ADPCM算法浅析
1. ADPCM算法简介
1.1 脉冲编码调制(PCM)的概念
- PCM是pulse code modulation的缩写
- 概念上最简单、理论上最完善、最早研制成功、使用最为广泛、数据量最大的编码系统
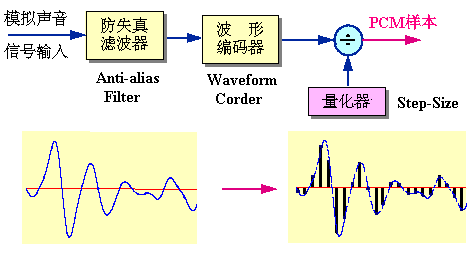
在上图中:
- 输入是模拟信号,输出是PCM样本。
- 防失真滤波器:低通滤波器,用来滤除声音频带以外的信号
- 波形编码器:可理解为采样器
- 量化器:可理解为“量化阶大小(step-size)”生成器或者称为“量化间隔”生成器
PCM实际上是模拟信号数字化:
- 第一步是采样,就是每隔一段时间间隔读一次声音的幅度
- 第二步是量化,就是把采样得到的声音信号幅度转换成数字值
1.2 量化的方法
量化的方法主要有均匀量化和非均匀量化。
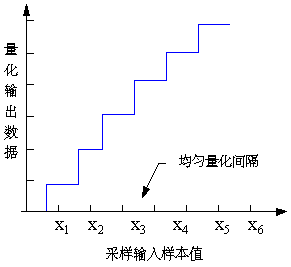
均匀量化:
- 采用相等的量化间隔/等分尺度量采样得到的信号幅度,也称为线性量化。
- 量化后的样本值Y和原始值X的差E=Y-X称为量化误差或量化噪声
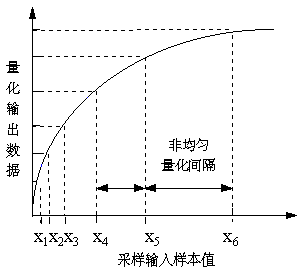
非均匀量化
- 大的输入信号采用大的量化间隔,小的输入信号采用小的量化间隔
- 可在满足精度要求的情况下用较少的位数来表示
- 声音数据还原时,采用相同的规则
- 采样输入信号幅度和量化输出数据之间定义了两种对应关系(μ律压扩算法,A律压扩算法)注:压扩(companding)
μ律压扩
- μ律(μ -Law)压扩(G.711)主要用在北美和日本等地区的数字电话通信中,按下式确定量化输入和输出的关系:
x为输入信号幅度,规格化成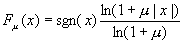 sgn(x)为x的极性;
sgn(x)为x的极性; - u为确定压缩量的参数,它反映最大量化间隔和最小量化间隔之比,取100≤u≤500。
- 由于u律压扩的输入和输出关系是对数关系,所以这种编码又称为对数PCM。具体计算时,用u=255,把对数曲线变成8条折线以简化计算过程。
A律压扩
- A律(A-Law)压扩(G.711)主要用在欧洲和中国大陆等地区的数字电话通信中,按下式确定量化输入和输出的关系:
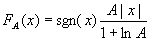 0≤ |x|≤1/A
0≤ |x|≤1/A
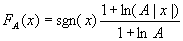 1/A < |x|≤1
1/A < |x|≤1 - x为输入信号幅度,规格化成 -1≤x≤1; sgn(x)为x的极性。
- A为确定压缩量的参数,它反映最大量化间隔和最小量化间隔之比。
小结:PCM编码早期主要用于话音通信中的多路复用。一般来说,在电信网中传输媒体线路费用约占总成本的65%,设备费用约占成本的35%,因此提高线路利用率是一个重要课题。
1.3 自适应差分脉冲编码调制(ADPCM)的概念
- ADPCM的中文术语为自适应差分脉冲编码调制
- adaptive difference pulse code modulation的缩写
- 综合了APCM的自适应特性和DPCM系统的差分特性,是一种性能比较好的波形编码技术
它的核心想法是:
- 利用自适应的思想改变量化阶的大小,即使用小的量化阶(step-size)去编码小的差值,使用大的量化阶去编码大的差值。
- 使用过去的样本值估算下一个输入样本的预测值,使实际样本值和预测值之间的差值总是最小
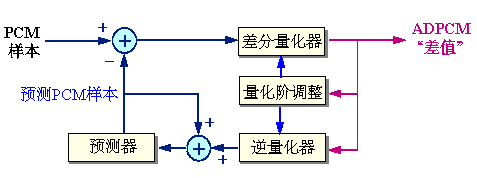
1.4 ADPCM编码框图
接收端的译码器使用与发送端相同的算法,利用传送来的信号来确定量化器和逆量化器中的量化阶大小,并且用它来预测下一个接收信号的预测值。
2 ADPCM代码实现
2.1 ADPCM编码程序逻辑
由待编码文件的起始部分开始,依次读取长度为len的数据段,送入adpcm_encoder,得到编码后的数据,并将结果存入中间文件,直到待编码文件的所有部分都已编码完成。
adpcm_reset(); //此函数只需在编码开始前调用一次
while(待编码文件未读完)
{
读取长度为len的数据段,存入固定的数组内;
执行adpcm_encoder,得到编码后的数据段,以及编码后的数据段长度len_2;
将编码后的数据段顺次存入中间文件内;
}
2.2 ADPCM解码程序逻辑
由中间文件的起始部分开始,依次读取长度为len_2的数据段,送入adpcm_decoder,得到编码后的数据,并将结果存入最终文件,直到中间文件的所有部分都已解码完成。
while(中间文件未读完)
{
读取长度为len_2的数据段,存入固定的数组内;
执行adpcm_decoder,得到解码后的数据段;
将解码后的数据段顺次存入最终文件内;
}2.3 代码示例
//#include <stdafx.h>
#include "ADPCM_thirdparty.h"
static short s_valprev;
static char s_index;
/* Intel ADPCM step variation table */
static int indexTable[16] = {
-1, -1, -1, -1, 2, 4, 6, 8,
-1, -1, -1, -1, 2, 4, 6, 8,
};
static unsigned int stepsizeTable[89] = {
7, 8, 9, 10, 11, 12, 13, 14, 16, 17,
19, 21, 23, 25, 28, 31, 34, 37, 41, 45,
50, 55, 60, 66, 73, 80, 88, 97, 107, 118,
130, 143, 157, 173, 190, 209, 230, 253, 279, 307,
337, 371, 408, 449, 494, 544, 598, 658, 724, 796,
876, 963, 1060, 1166, 1282, 1411, 1552, 1707, 1878, 2066,
2272, 2499, 2749, 3024, 3327, 3660, 4026, 4428, 4871, 5358,
5894, 6484, 7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899,
15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794, 32767
};
// 只能在编码开始前调用一次
void adpcm_thirdparty_reset(void)
{
s_valprev = 0;
s_index = 0;
}
int adpcm_coder(short *indata, unsigned char *outdata, int len)
{
short *inp; /* Input buffer pointer */
unsigned char *outp;/* output buffer pointer */
int val; /* Current input sample value */
int sign; /* Current adpcm sign bit */
unsigned int delta; /* Current adpcm output value */
int diff; /* Difference between val and valprev */
unsigned int udiff; /* unsigned value of diff */
unsigned int step; /* Stepsize */
int valpred; /* Predicted output value */
unsigned int vpdiff;/* Current change to valpred */
int index; /* Current step change index */
unsigned int outputbuffer = 0;/* place to keep previous 4-bit value */
int bufferstep; /* toggle between outputbuffer/output */
int count = 0; /* the number of bytes encoded */
outp = outdata;
inp = indata;
valpred = s_valprev;
index = s_index;
step = stepsizeTable[index];
bufferstep = 1;
while (len-- > 0 ) {
val = *inp++;
/* Step 1 - compute difference with previous value */
diff = val - valpred;
if(diff < 0)
{
sign = 8;
diff = (-diff);
}
else
{
sign = 0;
}
/* diff will be positive at this point */
udiff = (unsigned int)diff;
/* Step 2 - Divide and clamp */
/* Note:
** This code *approximately* computes:
** delta = diff*4/step;
** vpdiff = (delta+0.5)*step/4;
** but in shift step bits are dropped. The net result of this is
** that even if you have fast mul/div hardware you cannot put it to
** good use since the fixup would be too expensive.
*/
delta = 0;
vpdiff = (step >> 3);
if ( udiff >= step ) {
delta = 4;
udiff -= step;
vpdiff += step;
}
step >>= 1;
if ( udiff >= step ) {
delta |= 2;
udiff -= step;
vpdiff += step;
}
step >>= 1;
if ( udiff >= step ) {
delta |= 1;
vpdiff += step;
}
/* Phil Frisbie combined steps 3 and 4 */
/* Step 3 - Update previous value */
/* Step 4 - Clamp previous value to 16 bits */
if ( sign != 0 )
{
valpred -= vpdiff;
if ( valpred < -32768 )
valpred = -32768;
}
else
{
valpred += vpdiff;
if ( valpred > 32767 )
valpred = 32767;
}
/* Step 5 - Assemble value, update index and step values */
delta |= sign;
index += indexTable[delta];
if ( index < 0 ) index = 0;
if ( index > 88 ) index = 88;
step = stepsizeTable[index];
/* Step 6 - Output value */
if ( bufferstep != 0 ) {
outputbuffer = (delta << 4);
} else {
*outp++ = (char)(delta | outputbuffer);
count++;
}
bufferstep = !bufferstep;
}
/* Output last step, if needed */
if ( bufferstep == 0 )
{
*outp++ = (char)outputbuffer;
count++;
}
s_valprev = (short)valpred;
s_index = (char)index;
return count;
}
int adpcm_decoder(unsigned char *indata, short *outdata, int len)
{
unsigned char *inp; /* Input buffer pointer */
short *outp; /* output buffer pointer */
unsigned int sign; /* Current adpcm sign bit */
unsigned int delta; /* Current adpcm output value */
unsigned int step; /* Stepsize */
int valpred; /* Predicted value */
unsigned int vpdiff;/* Current change to valpred */
int index; /* Current step change index */
unsigned int inputbuffer = 0;/* place to keep next 4-bit value */
int bufferstep; /* toggle between inputbuffer/input */
int count = 0;
outp = outdata;
inp = indata;
valpred = s_valprev;
index = (int)s_index;
step = stepsizeTable[index];
bufferstep = 0;
len *= 2;
while ( len-- > 0 ) {
/* Step 1 - get the delta value */
if ( bufferstep != 0 ) {
delta = inputbuffer & 0xf;
} else {
inputbuffer = (unsigned int)*inp++;
delta = (inputbuffer >> 4);
}
bufferstep = !bufferstep;
/* Step 2 - Find new index value (for later) */
index += indexTable[delta];
if ( index < 0 ) index = 0;
if ( index > 88 ) index = 88;
/* Step 3 - Separate sign and magnitude */
sign = delta & 8;
delta = delta & 7;
/* Phil Frisbie combined steps 4 and 5 */
/* Step 4 - Compute difference and new predicted value */
/* Step 5 - clamp output value */
/*
** Computes 'vpdiff = (delta+0.5)*step/4', but see comment
** in adpcm_coder.
*/
vpdiff = step >> 3;
if ( (delta & 4) != 0 ) vpdiff += step;
if ( (delta & 2) != 0 ) vpdiff += step>>1;
if ( (delta & 1) != 0 ) vpdiff += step>>2;
if ( sign != 0 )
{
valpred -= vpdiff;
if ( valpred < -32768 )
valpred = -32768;
}
else
{
valpred += vpdiff;
if ( valpred > 32767 )
valpred = 32767;
}
/* Step 6 - Update step value */
step = stepsizeTable[index];
/* Step 7 - Output value */
*outp++ = (short)valpred;
count++;
}
s_valprev = (short)valpred;
s_index = (char)index;
return count;
}
3 ADPCM解码算法在某蓝牙主设备上的应用
3.1 待解包的帧格式
data[0] = 0x88 // 帧头部
data[1] // 帧编号,范围0x00-0xff
data[2]~data[21] // 编码后的数据域,20字节
data[22] = 0x0d // 帧尾部第1字节
data[23] = 0x0a // 帧尾部第2字节3.2 示例代码
截取有效数据域:
#define ADPCM_GROUP_SIZE 60
#define ADPCM_FRAME_SIZE 20
#define ADPCM_GROUP_FRAME_NUM 3
#define ADPCM_GROUP_HEADER_SIZE 2
#define ADPCM_GROUP_TAILER_SIZE 2
if (ulReadFileSize < ulSBCTempFileSize)
{
if (ucADPCM_CheckIfFindGroupHeader(fTemp))
{
fseek(fTemp, (ADPCM_FRAME_SIZE + ADPCM_GROUP_HEADER_SIZE), SEEK_CUR);
if (ucADPCM_CheckIfFindGroupTail(fTemp))
{
usFrameCnt++;
fseek(fTemp, -ADPCM_FRAME_SIZE, SEEK_CUR);
fread(ucADPCMBuffer, ADPCM_FRAME_SIZE, 1, fTemp);
fseek(fTemp, ADPCM_GROUP_TAILER_SIZE, SEEK_CUR);
ulReadFileSize += (ADPCM_FRAME_SIZE+ ADPCM_GROUP_TAILER_SIZE + ADPCM_GROUP_HEADER_SIZE);
ulSBCVoiceDataSize += ADPCM_FRAME_SIZE;
ucDecodeState = DECODE_STATE_DECODE_ONE_GROUP;
ulADPCMBufferLen = ADPCM_FRAME_SIZE;
}
else
{
fseek(fTemp, -(ADPCM_FRAME_SIZE + ADPCM_GROUP_HEADER_SIZE - 1), SEEK_CUR);
usIncompleteFrameCnt++;
}
}
else
{
//s_ucADPCMFrameCnt = 0;
fseek(fTemp, 1, SEEK_CUR);
ulReadFileSize++;
}
printf("Incomplete Group = %d, Total Group cnt = %d, ulReadFileSize = %dr", usIncompleteFrameCnt, usFrameCnt,ulReadFileSize);
}
else
{
ucDecodeState = DECODE_STATE_DECODE_SUCCESS;
}解码:
INT16 usDecodedBuffer[ADPCM_FRAME_SIZE*2];
adpcm_decoder(ucADPCMBuffer, usDecodedBuffer, ADPCM_FRAME_SIZE);4 如何理解ADPCM
- ADPCM可以将40个量化精度为16bit的采样值压缩到20Byte,压缩比是4:1
- 假设有40个量化精度为16bit的采样值,这里表示为short sample[40],用ADPCM算法压缩后用encoded_sample[20]表示。encoded_sample[0]和encoded_sample[1]分别存储sample[0]的高字节和低字节。从encoded_sample[2]开始,每个字节的高4位和低4位分别存储了1个sample的特征参数,且后一个sample的特征参数的值是前一个sample特征参数的函数。
- 基于上一点,如果压缩后的encoded_sample[20]在传输过程中出现丢失或误码,就会导致解码后的数据严重失真。所以在传输时建议采用可靠连接,即需要保证每次传输都被正确接收。
5 参考文献
1. 复旦大学课件——话音编码.ppt
2. Audio Signal Processing and Coding.pdf
3. MP3编码算法分析.zip
4. ADPCM文件解码详解
最后
以上就是秀丽冷风最近收集整理的关于ADPCM算法浅析ADPCM算法浅析的全部内容,更多相关ADPCM算法浅析ADPCM算法浅析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复