的缩进,方便抽离出一级评论者,点击详情之后由模仿了QQ的极简设计,保证了内容的充分展示,限制层级深入。还进一步突出用户个性化,用户体验比较好。设计与实现上需要关注以下几点:
(1)由于B站的点赞比较频繁,涉及点赞的内容比较多,所以可以利用redis对点赞信息冷处理,使用redis缓存点赞信息,然后定时同步redis缓存到数据库中,这个实现还是很有难度的,CSDN给的其实是防抖。
(2)设计上可以将用户的点赞信息直接作为字段放到动态或者评论里面冗余,因为如果独立的话,那么每次一条动态就需要查询大量的数据,加上B站的活跃用户比较多,评论也比较多,这样反复查询必然影响性能。
(3)最新点赞的设计上可以使用排序处理。
(4)最后补充一个细节,CSDN自己给自己点赞还有消息提示,重复点赞依然会有消息提示,这些可能是在设计上的不足,而B站相对弱化了这个消息提示功能,只能自己主动去点击“小红点”信封,查看消息才会看到。
当然,一切归于业务重点的侧重,这些都能被合理的解释,没有完美的设计,不断的学习、创新、优化才是王道。
最后,补充一下自己关于楼层的解释,其实楼层的理解可能自己有一些偏差,楼层也可能是楼主开的,然后分给各层小楼主,构建成一层层的小楼。我当时的理解是无限深入的往下嵌套。因为在我仔细查看发现天涯论坛里面竟然右侧有一个评论。那么不排除这里面又成了QQ模式的简洁版,删除的时候就能按照二级或者三级封顶的方式删除,甚至可以直接删除整个楼层。博文中大多数内容来源于自己的思考,如有错误,欢迎批评斧正。
最后
以上就是冷傲钥匙最近收集整理的关于论坛系统数据库设计的全部内容,更多相关论坛系统数据库设计内容请搜索靠谱客的其他文章。








发表评论 取消回复