2013年,我加入了聚美优品,当时成都团队仅有四五个人,负责一些辅助系统的日常运维,比如查查日志等。随着公司规模逐渐的扩大,一些重要的业务往成都迁移,这对成都团队是一个非常大的挑战。业务部署最开始是手工的,我们逐渐觉得应该有一个平台来满足我们的工作,所以我们打造了一个运维平台。
本文将围绕平台里有关自动化的东西做一个介绍,当然我们是一个小团队,不足的地方请大家指正。
传统运维带来的坑
说到运维自动化,前两年还是比较炙手可热的话题。先说一下传统运维的痛点和运维自动化的意义。我们日常运维工作是比较繁琐的,一些研发同学会经常让我们帮他们到服务器上查一下日志、或者是说今天上线一个东西陪他们加一下班部署下环境。这些琐事的事情充斥在我们的大部分工作,导致整个运维的部门产出不高。
还有一个关于标准的问题,这个问题让我们吃了很大的亏,早期聚美内部因为部署习惯千差万别,导致一些项目不可维护,谁去动,谁就死。2014年北京那边负责订单的同事离职,把订单系统的运维工作交接到成都这边来,我们当时面临“双十一”的上线,我们经常两三个通宵的搞,相当痛苦的。传统运维模式还有会带来效率的问题。到服务器上执行命令和部署程序的效率很低,并且非常容易出错,出错之后也不太好排查问题,浪费很多的时间。效率问题就引申出成本的问题,我们云服务器是从提供商那里购买的,需要花很多的时间准备运行环境、上下线,这对公司来说是不小的开支。
我们希望按点下班,陪陪家人什么的。我们运维工程师有一个习惯,电脑喜欢用多个显示器,窗口管理器也喜欢使用平铺的,这样子看上来好象挺牛,但是做的是很杂的一些工作,没什么效益。我们做自动化运维平台的话,就能够把日常遇到的这些个问题给解决掉。
运维自动化的演进
现在说一下运维自动化的演进过程:一开始并没有专门的工具为我们做这些事情;后来逐渐有了运维自动化的一些工具,比如说Bcfg2、Puppet、SaltStack等;最后打造出一个运维自动化的平台。
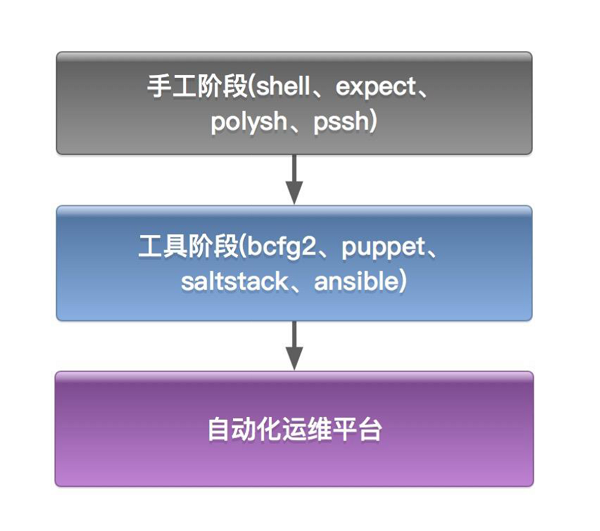
说到工具,确实为我们提供一些提高效率的方法,但还给我们带来了一些其他的问题,比如聚美早期时候采用Bcfg2+Fabric作为服务器部署的工具,由一两个核心的运维负责到主控的机器上采用命令行的方式执行操作,这时效率同样是很低的,而且随着运维工作量的增多,所有的工作都要丢到一两个人的身上,就很不方便。但如果把权限开放出来,对运维操作的权限没有任何限制也不利于审计。
还有一个问题,Fabric执行时执行输出刷屏不好定位问题,比如说执行20台,可能有19台在真正执行,有1台没有执行,输出内容就一闪而过,没有很好的反馈,这时我们将机器上线就会出错。我们需要用平台把这个问题给规避掉。
资产系统是运维自动化的基石
说到运维自动化的话,有一个东西是必须要说的,就是咱们的资产系统,这是运维自动化的基石。
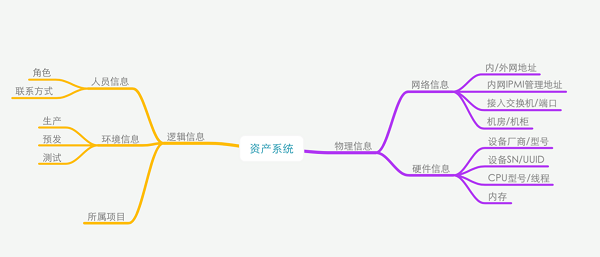
资产系统为运维提供一些基础的信息,比如说机器是属于哪一个项目的、这个机器是运行在什么样的环境。还有一些描述机器的属性,包括IP地址、IPMI管理地址、机器的类型,运维人员信息、所在的机柜、所连接交换端口。有了这些信息在机器出问题的的情况,可以让机房协调我们快速找到机器的位置。我们也可以通过这些信息做资产的盘点。
资产系统的信息包括物理信息和逻辑信息。物理信息包括硬件信息和网络连接的信息,是实实在在存在的信息;逻辑信息需要人工填进去,自动化运维的时候用得到。
SaltStack,自动化运维工具
讲完资产系统,还要讲一个运维自动化的工具——SaltStack。不管使用手工的方式还是使用自动化工具都要熟练的去配置服务器的操作系统、配置各项基础服务。比如说一些系统优化:包括sysctl.conf、ulimit.conf、网卡软中断的绑定。还有机器标准化的修改,包括机器locale、服务器时区、yum(apt)的配置。这些内容的标准化可以统一我们服务器的运行环境,避免出现因为环境差异导致各种奇葩的问题。除此之外还需要对服务器做一些基础服务的配置,每个公司都有些自己编写或者定义的程序需要在每一台服务器上面运行。比如聚美内部有统一登录认证服务、系统监控程序需要在服务器上面安装部署好。
除了系统配置和一些基础服务之外,还需要对各个业务服务熟悉配置。比如说包括负载均衡器:比如LVS、Nginx。还有就是JAVA和PHP等相关的业务:比如Tomcat、FPM、PHPServer。PHPServer是我们内部的一个RPC服务,所有业务主线都用这个。
我们使用SaltStack作为自动化运维可以简化以上一堆服务的配置工作。
自动化运维平台的运行逻辑
有了资产系统、运维自动化工具这两个基础之后,我们就要开始构建自动化运维平台,这个平台就是把资产系统和运维自动化工具结合起来。
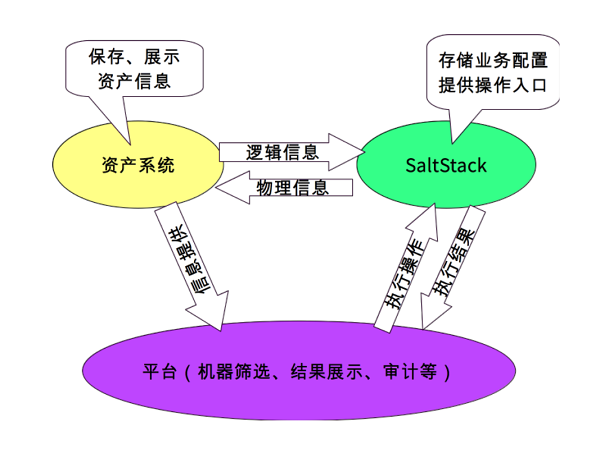
资产系统里面会为平台提供一些基础的信息,资产系统与SaltStack有一个信息交互的过程。比方说刚才说到的一些逻辑信息导入到SaltStack的grains里面去,一些物理信息需要使用SaltStack提交到资产平台。自动化的平台通过SaltStack的API去执行SLS文件,执行完了之后,通过SaltStack的returners调用运维平台的API将执行结果返回回来。
SaltStack是通过grains获取资产系统的信息的,在SaltStack的客户端salt-minion启动之后,SaltStack的master会收到一个“minion_start”的事件,可以在事件上面绑定一个sync_grains的动作,这个动作使得salt-minion资产平台拉所要的信息,把这些信息存到grains里面去。通过SaltStack初始化系统的时候我们会引用一个SLS文件,这个文件的内容是将SaltStack的grains里面保存的信息提交到资产平台。
现在来说说平台调用SaltStack执行的逻辑。一种场景是SaltStack代码要管理多个项目,常规的做法是每个项目定一个SLS文件,定义需要初始化的内容,这种做法也是可以的,但是对平台的开发没那么方便。我们的设计是的是无论多少个项目,根据配置文件来表述这些项目需要初始化的服务,这样子平台的话逻辑会变得相对简单。比如说有一个项目,我们把这个项目要定义的一些东西放到配置文件里面去,比如说它的项目属性、发布目录,还有就是要初始化什么样的服务,把这些东西通过配置文件组装起来。初始化的时候不用关心具体是什么项目,都调用统一的入口文件deploy。在deploy.sls做一些逻辑,按照配置文件初始化好各个服务整个项目就初始化好了。
SaltStack反馈执行效果的逻辑
刚才讲了去平台调用saltstack的逻辑,现在讲一下saltstack把结果反馈到平台的逻辑。
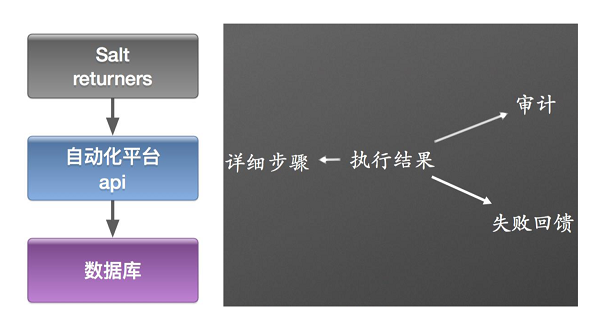
这个很简单的,刚才提到行的时候可能会有一大堆信息输出到屏幕上,没办法跟踪、定位具体哪一个地方出错了。我们就把执行的结果,通过调用平台的API返回到平台里面,平台把返回的结果存储到数据库里面去,后续可以在界面上可以看到每一步执行的详细结果,并且可以根据执行的一些信息做一些审计的工作。
SaltStack部署方法
运维自动化平台以稳定性为第一原则。我们之前老的系统为每一个项目新建一个用户,通过这个用户来运行FPM进程,而咱们新的平台一上线的时候,每个跑FPM的机器用户名都是一样的,执行用户的改变就导致之前写的日志没法写入了,出现了业务的故障。所以之后我们将老的系统迁移到新的自动化平台的时候都需要非常小心。
简单介绍一下SaltStack用户部署的方法。部署SaltStack的客户端salt-minion时候会有一个KEY接收的过程。传统的做法是是用“salt-key -L”命令看一下哪些机器已经注册到平台中,然后再使用“salt-key -a”把key接收进来。在咱们的平台中这个过程是自动的,我们通过reactor的机制来实现的。具体为:机器注册进来之后有一个“salt/auth”的事件,我们把给个事件绑定一个动作,然后在这个动作里面检查key是预定义的来决定是否让这个机器来注册到salt-master上面。如果salt-minion的机器配置目录被删除了,salt-minion重启之后不会注册到salt-master 上面。这时我们只需要在salt-minion的机器上重新跑下配置salt-minion的配置脚本,将统一的KEY下发给它就可以保证salt-minion能够重新被salt-master接受。
打造运维自动化平台遇到的问题
说一下初始化业务环境的时候,遇到的一些问题。
先说资产信息的频繁变更,比如说这个机器可能觉得数量比较多之后,将机器挪到其他项目上去,此时salt-minion 里面记录的grains还是之前项目的信息。出现这种情况需要我们在每次对机器执行初始化等操作的时候先给他绑定同步资产信息的动作。
还有一个是大量添加机器的删除的问题,比方说大促的时候两千台机子,大促完了之后会把机器给下掉,此时salt-master 接收的机器不会被删除,会有很多冗余的信息。我们目前想到的办法是通过cron把salt-master上面的机器列表拿出来ping一下,如果能ping通的就保留在salt-master上面,不能ping通的机器则使用“salt-key -d ”命令给删除掉。还有是一个“max open file”的问题,通过saltstack重启的服务,重启之后进程的“max open file”变成了默认的1024,此时我们需要定制下这些服务的启动脚本,在里面加入“ulimit -n 65535”等内容。
展望
最后,自动化运维平台后面会往容器或者是微服务的方向过渡,而传统的自动化方式对我们来说就没那么重要,我们现在也在做这方面的工作,因为我们公司内部有一些使用FPM的项目,对单个节点效率要求也不太高,放在容器里面运行比较合适,我们也在使用Kubernetes加上Docker做我们下一步的部署方案,但现在只是一个初期阶段。
声明:本文来自「又拍云主办的Open Talk——DevOps与持续交付实践」的演讲内容整理。PPT、速记和现场演讲视频等参见“UPYUN Open Talk”官网。
嘉宾:胡骏,聚美优品高级运维工程师。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件qianshg@csdn.net,另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qianshuguangarch申请入群,备注姓名+公司+职位。
最后
以上就是奋斗电脑最近收集整理的关于详解自动化运维平台的构建过程的全部内容,更多相关详解自动化运维平台内容请搜索靠谱客的其他文章。








发表评论 取消回复