章节
1、Netty学习(一):初识Netty
2、Netty学习(二):Netty的核心组件
3、Netty学习(三):Netty的流程分析
4、Netty学习(四):Netty零拷贝(转载)
5、Netty学习(五):Netty实现UDP的Server端
一、概述
- 本质:Netty的本质是一个网络应用程序框架
- 实现:异步、事件驱动
- 特性:高性能、可维护、快速开发
- 用途:开发服务器和客户端
作为当前最流行的 NIO 框架,Netty 在互联网领域、大数据分布式计算领域、游戏行业、通信行业等获得了广泛的应用,知名的 Elasticsearch 、Dubbo 框架及SpringWebFlux框架内部都采用了 Netty。
二、为什么使用Netty
一.不选择JAVA原生NIO编程的原因
- NIO的类库和API繁杂,使用麻烦,你需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等;
- 需要具备其它的额外技能做铺垫,例如熟悉Java多线程编程,因为NIO编程涉及到Reactor模式,你必须对多线程和网路编程非常熟悉,才能编写出高质量的NIO程序;
- 可靠性能力补齐,工作量和难度都非常大。例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等等,NIO编程的特点是功能开发相对容易,但是可靠性能力补齐工作量和难度都非常大;
- JDK NIO的BUG,例如臭名昭著的epoll bug,它会导致Selector空轮询,最终导致CPU100%。官方声称在JDK1.6版本的update18修复了该问题,但是直到JDK1.7版本该问题仍旧存在,只不过该bug发生概率降低了一些而已,它并没有被根本解决。
二.选择Netty的原因
Netty是业界最流行的NIO框架之一,它的健壮性、功能、性能、可定制性和可扩展性在同类框架中都是首屈一指的,它已经得到成百上千的商用项目验证,例如Hadoop的RPC框架avro使用Netty作为底层通信框架。很多其它业界主流的RPC框架,也使用Netty来构建高性能的异步通信能力。
- API使用简单,开发门槛低;(这个简单是相对的,事实上Netty使用并不简单,有茫茫多的专业词语需要去理解)
- 功能强大,预置了多种编解码功能,支持多种主流协议;
- 定制能力强,可以通过ChannelHandler对通信框架进行灵活的扩展;
- 性能高,通过与其它业界主流的NIO框架对比,Netty的综合性能最优;
- 成熟、稳定,Netty修复了已经发现的所有JDK NIO BUG,业务开发人员不需要再为NIO的BUG而烦恼;
- 社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更多的新功能会被加入;
正是因为这些优点,Netty逐渐成为Java NIO编程的首选框架。
三、Netty的I/O模式
一.经典的三种I/O模式
生活场景
当我们去饭店吃饭时:
• 食堂排队打饭模式:排队在窗口,打好才走;
• 点单、等待被叫模式:等待被叫,好了自己去端;
• 包厢模式:点单后菜直接被端上桌
| 现实模型 | IO模式 | JDK版本 |
|---|---|---|
| 排队打饭模式 | BIO (同步阻塞) | JDK1.4之前 |
| 点单被叫模式 | NIO (同步非阻塞) | JDK1.4 |
| 包厢模式 | AIO(异步非阻塞) | JDK1.7 |
1、阻塞与非阻塞
- 菜没好,要不要死等 -> 数据就绪前要不要等待?
- 阻塞:没有数据传过来时,读会阻塞直到有数据;缓冲区满时,写操作也会阻塞。 非阻塞遇到这些情况,都是直接返回。
2、同步与异步
- 菜好了,谁端 -> 数据就绪后,数据操作谁完成?
- 数据就绪后需要自己去读是同步,数据就绪直接读好再回调给程序是异步。
二.Netty对三种I/O模式的支持
Netty目前仅支持NIO模式,即同步非阻塞。
1、为什么不支持BIO(同步阻塞)
耗资源、效率低
阻塞意味着等待,等待就会一直占用该线程,当连接数高时,大多线程又在等待,就会耗尽系统的线程资源。
2、为什么不支持AIO(异步非阻塞)
Netty其实曾经是支持AIO的,但是因为AIO模式在WINDOWS环境下性能提高很明显,但是在Liunx环境下性能提升不明显,而WINDOWS很少作为服务器使用,netty 也是联系实际情况才有选择地支持高性能的 IO 模式。
四、Netty的开发模式
一.处理WEB请求的体系结构
在web服务中,处理web请求通常有两种体系结构,分别为:thread-based architecture(基于线程的架构)、event-driven architecture(事件驱动模型),
1、thread-based architecture(基于线程的架构)
通俗的说就是:多线程并发模式,一个连接一个线程,服务器每当收到客户端的一个请求, 便开启一个独立的线程来处理。
这种模式一定程度上极大地提高了服务器的吞吐量,由于在不同线程中,之前的请求在read阻塞以后,不会影响到后续的请求。但是,仅适用于于并发量不大的场景,因为:
- 线程需要占用一定的内存资源
- 创建和销毁线程也需一定的代价
- 操作系统在切换线程也需要一定的开销
- 线程处理I/O,在等待输入或输出的这段时间处于空闲的状态,同样也会造成cpu资源的浪费
2、event-driven architecture(事件驱动模型)
事件驱动模型非常常见,当事件被触发运行时,程序感知到不同的时间而产生的不同的动作,比如常见的WEB界面,在点击不同的按钮后会产生不同的效果,为了能够实现这一效果,就需要程序能够实时的感知所关心的事件和触发事件之后要完成的动作。
事件驱动模型有多种设计方式,这里主要介绍Netty的Reactor设计模式。
二.Netty的Reactor设计模式
1、Reactor设计模式的三种版本
生活场景:饭店规模变化
小饭馆: 一个人包揽所有:迎宾、点菜、做饭、上菜、送客等;
普通饭店: 多招几个伙计:大家一起做上面的事情;
海底捞: 进一步分工:搞一个或者多个人专门做迎宾,迎宾完之后有专门的服务员对应一定的桌台。
生活场景类比:
• 饭店伙计:线程
• 迎宾工作:接入连接
• 点菜:请求
• 做菜:业务处理
• 上菜:响应
• 送客:断连
- 一个人包揽所有:迎宾、点菜、做饭、上菜、送客等 -> Reactor 单线程
- 多招几个伙计:大家一起做上面的事情 -> Reactor 多线程模式
- 进一步分工:搞一个或者多个人专门做迎宾 -> 主从 Reactor 多线程模式
2、Reactor 单线程
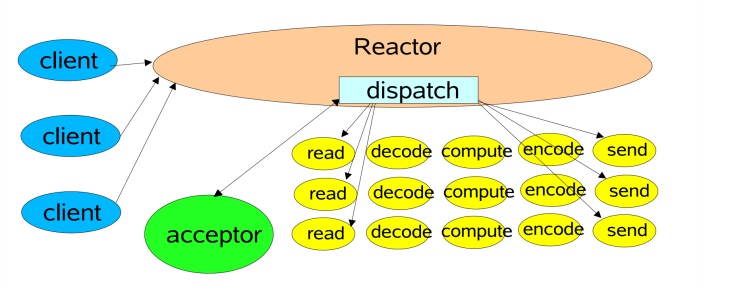
所有操作都在同一个NIO线程处理,在这个单线程中要负责接收请求,处理IO,编解码所有操作,相当于一个饭馆只有一个人,同时负责前台和后台服务,效率低。
EventLoopGroup eventGroup = new NioEventLoopGroup(1);
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(eventGroup);
3、Reactor 多线程
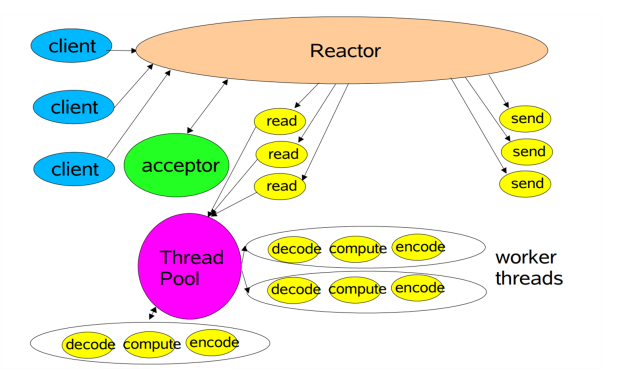
多线程的优点在于有单独的一个线程去处理请求,另外有一个线程池创建多个NIO线程去处理IO。相当于一个饭馆有一个前台负责接待,有很多服务员去做后面的工作,这样效率就比单线程模型提高很多。
EventLoopGroup eventGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(eventGroup);
4、Reactor 主从多线程
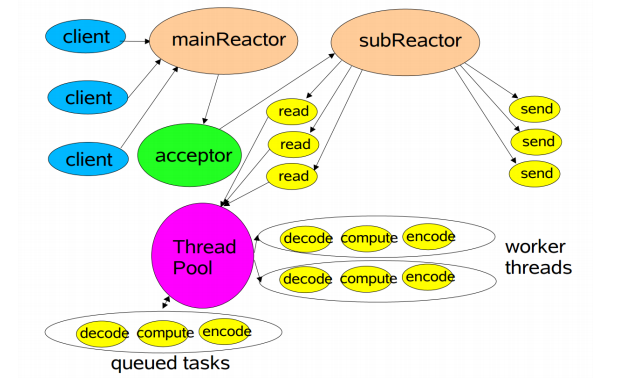
多线程模型的缺点在于并发量很高的情况下,只有一个Reactor单线程去处理是来不及的,就像饭馆只有一个前台接待很多客人也是不够的。为此需要使用主从线程模型。
主从线程模型:一组线程池接收请求,一组线程池处理IO。
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGroup, workerGroup);
五、Netty数据处理
一.TCP的粘包和半包
在客户端发送数据时,实际是把数据写入到了TCP发送缓存里面的。
1、案例
发送两条消息:“ABC”,“DEF”,那么对方接收到的消息不一定是这种格式的,对方可能一次性就接收到“ABCDEF”,也可能分好几次接收到“AB”,“CD”,“EF”,或者更为恶劣一次接收到了两个消息“A”,“BCDEF”。那么这样一次接收两个消息的称为粘包现象,分三次四接收到多个不完整的现象是半包现象。
2、粘包
如果发送的包的大小比TCP发送缓存容量小,并且TCP缓存可以存放多个包,那么客户端和服务端的一次通信就可能传递了多个包,这时候服务端从接受缓存就可能一下读取了多个包
3、粘包的主要原因:
发送方每次写入数据 < 套接字缓冲区大小,接收方读取套接字缓冲区数据不够及时。
4、半包
顾名思义就是接收到半个包,如果发送的包的大小比TCP发送缓存的容量大,那么这个数据包就会被分成多个包,通过socket多次发送到服务端,服务端第一次从接受缓存里面获取的数据,实际是整个包的一部分,半包不是说只收到了全包的一半,是说收到了全包的一部分。
5、半包的主要原因
发送方写入数据 > 套接字缓冲区大小,还有就是发送的数据大于协议的MTU(Maximum Transmission Unit 最大传输单元)的时候必须拆包。(MTU其实就是TCP协议每层的大小
二.Netty对粘包和半包的处理
1、封装成帧
封装成帧,找出消息的边界
封装成帧有三种方式
1.固定长度
比较浪费空间

2.分隔符进行切分(常用于第三方接口)
需要i进行转义
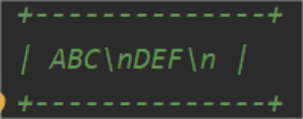
3.固定长度字段存个内容的长度信息
长度理论上有限制,需提前预知可能的最大长度从而定义长度占用字节数
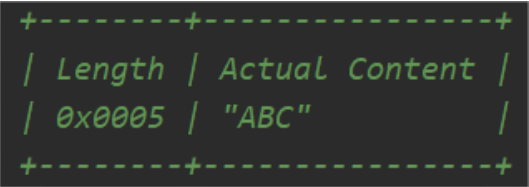
2、利用特定的数据格式
XML或者JSON,他的<>和{}都是成对出现的,只需要找出对应的边界即可。
三.Netty的二次编解码
1、为什么需要二次编解码
为什么编解码要分为两层,难道一层不可以吗?
一层当然是可以的,但是这样就没有了分层,导致代码的耦合度很高,如果有新的数据需要进行编解码,就要修改一大堆代码。
2、二次编解码
在项目中,除了可选的的压缩解压缩之外,还需要一层解码,因为一次解码的结果是字节,需要和项目中所使用的对象做转化,方便使用,这层解码器可以称为“二次解码器”,相应的,对应的编码器是为了将 Java 对象转化成字节流方便存储或传输。
流程如下
1.一次解码器:ByteToMessageDecoder
io.netty.buffer.ByteBuf (原始数据流)-> io.netty.buffer.ByteBuf (用户数据)
2.二次解码器:MessageToMessageDecoder
io.netty.buffer.ByteBuf (用户数据)-> Java Object
3、常用的二次编解码方式
Netty支持多种编解码方式,
• Java 序列化
• Marshaling
• XML
• JSON
• MessagePack
• Protobuf
• 其他
最后
以上就是尊敬乌冬面最近收集整理的关于Netty学习(一):初识Netty章节一、概述二、为什么使用Netty三、Netty的I/O模式四、Netty的开发模式五、Netty数据处理的全部内容,更多相关Netty学习(一):初识Netty章节一、概述二、为什么使用Netty三、Netty内容请搜索靠谱客的其他文章。








发表评论 取消回复