写在前面
我的需求
- 嗯,有几台很老的机器,上面部署的几个很老的应用
- 我需要每周对机器上的一些内存,磁盘,线程,应用和数据库进行
巡查监控,输出运维报告 - 因为是很老的东西,所以不敢随便乱动,怕掉坑里.
- 每次巡查都是通过通过命令行的方式一个一个指标处理的。
我是这样做的
- 写了一个
巡查脚本,输出一些需要监控的核心指标 - 脚本获取指标只使用系统自带的一些命令,没有安装任何工具。
- 这里要说明:这种方式很 old,对于这样的多机器
自动化巡查监控 - 如果只是基础指标监控,
轻量一点可以使用: Ansible利用template等模块,魔法变量、系统变量直接获取指标信息- 或者
ansible-galaxy找找有没有相关的角色 - 如果需要
告警、监控触发器、自动发现、主被动监控之类的功能,则需要部署一些重量级的: - 可以使用
Prometheus、Zabbix、Nagios、Cacti等 - 通过容器化的方式也是很容易实现的。
我的生命不长,但是,如你所说,我是自己生命的主宰。-----《阳光姐妹淘》
下面就脚本和小伙伴简单介绍下,如果小伙伴也有我这样的情况,可以参考。主要监控信息有以下几部分内容
- 系统基础信息
- 内存交换分区相关信息
- CPU相关信息
- 磁盘和IO相关信息
- 进程相关信息
- 网络相关信息
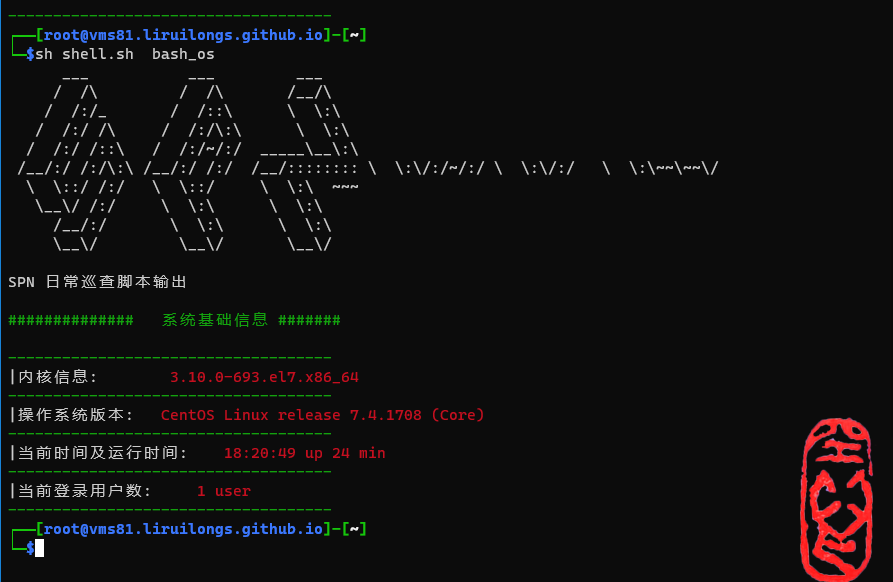
系统基础信息
系统基础信息包括一下几部分:
- 内核信息
- 操作系统版本
- 当前时间及系统运行时间
- 当前登录用户数
┌──[root@vms81.liruilongs.github.io]-[~]
└─$sh shell.sh bash_os
SPN 日常巡查脚本输出
############## 系统基础信息 #######
------------------------------------
|内核信息: 3.10.0-693.el7.x86_64
------------------------------------
|操作系统版本: CentOS Linux release 7.4.1708 (Core)
------------------------------------
|当前时间及运行时间: 18:06:22 up 9 min
------------------------------------
|当前登录用户数: 1 user
------------------------------------
对应的脚本中的函数
function bash_os() {
# "系统基础信息"
#内核信息
kernel=$(uname -r)
#操作系统版本
release=$(cat /etc/redhat-release)
#主机名称
hostname=$HOSTNAME
#当前时间及运行时间
dateload=$(uptime | awk -F "," '{print $1}')
# 当前登录用户数
users=$(uptime | awk -F "," '{print $2}')
echo -e "n�33[32m############## 系统基础信息 #######�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|内核信息:�33[31m $kernel �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|操作系统版本:�33[31m $release �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|当前时间及运行时间:�33[31m $dateload �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|当前登录用户数:�33[31m $users �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
内存交换分区相关信息
内存信息包括一下几部分:
- 总内存容量
- 用户程序内存量
- 多进程共享内存量
- 缓存占用内存量
- 空闲内存容量
- 剩余可用内存容量
- 可用内存百分比
- 总的交换分区容量
- 用户使用的交换分区容量
- 剩余交换分区容量
- 可用交换分区占比
################## 内存 ############
------------------------------------
|总内存容量: 3.10G
------------------------------------
|用户程序内存量: 1.21G
------------------------------------
|多进程共享内存量: 0.02G
------------------------------------
|缓存占用内存量: 1759MB
------------------------------------
|空闲内存容量: 0.18G
------------------------------------
|剩余可用内存容量: 1.57G
------------------------------------
|可用内存百分比: 50.68%
------------------------------------
############## 交换分区 #############
------------------------------------
总的交换分区容量: 0.00G
------------------------------------
|用户使用的交换分区容量: 0.00G
------------------------------------
|剩余交换分区容量: 0.00G
------------------------------------
|占用内存资源最多的10个进程列表:
434568 kube-apiserver --advertise-address=192.168.26.81 --allow-privileged=true --token-auth-file=/etc/kubernetes/pki/liruilong.csv --authorization-mode=Node,RBAC --client-ca-file=/etc/kubernetes/pki/ca.crt --enable-admission-plugins=NodeRestriction --enable-bootstrap-token-auth=true --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key --etcd-servers=https://127.0.0.1:2379 --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key --requestheader-allowed-names=front-proxy-client --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --secure-port=6443 --service-account-issuer=https://kubernetes.default.svc.cluster.local --service-account-key-file=/etc/kubernetes/pki/sa.pub --service-account-signing-key-file=/etc/kubernetes/pki/sa.key --service-cluster-ip-range=10.96.0.0/12 --tls-cert-file=/etc/kubernetes/pki/apiserver.crt --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
140716 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.5
95636 kube-controller-manager --allocate-node-cidrs=true --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf --bind-address=127.0.0.1 --client-ca-file=/etc/kubernetes/pki/ca.crt --cluster-cidr=10.244.0.0/16 --cluster-name=kubernetes --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt --cluster-signing-key-file=/etc/kubernetes/pki/ca.key --controllers=*,bootstrapsigner,tokencleaner --kubeconfig=/etc/kubernetes/controller-manager.conf --leader-elect=true --port=0 --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --root-ca-file=/etc/kubernetes/pki/ca.crt --service-account-private-key-file=/etc/kubernetes/pki/sa.key --service-cluster-ip-range=10.96.0.0/12 --use-service-account-credentials=true
94252 etcd --advertise-client-urls=https://192.168.26.81:2379 --cert-file=/etc/kubernetes/pki/etcd/server.crt --client-cert-auth=true --data-dir=/var/lib/etcd --initial-advertise-peer-urls=https://192.168.26.81:2380 --initial-cluster=vms81.liruilongs.github.io=https://192.168.26.81:2380 --key-file=/etc/kubernetes/pki/etcd/server.key --listen-client-urls=https://127.0.0.1:2379,https://192.168.26.81:2379 --listen-metrics-urls=http://127.0.0.1:2381 --listen-peer-urls=https://192.168.26.81:2380 --name=vms81.liruilongs.github.io --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt --peer-client-cert-auth=true --peer-key-file=/etc/kubernetes/pki/etcd/peer.key --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt --snapshot-count=10000 --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
90888 /usr/bin/dockerd --insecure-registry 192.168.26.56 -H fd:// --containerd=/run/containerd/containerd.sock
44736 /usr/bin/containerd
43584 calico-node -felix
40900 kube-scheduler --authentication-kubeconfig=/etc/kubernetes/scheduler.conf --authorization-kubeconfig=/etc/kubernetes/scheduler.conf --bind-address=127.0.0.1 --kubeconfig=/etc/kubernetes/scheduler.conf --leader-elect=true --port=0
37572 calico-node -allocate-tunnel-addrs
37284 calico-node -confd%
------------------------------------
对应的脚本中的函数
function memory() {
# 内存相关数据统计`free -m`
#总内存容量
mem_total=$(free -m | awk '/Mem/{printf "%.2fG", $2/1024}')
# 用户程序占用内存量
mem_user=$(free -m | awk '/Mem/{printf "%.2fG", $3/1024}')
# 多进程共享占用内存量
mem_shared=$(free -m | awk '/Mem/{printf "%.2fG", $5/1024}')
#缓存占用内存量
mem_buff_cache=$(free -m | awk '/Mem/{printf "%.fMB", $(NF-1)}')
#空闲内存容量
mem_free=$(free -m | awk '/Mem/{printf "%.2fG", $4/1024 }')
# 剩余可用内存容量
mem_available=$(free -m | awk 'NR==2{printf "%.2fG",$NF/1024}')
# 可用内存使用占比
mem_percentage=$(free -m | awk '/Mem/{printf "%.2f", $NF/$2*100}')
#总的交换分区容量
swap_total=$(free -m | awk '/Swap/{printf "%.2fG", $2/1024}')
#用户使用的交换分区容量
swap_user=$(free -m | awk '/Swap/{printf "%.2fG",$3/1024}')
#剩余交换分区容量
swap_free=$(free -m | awk '/Swap/{printf "%.2fG",$4/1024}')
#可用交换分区占比
swap_percentage=$(free -m | awk '/Swap/{printf "%.2f",$4/$2*100}')
#占用内存资源最多的10个进程列表
top_proc_mem=$(ps --no-headers -eo rss,args | sort -k1 -n -r | head -10)
echo -e "n�33[32m################## 内存 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|总内存容量:�33[31m $mem_total �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|用户程序内存量:�33[31m $mem_user �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|多进程共享内存量:�33[31m $mem_shared �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|缓存占用内存量:�33[31m $mem_buff_cache �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|空闲内存容量:�33[31m $mem_free �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|剩余可用内存容量:�33[31m $mem_available �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|可用内存百分比:�33[31m $mem_percentage% �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "�33[32m############## 交换分区 #############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "总的交换分区容量:�33[31m $swap_total �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|用户使用的交换分区容量:�33[31m $swap_user �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|剩余交换分区容量:�33[31m ${swap_free}"
echo -e "�33[32m------------------------------------�33[0m"
if [ $(free -m | awk '/Swap/{print $2}') -ne 0 ]; then
echo -e "|可用交换分区占比:�33[31m $swap_percentage% �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
fi
echo -e "|占用内存资源最多的10个进程列表:"
echo -e "�33[31m$top_proc_mem% �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
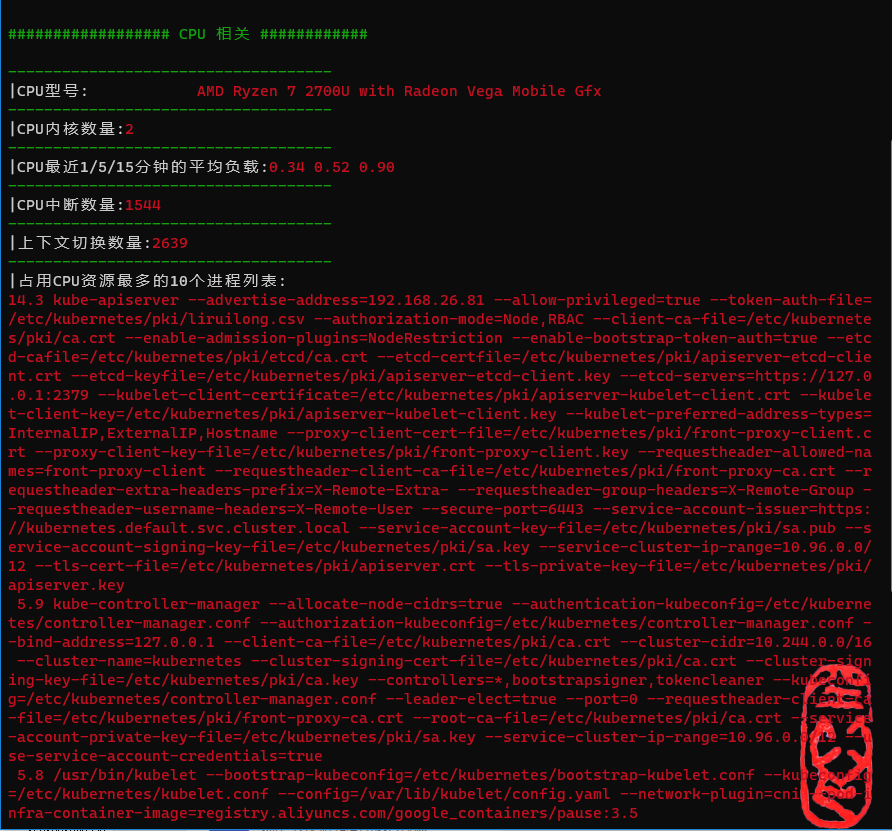
CPU相关信息
CPU相关信息包含:
- CPU型号
- CPU内核数量
- CPU最近1/5/15分钟的平均负载
- 当前CPU中断数量
- 当前上下文切换数量
################## CPU 相关 ############
------------------------------------
|CPU型号: AMD Ryzen 7 2700U with Radeon Vega Mobile Gfx
------------------------------------
|CPU内核数量:2
------------------------------------
|CPU最近1/5/15分钟的平均负载:0.34 0.52 0.90
------------------------------------
|CPU中断数量:1544
------------------------------------
|上下文切换数量:2639
------------------------------------
|占用CPU资源最多的10个进程列表:
14.3 kube-apiserver --advertise-address=192.168.26.81 --allow-privileged=true --token-auth-file=/etc/kubernetes/pki/liruilong.csv --authorization-mode=Node,RBAC --client-ca-file=/etc/kubernetes/pki/ca.crt --enable-admission-plugins=NodeRestriction --enable-bootstrap-token-auth=true --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key --etcd-servers=https://127.0.0.1:2379 --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key --requestheader-allowed-names=front-proxy-client --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --secure-port=6443 --service-account-issuer=https://kubernetes.default.svc.cluster.local --service-account-key-file=/etc/kubernetes/pki/sa.pub --service-account-signing-key-file=/etc/kubernetes/pki/sa.key --service-cluster-ip-range=10.96.0.0/12 --tls-cert-file=/etc/kubernetes/pki/apiserver.crt --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
5.9 kube-controller-manager --allocate-node-cidrs=true --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf --bind-address=127.0.0.1 --client-ca-file=/etc/kubernetes/pki/ca.crt --cluster-cidr=10.244.0.0/16 --cluster-name=kubernetes --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt --cluster-signing-key-file=/etc/kubernetes/pki/ca.key --controllers=*,bootstrapsigner,tokencleaner --kubeconfig=/etc/kubernetes/controller-manager.conf --leader-elect=true --port=0 --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --root-ca-file=/etc/kubernetes/pki/ca.crt --service-account-private-key-file=/etc/kubernetes/pki/sa.key --service-cluster-ip-range=10.96.0.0/12 --use-service-account-credentials=true
5.8 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.5
5.1 calico-node -felix
3.4 etcd --advertise-client-urls=https://192.168.26.81:2379 --cert-file=/etc/kubernetes/pki/etcd/server.crt --client-cert-auth=true --data-dir=/var/lib/etcd --initial-advertise-peer-urls=https://192.168.26.81:2380 --initial-cluster=vms81.liruilongs.github.io=https://192.168.26.81:2380 --key-file=/etc/kubernetes/pki/etcd/server.key --listen-client-urls=https://127.0.0.1:2379,https://192.168.26.81:2379 --listen-metrics-urls=http://127.0.0.1:2381 --listen-peer-urls=https://192.168.26.81:2380 --name=vms81.liruilongs.github.io --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt --peer-client-cert-auth=true --peer-key-file=/etc/kubernetes/pki/etcd/peer.key --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt --snapshot-count=10000 --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
2.6 /usr/bin/dockerd --insecure-registry 192.168.26.56 -H fd:// --containerd=/run/containerd/containerd.sock
0.7 kube-scheduler --authentication-kubeconfig=/etc/kubernetes/scheduler.conf --authorization-kubeconfig=/etc/kubernetes/scheduler.conf --bind-address=127.0.0.1 --kubeconfig=/etc/kubernetes/scheduler.conf --leader-elect=true --port=0
0.6 /usr/bin/containerd
0.4 /speaker --port=7472 --config=config --log-level=info
0.3 [rcu_sched]
------------------------------------
对应的脚本中的函数
function cpu() {
#CPU型号
cpu_info=$(LANG=C lscpu | awk -F: '/Model name/ {print $2}')
#CPU内核数量
cpu_core=$(awk '/processor/{core++} END{print core}' /proc/cpuinfo)
#CPU最近1/5/15分钟的平均负载
load1515=$(uptime | sed 's/,/ /g' | awk '{for(i=NF-2;i<=NF;i++)print $i }' | xargs)
#发生中断数量
irq=$(vmstat 1 1 | awk 'NR==3{print $11}')
#上下文切换数量
cs=$(vmstat 1 1 | awk 'NR==3{print $12}')
#占用CPU资源最多的10个进程列表
top_proc_cpu=$(ps --no-headers -eo %cpu,args | sort -k1 -n -r | head -10)
echo -e "n�33[32m################## CPU 相关 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU型号:�33[31m$cpu_info �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU内核数量:�33[31m$cpu_core �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU最近1/5/15分钟的平均负载:�33[31m$load1515 �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU中断数量:�33[31m$irq �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|上下文切换数量:�33[31m$cs �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|占用CPU资源最多的10个进程列表:"
echo -e "�33[31m$top_proc_cpu �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
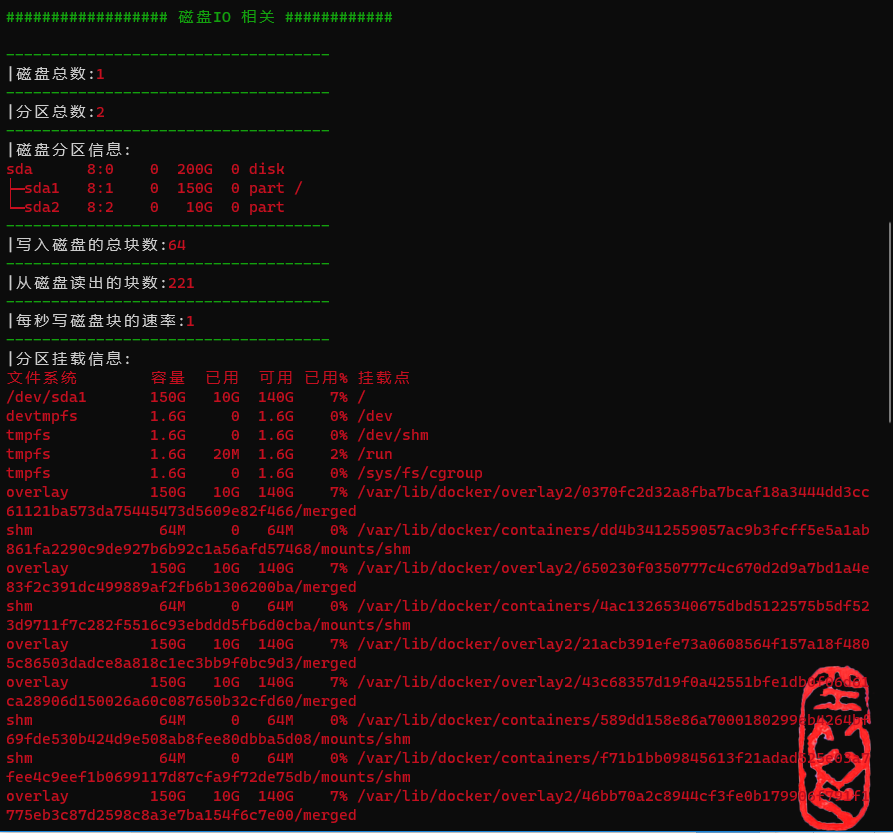
磁盘和IO相关信息
磁盘和IO相关信息包括:
- 磁盘总数
- 分区总数
- 磁盘分区信息
- 写入磁盘的总块数
- 从磁盘读出的块数
- 每秒写磁盘块的速率
- 分区挂载信息

对应的脚本中的函数
################## 磁盘IO 相关 ############
------------------------------------
|磁盘总数:1
------------------------------------
|分区总数:2
------------------------------------
|磁盘分区信息:
sda 8:0 0 200G 0 disk
├─sda1 8:1 0 150G 0 part /
└─sda2 8:2 0 10G 0 part
------------------------------------
|写入磁盘的总块数:74
------------------------------------
|从磁盘读出的块数:272
------------------------------------
|每秒写磁盘块的速率:2
------------------------------------
|分区挂载信息:
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda1 150G 10G 140G 7% /
devtmpfs 1.6G 0 1.6G 0% /dev
tmpfs 1.6G 0 1.6G 0% /dev/shm
tmpfs 1.6G 20M 1.6G 2% /run
tmpfs 1.6G 0 1.6G 0% /sys/fs/cgroup
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/0370fc2d32a8fba7bcaf18a3444dd3cc61121ba573da75445473d5609e82f466/merged
shm 64M 0 64M 0% /var/lib/docker/containers/dd4b3412559057ac9b3fcff5e5a1ab861fa2290c9de927b6b92c1a56afd57468/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/650230f0350777c4c670d2d9a7bd1a4e83f2c391dc499889af2fb6b1306200ba/merged
shm 64M 0 64M 0% /var/lib/docker/containers/4ac13265340675dbd5122575b5df523d9711f7c282f5516c93ebddd5fb6d0cba/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/21acb391efe73a0608564f157a18f4805c86503dadce8a818c1ec3bb9f0bc9d3/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/43c68357d19f0a42551bfe1db0f06d61ca28906d150026a60c087650b32cfd60/merged
shm 64M 0 64M 0% /var/lib/docker/containers/589dd158e86a7000180299eb4264bf69fde530b424d9e508ab8fee80dbba5d08/mounts/shm
shm 64M 0 64M 0% /var/lib/docker/containers/f71b1bb09845613f21adad525e03a7fee4c9eef1b0699117d87cfa9f72de75db/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/46bb70a2c8944cf3fe0b179906f791f1775eb3c87d2598c8a3e7ba154f6c7e00/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/1d542264230ed8d093971177f13ba90700d5b6d4c8703e89eafe3d548fcd15ab/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/e5023f46fda09e5a04cf392ae0461511930a9095196c0136f0b5e78331488556/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/3e06461dcde6535e1857fb32d5a6b9b7e24479fdde083c2e0a23302e747cb926/merged
tmpfs 3.1G 12K 3.1G 1% /var/lib/kubelet/pods/8dc44e6f-10c8-4336-8d17-3d7d30e068d7/volumes/kubernetes.io~projected/kube-api-access-lrqtd
tmpfs 170M 12K 170M 1% /var/lib/kubelet/pods/3c16b2c9-72b8-42d2-9c56-f572f1c3d715/volumes/kubernetes.io~projected/kube-api-access-cnrsg
tmpfs 3.1G 12K 3.1G 1% /var/lib/kubelet/pods/c468b66c-2c95-49b0-8081-241ae7b7ddb5/volumes/kubernetes.io~projected/kube-api-access-mlwx6
tmpfs 170M 12K 170M 1% /var/lib/kubelet/pods/8628a04d-61f2-42a7-aa29-10318d5628ec/volumes/kubernetes.io~projected/kube-api-access-rqjht
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/97dbbac8525cec33bc85856090675edc8463e46960bb5b5e50347e59eeb45ffc/merged
shm 64M 0 64M 0% /var/lib/docker/containers/a1d8a8046b2e0fde29fe8b36b8621c5773a5c557a6ab7c6a6ffea1d672a87e31/mounts/shm
tmpfs 3.1G 12K 3.1G 1% /var/lib/kubelet/pods/95d09836-f343-4814-8daf-f41b90a5da63/volumes/kubernetes.io~projected/kube-api-access-8zzsm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/2c9c06fb46aac0de072f2f27d6c20b9da6e9891065558341d569f9dfbfbab4ec/merged
tmpfs 3.1G 12K 3.1G 1% /var/lib/kubelet/pods/dbe168eb-be54-4248-a1ac-c98e209dd735/volumes/kubernetes.io~projected/kube-api-access-56x97
shm 64M 0 64M 0% /var/lib/docker/containers/523c33b8c407e3a71150ffedb34035074bf4777f18cf26067c3c033119bb67b2/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/601f14c96dc128154eba3be7db81c0585b90ded24ca3f833d860dbfed57bca8e/merged
shm 64M 0 64M 0% /var/lib/docker/containers/389ca895399660bdc841974db7f01b71e38955c4eabbba9be680a2ef17ee7867/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/cd288d78dde65645df76d6dc1e56acada16a699412db9a0fe723d7f07dcc25b9/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/49742d1a276e657bf45bd80be2f375282af29490dad15bc4c3ba99beeb9bd115/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/76a1d6e77213fa534970e4a3d5e912e59f2b46e3a804bec37378fcca52e15183/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/484276ff32ad852232ca4ce9c623d8fbf00ae4bd7854ac45e480cb2e9bd8b5e6/merged
shm 64M 0 64M 0% /var/lib/docker/containers/ac12271bfe6d640b98634b054d45711c12cdecc9dca5d7dff19e62d2959bf9a9/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/269e190d7572774c7c68e1b33d11d3744913e9dc55bcd95d2a610fa1410036ac/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/753af2fd5b0d4a80fc592fd30d58666314f40b2bc532524679c1cb50bf8c863b/merged
shm 64M 0 64M 0% /var/lib/docker/containers/745e022eb0250c13428ccc0cee5711d00781ecab73b5162efb1feba31873691b/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/c429b395aeb4fa89c1d3f962659fcd3401daf66478b050978de298d072e8a070/merged
shm 64M 0 64M 0% /var/lib/docker/containers/8f02998d5eaf938b574bc0786942b0e706af6ed9bce6162331ab8e665d863ac4/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/8904325f526fa3cd547065643b5d91a524fa5500d0e1da1fdbed7cbcefefcfbe/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/76d066655c0543fe08b4533ffe458df11a067416bf34cea2044d516ddc383791/merged
tmpfs 318M 0 318M 0% /run/user/0
tmpfs 3.1G 12K 3.1G 1% /var/lib/kubelet/pods/a14eb2df-b067-46a2-99e9-e4aba955832b/volumes/kubernetes.io~projected/kube-api-access-qqjjw
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/7767f584dd56da2abf00246a80fc672de6b42f9254bbcc287e2018f507c6f9e3/merged
shm 64M 0 64M 0% /var/lib/docker/containers/399881a65fdd43e1285e0fa5999f49e5935258cf28c79320d0358d8211449b03/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/cfd2cad23e6b790f5c41bb61ed9b474534623e7fe47d593375c5ab44bc2505df/merged
tmpfs 3.1G 0 3.1G 0% /var/lib/kubelet/pods/be82f8c8-deb7-4613-a9ae-26c29a478e09/volumes/kubernetes.io~secret/kubernetes-dashboard-certs
tmpfs 3.1G 12K 3.1G 1% /var/lib/kubelet/pods/be82f8c8-deb7-4613-a9ae-26c29a478e09/volumes/kubernetes.io~projected/kube-api-access-8jlj7
tmpfs 3.1G 12K 3.1G 1% /var/lib/kubelet/pods/23138c5c-1af0-47cf-bae3-96176987cdcf/volumes/kubernetes.io~projected/kube-api-access-m7tn5
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/120df040da0b33e2ca103484488de82c77ba1a7035072cba17369abdb9c11cf5/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/100d7769672fa6f0094af996497671dafda20c15b2b4d7cf6aa19275e48a2b75/merged
shm 64M 0 64M 0% /var/lib/docker/containers/14542965702ed9d933fd27be54fc20104117d3b9590efc96e452f0edef4f5c82/mounts/shm
shm 64M 0 64M 0% /var/lib/docker/containers/b3ba89290656559ea0a7b1d58f0c107c876136dee65bd069ee0f88879d48c7ec/mounts/shm
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/79ff92c12ad8392bffd74e1b495b53d390ac11a3fbf5d738c26619e8eb371473/merged
overlay 150G 10G 140G 7% /var/lib/docker/overlay2/284d770969fb28dd6e1530643a072a90dab620ebe2477c758eb63cd5feb7defa/merged
------------------------------------
function disk_io() {
#分区挂载信息
disk=$(df -h)
# 磁盘总数
disk_total=$(vmstat -D | awk 'NR==1{print $1}')
# 分区总数
disk_sub=$(vmstat -D | awk 'NR==2{print $1}')
#磁盘分区信息
lsblk_=$(lsblk -n)
#写入磁盘的总块数
bo=$(vmstat 1 1 | awk 'NR==3{print $10}')
#从磁盘读出的块数
bi=$(vmstat 1 1 | awk 'NR==3{print $9}')
#每秒写磁盘块的速率
wa=$(vmstat 1 1 | awk 'NR==3{print $16}')
echo -e "n�33[32m################## 磁盘IO 相关 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|磁盘总数:�33[31m$disk_total �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|分区总数:�33[31m$disk_sub �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|磁盘分区信息:"
echo -e "�33[31m$lsblk_ �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|写入磁盘的总块数:�33[31m$bo �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|从磁盘读出的块数:�33[31m$bi �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|每秒写磁盘块的速率:�33[31m$wa �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|分区挂载信息:"
echo -e "�33[31m$disk �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
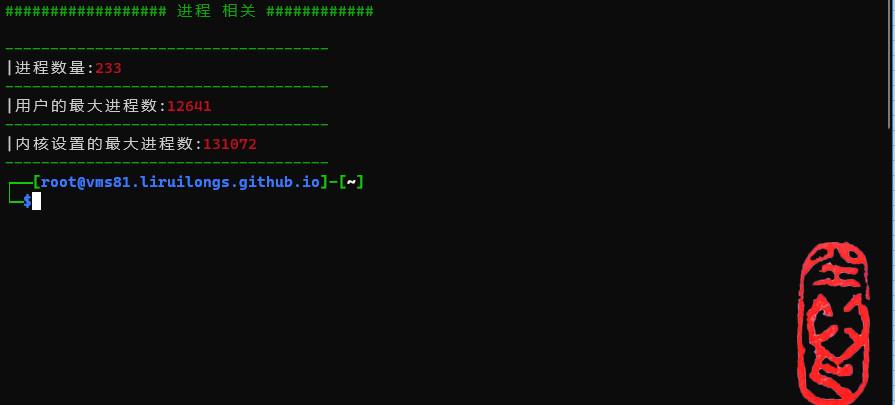
进程相关信息
进程相关信息包括:
- 当前进程数量
- 用户的最大进程数
- 内核设置的最大进程数
################## 进程 相关 ############
------------------------------------
|进程数量:233
------------------------------------
|用户的最大进程数:12641
------------------------------------
|内核设置的最大进程数:131072
------------------------------------
对应的脚本中的函数
function procs() {
#进程数量
procs=$(ps aux | wc -l)
#用户的最大进程数
ulimit_=$(ulimit -u)
#内核设置的最大进程数
pid_max=$(sysctl kernel.pid_max | awk '{print $3}')
echo -e "n�33[32m################## 进程 相关 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|进程数量:�33[31m$procs �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|用户的最大进程数:�33[31m$ulimit_ �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|内核设置的最大进程数:�33[31m$pid_max �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
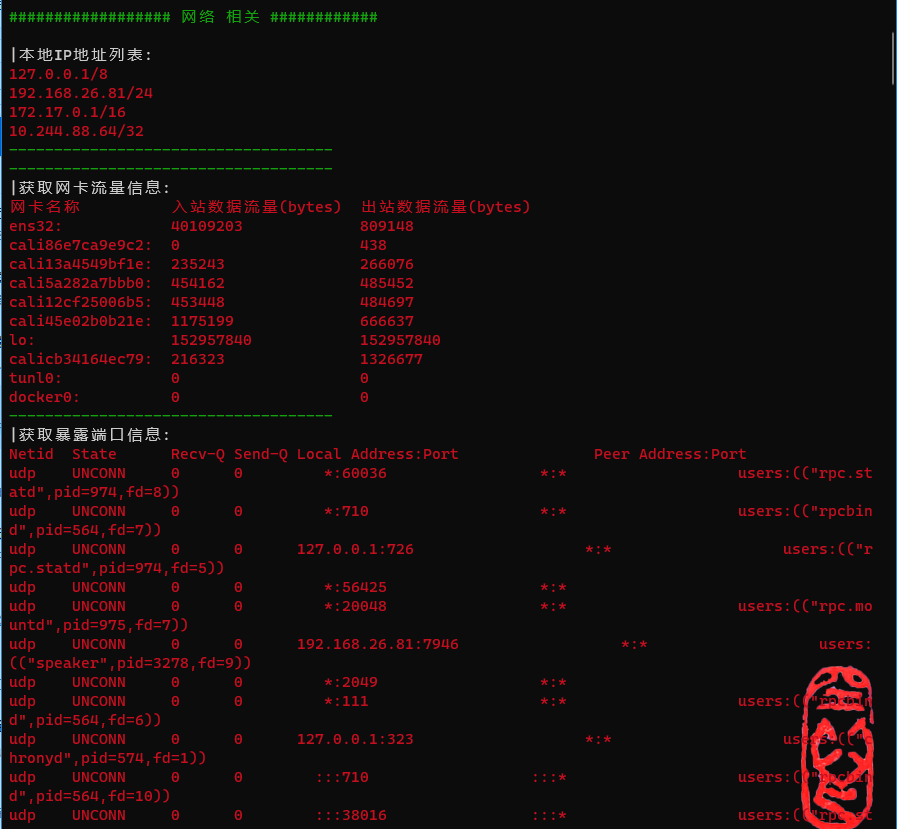
网络相关信息
网络相关信息包括:
- 本地IP地址列表
- 获取网卡流量信息
- 获取暴露端口信息
################## 网络 相关 ############
|本地IP地址列表:
127.0.0.1/8
192.168.26.81/24
172.17.0.1/16
10.244.88.64/32
------------------------------------
------------------------------------
|获取网卡流量信息:
网卡名称 入站数据流量(bytes) 出站数据流量(bytes)
ens32: 40109203 809148
cali86e7ca9e9c2: 0 438
cali13a4549bf1e: 235243 266076
cali5a282a7bbb0: 454162 485452
cali12cf25006b5: 453448 484697
cali45e02b0b21e: 1175199 666637
lo: 152957840 152957840
calicb34164ec79: 216323 1326677
tunl0: 0 0
docker0: 0 0
------------------------------------
|获取暴露端口信息:
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:60036 *:* users:(("rpc.statd",pid=974,fd=8))
udp UNCONN 0 0 *:710 *:* users:(("rpcbind",pid=564,fd=7))
udp UNCONN 0 0 127.0.0.1:726 *:* users:(("rpc.statd",pid=974,fd=5))
udp UNCONN 0 0 *:56425 *:*
udp UNCONN 0 0 *:20048 *:* users:(("rpc.mountd",pid=975,fd=7))
udp UNCONN 0 0 192.168.26.81:7946 *:* users:(("speaker",pid=3278,fd=9))
udp UNCONN 0 0 *:2049 *:*
udp UNCONN 0 0 *:111 *:* users:(("rpcbind",pid=564,fd=6))
udp UNCONN 0 0 127.0.0.1:323 *:* users:(("chronyd",pid=574,fd=1))
udp UNCONN 0 0 :::710 :::* users:(("rpcbind",pid=564,fd=10))
udp UNCONN 0 0 :::38016 :::* users:(("rpc.statd",pid=974,fd=10))
udp UNCONN 0 0 :::20048 :::* users:(("rpc.mountd",pid=975,fd=9))
udp UNCONN 0 0 :::2049 :::*
udp UNCONN 0 0 :::111 :::* users:(("rpcbind",pid=564,fd=9))
udp UNCONN 0 0 :::59526 :::*
udp UNCONN 0 0 ::1:323 :::* users:(("chronyd",pid=574,fd=2))
tcp LISTEN 0 128 127.0.0.1:9099 *:* users:(("calico-node",pid=4355,fd=8))
tcp LISTEN 0 128 192.168.26.81:2379 *:* users:(("etcd",pid=2138,fd=9))
tcp LISTEN 0 128 127.0.0.1:2379 *:* users:(("etcd",pid=2138,fd=8))
.......
对应的脚本中的函数
function network() {
#获取网卡流量信息,接收|发送的数据流量,单位为字节(bytes)
net_monitor=$(cat /proc/net/dev | tail -n +3 | awk 'BEGIN{ print "网卡名称 入站数据流量(bytes) 出站数据流量(bytes)"} {print $1,$2,$10}' | column -t)
#获取暴露端口信息
ip_port=$(ss -ntulpa)
#本地IP地址列表
localip=$(ip a s | awk '/inet /{print $2}' )
echo -e "n�33[32m################## 网络 相关 ############�33[0mn"
echo -e "|本地IP地址列表:"
echo -e "�33[31m$localip �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|获取网卡流量信息:"
echo -e "�33[31m$net_monitor �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|获取暴露端口信息:"
echo -e "�33[31m$ip_port �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
完整的脚本
#!/bin/bash
#@File : shell.sh
#@Time : 2022/01/20 15:48:39
#@Author : Li Ruilong
#@Version : 1.0
#@Desc : SPN 系统维护脚本
#@Contact : 1224965096@qq.com
echo " ___ ___ ___
/ / / / /__/
/ /:/_ / /:: :
/ /:/ / / /:/: :
/ /:/ /:: / /:/~/:/ _______:
/__/:/ /:/: /__/:/ /:/ /__/::::::::
:/:/~/:/ :/:/ :~~~~/
::/ /:/ ::/ :
__/ /:/ : :
/__/:/ : :
__/ __/ __/
"
echo "SPN 日常巡查脚本输出"
# 清理屏幕
clear
function bash_os() {
# "系统基础信息"
#内核信息
kernel=$(uname -r)
#操作系统版本
release=$(cat /etc/redhat-release)
#主机名称
hostname=$HOSTNAME
#当前时间及运行时间
dateload=$(uptime | awk -F "," '{print $1}')
# 当前登录用户数
users=$(uptime | awk -F "," '{print $2}')
echo -e "n�33[32m############## 系统基础信息 #######�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|内核信息:�33[31m $kernel �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|操作系统版本:�33[31m $release �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|当前时间及运行时间:�33[31m $dateload �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|当前登录用户数:�33[31m $users �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
function memory() {
# 内存相关数据统计`free -m`
#总内存容量
mem_total=$(free -m | awk '/Mem/{printf "%.2fG", $2/1024}')
# 用户程序占用内存量
mem_user=$(free -m | awk '/Mem/{printf "%.2fG", $3/1024}')
# 多进程共享占用内存量
mem_shared=$(free -m | awk '/Mem/{printf "%.2fG", $5/1024}')
#缓存占用内存量
mem_buff_cache=$(free -m | awk '/Mem/{printf "%.fMB", $(NF-1)}')
#空闲内存容量
mem_free=$(free -m | awk '/Mem/{printf "%.2fG", $4/1024 }')
# 剩余可用内存容量
mem_available=$(free -m | awk 'NR==2{printf "%.2fG",$NF/1024}')
# 可用内存使用占比
mem_percentage=$(free -m | awk '/Mem/{printf "%.2f", $NF/$2*100}')
#总的交换分区容量
swap_total=$(free -m | awk '/Swap/{printf "%.2fG", $2/1024}')
#用户使用的交换分区容量
swap_user=$(free -m | awk '/Swap/{printf "%.2fG",$3/1024}')
#剩余交换分区容量
swap_free=$(free -m | awk '/Swap/{printf "%.2fG",$4/1024}')
#可用交换分区占比
swap_percentage=$(free -m | awk '/Swap/{printf "%.2f",$4/$2*100}')
#占用内存资源最多的10个进程列表
top_proc_mem=$(ps --no-headers -eo rss,args | sort -k1 -n -r | head -10)
echo -e "n�33[32m################## 内存 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|总内存容量:�33[31m $mem_total �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|用户程序内存量:�33[31m $mem_user �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|多进程共享内存量:�33[31m $mem_shared �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|缓存占用内存量:�33[31m $mem_buff_cache �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|空闲内存容量:�33[31m $mem_free �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|剩余可用内存容量:�33[31m $mem_available �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|可用内存百分比:�33[31m $mem_percentage% �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "�33[32m############## 交换分区 #############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "总的交换分区容量:�33[31m $swap_total �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|用户使用的交换分区容量:�33[31m $swap_user �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|剩余交换分区容量:�33[31m ${swap_free}"
echo -e "�33[32m------------------------------------�33[0m"
if [ $(free -m | awk '/Swap/{print $2}') -ne 0 ]; then
echo -e "|可用交换分区占比:�33[31m $swap_percentage% �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
fi
echo -e "|占用内存资源最多的10个进程列表:"
echo -e "�33[31m$top_proc_mem% �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
function cpu() {
#CPU型号
cpu_info=$(LANG=C lscpu | awk -F: '/Model name/ {print $2}')
#CPU内核数量
cpu_core=$(awk '/processor/{core++} END{print core}' /proc/cpuinfo)
#CPU最近1/5/15分钟的平均负载
load1515=$(uptime | sed 's/,/ /g' | awk '{for(i=NF-2;i<=NF;i++)print $i }' | xargs)
#发生中断数量
irq=$(vmstat 1 1 | awk 'NR==3{print $11}')
#上下文切换数量
cs=$(vmstat 1 1 | awk 'NR==3{print $12}')
#占用CPU资源最多的10个进程列表
top_proc_cpu=$(ps --no-headers -eo %cpu,args | sort -k1 -n -r | head -10)
echo -e "n�33[32m################## CPU 相关 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU型号:�33[31m$cpu_info �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU内核数量:�33[31m$cpu_core �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU最近1/5/15分钟的平均负载:�33[31m$load1515 �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|CPU中断数量:�33[31m$irq �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|上下文切换数量:�33[31m$cs �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|占用CPU资源最多的10个进程列表:"
echo -e "�33[31m$top_proc_cpu �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
function disk_io() {
#分区挂载信息
disk=$(df -h)
# 磁盘总数
disk_total=$(vmstat -D | awk 'NR==1{print $1}')
# 分区总数
disk_sub=$(vmstat -D | awk 'NR==2{print $1}')
#磁盘分区信息
lsblk_=$(lsblk -n)
#写入磁盘的总块数
bo=$(vmstat 1 1 | awk 'NR==3{print $10}')
#从磁盘读出的块数
bi=$(vmstat 1 1 | awk 'NR==3{print $9}')
#每秒写磁盘块的速率
wa=$(vmstat 1 1 | awk 'NR==3{print $16}')
echo -e "n�33[32m################## 磁盘IO 相关 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|磁盘总数:�33[31m$disk_total �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|分区总数:�33[31m$disk_sub �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|磁盘分区信息:"
echo -e "�33[31m$lsblk_ �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|写入磁盘的总块数:�33[31m$bo �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|从磁盘读出的块数:�33[31m$bi �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|每秒写磁盘块的速率:�33[31m$wa �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|分区挂载信息:"
echo -e "�33[31m$disk �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
function procs() {
#进程数量
procs=$(ps aux | wc -l)
#用户的最大进程数
ulimit_=$(ulimit -u)
#内核设置的最大进程数
pid_max=$(sysctl kernel.pid_max | awk '{print $3}')
echo -e "n�33[32m################## 进程 相关 ############�33[0mn"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|进程数量:�33[31m$procs �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|用户的最大进程数:�33[31m$ulimit_ �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|内核设置的最大进程数:�33[31m$pid_max �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
function network() {
#获取网卡流量信息,接收|发送的数据流量,单位为字节(bytes)
net_monitor=$(cat /proc/net/dev | tail -n +3 | awk 'BEGIN{ print "网卡名称 入站数据流量(bytes) 出站数据流量(bytes)"} {print $1,$2,$10}' | column -t)
#获取暴露端口信息
ip_port=$(ss -ntulpa)
#本地IP地址列表
localip=$(ip a s | awk '/inet /{print $2}' )
echo -e "n�33[32m################## 网络 相关 ############�33[0mn"
echo -e "|本地IP地址列表:"
echo -e "�33[31m$localip �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|获取网卡流量信息:"
echo -e "�33[31m$net_monitor �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
echo -e "|获取暴露端口信息:"
echo -e "�33[31m$ip_port �33[0m"
echo -e "�33[32m------------------------------------�33[0m"
}
case $1 in
all)
bash_os
memory
cpu
disk_io
procs
network
;;
bash_os)
bash_os
;;
memory)
memory
;;
cpu)
cpu
;;
disk_io)
disk_io
;;
procs)
procs
;;
network)
network
;;
*)
echo "Usage: bash_os|memory|cup|disk_io|procs|network|all"
;;
esac
最后
以上就是儒雅小鸽子最近收集整理的关于一个轻量的Linux运维监控脚本写在前面的全部内容,更多相关一个轻量内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复