目标
使用rust构建一个单线程处理http请求的web服务器。
- 学习有关TCP和HTTP两个协议的知识。
- 侦听套接字上的TCP连接。
- 掌握http协议
动手
cargo 构建项目
我们不希望只构建一个小玩具的rs代码,而是采用生产方式来构建我们的任何rs项目,这需要我们用到之前讲述过的cargo工具。执行一下指令构建本次实践的项目
cargo new webBean
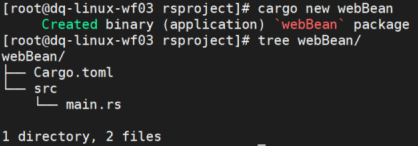
回顾之前文章讲过的内容:
1、Cargo.toml是项目描述信息
2、src是源代码放置的目录
使用net网路库监听tcp链接
- 补充知识:
Web服务器中涉及的两个主要协议是超文本传输协议 (HTTP)和传输控制协议 (TCP)。两种协议都是请求-响应协议,这意味着客户端发起请求,服务器监听请求并向客户端提供响应。
- 概述:
- tcp是传输层协议,用来实现端到端的数据传输。
- http是应用层协议,当服务器端接收到请求端的数据时,用户应用层通过解析数据识别是什么应用请求(http,icmp,ftp)等再进行业务处理,应用层协议实际上也是一种逻辑业务:比如nginx解析http进行转发,或者通常使用的http 框架(比如go的beego、java的spring mvc等)都进行了封装,用户只需要处理“真正的业务”请求。
创建服务器,监听tcp链接:
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("localhost:9999").unwrap();
for stream in listener.incoming(){
let stream = stream.unwrap();
println!("connection established!");
}
}
核心知识点:
- 使用use 引入rust提供的net包,使用TcpListener的bind函数来请求分配一个监听会话,该bind函数返回一个Result<T, E>,指示绑定可能失败。正常来说,返回失败时,我们服务器应该是无效的,需要退出。那么常见的失败原因有端口被占用、或者非管理员端口申请(比如80等)。
- unwrap是rust语言中,主要用于Option或Result的打开其包装的结果,在生产中通常处理Result而不是直接使用unwrap,在这里只是演示,不做深入解析。
- 使用let 将 TcpListener监听的返回值绑定到"变量" listener,这个绑定是不可变的,所以实际上又是一个常量。注意第7行的 let stream,这里的stream虽然与循坏的stream重名了,但实际上是通过let绑定了一个新值,是一个新的"变量"。
- 服务器建立监听后,可以通过Incoming函数来接收客户端链接的请求流,for循环将依次处理每个连接并产生一系列流供我们处理。
- 我们对每个流进行unwrap处理,如果有错误即终止程序,生产环境中我们还是通过对Result进行错误处理,而不是直接终止程序。
读取请求
- 我们编写函数handle_connection来处理服务器接收到请求流:
重写后
use std::net::TcpStream;
use std::net::TcpListener;
use std::io::prelude::*;
fn main() {
let listener = TcpListener::bind("127.0.0.1:9999").unwrap();
for stream in listener.incoming(){
let stream = stream.unwrap();
// println!("connection established!");
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
println!("request : {}",String::from_utf8_lossy(&buffer[..]));
}
核心知识点:
1、引入了io包,通过stream.read函数,我们将流的数据写入到在栈上分配好的buffer缓冲区,buffer大小为1024字节,大小足以处理我们的这个demo请求,buffer需要存储我们的数据流,因此需要用mut表示可变性,这里的缓存大小1024字节 主要是满足示例演示,如果数据量大,我们需要对buffer进行管理,传输流并不是一次性传输的,网络编程中时需要解决由小包、大包所引发的一系列问题,在这里暂不详细描述。
2、String::from_utf8_lossy 函数获取一个 &[u8] 并产生一个 String。函数名的 “lossy” 部分来源于当其遇到无效的 UTF-8 序列时的行为:它使用 �,U+FFFD REPLACEMENT CHARACTER,来代替无效序列。你可能会在缓冲区的剩余部分看到这些替代字符,因为他们没有被请求数据填满。
3、u8表示无符号的8bit,我们知道,一字节等于8bit,而这里采用[]数组来表示字符串,&表示引用,对c++使用者来说,并不陌生。
使用cargo run运行我们的项目:
$ cargo run
Compiling webBean v0.1.0 (file:///projects/webBean)
Finished dev [unoptimized + debuginfo] target(s) in 0.42 secs
Running `target/debug/webBean`
Request: GET / HTTP/1.1
Host: 127.0.0.1:7878
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101
Firefox/52.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
������������������������������������
浏览器访问,以下为服务器接收到的流
request : GET / HTTP/1.1
Host: 10.86.168.45:9999
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: XSRF-TOKEN=4e49b69a-04ae-4f95-b0a4-ca0be37eb43e; JSESSIONID=FA53C000048E241DCE62614648599B6D
http协议解析
http是一种文本协议,其请求格式如下:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
Request
对照我们前文服务器的输出内容:
1、Method 表示我们请求使用的方法,比如 Get、Post,而我们通过浏览器访问时,客户端请求使用的是Get 方法。
2、Request-URI,URI(Uniform Resource Identifier)统一资源标识符,用于标识我们所请求的资源。我们客户端访问的是 / 资源。
3、HTTP-Version 表示http 协议的版本,可以看到我们客户端使用的是1.1
4、最后行结束采用CRLF 回车换行符 rn
5、我们请求的第二行内容 Host: 开始表示的是协议头,请求没有body
Response
有请求,那必然得回复,http的回复协议格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
1、Status-Code:请求状态码,比如常见的 200表示成功、500表示服务器错误等
2、Reason-Phrase:状态描述,比如描述200时, 其内容为 ok
接下来改进我们的服务端程序,让其返回200给客户端, 表示请求成功。
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let response = "HTTP/1.1 200 OKrnrn";
stream.write(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
1、按照http的返回协议,我们需要定义返回的内容,暂时不返回body
HTTP/1.1 200 OKrnrn
2、定义了response变量存储我们的成功消息,调用as_bytes()函数将字符串转成字节,调用stream的write函数,将我们的字节数据传回给链接端,write函数的参数为&[u8]。
3、调用stream的flush函数,flush会阻塞程序直到将所有数据发送到链接端。
4、TcpStream包含一个内部缓冲区来最小化对底层操作系统的调用。

可以看到我们的请求返回了200 的成功状态。
返回我们的第一个html资源
总结一下前文学到的内容:我们搭建了一个http服务器,用于接收客户端的资源请求,同时响应客户端的请求时,服务端返回200的请求状态,虽然没有返回任何的body内容,但我们已经迈出了一大步,即实现了web应用交互流程。
接下来我们请求一个html资源,让我们的web应用更具肉感。
html(HyperText Markup Language)超文本标记语言,是当前浏览器的语言标准了,当浏览器解析html时是在构建我们的冲浪环境,通过浏览器打开f12,你可以看到整个真实的世界,接下来我们将成为这个世界的创造者之一。
1、先创建一个web资源目录,添加hello.html文件,其内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
目录路径:web是独立的资源,区别于我们的web工程目录
2、改写handle_connection将html的内容作为response的body放回给请求端
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let contents = fs::read_to_string("/usr/yangbin/workdir/rsproject/web/hello.html").unwrap();
let response = format!("HTTP/1.1 200 ok rnContent-Length: {} rnrn{} rn",
contents.len(),
contents
);
stream.write(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
需要引入fs包
use std::fs;
使用fs函数read_to_string 读取hello.html的内容,采用format格式组装response。
需要注意的是response包采用rn进行分行,而body 需要两个rn 即空多一行。
Content-Length 表示body的大小,在这里即是hello.html的内容大小。
3、选择性响应
在完成读取html文件内容进行返回后,实际上还需要对请求做出判断,而不像现在这样无条件的返回。改写handle_connection,对请求的内容进行判断
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1 /r/n";
if buffer.starts_with(get) {
let contents = fs::read_to_string("/usr/yangbin/workdir/rsproject/web/hello.html").unwrap();
let response = format!(
"HTTP/1.1 200 ok rnContent-Length: {} rnrn{} rn",
contents.len(),
contents
);
stream.write(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
}
首先,定义变量get,因为buffer存储的是二进制内容,所以使用b来转换字符串"GET / HTTP/1.1 rn", 这个格式在讲解request时提到的,表示http协议的请求内容,当然了,uri / 可以换成 hello.
当客户端请求,符合get时,服务端才将hello.html的内容返回给客户端。
如果buffer中的内容不以get内容为开始,说明客户端请求的是其他的内容。通常在生产环境,http请求的内容取决于服务端提供的服务,而如果都通过if else 来匹配请求内容的话,逻辑块会冗长难维护,而现在成熟的web框架,比如java的 spring mvc 、go的beego等都会提供请求路由,我们这里不做扩展,只提供思路,比如当请求内容不存在时,服务端可以返回404以及提示页,那么两个请求的匹配只在于状态码和返回的内容,所以我们可以简单的封装下:
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1rn";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK", "/usr/yangbin/workdir/rsproject/web/hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "/usr/yangbin/workdir/rsproject/web/404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!(
"{} rnContent-Length: {} rnrn{} rn",
status_line,
contents.len(),
contents
);
stream.write(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
通过返回tuple元祖,也即是多个数据对,这里封装了(status_line, filename)两个数组
其实这里的封装还不够彻底,因为这里暴露了我们业务层的 get ,我们可以通过map来封装请求路由,再后续的文章,我们将继续改进web服务器,下一步目标是将单线程处理改用多线程并发模型来提高请求处理能力。
最后
以上就是彩色外套最近收集整理的关于rust实践 - 使用tcp链接监听web请求,进行http解析目标动手http协议解析的全部内容,更多相关rust实践内容请搜索靠谱客的其他文章。








发表评论 取消回复