19.7 案例7:Fuse内核死锁导致的系统死机问题
1. 问题现象
- 问题发生的Android系统版本是7.1(Nougat);
- 界面定住,没有任何刷新,所有输入事件无效,包括电源键;
- watchdog没有重启system_server;
- 问题现场可以连接adb;
- 执行ps命令卡住;
2. 初步分析
对于死机问题,我们需要做一些分析前的准备工作:
(1)拿到问题现场,及时充电以保证问题现场不被破坏;
(2)如果没有现场可以忽略这一步,通过kill -3 后面跟上system_server pid命令产生一份最新的traces文件;
(3)如果最新的traces文件无法产生,则通过debuggerd -b $system_server pid打印出一份所有线程的Native调用栈到文件中;
(4)通过adb将/data/anr下的文件都pull出来;
(5)通过adb将/data/tombstones下的文件都pull出来;
当前问题比较特殊,虽然可以连接adb但是执行ps命令获取system_server pid时会卡住,所以先通过logcat获取到system_server的pid,然后再尝试用kill-3命令获取system_server最新的traces,拿到traces后首先搜索定位到system_server进程的watchdog线程处,看watchdog线程当前处于什么状态,为什么没有重启手机,具体调用栈如下:
"watchdog" prio=5 tid=89 TimedWaiting
| group="main" sCount=1 dsCount=0 obj=0x12d13df0 self=0x7f89f7ba00
| sysTid=2980 nice=0 cgrp=default sched=0/0 handle=0x7f7cba4450
| state=D schedstat=( 2627798736 555836564 6770 ) utm=195 stm=67 core=1 HZ=100
| stack=0x7f7caa2000-0x7f7caa4000 stackSize=1037KB
| held mutexes=
kernel: __switch_to+0x88/0x94
kernel: proc_pid_cmdline_read+0xac/0x424
kernel: __vfs_read+0x28/0xc8
kernel: vfs_read+0x84/0xfc
kernel: SyS_read+0x48/0x84
kernel: el0_svc_naked+0x24/0x28
native: #00 pc 0000000000078d70 /system/lib64/libc.so (read+8)
native: #01 pc 0000000000103a6c /system/lib64/libandroid_runtime.so (_Z37android_os_Process_getPidsForCommandsP7_JNIEnvP8_jobjectP13_jobjectArray+576)
native: #02 pc 00000000011888c8 /data/dalvik-cache/arm64/system@framework@boot.oat (Java_android_os_Process_getPidsForCommands___3Ljava_lang_String_2+148)
at android.os.Process.getPidsForCommands(Native method)
at com.android.server.am.ActivityManagerService.dumpStackTraces(ActivityManagerService.java:5582)
at com.android.server.am.ActivityManagerService.dumpStackTraces(ActivityManagerService.java:5544)
at com.android.server.Watchdog.run(Watchdog.java:434)
从调用栈中可以看到watchdog线程当前在做dumpStackTraces的操作,通过调用栈定位到对应的具体源代码如下:
public void run() {
...
final File stack = ActivityManagerService.dumpStackTraces(
!waitedHalf, pids, null, null, NATIVE_STACKS_OF_INTEREST);
...
Slog.w(TAG, "*** WATCHDOG KILLING SYSTEM PROCESS: " + subject);
...
Slog.w(TAG, "*** GOODBYE!");
Process.killProcess(Process.myPid());
System.exit(10);
...
}
从对应的源代码可以看到watchdog已经发生,在watchdog重启system_server之前触发了dumpStackTraces操作,但是在dumpStackTraces的过程中被block了,通过addr2line和偏移地址定位到最终block的代码如下:
/* kernel/msm-4.4/fs/proc/base.c */
static ssize_t proc_pid_cmdline_read(struct file *file, char __user *buf,
size_t _count, loff_t *pos)
{
...
struct mm_struct *mm;
...
down_read(&mm->mmap_sem);
...
}
从调用栈和对应的源代码可以看到watchdog线程在kernel空间执行proc_pid_cmdline_read方法,在执行的过程中调用down_read方法时block,并且watchdog线程的状态也变成了D状态,所以接下来需要继续分析为什么watchdog线程在kernel空间执行down_read时会被block并且进入D状态。
执行down_read(&mm->mmap_sem)时被block,这是在做什么操作呢?先看看mm->mmap_sem,关键代码如下:
/* kernel/msm-4.4/include/linux/mm_types.h */
struct mm_struct {
...
struct rw_semaphore mmap_sem;
...
}
原来mmap_sem是个rw_semaphore读写信号量,watchdog线程在kernel空间的proc_pid_cmdline_read函数中想要以read的方式持有mm->mmap_sem这个rw_semaphore的时候发生block,这里block说明前面已经有线程在kernel空间以write的方式持有了这个rw_semaphore或者有线程以read的方式持有了这个rw_semaphore并且有写者在等待,但是如何找到这个在kernel空间已经以write或者read持有rw_semaphore的线程呢?
rw_semaphore即读写信号量,rw_semaphore将访问者分为读者和写者,同时可以有多个读者持有读写信号量,即读者之间可以共享读写信号量,写者同时有且只能有一个,并且与读者互斥,当有读者持有读写信号量的时候写者会被block,直到所有读者释放,并且在写者等待期间后面的读者再请求持有读写信号量时也会同样发生block。当有写者持有读写信号量时读者和写者都会被block,直到写者释放。
问题进入到kernel空间之后常规的用户空间的调试手段就不太适用了,必须要启用新的工具和方式,面对当前的问题我们可以获取RAMDUMP然后使用Crash工具来继续分析这个问题,RAMDUMP的获取方式可以参考前面调试秘籍中的章节,Crash工具的获取和使用环境搭建也同样参考前面调试秘籍中的章节。
获取到RAMDUMP并搭建好Crash工具的环境后我们就可以开始继续分析了,首先通过Crash工具加载RAMDUMP进入Crash的调试环境,加载命令如下:
$ ./crash_ARM64 vmlinux DDRCS0_0.BIN@0x0000000080000000,DDRCS1_0.BIN@0x0000000100000000,DDRCS1_1.BIN@0x0000000180000000 --kaslr 0x199e600000
进入Crash调试环境之后我们先ps一下watchdog线程,具体命令和输出如下:
crash_ARM64> ps -u |grep watchdog
2980 1472 0 ffffffd63ad2e400 UN 4.2 2678340 350496 watchdog
-u是排除kernel线程,UN是Uninterruptiable Sleep即D状态,然后再次查看一下watchdog线程的调用栈,具体命令和输出如下:
crash_ARM64> bt 2980
PID: 2980 TASK: ffffffd63ad2e400 CPU: 0 COMMAND: "watchdog"
#0 [ffffffd6d9e4bc00] __switch_to at ffffff99a6685560
#1 [ffffffd6d9e4bc30] __schedule at ffffff99a74df9f0
#2 [ffffffd6d9e4bc90] schedule at ffffff99a74dfd54
#3 [ffffffd6d9e4bcb0] rwsem_down_read_failed at ffffff99a74e2094
#4 [ffffffd6d9e4bd00] down_read at ffffff99a74e19e4
#5 [ffffffd6d9e4bd10] proc_pid_cmdline_read at ffffff99a680aaa0
#6 [ffffffd6d9e4bdb0] __vfs_read at ffffff99a67b4860
#7 [ffffffd6d9e4be30] vfs_read at ffffff99a67b5038
#8 [ffffffd6d9e4be70] sys_read at ffffff99a67b5888
kernel中的调用栈和用户空间的调用栈对应起来了,并且比用户空间获取到的调用栈更详细,接下来我们就开始通过反汇编来推导这个rw_semaphore具体的值,首先反汇编出来当前watchdog线程在proc_pid_cmdline_read方法中调用down_read方法的汇编代码,即proc_pid_cmdline_read at ffffff99a680aaa0,具体命令和输出如下:
crash_ARM64> dis proc_pid_cmdline_read
...
0xffffff99a680aa98 <proc_pid_cmdline_read+160>: add x28, x21, #0x68
0xffffff99a680aa9c <proc_pid_cmdline_read+164>: mov x0, x28
0xffffff99a680aaa0 <proc_pid_cmdline_read+168>: bl 0xffffff99a74e19c0
...
然后再看一下down_read方法的原型,具体代码如下:
/* kernel/msm-4.4/kernel/locking/rwsem.c */
void __sched down_read(struct rw_semaphore *sem)
接下来根据对应的源代码和函数原型尝试理解上面的汇编代码,首先将x21寄存器中的值加上0x68然后给x28寄存器,随后将x28寄存器中的值给x0,最后调用down_read方法,由于down_read方法的第一个参数sem是rw_semaphore的指针,所以x0和x28中存放的就是参数sem,另外通过推导可以知道x21中存放的就是指针mm,因为mm_struct的mmap_sem成员的offset就是104(0x68),具体推导过程如下:
crash_ARM64> p 0x68
$1 = 104
crash_ARM64> whatis -o mm_struct
struct mm_struct {
[0] struct vm_area_struct *mmap;
[8] struct rb_root mm_rb;
[16] u32 vmacache_seqnum;
[24] unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
[32] unsigned long mmap_base;
[40] unsigned long mmap_legacy_base;
[48] unsigned long task_size;
[56] unsigned long highest_vm_end;
[64] pgd_t *pgd;
[72] atomic_t mm_users;
[76] atomic_t mm_count;
[80] atomic_long_t nr_ptes;
[88] atomic_long_t nr_pmds;
[96] int map_count;
[100] spinlock_t page_table_lock;
[104] struct rw_semaphore mmap_sem;
[144] struct list_head mmlist;
[160] unsigned long hiwater_rss;
...
}
SIZE: 784
因此接下来我们只需要知道x21或者x28就可以知道mm和mmap_sem的值,由于函数调用时,被调用函数会在自己的栈帧中保存即将被修改的寄存器,所以这些寄存器很可能在down_read函数或者down_read函数中调用的下一级函数的的调用栈中找到,即只要down_read,rwsem_down_read_failed,schedule,__schedule,__switch_to等函数中用到x21或x28寄存器,它们势必会在栈帧中保存这些寄存器,根据这个理论接下来我们继续分析。
首先查看down_read方法的反汇编实现,具体代码如下:
crash_ARM64> dis down_read
0xffffff99a74e19c0 <down_read>: stp x29, x30, [sp,#-16]!
0xffffff99a74e19c4 <down_read+4>: mov x29, sp
0xffffff99a74e19c8 <down_read+8>: prfm pstl1strm, [x0]
0xffffff99a74e19cc <down_read+12>: ldaxr x1, [x0]
0xffffff99a74e19d0 <down_read+16>: add x1, x1, #0x1
0xffffff99a74e19d4 <down_read+20>: stxr w2, x1, [x0]
0xffffff99a74e19d8 <down_read+24>: cbnz w2, 0xffffff99a74e19cc
0xffffff99a74e19dc <down_read+28>: cmp x1, xzr
0xffffff99a74e19e0 <down_read+32>: b.gt 0xffffff99a74e19e8
0xffffff99a74e19e4 <down_read+36>: bl 0xffffff99a74e1fbc
0xffffff99a74e19e8 <down_read+40>: ldp x29, x30, [sp],#16
0xffffff99a74e19ec <down_read+44>: ret
比较遗憾down_read方法没有用到x21和x28,所以没有保存这两个寄存器到栈帧上,接着继续查rwsem_down_read_failed方法的反汇编实现,具体代码如下:
crash_ARM64> dis rwsem_down_read_failed
0xffffff99a74e1fbc <rwsem_down_read_failed>: stp x29, x30, [sp,#-80]!
0xffffff99a74e1fc0 <rwsem_down_read_failed+4>: mov x29, sp
0xffffff99a74e1fc4 <rwsem_down_read_failed+8>: stp x19, x20, [sp,#16]
0xffffff99a74e1fc8 <rwsem_down_read_failed+12>: stp x21, x22, [sp,#32]
...
很幸运在rwsem_down_read_failed中使用了x21并且将x21存储到了栈帧偏移32字节处,从调用栈中我们可以知道rwsem_down_read_failed的栈帧是ffffffd6d9e4bcb0~ffffffd6d9e4bd00,具体如下:
#3 [ffffffd6d9e4bcb0] rwsem_down_read_failed at ffffff99a74e2094
#4 [ffffffd6d9e4bd00] down_read at ffffff99a74e19e4
查看一下它栈帧里的内容,具体命令和输出如下:
crash_ARM64> rd ffffffd6d9e4bcb0 -e ffffffd6d9e4bd00
ffffffd6d9e4bcb0: ffffffd6d9e4bd00 ffffff99a74e19e8 ..........N.....
ffffffd6d9e4bcc0: 0000000000000fff ffffffd728b8b200 ...........(....
ffffffd6d9e4bcd0: ffffffd76e349a00 0000007f7cba2ae8 ..4n.....*.|....
ffffffd6d9e4bce0: ffffffd683d93d70 ffffffd6a3937d70 p=......p}......
ffffffd6d9e4bcf0: ffffffd63ad2e400 0000000000000001 ...:............
我们知道x21存储到了栈帧偏移32字节处,对应的就是栈帧中ffffffd6d9e4bcd0处的数据,即ffffffd76e349a00,这个数据就是mm指针,根据这个mm指针我们可以打印出其指向的mm_struct的值,具体命令和输出如下:
crash_ARM64> struct mm_struct ffffffd76e349a00
struct mm_struct {
mmap = 0xffffffd705b1b4d0,
mm_rb = {
rb_node = 0xffffffd64ceec230
},
vmacache_seqnum = 11763,
get_unmapped_area = 0xffffff99a6791434,
mmap_base = 4142907392,
mmap_legacy_base = 0,
task_size = 4294967296,
highest_vm_end = 4294905856,
pgd = 0xffffffd70c70c000,
...
owner = 0xffffffd728b8b200,
exe_file = 0xffffffd75c119300,
tlb_flush_pending = false,
uprobes_state = {<No data fields>}
}
其中mm_struct的owner成员指向task_struct,所以根据这个信息我们可以知道这个mm_struct是属于哪一个进程:
crash_ARM64> struct task_struct.comm,pid 0xffffffd728b8b200
comm = "tencent.karaoke"
pid = 1651
至此我们就可以知道watchdog线程是在读取tencent.karaoke的proc节点时被block了,原因是这个进程的mm的mmap_sem被其他线程持有了,所以接下来我们需要继续分析是谁持了mmap_sem。
在上面的分析推导中我们找到了x21即mm指针,接下来我们给x21加上0x68就可以得到x28,即x28 = x21 + 0x68 = 0xffffffd76e349a68,我们知道x28中存放的是sem指针,而sem指针又是以参数的方式将mm->mmap_sem传递过去的,所以sem指针就是mm->mmap_sem指针,根据这个mm->mmap_sem指针我们可以打印出其指向的rw_semaphore的值,具体命令和输出如下:
crash_ARM64> struct rw_semaphore -x ffffffd76e349a68
struct rw_semaphore {
count = 0xffffffff00000001,
wait_list = {
next = 0xffffffd604ac3e10,
prev = 0xffffffd68204bce0
},
wait_lock = {
raw_lock = {
owner = 0x1659,
next = 0x1659
}
},
osq = {
tail = {
counter = 0x0
}
},
owner = 0x0
}
打印出rw_semaphore的值之后我们可以通过它的成员wait_list查找有哪些线程在等待这个rw_semaphore,具体命令和输出如下:
crash_ARM64> list rwsem_waiter.list -s rwsem_waiter.task,type -h 0xffffffd604ac3e10
ffffffd604ac3e10
task = 0xffffffd64894b200
type = RWSEM_WAITING_FOR_WRITE
ffffffd70c4d3d70
task = 0xffffffd728b8b200
type = RWSEM_WAITING_FOR_READ
ffffffd619c4fd70
task = 0xffffffd75ef54b00
type = RWSEM_WAITING_FOR_READ
ffffffd6cd317d70
task = 0xffffffd7071de400
type = RWSEM_WAITING_FOR_READ
ffffffd6e531bd70
task = 0xffffffd71ba99900
type = RWSEM_WAITING_FOR_READ
ffffffd75d33fcd0
task = 0xffffffd75a8abe80
type = RWSEM_WAITING_FOR_READ
ffffffd604a87d70
task = 0xffffffd64fbe3e80
type = RWSEM_WAITING_FOR_READ
ffffffd76fb8fd70
task = 0xffffffd627cff080
type = RWSEM_WAITING_FOR_READ
ffffffd70e1abd70
task = 0xffffffd6ae10f080
type = RWSEM_WAITING_FOR_READ
ffffffd66ccf7970
task = 0xffffffd65bb72580
type = RWSEM_WAITING_FOR_WRITE
ffffffd6a3937d70
task = 0xffffffd728b8e400
type = RWSEM_WAITING_FOR_READ
ffffffd6d9e4bce0
task = 0xffffffd63ad2e400
type = RWSEM_WAITING_FOR_READ
ffffffd683d93d70
task = 0xffffffd728b89900
type = RWSEM_WAITING_FOR_READ
ffffffd686d3fd70
task = 0xffffffd6c3f6a580
type = RWSEM_WAITING_FOR_READ
ffffffd6db78fd70
task = 0xffffffd705b4f080
type = RWSEM_WAITING_FOR_READ
ffffffd68778bce0
task = 0xffffffd616f6cb00
type = RWSEM_WAITING_FOR_READ
ffffffd6197e7ce0
task = 0xffffffd6156f8c80
type = RWSEM_WAITING_FOR_READ
ffffffd6812e7ce0
task = 0xffffffd659b72580
type = RWSEM_WAITING_FOR_READ
ffffffd68204bce0
task = 0xffffffd626a1be80
type = RWSEM_WAITING_FOR_READ
从上面的wait_list中可以看到有2个write和17个read总共19个线程都在等待这个rw_semaphore,在等待期间这19个线程都会进入UNINTERRUPTIBLE状态,可以通过ps命令来列出当前系统中所有的UNINTERRUPTIBLE状态线程来确认,具体命令和输出如下:
crash_ARM64> ps -u |grep UN
1119 1473 1 ffffffd6ae10f080 UN 2.7 2089184 222932 Binder:1651_5
* 1643 1 6 ffffffd757d65780 UN 0.2 133072 15584 Binder:1474_2
1651 1473 2 ffffffd728b8b200 UN 2.7 2089184 222932 tencent.karaoke
1659 1473 0 ffffffd728b89900 UN 2.7 2089184 222932 JDWP
1663 1473 2 ffffffd64894b200 UN 2.7 2089184 222932 HeapTaskDaemon
1711 1473 2 ffffffd627cff080 UN 2.7 2089184 222932 ccess.Collector
1749 1473 5 ffffffd705b4f080 UN 2.7 2089184 222932 TcmReceiver
1805 1473 1 ffffffd728b8e400 UN 2.7 2089184 222932 ReporterMachine
1818 1473 2 ffffffd64fbe3e80 UN 2.7 2089184 222932 pool-2-thread-1
1862 1473 2 ffffffd71ba99900 UN 2.7 2089184 222932 pool-4-thread-1
1864 1473 0 ffffffd7071de400 UN 2.7 2089184 222932 pool-4-thread-3
1869 1473 1 ffffffd6c3f6a580 UN 2.7 2089184 222932 TcmReceiver
1872 1472 4 ffffffd75a8abe80 UN 4.2 2678340 350496 android.bg
* 1873 1472 6 ffffffd75a8acb00 UN 4.2 2678340 350496 ActivityManager
* 1909 1472 6 ffffffd7587e1900 UN 4.2 2678340 350496 android.display
2107 1473 1 ffffffd75ef54b00 UN 2.7 2089184 222932 PackageProcesso
* 2650 1472 0 ffffffd758db2580 UN 4.2 2678340 350496 ConnectivitySer
* 2767 601 2 ffffffd6e2180c80 UN 0.0 19556 3888 sdcard
2980 1472 0 ffffffd63ad2e400 UN 4.2 2678340 350496 watchdog
3337 1472 0 ffffffd65bb72580 UN 4.2 2678340 350496 Binder:1817_18
28387 1 6 ffffffd616f6cb00 UN 0.0 9656 1936 ps
29239 1 2 ffffffd6156f8c80 UN 0.0 9656 1944 ps
30079 1 6 ffffffd659b72580 UN 0.0 9656 1936 ps
30271 1 6 ffffffd626a1be80 UN 0.0 9656 1940 ps
可以发现这19个线程都在上面ps输出的列表中,分析到这里我们知道了包括watchdog线程在内的19个线程都被tencent.karaoke进程的rw_semaphore block了,但是怎么找到是谁持有着这个rw_semaphore呢?
一般情况下我们可以通过rw_semaphore的owner成员找到持有rw_semaphore的线程,但是这里owner是0,导致这种情况发生的原因只有两种,一种是CONFIG_RWSEM_SPIN_ON_OWNER宏没打开,另外一种是持有rw_semaphore的是read线程,不管是哪一种原因我们都没有办法再根据这个owner成员来快速找到持有者了,这个时候怎么办?
常规手段无效之后我们只能使用非常规手段之栈推导,接下来我们就一步步通过栈推导的方式来查找持有rw_semaphore的线程。
推导之前我们有必要先看看rw_semaphore的基本用法来作为背景知识:
static void my_function()
{
...
down_read(&sem);
...
sub_function();
...
up_read(&sem);
...
}
正常情况下一个函数里先用down_xxx函数来持有rw_semaphore,然后执行相关的代码及子函数调用,在调用的过程中为了保证子函数返回后能正常调用up_xxx来释放rw_semaphore,所以在子函数中或者更深一级的子函数中必须要将保存rw_semaphore地址的寄存器存储到栈帧中,并且在子函数返回时从栈中恢复这个寄存器的值,因此,我们只需要扫描所有线程的栈帧找到rw_semaphore的地址ffffffd76e349a68,就能找到等待rw_semaphore和持有rw_semaphore的线程,具体命令和输出如下:
crash64> search -t ffffffd76e349a68
PID: 1119 TASK: ffffffd6ae10f080 CPU: 1 COMMAND: "Binder:1651_5"
ffffffd70e1abd10: ffffffd76e349a68
ffffffd70e1abd30: ffffffd76e349a68
PID: 1651 TASK: ffffffd728b8b200 CPU: 2 COMMAND: "tencent.karaoke"
ffffffd70c4d3d10: ffffffd76e349a68
ffffffd70c4d3d30: ffffffd76e349a68
PID: 1659 TASK: ffffffd728b89900 CPU: 0 COMMAND: "JDWP"
ffffffd683d93d10: ffffffd76e349a68
ffffffd683d93d30: ffffffd76e349a68
PID: 1663 TASK: ffffffd64894b200 CPU: 2 COMMAND: "HeapTaskDaemon"
ffffffd604ac3e40: ffffffd76e349a68
PID: 1711 TASK: ffffffd627cff080 CPU: 2 COMMAND: "ccess.Collector"
ffffffd76fb8fd10: ffffffd76e349a68
ffffffd76fb8fd30: ffffffd76e349a68
PID: 1749 TASK: ffffffd705b4f080 CPU: 5 COMMAND: "TcmReceiver"
ffffffd6db78fd10: ffffffd76e349a68
ffffffd6db78fd30: ffffffd76e349a68
PID: 1805 TASK: ffffffd728b8e400 CPU: 1 COMMAND: "ReporterMachine"
ffffffd6a3937d10: ffffffd76e349a68
ffffffd6a3937d30: ffffffd76e349a68
PID: 1818 TASK: ffffffd64fbe3e80 CPU: 2 COMMAND: "pool-2-thread-1"
ffffffd604a87d10: ffffffd76e349a68
ffffffd604a87d30: ffffffd76e349a68
PID: 1862 TASK: ffffffd71ba99900 CPU: 2 COMMAND: "pool-4-thread-1"
ffffffd6e531bd10: ffffffd76e349a68
ffffffd6e531bd30: ffffffd76e349a68
PID: 1864 TASK: ffffffd7071de400 CPU: 0 COMMAND: "pool-4-thread-3"
ffffffd6cd317d10: ffffffd76e349a68
ffffffd6cd317d30: ffffffd76e349a68
PID: 1869 TASK: ffffffd6c3f6a580 CPU: 1 COMMAND: "TcmReceiver"
ffffffd686d3fd10: ffffffd76e349a68
ffffffd686d3fd30: ffffffd76e349a68
PID: 1872 TASK: ffffffd75a8abe80 CPU: 4 COMMAND: "android.bg"
ffffffd75d33fc90: ffffffd76e349a68
PID: 2107 TASK: ffffffd75ef54b00 CPU: 1 COMMAND: "PackageProcesso"
ffffffd619c4fd10: ffffffd76e349a68
ffffffd619c4fd30: ffffffd76e349a68
PID: 2124 TASK: ffffffd771be3e80 CPU: 0 COMMAND: "wnloader.impl.c"
ffffffd6d396b8b0: ffffffd76e349a68
PID: 2980 TASK: ffffffd63ad2e400 CPU: 0 COMMAND: "watchdog"
ffffffd6d9e4bca0: ffffffd76e349a68
PID: 3337 TASK: ffffffd65bb72580 CPU: 0 COMMAND: "Binder:1817_18"
ffffffd66ccf7930: ffffffd76e349a68
PID: 28387 TASK: ffffffd616f6cb00 CPU: 6 COMMAND: "ps"
ffffffd68778bca0: ffffffd76e349a68
PID: 29239 TASK: ffffffd6156f8c80 CPU: 2 COMMAND: "ps"
ffffffd6197e7ca0: ffffffd76e349a68
PID: 30079 TASK: ffffffd659b72580 CPU: 6 COMMAND: "ps"
ffffffd6812e7ca0: ffffffd76e349a68
PID: 30271 TASK: ffffffd626a1be80 CPU: 6 COMMAND: "ps"
ffffffd68204bca0: ffffffd76e349a68
从上面的输出来看总共找到了20个存储rw_semaphore地址的线程栈帧,其中有19个是在wait_list中等待rw_semaphore的线程,根据前面的原理和背景推导,剩下的那1个线程就势必是持有rw_semaphore的线程,这个线程的信息如下:
PID: 2124 TASK: ffffffd771be3e80 CPU: 0 COMMAND: "wnloader.impl.c"
ffffffd6d396b8b0: ffffffd76e349a68
通过PID可以知道这个线程是tencent.karaoke进程的子线程,查看一下这个线程的调用栈,具体命令和输出如下:
crash_ARM64> bt 2124
PID: 2124 TASK: ffffffd771be3e80 CPU: 0 COMMAND: "wnloader.impl.c"
#0 [ffffffd6d396b4b0] __switch_to at ffffff99a6685560
#1 [ffffffd6d396b4e0] __schedule at ffffff99a74df9f0
#2 [ffffffd6d396b540] schedule at ffffff99a74dfd54
#3 [ffffffd6d396b560] request_wait_answer at ffffff99a68c0350
#4 [ffffffd6d396b5d0] __fuse_request_send at ffffff99a68c2f60
#5 [ffffffd6d396b600] fuse_request_send at ffffff99a68c2fb8
#6 [ffffffd6d396b610] fuse_send_readpages at ffffff99a68c8ef8
#7 [ffffffd6d396b640] fuse_readpages at ffffff99a68c8fe8
#8 [ffffffd6d396b6c0] __do_page_cache_readahead at ffffff99a676cfc0
#9 [ffffffd6d396b780] filemap_fault at ffffff99a6762fc4
#10 [ffffffd6d396b7f0] __do_fault at ffffff99a6789c38
#11 [ffffffd6d396b860] handle_mm_fault at ffffff99a678d540
#12 [ffffffd6d396b920] do_page_fault at ffffff99a6696f4c
#13 [ffffffd6d396b990] do_mem_abort at ffffff99a6680ad8
#14 [ffffffd6d396bb80] el1_da at ffffff99a6683cf8
#15 [ffffffd6d396bc00] __generic_file_write_iter at ffffff99a6762af8
#16 [ffffffd6d396bc50] ext4_file_write_iter at ffffff99a68201f4
#17 [ffffffd6d396bd00] fuse_passthrough_write_iter at ffffff99a68cd4d0
#18 [ffffffd6d396bd50] fuse_file_write_iter at ffffff99a68ca1f4
#19 [ffffffd6d396bdb0] __vfs_write at ffffff99a67b49a0
#20 [ffffffd6d396be30] vfs_write at ffffff99a67b515c
#21 [ffffffd6d396be70] sys_pwrite64 at ffffff99a67b5a1c
从上面的kernel调用栈和search的结果可以看到rw_semaphore的地址是存储在handle_mm_fault的栈帧里,因此基于前面的理论可以推断,持锁的函数是在handle_mm_fault之前。
我们先看一下do_page_fault函数:
/* kernel/msm-4.4/arch/arm64/mm/fault.c */
static int __kprobes do_page_fault(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
struct task_struct *tsk;
struct mm_struct *mm;
int fault, sig, code;
unsigned long vm_flags = VM_READ | VM_WRITE | VM_EXEC;
unsigned int mm_flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE;
tsk = current;
mm = tsk->mm;
...
if (!down_read_trylock(&mm->mmap_sem)) {
if (!user_mode(regs) && !search_exception_tables(regs->pc))
goto no_context;
retry:
down_read(&mm->mmap_sem); <<<
} else {
...
}
fault = __do_page_fault(mm, addr, mm_flags, vm_flags, tsk);
...
up_read(&mm->mmap_sem);
...
}
static int __do_page_fault(struct mm_struct *mm, unsigned long addr,
unsigned int mm_flags, unsigned long vm_flags, struct task_struct *tsk)
{
...
return handle_mm_fault(mm, vma, addr & PAGE_MASK, mm_flags);
}
代码中确实是存在持有mmap_sem的地方,分析到这里就基本确定是2124线程持有了mmap_sem,并且也解释了前面watchdog线程为什么没有重启系统的问题,但是2124线程为什么在持有mmap_sem后迟迟不释放,从而导致包括watchdog线程在内的19个线程都被block?
3. 深入分析
带着初步分析的线索和问题,我们继续分析,首先再看一下2124线程的kernel调用栈:
crash_ARM64> bt 2124
PID: 2124 TASK: ffffffd771be3e80 CPU: 0 COMMAND: "wnloader.impl.c"
#0 [ffffffd6d396b4b0] __switch_to at ffffff99a6685560
#1 [ffffffd6d396b4e0] __schedule at ffffff99a74df9f0
#2 [ffffffd6d396b540] schedule at ffffff99a74dfd54
#3 [ffffffd6d396b560] request_wait_answer at ffffff99a68c0350
#4 [ffffffd6d396b5d0] __fuse_request_send at ffffff99a68c2f60
#5 [ffffffd6d396b600] fuse_request_send at ffffff99a68c2fb8
#6 [ffffffd6d396b610] fuse_send_readpages at ffffff99a68c8ef8
#7 [ffffffd6d396b640] fuse_readpages at ffffff99a68c8fe8
#8 [ffffffd6d396b6c0] __do_page_cache_readahead at ffffff99a676cfc0
#9 [ffffffd6d396b780] filemap_fault at ffffff99a6762fc4
#10 [ffffffd6d396b7f0] __do_fault at ffffff99a6789c38
#11 [ffffffd6d396b860] handle_mm_fault at ffffff99a678d540
#12 [ffffffd6d396b920] do_page_fault at ffffff99a6696f4c
#13 [ffffffd6d396b990] do_mem_abort at ffffff99a6680ad8
#14 [ffffffd6d396bb80] el1_da at ffffff99a6683cf8
#15 [ffffffd6d396bc00] __generic_file_write_iter at ffffff99a6762af8
#16 [ffffffd6d396bc50] ext4_file_write_iter at ffffff99a68201f4
#17 [ffffffd6d396bd00] fuse_passthrough_write_iter at ffffff99a68cd4d0
#18 [ffffffd6d396bd50] fuse_file_write_iter at ffffff99a68ca1f4
#19 [ffffffd6d396bdb0] __vfs_write at ffffff99a67b49a0
#20 [ffffffd6d396be30] vfs_write at ffffff99a67b515c
#21 [ffffffd6d396be70] sys_pwrite64 at ffffff99a67b5a1c
从调用栈上可以看到2124线程是等待fuse的处理结果,我们知道fuse的请求是由sdcard进程处理的,所以我们接下来再看一下sdcard进程中各个线程的状态,通过ps命令发现sdcard进程总共有4个线程,其中有一个线程处于可疑的D状态,具体调用栈如下:
crash_ARM64> bt 2767
PID: 2767 TASK: ffffffd6e2180c80 CPU: 2 COMMAND: "sdcard"
#0 [ffffffd6e218fac0] __switch_to at ffffff99a6685560
#1 [ffffffd6e218faf0] __schedule at ffffff99a74df9f0
#2 [ffffffd6e218fb50] schedule at ffffff99a74dfd54
#3 [ffffffd6e218fb70] schedule_preempt_disabled at ffffff99a74e009c
#4 [ffffffd6e218fb90] __mutex_lock_slowpath at ffffff99a74e15d4
#5 [ffffffd6e218fbf0] mutex_lock at ffffff99a74e1664
#6 [ffffffd6e218fc10] do_truncate at ffffff99a67b35bc
#7 [ffffffd6e218fc80] path_openat at ffffff99a67c1938
#8 [ffffffd6e218fd50] do_filp_open at ffffff99a67c26f8
#9 [ffffffd6e218fe50] do_sys_open at ffffff99a67b44c4
#10 [ffffffd6e218feb0] sys_openat at ffffff99a67b4594
#11 [ffffffd6e218fed0] el0_svc_naked at ffffff99a668462c
这个sdcard线程是在做什么呢?为什么会进入D状态?进入D状态会直接影响2124线程的fuse请求吗?
带着问题和调用栈我们继续分析,首先看一下2124线程正在执行的__fuse_request_send函数的实现:
/* kernel/msm-4.4/fs/fuse/dev.c */
static void __fuse_request_send(struct fuse_conn *fc, struct fuse_req *req)
{
struct fuse_iqueue *fiq = &fc->iq;
BUG_ON(test_bit(FR_BACKGROUND, &req->flags));
spin_lock(&fiq->waitq.lock);
if (!fiq->connected) {
spin_unlock(&fiq->waitq.lock);
req->out.h.error = -ENOTCONN;
} else {
req->in.h.unique = fuse_get_unique(fiq);
queue_request(fiq, req);
__fuse_get_request(req);
spin_unlock(&fiq->waitq.lock);
request_wait_answer(fc, req); <<<<
/* Pairs with smp_wmb() in request_end() */
smp_rmb();
}
}
我们先通过栈推导,推导过程可以参考上面,具体过程就不再赘述,推导出fuse_req的地址为ffffffd6db690d00,然后打印出fuse_req的值:
crash_ARM64> struct -x fuse_req ffffffd6db690d00
struct fuse_req {
list = {
next = 0xffffffd7063d8000,
prev = 0xffffffd76f868680
},
intr_entry = {
next = 0xffffffd6db690d10,
prev = 0xffffffd6db690d10
},
count = {
counter = 0x2
},
intr_unique = 0x0,
flags = 0x89,
...
从中可以看到flags = 0x89 = 0b10001001,对应的flags定义如下:
enum fuse_req_flag {
FR_ISREPLY,
FR_FORCE,
FR_BACKGROUND,
FR_WAITING,
FR_ABORTED,
FR_INTERRUPTED,
FR_LOCKED,
FR_PENDING,
FR_SENT,
FR_FINISHED,
FR_PRIVATE,
};
因此可以计算出flags对应的组合是FR_ISREPLY|FR_WAITING|FR_PENDING,根据PENDING状态我们可以知道sdcard进程正在处理前面的请求,并且从sdcard进程的另外两个线程的调用栈中可以看出它们都在空闲状态,只有2767线程当前在工作并处于D状态,至此即可确定2124线程是在等待2767线程,或者说是2124线程被2767线程block,但是2767线程为什么会一直处于D状态?
带着问题我们继续分析,再次看一下2767线程的kernel调用栈:
crash_ARM64> bt 2767
PID: 2767 TASK: ffffffd6e2180c80 CPU: 2 COMMAND: "sdcard"
#0 [ffffffd6e218fac0] __switch_to at ffffff99a6685560
#1 [ffffffd6e218faf0] __schedule at ffffff99a74df9f0
#2 [ffffffd6e218fb50] schedule at ffffff99a74dfd54
#3 [ffffffd6e218fb70] schedule_preempt_disabled at ffffff99a74e009c
#4 [ffffffd6e218fb90] __mutex_lock_slowpath at ffffff99a74e15d4
#5 [ffffffd6e218fbf0] mutex_lock at ffffff99a74e1664
#6 [ffffffd6e218fc10] do_truncate at ffffff99a67b35bc
#7 [ffffffd6e218fc80] path_openat at ffffff99a67c1938
#8 [ffffffd6e218fd50] do_filp_open at ffffff99a67c26f8
#9 [ffffffd6e218fe50] do_sys_open at ffffff99a67b44c4
#10 [ffffffd6e218feb0] sys_openat at ffffff99a67b4594
#11 [ffffffd6e218fed0] el0_svc_naked at ffffff99a668462c
从调用栈中可以看到2767线程是在执行mutex_lock时由于无法获取成功mutex而进入D状态,所以接下来我们需要先找到这个mutex的地址,然后再找出来是谁持有了这个mutex,怎么找?
我们首先从mutex_lock函数入手,看一下mutex_lock函数的声明:
crash_ARM64> p mutex_lock
mutex_lock = $26 =
{void (struct mutex *)} 0xffffff99a74e163c
从上面的打印可以看到它的参数只有1个,就是struct mutex指针,接下来再看看mutex_lock函数的实现:
crash_ARM64> dis mutex_lock
0xffffff99a74e163c <mutex_lock>: stp x29, x30, [sp,#-32]!
0xffffff99a74e1640 <mutex_lock+4>: mov x29, sp
0xffffff99a74e1644 <mutex_lock+8>: str x19, [sp,#16]
0xffffff99a74e1648 <mutex_lock+12>: mov x19, x0
0xffffff99a74e164c <mutex_lock+16>: prfm pstl1strm, [x0]
0xffffff99a74e1650 <mutex_lock+20>: ldaxr w1, [x0]
0xffffff99a74e1654 <mutex_lock+24>: sub w1, w1, #0x1
0xffffff99a74e1658 <mutex_lock+28>: stxr w2, w1, [x0]
0xffffff99a74e165c <mutex_lock+32>: cbnz w2, 0xffffff99a74e1650
0xffffff99a74e1660 <mutex_lock+36>: tbz w1, #31, 0xffffff99a74e1668
0xffffff99a74e1664 <mutex_lock+40>: bl 0xffffff99a74e14ec
0xffffff99a74e1668 <mutex_lock+44>: mrs x0, sp_el0
0xffffff99a74e166c <mutex_lock+48>: ldr x0, [x0,#16]
0xffffff99a74e1670 <mutex_lock+52>: str x0, [x19,#24]
0xffffff99a74e1674 <mutex_lock+56>: ldr x19, [sp,#16]
0xffffff99a74e1678 <mutex_lock+60>: ldp x29, x30, [sp],#32
0xffffff99a74e167c <mutex_lock+64>: ret
mutex_lock的第一个参数x0就是我们要找的struct mutex指针,它在函数入口处被保存到了x19寄存器中:
0xffffff99a74e1648 <mutex_lock+12>: mov x19, x0
接着又调用了__mutex_lock_slowpath:
0xffffff99a74e1664 <mutex_lock+40>: bl 0xffffff99a74e14ec
x19寄存器是callee寄存器,即在被调用的函数中如果要用到x19就会保存在被调用函数的栈帧中,这里对应的被调用函数就是__mutex_lock_slowpath:
crash_ARM64> dis __mutex_lock_slowpath
0xffffff99a74e14ec <__mutex_lock_slowpath>: stp x29, x30, [sp,#-96]!
0xffffff99a74e14f0 <__mutex_lock_slowpath+4>: mov x29, sp
0xffffff99a74e14f4 <__mutex_lock_slowpath+8>: stp x19, x20, [sp,#16]
0xffffff99a74e14f8 <__mutex_lock_slowpath+12>: stp x21, x22, [sp,#32]
0xffffff99a74e14fc <__mutex_lock_slowpath+16>: stp x23, x24, [sp,#48]
0xffffff99a74e1500 <__mutex_lock_slowpath+20>: mrs x20, sp_el0
0xffffff99a74e1504 <__mutex_lock_slowpath+24>: ldr w1, [x20,#24]
0xffffff99a74e1508 <__mutex_lock_slowpath+28>: mov x19, x0
从上面对应的汇编代码中我们可以看到__mutex_lock_slowpath函数确实将x19寄存器保存在了栈帧中,因此我们只需要在__mutex_lock_slowpath的栈帧中找到x19,它就是我们要找的struct mutex指针了。
通过bt 2767命令的输出可知,__mutex_lock_slowpath的栈帧范围是ffffffd6e218fb90到ffffffd6e218fbf0:
#4 [ffffffd6e218fb90] __mutex_lock_slowpath at ffffff99a74e15d4
#5 [ffffffd6e218fbf0] mutex_lock at ffffff99a74e1664
再对应__mutex_lock_slowpath的汇编代码:
crash_ARM64> dis __mutex_lock_slowpath
0xffffff99a74e14ec <__mutex_lock_slowpath>: stp x29, x30, [sp,#-96]!
0xffffff99a74e14f0 <__mutex_lock_slowpath+4>: mov x29, sp
0xffffff99a74e14f4 <__mutex_lock_slowpath+8>: stp x19, x20, [sp,#16]
0xffffff99a74e14f8 <__mutex_lock_slowpath+12>: stp x21, x22, [sp,#32]
0xffffff99a74e14fc <__mutex_lock_slowpath+16>: stp x23, x24, [sp,#48]
...
我们可以得到栈帧和寄存器的位置对应关系:
crash_ARM64> rd ffffffd6e218fb90 -e ffffffd6e218fbf0
ffffffd6e218fb90: ffffffd6e218fbf0 ffffff99a74e1668 ........h.N.....
x29 x30
ffffffd6e218fba0: ffffffd6948f4090 ffffffd75a828c00 .@.........Z....
x19 x20
...
最终得到mutex的值就是ffffffd6948f4090,它的owner为:
crash_ARM64> struct mutex.owner ffffffd6948f4090
owner = 0xffffffd771be3e80
持锁线程的pid为:
crash_ARM64> struct task_struct.pid 0xffffffd771be3e80
pid = 2124
分析到这里2124线程和2767线程之间的关系基本清楚了,2124线程在持有mutex锁的情况下发送了fuse请求并等待2767线程处理,而2767线程当前又在处理另外一个fuse请求,并且处理这个请求的过程中又需要被2124线程持有的mutex锁,简单点说就是2124线程和2767线程之间死锁了,但是为什么会死锁呢?
带着问题继续分析,看它在持有mutex的情况下又发送fuse请求的逻辑是否合理?
首先我们先看2124线程的调用栈并找出持有mutex的函数:
crash_ARM64> bt 2124
PID: 2124 TASK: ffffffd771be3e80 CPU: 0 COMMAND: "wnloader.impl.c"
#0 [ffffffd6d396b4b0] __switch_to at ffffff99a6685560
#1 [ffffffd6d396b4e0] __schedule at ffffff99a74df9f0
#2 [ffffffd6d396b540] schedule at ffffff99a74dfd54
#3 [ffffffd6d396b560] request_wait_answer at ffffff99a68c0350
#4 [ffffffd6d396b5d0] __fuse_request_send at ffffff99a68c2f60
#5 [ffffffd6d396b600] fuse_request_send at ffffff99a68c2fb8
#6 [ffffffd6d396b610] fuse_send_readpages at ffffff99a68c8ef8
#7 [ffffffd6d396b640] fuse_readpages at ffffff99a68c8fe8
#8 [ffffffd6d396b6c0] __do_page_cache_readahead at ffffff99a676cfc0
#9 [ffffffd6d396b780] filemap_fault at ffffff99a6762fc4
#10 [ffffffd6d396b7f0] __do_fault at ffffff99a6789c38
#11 [ffffffd6d396b860] handle_mm_fault at ffffff99a678d540
#12 [ffffffd6d396b920] do_page_fault at ffffff99a6696f4c
#13 [ffffffd6d396b990] do_mem_abort at ffffff99a6680ad8
#14 [ffffffd6d396bb80] el1_da at ffffff99a6683cf8
#15 [ffffffd6d396bc00] __generic_file_write_iter at ffffff99a6762af8
#16 [ffffffd6d396bc50] ext4_file_write_iter at ffffff99a68201f4
#17 [ffffffd6d396bd00] fuse_passthrough_write_iter at ffffff99a68cd4d0
#18 [ffffffd6d396bd50] fuse_file_write_iter at ffffff99a68ca1f4
#19 [ffffffd6d396bdb0] __vfs_write at ffffff99a67b49a0
#20 [ffffffd6d396be30] vfs_write at ffffff99a67b515c
#21 [ffffffd6d396be70] sys_pwrite64 at ffffff99a67b5a1c
根据栈推导的原理找出存mutex指针ffffffd6948f4090的栈帧:
crash_ARM64> rd ffffffd6d396b4b0 -e ffffffd6d396be70
...
ffffffd6d396bc40: ffffffd6948f4090 0000000000000000 .@..............
...
在ffffffd6d396bc40处即__generic_file_write_iter的栈帧里找到了mutex指针:
#15 [ffffffd6d396bc00] __generic_file_write_iter at ffffff99a6762af8
#16 [ffffffd6d396bc50] ext4_file_write_iter at ffffff99a68201f4
根据栈推导的原理可以知道在__generic_file_write_iter之前的函数中就已经持锁了,所以接着再查看ext4_file_write_iter函数:
/* kernel/msm-4.4/fs/ext4/file.c */
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct inode *inode = file_inode(iocb->ki_filp);
...
mutex_lock(&inode->i_mutex);
...
ret = __generic_file_write_iter(iocb, from);
mutex_unlock(&inode->i_mutex);
从上面的代码中可以看到在ext4_file_write_iter函数中确实持有了mutex,接着调用了__generic_file_write_iter函数,随后发生了pagefault,在处理pagefault的过程中又触发了fuse的read请求。
分析到这里有两个个问题:
1、从调用栈上来看2124线程是在进行fuse文件的write的操作,正常情况下fuse文件的访问都是通过将请求发送给fuse daemon即sdcard进程来完成的,这里却越过sdcard进程直接拿着ext4的inode操作了ext4,为什么?
2、在ext4文件写入的过程中为什么发生了pagefault并触发了fuse的read请求?
通过分析源代码发现这是fuse中的一个名叫passthrough的优化,即在进行fuse文件操作的进程中获取fuse文件对应的ext4文件的inode,然后直接对文件进行读写操作,关键源代码如下:
/* kernel/msm-4.4/fs/fuse/passthrough.c */
static ssize_t fuse_passthrough_read_write_iter(struct kiocb *iocb,
struct iov_iter *iter, int do_write)
{
ssize_t ret_val;
struct fuse_file *ff;
struct file *fuse_file, *passthrough_filp;
struct inode *fuse_inode, *passthrough_inode;
struct fuse_conn *fc;
ff = iocb->ki_filp->private_data;
fuse_file = iocb->ki_filp;
passthrough_filp = ff->passthrough_filp;
fc = ff->fc;
get_file(passthrough_filp);
iocb->ki_filp = passthrough_filp;
fuse_inode = fuse_file->f_path.dentry->d_inode;
passthrough_inode = file_inode(passthrough_filp);
if (do_write) {
if (!passthrough_filp->f_op->write_iter)
return -EIO;
ret_val = passthrough_filp->f_op->write_iter(iocb, iter);
...
/* kernel/msm-4.4/fs/fuse/file.c */
int fuse_do_open(struct fuse_conn *fc, u64 nodeid, struct file *file, bool isdir)
{
struct fuse_file *ff;
struct file *passthrough_filp = NULL;
int opcode = isdir ? FUSE_OPENDIR : FUSE_OPEN;
ff = fuse_file_alloc(fc);
ff->fh = 0;
ff->open_flags = FOPEN_KEEP_CACHE;
if (!fc->no_open || isdir) {
struct fuse_open_out outarg;
int err;
err = fuse_send_open(fc, nodeid, file, opcode, &outarg, &(passthrough_filp));
if (!err) {
ff->fh = outarg.fh;
ff->open_flags = outarg.open_flags;
ff->passthrough_filp = passthrough_filp;
...
file->private_data = fuse_file_get(ff);
return 0;
}
通过passthrough的优化可以节省sdcard的中间环节提升读写性能和效率,但是这种可能增加了fuse文件读写的进程和sdcard进程之间的竞争,分析到这里解释了第一个问题,即为什么fuse文件写入会直接操作ext4文件。
继续分析来解释第二个问题,从调用栈中可以看到是__generic_file_write_iter函数在调用iov_iter_fault_in_readable函数时触发的pagefault:
#13 [ffffffd6d396b990] do_mem_abort at ffffff99a6680ad8
#14 [ffffffd6d396bb80] el1_da at ffffff99a6683cf8
PC: ffffffd7017056c0 [unknown or invalid address]
LR: ffffff99a695da6c [iov_iter_fault_in_readable+64]
...
#15 [ffffffd6d396bc00] __generic_file_write_iter at ffffff99a6762af8
#16 [ffffffd6d396bc50] ext4_file_write_iter at ffffff99a68201f4
查看对应的源码:
/* kernel/msm-4.4/mm/filemap.c */
size_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
...
if (iocb->ki_flags & IOCB_DIRECT) {
...
status = generic_perform_write(file, from, pos = iocb->ki_pos);
...
ssize_t generic_perform_write(struct file *file, struct iov_iter *i, loff_t pos)
{
...
unsigned long bytes; /* Bytes to write to page */
...
if (unlikely(iov_iter_fault_in_readable(i, bytes))) {
...
pagefault是发生在iov_iter_fault_in_readable函数中,参数i是__generic_file_write_iter函数的from参数,通过分析iov_iter_fault_in_readable函数的源码可以知道发生pagefault的是from指向的buf,但是这个buf为什么会pagefault并且触发fuse的read请求?
通过pagefault的调用栈我们可以确定from指向的buf是mmap的一个fuse文件的返回地址,所以在访问buf时一旦访问到还没有从文件中映射的数据,就会触发pagefault来分配page,并从文件中read对应的数据加载到page中,同时更新页表将page和buf关联,由于这个文件是fuse文件,所以这里的read操作就需要将请求发送给sdcard进程,但是当前sdcard进程中的工作线程正在open一个文件,open的过程中需要这个文件的inode的mutex,由于这个文件的inode的mutex已经被发送read请求的线程占用,从而发生了死锁,分析到这里第二个问题也已经解释清楚了,即在ext4文件写入的过程中为什么发生pagefault并触发fuse的read请求。
分析清楚了发生死锁的原理和流程,接下来我们就可以写一个测试程序来模拟复现问题的场景:
static void* fuse_test1(void* data)
{
int fd = -1;
while (1) {
fd = open("/sdcard/test2.txt", O_WRONLY|O_CREAT|O_TRUNC );
close(fd);
}
return NULL;
}
int main(int argc, char** argv)
{
int ret = 0;
int fd1 = -1;
int fd2 = -1;
pthread_t thread1;
unsigned char * base = NULL;
fd1 = open("/sdcard/test1.txt", O_RDWR);
fd2 = open("/sdcard/test2.txt", O_RDWR);
pthread_create(&thread1, NULL, fuse_test1, NULL);
while(1) {
base = (unsigned char *)mmap(0, 4096*50000,PROT_READ|PROT_WRITE, MAP_SHARED, fd1, 0);
ret = write(fd2, base, 4096*50000);
munmap(base, 4096*50000);
usleep(1000);
}
return 0;
}
将测试程序push到手机上执行,必现当前的问题,调用栈和相关线程状态如下:
# ps -t 4225
USER PID PPID VSIZE RSS WCHAN PC NAME
root 4225 4169 210128 1676 request_wa 7f9d038358 S fusetest
root 4226 4225 210128 1676 request_wa 7f9d037338 S fusetest
# cat proc/4225/stack
[<0000000000000000>] __switch_to+0x98/0xa4
[<0000000000000000>] request_wait_answer+0x64/0x248
[<0000000000000000>] __fuse_request_send+0x84/0x98
[<0000000000000000>] fuse_request_send+0x44/0x4c
[<0000000000000000>] fuse_send_readpages+0x90/0xb8
[<0000000000000000>] fuse_readpages+0xc8/0xf0
[<0000000000000000>] __do_page_cache_readahead+0x144/0x210
[<0000000000000000>] ondemand_readahead+0x214/0x230
[<0000000000000000>] page_cache_async_readahead+0xc8/0xdc
[<0000000000000000>] filemap_fault+0xc4/0x418
[<0000000000000000>] __do_fault+0x3c/0x8c
[<0000000000000000>] handle_mm_fault+0x648/0x10b4
[<0000000000000000>] do_page_fault+0x168/0x30c
[<0000000000000000>] do_mem_abort+0x40/0x9c
[<0000000000000000>] el1_da+0x18/0x78
[<0000000000000000>] __generic_file_write_iter+0xcc/0x16c
[<0000000000000000>] ext4_file_write_iter+0x230/0x2f4
[<0000000000000000>] fuse_passthrough_write_iter+0x68/0xec
[<0000000000000000>] fuse_file_write_iter+0x11c/0x210
[<0000000000000000>] __vfs_write+0xa0/0xd0
[<0000000000000000>] vfs_write+0xac/0x144
[<0000000000000000>] SyS_write+0x48/0x84
[<0000000000000000>] el0_svc_naked+0x24/0x28
[<0000000000000000>] 0xffffffffffffffff
# cat /proc/4226/stack
[<0000000000000000>] __switch_to+0x98/0xa4
[<0000000000000000>] request_wait_answer+0x64/0x248
[<0000000000000000>] __fuse_request_send+0x84/0x98
[<0000000000000000>] fuse_request_send+0x44/0x4c
[<0000000000000000>] fuse_simple_request+0x120/0x170
[<0000000000000000>] fuse_send_open+0x9c/0xb8
[<0000000000000000>] fuse_do_open+0x80/0x100
[<0000000000000000>] fuse_open_common+0x7c/0xb4
[<0000000000000000>] fuse_open+0x10/0x18
[<0000000000000000>] do_dentry_open+0x1d0/0x2ec
[<0000000000000000>] vfs_open+0x6c/0x78
[<0000000000000000>] path_openat+0x948/0xbd4
[<0000000000000000>] do_filp_open+0x3c/0x84
[<0000000000000000>] do_sys_open+0x164/0x1fc
[<0000000000000000>] SyS_openat+0x10/0x18
[<0000000000000000>] el0_svc_naked+0x24/0x28
[<0000000000000000>] 0xffffffffffffffff
# ps -t 2086
USER PID PPID VSIZE RSS WCHAN PC NAME
media_rw 2086 569 15460 2652 wait_woken 7fb3d1bd70 S /system/bin/sdcard
media_rw 2099 2086 15460 2652 pipe_wait 7fb3d1bd70 S sdcard
media_rw 2100 2086 15460 2652 do_truncat 7fb3d1b338 D sdcard
media_rw 2101 2086 15460 2652 fuse_dev_d 7fb3d1bd70 S sdcard
media_rw 2102 2086 15460 2652 fuse_dev_d 7fb3d1bd70 S sdcard
# cat /proc/2100/stack
[<0000000000000000>] __switch_to+0x98/0xa4
[<0000000000000000>] do_truncate+0x6c/0xa0
[<0000000000000000>] path_openat+0xa10/0xbd4
[<0000000000000000>] do_filp_open+0x3c/0x84
[<0000000000000000>] do_sys_open+0x164/0x1fc
[<0000000000000000>] SyS_openat+0x10/0x18
[<0000000000000000>] el0_svc_naked+0x24/0x28
[<0000000000000000>] 0xffffffffffffffff
问题发生时的执行流程图:
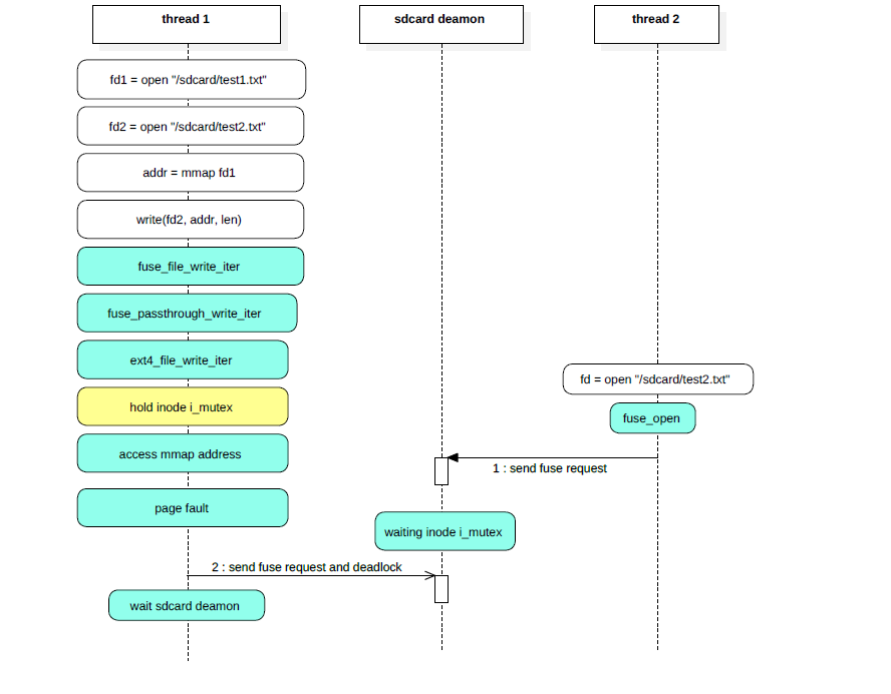
分析到这里watchdog线程为什么没有重启system_server的原因已经彻底解释清楚了,但是为什么会触发watchdog呢?
通过查看system_server中各个线程的状态,发现有多个线程处于D状态,其中就包括被watchdog监控的关键线程ActivityManager和android.display:
crash_ARM64> ps -u |grep UN
...
1873 1472 6 ffffffd75a8acb00 UN 4.2 2678340 350496 ActivityManager
1909 1472 6 ffffffd7587e1900 UN 4.2 2678340 350496 android.display
...
接着打出ActivityManager线程的调用栈:
crash_ARM64> bt 1873
PID: 1873 TASK: ffffffd75a8acb00 CPU: 6 COMMAND: "ActivityManager"
#0 [ffffffd75ca378d0] __switch_to at ffffff99a6685560
#1 [ffffffd75ca37900] __schedule at ffffff99a74df9f0
#2 [ffffffd75ca37960] schedule at ffffff99a74dfd54
#3 [ffffffd75ca37980] schedule_preempt_disabled at ffffff99a74e009c
#4 [ffffffd75ca379a0] __mutex_lock_slowpath at ffffff99a74e15d4
#5 [ffffffd75ca37a00] mutex_lock at ffffff99a74e1664
#6 [ffffffd75ca37a20] binder_alloc_new_buf at ffffff99a71b9f9c
#7 [ffffffd75ca37ab0] binder_transaction at ffffff99a71b5400
#8 [ffffffd75ca37be0] binder_thread_write at ffffff99a71b7500
#9 [ffffffd75ca37cd0] binder_ioctl_write_read at ffffff99a71b7f38
#10 [ffffffd75ca37d50] binder_ioctl at ffffff99a71b834c
#11 [ffffffd75ca37df0] do_vfs_ioctl at ffffff99a67c4820
#12 [ffffffd75ca37e80] sys_ioctl at ffffff99a67c4958
通过调用栈可以看到ActivityManager线程是在binder_alloc_new_buf函数中由于获取不到对应的mutex lock而进入D状态,所以接下来需要找出这个mutex是谁在持有,为什么没有及时释放,但是怎么找呢?
既然是执行mutex_lock时获取不到,我们就先从mutex_lock函数入手,先通过栈推导的方式找到对应的mutex地址,找到之后就可以通过查看mutex的成员owner来找到持有者:
crash_ARM64> p mutex_lock
mutex_lock = $26 =
{void (struct mutex *)} 0xffffff99a74e163c
从mutex_lock的声明中可以看到它的参数只有1个,就是struct mutex指针,接下来再看一下mutex_lock函数对应的反汇编实现:
crash_ARM64> dis mutex_lock
0xffffff99a74e163c <mutex_lock>: stp x29, x30, [sp,#-32]!
0xffffff99a74e1640 <mutex_lock+4>: mov x29, sp
0xffffff99a74e1644 <mutex_lock+8>: str x19, [sp,#16]
0xffffff99a74e1648 <mutex_lock+12>: mov x19, x0
...
0xffffff99a74e1664 <mutex_lock+40>: bl 0xffffff99a74e14ec
...
mutex_lock的第一个参数x0就是我们要找的struct mutex,在函数入口处被保存在x19寄存器中,接着调用了__mutex_lock_slowpath,x19是callee寄存器,如果在被调用函数中使用则会将其先保存到栈帧上,这里的被调用函数就是__mutex_lock_slowpath:
crash_ARM64> dis __mutex_lock_slowpath
0xffffff99a74e14ec <__mutex_lock_slowpath>: stp x29, x30, [sp,#-96]!
0xffffff99a74e14f0 <__mutex_lock_slowpath+4>: mov x29, sp
0xffffff99a74e14f4 <__mutex_lock_slowpath+8>: stp x19, x20, [sp,#16]
...
0xffffff99a74e1508 <__mutex_lock_slowpath+28>: mov x19, x0
所以我们只要在__mutex_lock_slowpath的栈帧中找到x19,就找到了mutex的地址。
通过bt 1873的输出即ActivityManager的调用栈可以知道__mutex_lock_slowpath的栈帧范围是ffffffd75ca379a0到ffffffd75ca37a00:
#4 [ffffffd75ca379a0] __mutex_lock_slowpath at ffffff99a74e15d4
#5 [ffffffd75ca37a00] mutex_lock at ffffff99a74e1664
根据反汇编的代码得出栈帧中相关寄存器的对应位置如下:
crash_ARM64> rd ffffffd75ca379a0 -e ffffffd75ca37a00
ffffffd75ca379a0: ffffffd75ca37a00 ffffff99a74e1668 .z.....h.N.....
x29 x30
ffffffd75ca379b0: ffffffd6dfa02200 ffffffd6dfa02200 ."......."......
x19 x20
...
其中x19中的值ffffffd6dfa02200就是我们要找的mutex指针,通过struct命令查看mutex指针对应的值:
crash_ARM64> struct mutex ffffffd6dfa02200
struct mutex {
count = {
counter = -4
},
...
owner = 0xffffffd65bb72580,
...
}
其中owner就是持有当前mutex的线程所对应的task_struct指针,通过task_struct指针可以找到对应的pid:
crash_ARM64> task_struct.pid 0xffffffd65bb72580
pid = 3337
查看这个pid对应的调用栈:
crash_ARM64> bt 3337
PID: 3337 TASK: ffffffd65bb72580 CPU: 0 COMMAND: "Binder:1817_18"
#0 [ffffffd66ccf7870] __switch_to at ffffff99a6685560
#1 [ffffffd66ccf78a0] __schedule at ffffff99a74df9f0
#2 [ffffffd66ccf7900] schedule at ffffff99a74dfd54
#3 [ffffffd66ccf7920] rwsem_down_write_failed at ffffff99a74e2388
#4 [ffffffd66ccf7990] down_write at ffffff99a74e1a20
#5 [ffffffd66ccf79b0] binder_update_page_range at ffffff99a71b9938
#6 [ffffffd66ccf7a20] binder_alloc_new_buf at ffffff99a71ba238
#7 [ffffffd66ccf7ab0] binder_transaction at ffffff99a71b5400
#8 [ffffffd66ccf7be0] binder_thread_write at ffffff99a71b7500
#9 [ffffffd66ccf7cd0] binder_ioctl_write_read at ffffff99a71b7f38
#10 [ffffffd66ccf7d50] binder_ioctl at ffffff99a71b834c
#11 [ffffffd66ccf7df0] do_vfs_ioctl at ffffff99a67c4820
#12 [ffffffd66ccf7e80] sys_ioctl at ffffff99a67c4958
这个线程的pid和名字都比较熟悉,在前面的分析中曾经出现过,是19个包括watchdog线程在内的等待tencent.karaoke进程mm的mmap_sem读写锁线程中的一个,至此所有问题都得到了彻底的分析和解释。
4. 问题总结
总结一下问题的死锁流程:
- tencent.karaoke进程中的线程T1打开了fuse文件F1和F2;
- 线程T1通过mmap的方式映射了fuse文件F1并得到了一个返回地址buf;
- 接着线程T1将buf写入到fuse文件F2;
- 在写入的过程中由于passthrough的优化直接向fuse文件F2对应的ext4文件进行了写入,同时持有了fuse文件F2对应的ext4文件的inode中的mutex;
- 接着tencent.karaoke进程中的线程T2向sdcard进程发送了打开fuse文件F2的请求;
- sdcard进程中的工作线程S1收到打开fuse文件F2的请求后开始处理,处理的过程中需要获取对应的ext4文件的inode中的mutex,由于此mutex已经被tencent.karaoke进程中的线程T1持有,此时获取失败并进入D状态;
- tencent.karaoke进程中的线程T1在持有mutex的情况下,写入的过程中由于buf对应的文件内容并未load到内存中而发生了pagefault;
- 在pagefault的过程中持有了tencent.karaoke进程mm的mmap_sem,接着向sdcard进程发出了fuse read的请求;
- 由于sdcard进程的工作线程S1已经被block进入D状态,fuse read的请求永远不会得到响应;
- T1线程持有了tencent.karaoke进程mm的mmap_sem和fuse文件F2对应的ext4文件的inode中的mutex,并永远等待;
- 随后system_server中的ActivityManager、android.display以及其他线程在与tencent.karaoke进程binder通信的过程中由于拿不到对应mm的mmap_sem而进入D状态,永远无法恢复;
- watchdog线程监控到ActivityManager等关键线程在1分钟内无响应,开始进入watchdog的处理并执行dumpStackTraces;
- 在执行dumpStackTraces的过程中由于需要获取指定进程的pid需要遍历proc节点,一旦遍历到tencent.karaoke进程的proc节点就需要获取对应mm的mmap_sem,由于获取不到同样进入D状态,永远无法恢复;
- 至此死锁环形成,谁也无法剥夺谁持有的资源,并且满足不了继续运行的条件,最终导致死锁;
5. 解决方案
通过初步分析、深入分析和问题总结,我们清楚的知道了问题的原因,接下来我们再分析一下如何解决这个问题:
- passthrough直接持有ext4文件对应inode的mutex的优化是正常并且通用合理的,不能调整;
- 访问mmap对应的buf触发pagefault并持有mm的mmap_sem的流程也是正常的,不能调整;
- 在持有ext4文件对应inode的mutex前先访问buf并执行pagefault的流程;
- pagefault流程正常执行,fuse的read请求正常发送,sdcard进程的open和read正常处理,watchdog不会被触发,系统不会冻屏;
- 所有逻辑都恢复正常,死锁环被断开;
修复的关键代码如下:
/* kernel/msm-4.4/fs/fuse/file.c */
static ssize_t fuse_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
...
if (ff && ff->passthrough_enabled && ff->passthrough_filp) {
+ size_t bytes = iov_iter_count(from);
+ /*
+ * page fault before fuse_passthrough_write_iter.
+ * Otherwise there is a deadlock to send a fuse req to fuse deamon.
+ * as it hold the inode->i_mutex
+ */
+ iov_iter_fault_in_multipages_readable(from, bytes);
written = fuse_passthrough_write_iter(iocb, from);
goto out;
}
...
6. 实战心得
- 对于系统优化要全面考虑,避免1+1<1的情况;
- 持锁期间要清楚的知道会发生什么样的事情,会走什么样的分支,避免意外流程导致死锁;
- 临界区尽量小,做的事情和分支尽量少;
最后
以上就是结实烧鹅最近收集整理的关于Fuse内核死锁导致的Android系统死机问题分析的全部内容,更多相关Fuse内核死锁导致内容请搜索靠谱客的其他文章。








发表评论 取消回复