CVPR 2017
Semantic Compositional Networks(SCN)有效的组合各个标签,来生成描述图像整体意义的描述。《Semantic Compositional Networks for Visual Captioning》也是CNN-LSTM结构,但SCA扩展传统LSTM的每个权重矩阵为依赖于标签的权重矩阵的集成,这取决于标签存在于图像中的概率。
给定图片I,描述![]() ,其中
,其中![]() 是热独编码,词汇表大小为V,视觉特征为
是热独编码,词汇表大小为V,视觉特征为![]() 。第t个描述单词
。第t个描述单词![]() 被线性嵌入为
被线性嵌入为![]() 维的实值向量
维的实值向量![]() ,
,![]() 是需要学习的词嵌入向量。给定图像特征
是需要学习的词嵌入向量。给定图像特征![]() ,描述X的概率为:
,描述X的概率为:
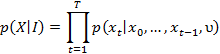
每个条件![]() 被指定为softmax(Vht),其中
被指定为softmax(Vht),其中![]() 通过
通过![]() 递归更新,
递归更新,![]() 被指定为零向量。对于带有简单转换函数的RNN,
被指定为零向量。对于带有简单转换函数的RNN,![]() 定义为:
定义为:
![]()
其中,1表示只是函数,特征向量只在开始时被馈送给RNN,W定义为输入矩阵,U为递归矩阵。
SCN扩展卷积RNN的每个权重矩阵为一组依赖于标签的权重矩阵的一个集成,与标签存在于图像中的概率相关。SCN-RNN计算![]() 为:
为:
![]()
其中,![]() ,
,![]() 与
与![]() 是根据语义概念向量s,依赖标签的权重矩阵集成。
是根据语义概念向量s,依赖标签的权重矩阵集成。
给定![]() ,定义两个权重张量
,定义两个权重张量![]() ,
, ![]() ,
, ![]() ,
,![]() ,则
,则
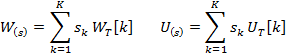
其中,![]() 是s中第k个元素,
是s中第k个元素,![]() 、
、![]() 是
是![]() 、
、![]() 的二维切片。
的二维切片。
该方法参数的数量与K成正比,对比较大的K难以实现,因此作者因式分解![]() 和
和![]() :
:
![]()
![]()
其中,![]() ,
,![]() ,
,![]() ,
, ![]() ,
,![]() ,
,![]() ,
, ![]() 是因子数量。将上式代入,则用RNN获得SCN:
是因子数量。将上式代入,则用RNN获得SCN:
![]()
![]()
![]()
![]()
其中,![]() 表示基于元素的相乘,
表示基于元素的相乘,![]() 、
、![]() 在所有描述上共享,有效的捕获常见的语言模式。
在所有描述上共享,有效的捕获常见的语言模式。
使用LSTM单元归纳SCN-RNN,定义![]() 为:
为:
![]()
![]()
![]()
![]()
![]()
![]()
对于*=I,f,o,c,定义:
![]()
![]()
最终目标函数为:
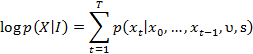
最后
以上就是忧伤戒指最近收集整理的关于《Semantic Compositional Networks for Visual Captioning》论文笔记的全部内容,更多相关《Semantic内容请搜索靠谱客的其他文章。








发表评论 取消回复