目录
- 一: 复制:
- 1:复制作用:
- 2:复制的原理:
- 3:常用架构:
- 4:实现读写分离
- 4.1: 研究sqlalchemy官方文档:
- 4.2:我们的flask_sqlalchemy是如何做的呢?
- 4.3:实现读写分离:
- 4.4: 项目中实现读写分离:
- 二:分片:
- 2.1:垂直拆分:
- 2.2:垂直分库:
- 2.3:如何分库访问?
- 2.4:水平拆分:
- 2.5:如何定向查询?
- 2.6: 水平分表以上操作仍然存在的问题:
- 三:分布式事务问题:
- 方案一:二阶段提交:
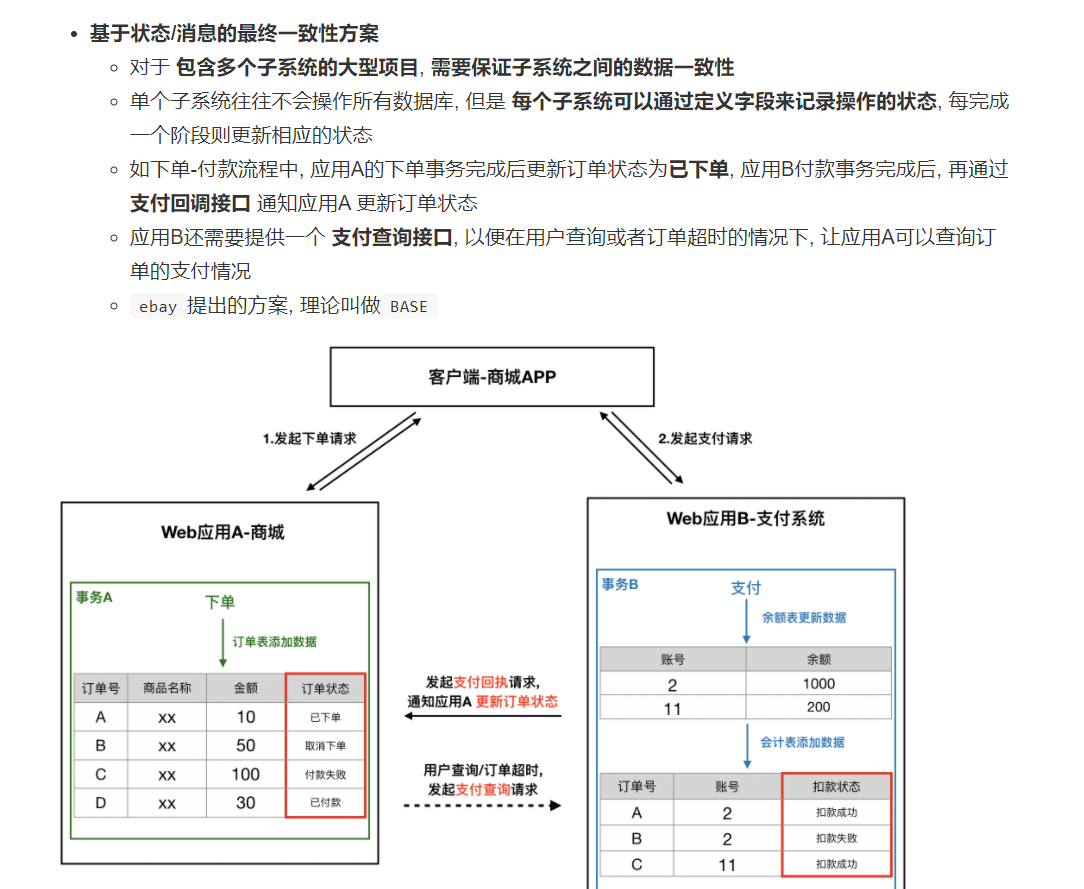
- 方案二:状态消息的一致性方案:
- 四:分布式Join/分页/排序问题:
- 方案一:
- 方案二:
一: 复制:
1:复制作用:
- 对数据进行备份,提高高可用。高可用原因是主服务器挂了,从服务器还可以使用。
- 通过读写分离,提高吞吐量,实现高性能。
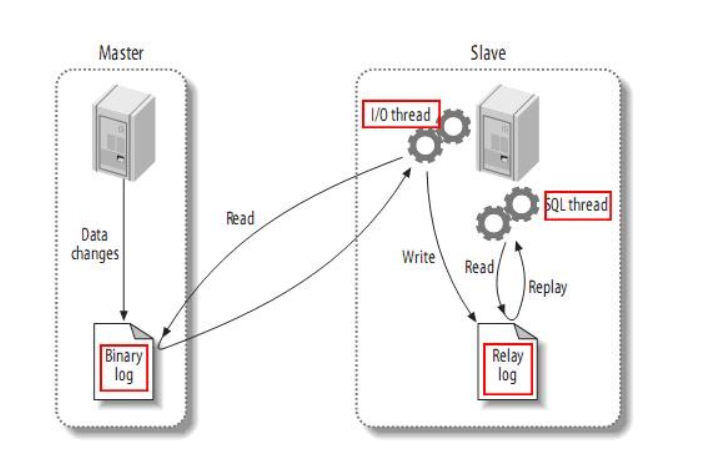
2:复制的原理:
- 1:mysql主服务器会将写操作,写入自己的二进制日志文件中。
- 2:mysql的从服务器的IO线程会连接mysql主服务器,请求读取主服务器的二进制日志指定内容。
- 3:mysql的主服务器的IO线程将二进制内容读取到,复制给mysql从服务器的IO线程。
- 4:mysql的从服务器的IO线程将收到的日志,写入自己的中继日志中。
- 5:mysql的从服务器的SQL线程执行中继日志的mysql语句。
3:常用架构:
- 1:主从架构----一主多从,读写分离,提高吞吐量。缺点:主库单点,从库高可用,主库一旦挂掉,无法写入操作。
- 2:主备架构—多主库,互相数据备份。单裤读写,性能一般。高可用,一旦主库挂掉,就启用备库。(阿里云,美团)
问题: 既然主备互为备份,为什么不采用双主方案,提供两台主进行负载均衡呢?
答:双主方案会造成数据的不一致性。
比如:有两个操作,第一个将next字段修改成20,第二个字段将next字段修改成40,假设A库将next字段修改成20,B库将next字段从20修改成30。而此时双主需要同步,B库IO线程读取A库的日志,将next字段重新修改成20,造成数据库错误。同时A库再次同步B数据库的日志,将next字段修改成30。这样的结果导致A库最终结果是正确的,B库的结果是错误的。两个数据库还发生不一致的现象。
- 3: 高可用符合架构:
- 两台主数据库互相备份,多台从服务器与主服务器形成主从同步。
- 读写分离,高可用,提高性能。
4:实现读写分离
4.1: 研究sqlalchemy官方文档:
文档地址
4.2:我们的flask_sqlalchemy是如何做的呢?
- 1:flask_sqlalchemy中使用SignallingSession继承于sqlalchemy中的Session。
- 2:我们看看SignallingSession做了什么呢?
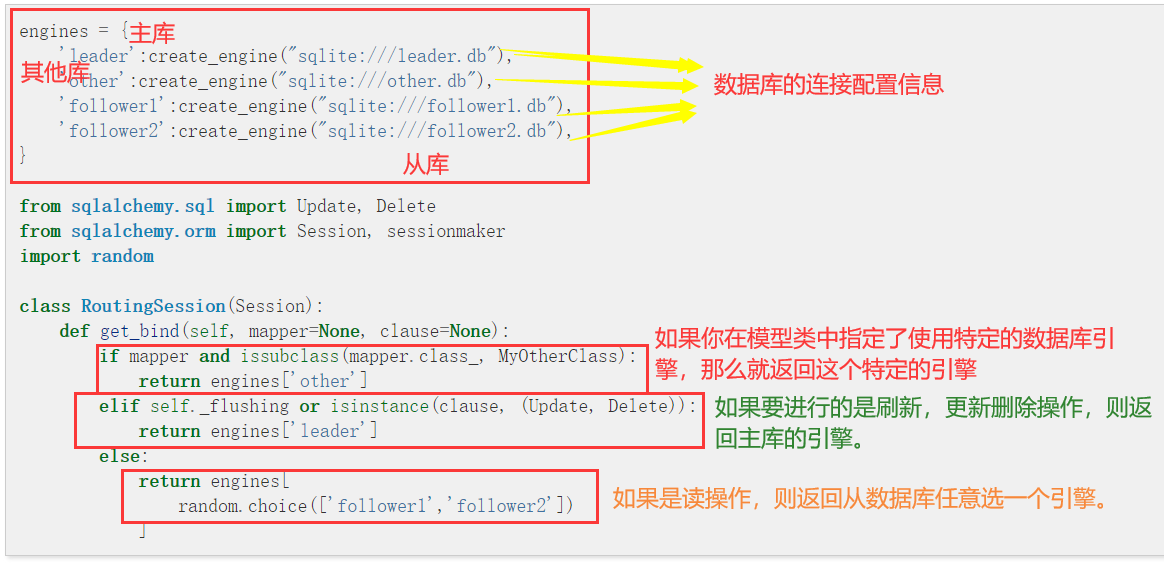
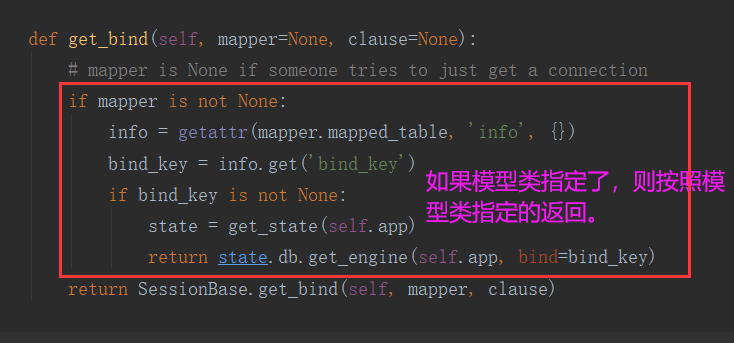
- 3:如果模型类中用bind_key指定了数据库的引擎,则按照模型类中指定的数据库引擎返回。
- 4: 在flask_sqlalchemy中如何替换掉Session呢?
- 追溯源码发现Sqlalchemy中有一个create_session方法。这个方法只当构造session使用的类,所以只需要创建一个类,继承于Sqlalchemy修改掉create_session方法就可以了。
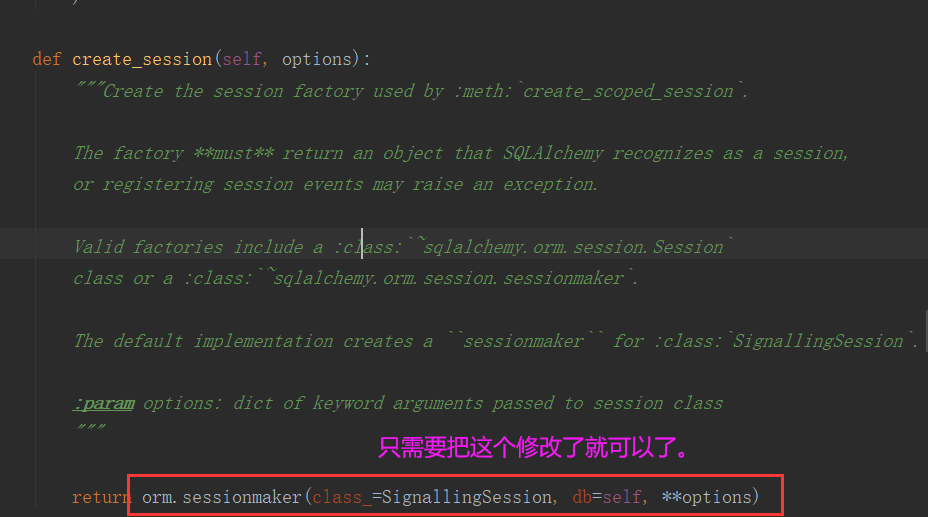
4.3:实现读写分离:
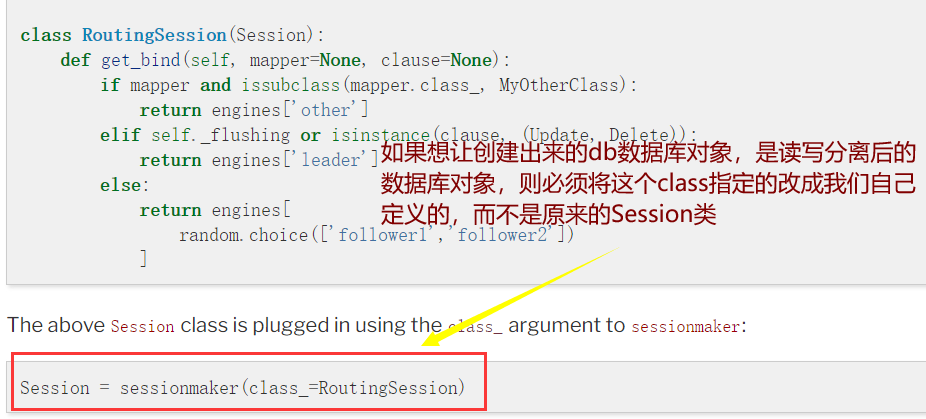
- 1: 自定义Session类,继承于SignallingSession类,重写get_bind方法,根据读写需求选择对应的数据库地址。
- 2:实现自定义SQLAlchemy类,继承于SQLAlchemy类,重写create_session方法,在内部使用自己定义的Session类。
1:自定义Session类:
核心代码:
# 1. 自定义Session类, 继承SignallingSession, 并重写get_bind方法
class RoutingSession(SignallingSession):
def __init__(self, *args, **kwargs):
super(RoutingSession, self).__init__(*args, **kwargs)
def get_bind(self, mapper=None, clause=None):
"""每次数据库操作(增删改查及事务操作)都会调用该方法, 来获取对应的数据库引擎(访问的数据库)"""
state = get_state(self.app)
if mapper is not None:
try:
# SA >= 1.3
persist_selectable = mapper.persist_selectable
except AttributeError:
# SA < 1.3
persist_selectable = mapper.mapped_table
# 如果项目中指明了特定数据库,就获取到bind_key指明的数据库,进行数据库绑定
info = getattr(persist_selectable, 'info', {})
bind_key = info.get('bind_key')
if bind_key is not None:
return state.db.get_engine(self.app, bind=bind_key)
# 使用默认的主数据库
# return SessionBase.get_bind(self, mapper, clause)
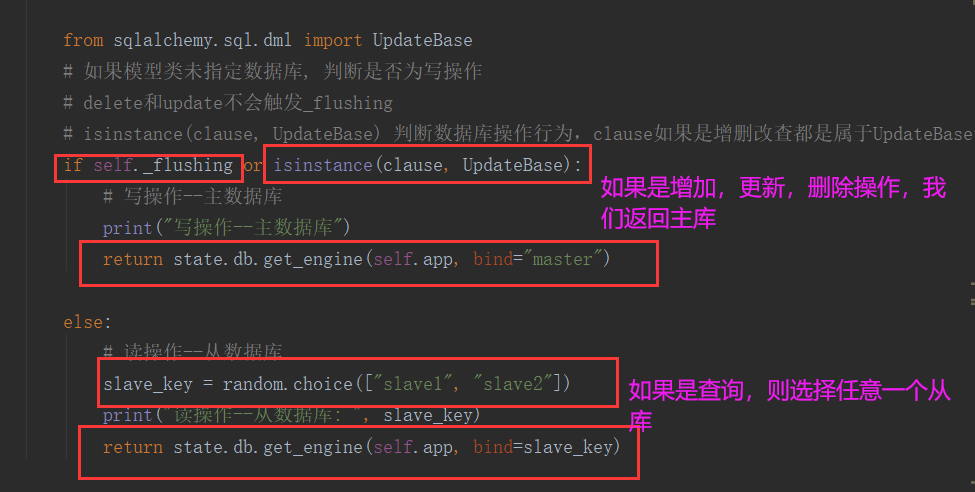
from sqlalchemy.sql.dml import UpdateBase
# 如果模型类未指定数据库, 判断是否为写操作
# delete和update不会触发_flushing
# isinstance(clause, UpdateBase) 判断数据库操作行为,clause如果是增删改查都是属于UpdateBase子类
if self._flushing or isinstance(clause, UpdateBase):
# 写操作--主数据库
print("写操作--主数据库")
return state.db.get_engine(self.app, bind="master")
else:
# 读操作--从数据库
slave_key = random.choice(["slave1", "slave2"])
print("读操作--从数据库: ", slave_key)
return state.db.get_engine(self.app, bind=slave_key)
2:自定义SQLalchemy类:
# 2. 自定义SQLALchemy类, 重写create_session方法
class RoutingSQLAlchemy(SQLAlchemy):
def create_session(self, options):
# 继承-拓展SQLAlchemy的功能,封装一个RoutingSession类实现读写分离
return orm.sessionmaker(class_=RoutingSession, db=self, **options)
3:完整的测试代码:
import random
from flask import Flask
from flask_sqlalchemy import SQLAlchemy, SignallingSession, get_state
import pymysql
from sqlalchemy import orm
pymysql.install_as_MySQLdb()
app = Flask(__name__)
# 单数据库
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:mysql@192.168.44.128:3306/test1"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
# 多数据库-主从
app.config["SQLALCHEMY_BINDS"] = {
"master": "mysql://root:mysql@192.168.44.128:3306/test1",
"slave1": "mysql://root:mysql@192.168.44.128:8306/test1",
"slave2": "mysql://root:mysql@192.168.44.128:3306/test1",
}
# 1. 自定义Session类, 继承SignallingSession, 并重写get_bind方法
class RoutingSession(SignallingSession):
def __init__(self, *args, **kwargs):
super(RoutingSession, self).__init__(*args, **kwargs)
def get_bind(self, mapper=None, clause=None):
"""每次数据库操作(增删改查及事务操作)都会调用该方法, 来获取对应的数据库引擎(访问的数据库)"""
state = get_state(self.app)
if mapper is not None:
try:
# SA >= 1.3
persist_selectable = mapper.persist_selectable
except AttributeError:
# SA < 1.3
persist_selectable = mapper.mapped_table
# 如果项目中指明了特定数据库,就获取到bind_key指明的数据库,进行数据库绑定
info = getattr(persist_selectable, 'info', {})
bind_key = info.get('bind_key')
if bind_key is not None:
return state.db.get_engine(self.app, bind=bind_key)
# 使用默认的主数据库
# return SessionBase.get_bind(self, mapper, clause)
from sqlalchemy.sql.dml import UpdateBase
# 如果模型类未指定数据库, 判断是否为写操作
# delete和update不会触发_flushing
# isinstance(clause, UpdateBase) 判断数据库操作行为,clause如果是增删改查都是属于UpdateBase子类
if self._flushing or isinstance(clause, UpdateBase):
# 写操作--主数据库
print("写操作--主数据库")
return state.db.get_engine(self.app, bind="master")
else:
# 读操作--从数据库
slave_key = random.choice(["slave1", "slave2"])
print("读操作--从数据库: ", slave_key)
return state.db.get_engine(self.app, bind=slave_key)
# 2. 自定义SQLALchemy类, 重写create_session方法
class RoutingSQLAlchemy(SQLAlchemy):
def create_session(self, options):
# 继承-拓展SQLAlchemy的功能,封装一个RoutingSession类实现读写分离
return orm.sessionmaker(class_=RoutingSession, db=self, **options)
# 自定义RoutingSQLAlchemy类创建数据库对象
db = RoutingSQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
age = db.Column(db.Integer, default=0, index=True)
@app.route('/')
def index():
"""增加数据"""
# read()
# write()
# read()
update()
return "index"
def read():
print('---读-----------')
users = User.query.all()
print(users)
for user in users:
print(user.id, user.name, user.age)
def write():
print('---写-----------')
user1 = User(name='james', age=20)
db.session.add(user1)
db.session.commit()
def update():
print("---更新写---")
User.query.filter(User.name == 'xiaoming').update({"name": "Uzi"})
db.session.commit()
if __name__ == '__main__':
# 重置所有继承自db.Model的表
# 如果模型类没有设置__bind_ky__属性(指定对应的数据库), 则DDL操作 根据SQLALCHEMY_DATABASE_URI 指定的数据库进行处理
# db.drop_all()
# db.create_all()
app.run(host='0.0.0.0', debug=True, port=8000)
4.4: 项目中实现读写分离:
1:在modelsrouting_dbrouting_sqlalchemy.py中编写读写分离的工具类:
import random
from flask_sqlalchemy import SignallingSession, get_state, SQLAlchemy
# app.config["SQLALCHEMY_BINDS"] = {
# "master": "mysql://root:mysql@192.168.243.151:3306/test30",
# "slave1": "mysql://root:mysql@192.168.243.151:8306/test30",
# "slave2": "mysql://root:mysql@192.168.243.151:3306/test30",
# }
# 1. 自定义Session类, 继承SignallingSession, 并重写get_bind方法
from sqlalchemy import orm
class RoutingSession(SignallingSession):
def __init__(self, *args, **kwargs):
super(RoutingSession, self).__init__(*args, **kwargs)
# 随机选择从数据库的key
self.slave_key = random.choice(["slave1", "slave2"])
def get_bind(self, mapper=None, clause=None):
"""每次数据库操作(增删改查及事务操作)都会调用该方法, 来获取对应的数据库引擎(访问的数据库)"""
state = get_state(self.app)
# 按照模型类中指定的数据库,返回数据库引擎
if mapper is not None:
try:
# SA >= 1.3
persist_selectable = mapper.persist_selectable
except AttributeError:
# SA < 1.3
persist_selectable = mapper.mapped_table
# 如果项目中指明了特定数据库,就获取到bind_key指明的数据库,进行数据库绑定
info = getattr(persist_selectable, 'info', {})
bind_key = info.get('bind_key')
if bind_key is not None:
return state.db.get_engine(self.app, bind=bind_key)
# 使用默认的主数据库
# return SessionBase.get_bind(self, mapper, clause)
from sqlalchemy.sql.dml import UpdateBase
# 如果模型类未指定数据库, 判断是否为写操作
# delete和update不会触发_flushing
# isinstance(clause, UpdateBase) 判断数据库操作行为,clause如果是增删改查都是属于UpdateBase子类
if self._flushing or isinstance(clause, UpdateBase):
# 写操作--主数据库
print("写操作--主数据库")
return state.db.get_engine(self.app, bind="master")
else:
# 读操作--从数据库
print("读操作--从数据库: ", self.slave_key)
return state.db.get_engine(self.app, bind=self.slave_key)
# 2. 自定义SQLALchemy类, 重写create_session方法
class RoutingSQLAlchemy(SQLAlchemy):
def create_session(self, options):
# 继承-拓展SQLAlchemy的功能,封装一个RoutingSession类实现读写分离
return orm.sessionmaker(class_=RoutingSession, db=self, **options)
2: 在项目初始化文件中编写读写分离的配置信息:
class BaseConfig(object):
# 加密密钥
SECRET_KEY = "python"
SQLALCHEMY_BINDS = {
"master": 'mysql+pymysql://root:mysql@192.168.44.128:3306/hm_topnews',
"slave1": 'mysql+pymysql://root:mysql@192.168.44.128:8306/hm_topnews',
"slave2": 'mysql+pymysql://root:mysql@192.168.44.128:3306/hm_topnews',
}
# mysql数据库的配置信息 + 解决内部报错
SQLALCHEMY_DATABASE_URI = 'mysql://root:mysql@192.168.44.128:3306/hm_topnews' # 连接地址
SQLALCHEMY_TRACK_MODIFICATIONS = False # 是否追踪数据变化
SQLALCHEMY_ECHO = False # 是否打印底层执行的SQL
# redis数据库的配置信息
REDIS_HOST = "192.168.44.128"
REDIS_PORT = 6381
# JWT配置信息
# JWT密钥
JWT_SECRET = "adadwAdmldadnawasdadwddnodam"
# 2小时的tocken过期时间
LOGIN_TOCKEN_EXPIRE = 2
# 14天的刷新tockend的过期时间
REFRESH_TOCKEN_EXPIRE = 14
# 中文编码问题:
LOGIN_AS_ASCII = False
RESTFUL_JSON = {"ensure_ascii": False}
# 七牛云的配置信息
QINIU_ACCESS_KEY = 'LSo9n249hhQP9VQPHtJkNpC-2l6zAAJUgYm0q69J'
QINIU_SECRET_KEY = 'lnm0ebW2Qp3CLZberagsKPfBY2p_aDo_IV-_LP-J'
QINIU_BUCKET_NAME = 'sztopnews'
QINIU_DOMAIN = 'http://qji837cfs.hn-bkt.clouddn.com/'
3:初始化文件中修改创建数据库对象的方式:
# 创建数据库对象,定义成全局变量
from models.routing_db.routing_sqlalchemy import RoutingSQLAlchemy
db = RoutingSQLAlchemy()
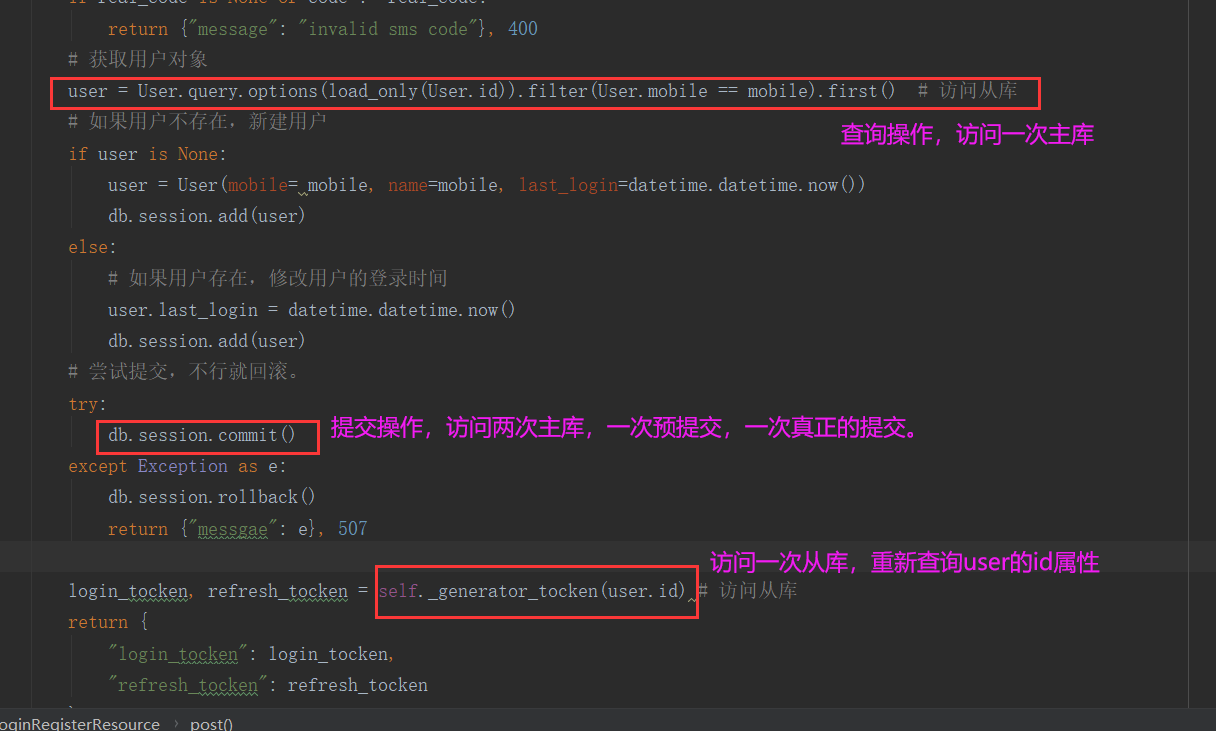
4: 测试读写分离:
分析登录的过程的访问主库和从库的顺序和次数。

二:分片:
- 1:分布式服务器
- 2:拆表
- 3: 拆库
- 4: 方式—垂直拆分和水平拆分。
2.1:垂直拆分:
- 垂直拆分的依据:相关性,使用频率,字段太长等。
- 1:相关性:例如用户表很大,而用户名和密码是相关的,其他用户的信息又是相关的,所以我们可以单独将用户名和密码拆分到认证表,把其他信息拆分到用户信息表。
- 2:使用频率:例如:用户名,密码, 登录日期,是经常访问的,而用户的其他字段是不经常访问的,所以可以单独拆分一张经常访问和另外一张不经常访问的表。
- 3:字段太长,某些字段数据量太大,比如文章信息,我们查询文章的时候可以单独把文章信息拆分到一张表中,这样不用每次查询文章对象的时候都携带者文章信息。
2.2:垂直分库:
- 垂直分库的依据:相关性, 比如将文章相关信息放在A库,将用户信息放在B库。
- 垂直分库带来的问题:
- 数据库的事务,不允许跨库操作。
2.3:如何分库访问?
1: 创建数据库db1,db2。
2: 测试代码:
步骤:
1:配置多个数据库
app.config[“SQLALCHEMY_BINDS”] = {
“db1”: “mysql://root:mysql@192.168.44.128:3306/db1”,
“db2”: “mysql://root:mysql@192.168.44.128:3306/db2”,
}
2:视图中指定数据库:
__bind_key__ = "db2"
import random
from flask import Flask
from flask_sqlalchemy import SQLAlchemy, SignallingSession, get_state
import pymysql
from sqlalchemy import orm
pymysql.install_as_MySQLdb()
app = Flask(__name__)
# 单数据库
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:mysql@192.168.44.128:3306/db1"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
app.config['SQLALCHEMY_ECHO'] = True
app.config["SQLALCHEMY_BINDS"] = {
"db1": "mysql://root:mysql@192.168.44.128:3306/db1",
"db2": "mysql://root:mysql@192.168.44.128:3306/db2",
}
# 1. 自定义Session类, 继承SignallingSession, 并重写get_bind方法
class RoutingSession(SignallingSession):
def __init__(self, *args, **kwargs):
super(RoutingSession, self).__init__(*args, **kwargs)
def get_bind(self, mapper=None, clause=None):
"""每次数据库操作(增删改查及事务操作)都会调用该方法, 来获取对应的数据库引擎(访问的数据库)"""
state = get_state(self.app)
if mapper is not None:
try:
# SA >= 1.3
persist_selectable = mapper.persist_selectable
except AttributeError:
# SA < 1.3
persist_selectable = mapper.mapped_table
# 如果项目中指明了特定数据库,就获取到bind_key指明的数据库,进行数据库绑定
info = getattr(persist_selectable, 'info', {})
bind_key = info.get('bind_key')
if bind_key is not None:
return state.db.get_engine(self.app, bind=bind_key)
# 使用默认的主数据库
# return SessionBase.get_bind(self, mapper, clause)
from sqlalchemy.sql.dml import UpdateBase
# 如果模型类未指定数据库, 判断是否为写操作
# delete和update不会触发_flushing
# isinstance(clause, UpdateBase) 判断数据库操作行为,clause如果是增删改查都是属于UpdateBase子类
if self._flushing or isinstance(clause, UpdateBase):
# 写操作--主数据库
print("写操作--主数据库")
return state.db.get_engine(self.app, bind="master")
else:
# 读操作--从数据库
slave_key = random.choice(["slave1", "slave2"])
print("读操作--从数据库: ", slave_key)
return state.db.get_engine(self.app, bind=slave_key)
# 2. 自定义SQLALchemy类, 重写create_session方法
class RoutingSQLAlchemy(SQLAlchemy):
def create_session(self, options):
# 继承-拓展SQLAlchemy的功能,封装一个RoutingSession类实现读写分离
return orm.sessionmaker(class_=RoutingSession, db=self, **options)
# 自定义RoutingSQLAlchemy类创建数据库对象
db = RoutingSQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
__bind_key__ = "db1"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
age = db.Column(db.Integer, default=0, index=True)
class Address(db.Model):
__tablename__ = 't_address'
__bind_key__ = "db2"
id = db.Column(db.Integer, primary_key=True)
detial = db.Column(db.String(20), unique=True)
user_id = db.Column(db.Integer)
@app.route('/')
def hello_world():
return "hello world!"
if __name__ == '__main__':
# 重置所有继承自db.Model的表
# 如果模型类没有设置__bind_ky__属性(指定对应的数据库), 则DDL操作 根据SQLALCHEMY_DATABASE_URI 指定的数据库进行处理
db.drop_all()
db.create_all()
app.run(host='0.0.0.0', debug=True, port=8000)
3: 修改代码测试:
@app.route('/')
def add():
# 1: 创建用户对象
user1 = User(name="laowang", age=28)
db.session.add(user1)
db.session.flush()
# 2: 创建地址对象
addr1 = Address(detial="中联", user_id=user1.id)
addr2 = Address(detial="东北", user_id=user1.id)
db.session.add_all([addr1, addr2])
# 3: 提交的到数据库
db.session.commit()
return "hello world!"
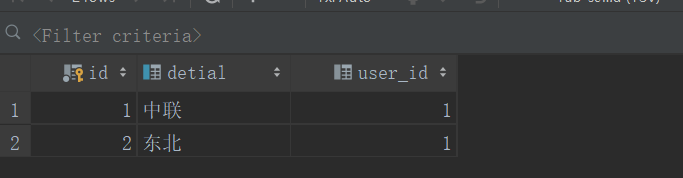
4: 如何分库查询呢?
由于分库,导致不能使用join连表查询只能分开查询。
@app.route('/query')
def query_data():
user1 = User.query.filter(User.name == "laowang").first()
addr_list = Address.query.filter(Address.user_id == user1.id).all()
for addr in addr_list:
print(addr.detial)
return "hahahhahaha"
2.4:水平拆分:
- 1: 水平分表,水平分库:
- 2:拆分的规则:时间,业务,ID范围, HASH取模离散化,地区划分(云服务器)。
- 3: 存在的问题:
- 如果查询条件比较模糊,那么需要遍历每一个数据库进行查询。
- 怎样定向查询呢?假设我只想查询db1数据库的信息,怎么操作?
2.5:如何定向查询?
1: db3和db4中分别录入数据:
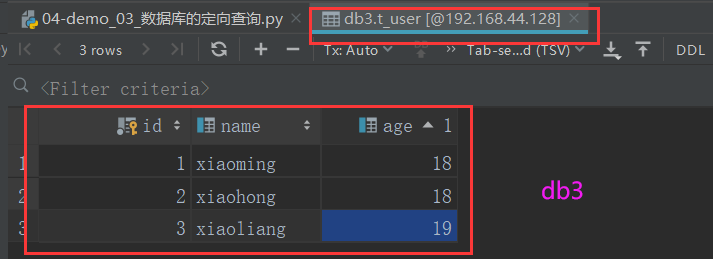
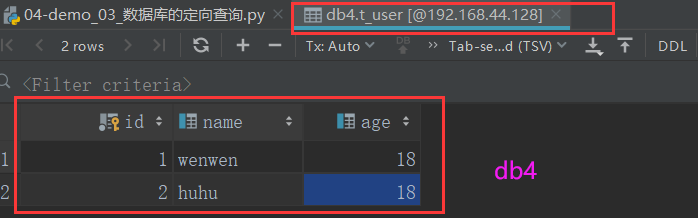
2: 编写测试代码:
import random
from flask import Flask
from flask_sqlalchemy import SQLAlchemy, SignallingSession, get_state
import pymysql
from sqlalchemy import orm
pymysql.install_as_MySQLdb()
app = Flask(__name__)
# 单数据库
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:mysql@192.168.44.128:3306/db4"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
app.config['SQLALCHEMY_ECHO'] = True
app.config["SQLALCHEMY_BINDS"] = {
"db3": "mysql://root:mysql@192.168.44.128:3306/db3",
"db4": "mysql://root:mysql@192.168.44.128:3306/db4",
}
# 1. 自定义Session类, 继承SignallingSession, 并重写get_bind方法
class RoutingSession(SignallingSession):
def __init__(self, *args, **kwargs):
super(RoutingSession, self).__init__(*args, **kwargs)
def get_bind(self, mapper=None, clause=None):
"""每次数据库操作(增删改查及事务操作)都会调用该方法, 来获取对应的数据库引擎(访问的数据库)"""
state = get_state(self.app)
if mapper is not None:
try:
# SA >= 1.3
persist_selectable = mapper.persist_selectable
except AttributeError:
# SA < 1.3
persist_selectable = mapper.mapped_table
# 如果项目中指明了特定数据库,就获取到bind_key指明的数据库,进行数据库绑定
info = getattr(persist_selectable, 'info', {})
bind_key = info.get('bind_key')
if bind_key is not None:
return state.db.get_engine(self.app, bind=bind_key)
# 使用默认的主数据库
# return SessionBase.get_bind(self, mapper, clause)
from sqlalchemy.sql.dml import UpdateBase
# 如果模型类未指定数据库, 判断是否为写操作
# delete和update不会触发_flushing
# isinstance(clause, UpdateBase) 判断数据库操作行为,clause如果是增删改查都是属于UpdateBase子类
if self._flushing or isinstance(clause, UpdateBase):
# 写操作--主数据库
print("写操作--主数据库")
return state.db.get_engine(self.app, bind="master")
else:
# 读操作--从数据库
slave_key = random.choice(["slave1", "slave2"])
print("读操作--从数据库: ", slave_key)
return state.db.get_engine(self.app, bind=slave_key)
# 2. 自定义SQLALchemy类, 重写create_session方法
class RoutingSQLAlchemy(SQLAlchemy):
def create_session(self, options):
# 继承-拓展SQLAlchemy的功能,封装一个RoutingSession类实现读写分离
return orm.sessionmaker(class_=RoutingSession, db=self, **options)
# 自定义RoutingSQLAlchemy类创建数据库对象
db = RoutingSQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
age = db.Column(db.Integer, default=0, index=True)
if __name__ == '__main__':
# 重置所有继承自db.Model的表
# 如果模型类没有设置__bind_ky__属性(指定对应的数据库), 则DDL操作 根据SQLALCHEMY_DATABASE_URI 指定的数据库进行处理
# db.drop_all()
# db.create_all()
app.run(host='0.0.0.0', debug=True, port=8000)
3:了解需求:
查询年龄是18岁的用户数据,只查询db3和db4数据库中的?
4: 在RoutingSession中创建一个方法接收视图函数传递给他的数据库名,并将数据库名传递给全局变量保存。
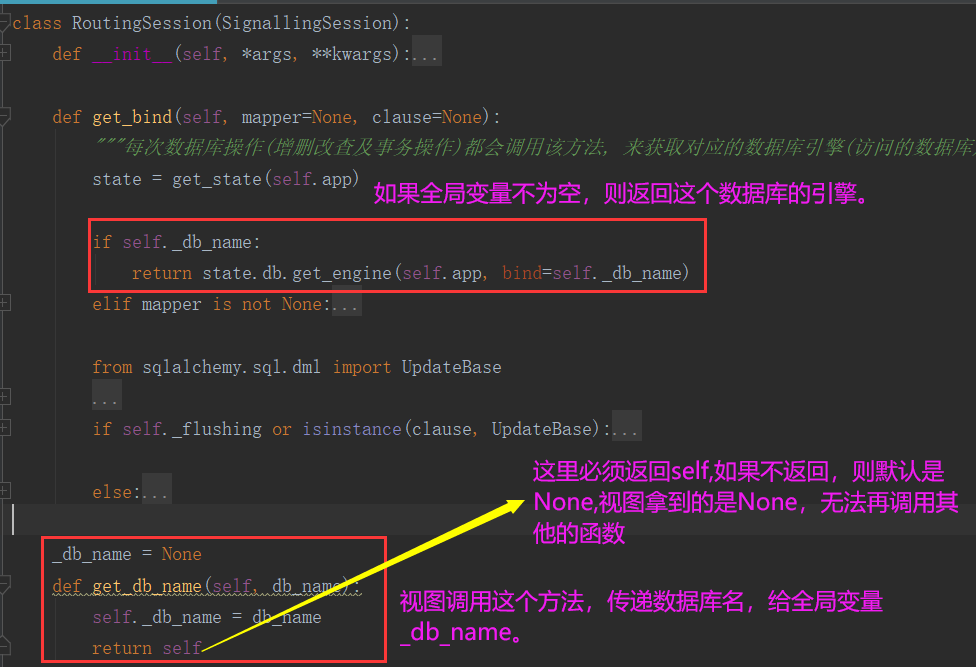
@app.route('/')
def find_all():
for db_name in ['db3', 'db4']:
user_list = db.session().get_db_name(db_name).query(User.name).filter(User.age == 18).all()
for user in user_list:
print(user.name)
return "hahahaha"
测试结果:两张表都查询到了。

5: 存在的问题:对于只查询User,我们发现结果是只能查询到db3中的。
@app.route('/')
def find_all():
for db_name in ['db3', 'db4']:
user_list = db.session().get_db_name(db_name).query(User).filter(User.age == 18).all()
for user in user_list:
print(user.name)
return "hahahaha"
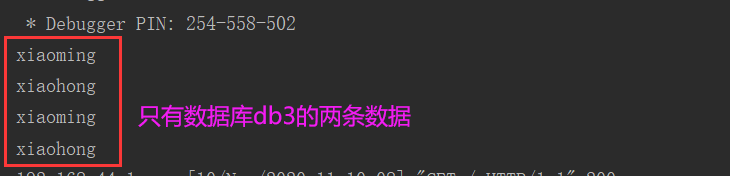
发生的原因在于,第一次查询db3数据库两个用户的id,分别是1 2,而第二次查询db4的时候,发现缓存中已经存在id为1和2的数据了,就不再查询了。
验证:将数据库db4修改id后再次查询:
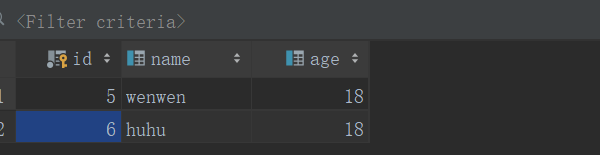
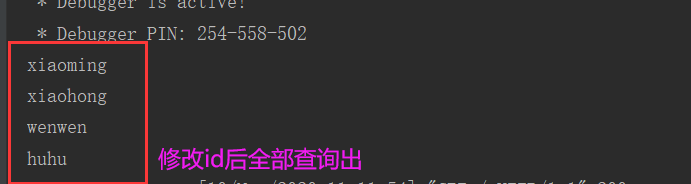
注意:水平分表之后,尽量使用i每个数据库d不一致,否则会出现冲突。
2.6: 水平分表以上操作仍然存在的问题:
问题描述:
假设以上操作,我们使用完db3,和db4,那么我的_db_name属性一直保存db4这个数据库,那么我的其他请求想访问其他数据库就不行了。
方案:其他的请求都加上get_db_name(None)
db.session().get_db_name(None).query(User).filter(User.age == 18).all()
三:分布式事务问题:
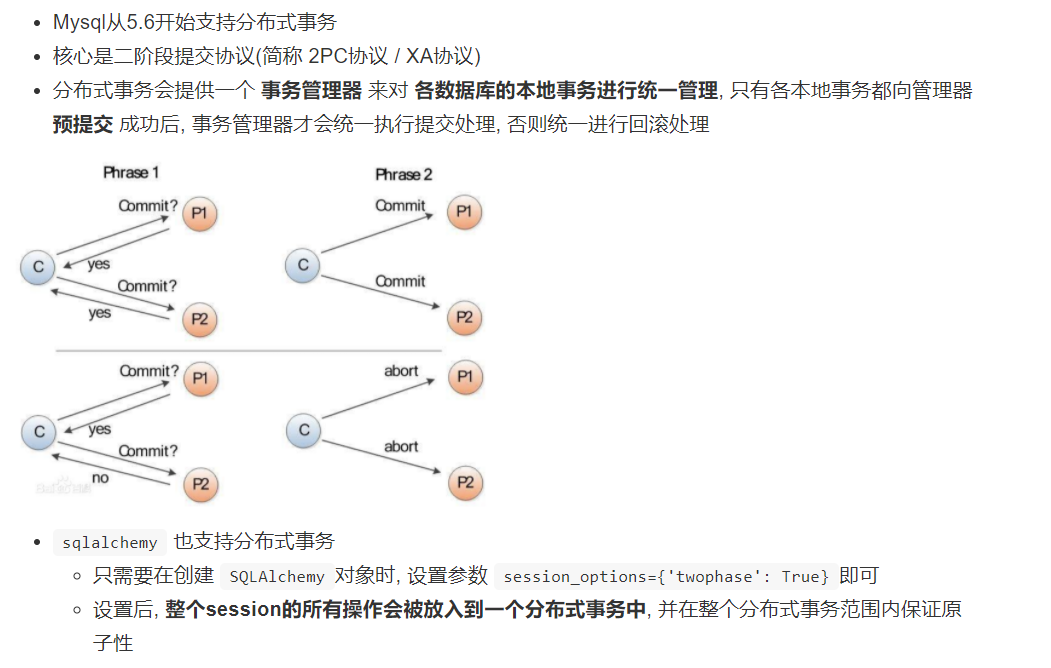
方案一:二阶段提交:
核心思想:事务管理器先对每个数据库的事务进行提交,如果两个都提交成功,则再真正提交。
方案二:状态消息的一致性方案:
核心思想:双方增加一个状态字段,当自己表状态修改后,发送消息调用对方的接口,修改对方数据库的字段状态。
四:分布式Join/分页/排序问题:
方案一:
两次查询再合并。
方案二:
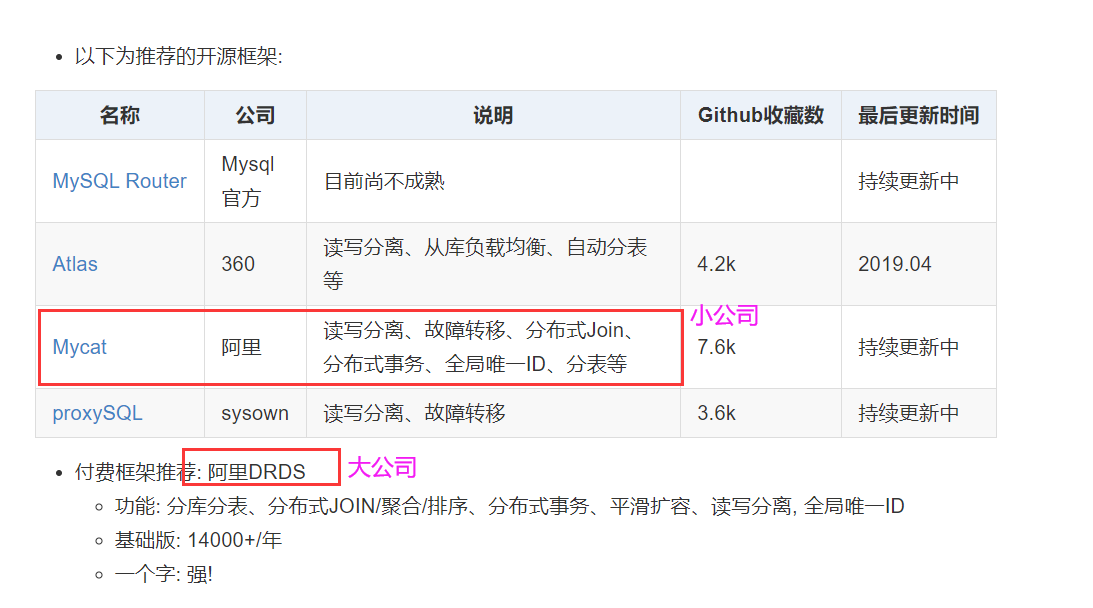
啥也不说了,买就完了。
最后
以上就是温婉芹菜最近收集整理的关于MYSQL分布式设计的全部内容,更多相关MYSQL分布式设计内容请搜索靠谱客的其他文章。








发表评论 取消回复