准备开始读一下Image Caption,先记录一下对论文的理解,一些公式没有记录下来,在论文中可查。
目录
1.Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
1. Introduction
2.RNN Encoder-Decoder
3.Statistical Machine Translation
4.Experiments
2.Show and Tell: A Neural Image Caption Generator
1.Introduction
2.Related Work
3.Model
4.Experiments
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
1.Introduction
3.Image Caption Generation with Attention Mechanism
1.Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
1. Introduction
本文提出了RNN Encoder-Decoder模型,其中包括两个RNN模型,一个encode句子为固定长度的向量表达,一个将表达解码为变长的句子。另外我们用一个隐藏的单元去增加模型的记忆力及减少训练的难度。
最后我们通过实验得出结论,Encoder-Decoder模型擅长于找到语法规律,并且他可以学到连续的语义和语法表达信息。
2.RNN Encoder-Decoder
首先介绍了RNN网络的结构,,其中f是非线性激活函数,x为输入,h为隐藏单元。RNN可以通过预测下个句子的训练,学习到序列的分布规律。
接下来说RNN Encoder-Decoder结构。在这篇文章中,我们提出了一个新的神经网络结构,它可以将变长的序列编码成定长的向量表达,并将定长的向量表达重新解码成变长的序列。
Encoder编码器是一个RNN结构,他逐个读取输入序列,此时RNN的隐藏单元层根据
变化。当读完一个句子,这个隐藏单元是整个输入句子的summary
。
Decoder解码器是另一个被提出的RNN,他通过给定的去预测下一个单元
并生成输出。此时的
和
都以
和
为条件的。所以,dcoder的隐藏单元及时间
是这么计算的
,同样,下一个单元的条件分布为
。
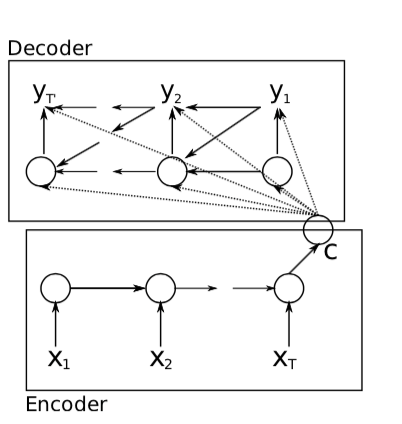
这两个部分共同去训练,使得条件似然最大。
训练好的模型可以用在两种途径,一种是给定一个输入句子去生成一个输出序列, 一种是给定一个输入输出序列从而给出评分,这个评分是一个概率。
在这里提出了一个记忆门单元,是由LSTM启发, 但是计算和应用更简单,分为reset gate和update gate。The update gate z去选择隐藏单元是否用一个新的隐藏状态更新。另外update gate控制着前面隐藏单元传递多少信息,这一点和LSTM很像,他控制着RNN有长期记忆。
每个隐藏单元有分开的reset和update门,因此每个隐藏单元会学习不同时间尺度的东西。那些short-term的单元会有更多活跃的reset门,而long-term的单元会有更多活跃的update门。
3.Statistical Machine Translation
在这里我们提出用一张相位对的表去训练Encoder-Decoder模型。当训练的时候,我们忽略样本出现的次数。
4.Experiments
本文用到的RNN Encoder-Decoder有1000个隐藏单元,BLEU为平均指标。
2.Show and Tell: A Neural Image Caption Generator
1.Introduction
本文用深度卷积神经网络(CNN)去代替RNN编码器。实验证明,CNN可以通过将输入图像分词成固定长度的向量从而产生更多的语义信息。首先,通过分类任务与训练一个CNN模型,用最后的隐藏层作为输入输入到RNN decoder中从而生成句子。我们叫这个模型为Neural Image Caption(NIC)。
本文的贡献为:
- 提出一个端到端的系统,用SGD的方法训练一个神经网络
- 模型融合了vision和language的state-of-art的模型,模型可以现在一个大的集合里预训练,然后可以利用多余的数据
- 这么模型最终显示出很好的结果
2.Related Work
生成自然语言描述的这个问题在cv领域发展已经很久了,但通常用于视频。这些系统一般很复杂。
而关于图像的自然文字描述是最近流行的事情。在这篇论文里,我们将图像检测的深度卷积网络和序列模型的recurrent networks结合起来,RNN由基于内容的单端对端网络训练而成,这个模型是由在机器翻译中的序列生成模型启发的,区别是不使用一个句子开始,而是用卷积网络处理图像开始。对比其他的work,我们用看一个非常强壮的RNN模型,我们直接把图像输入到RNN中,这使得RNN可以直接追踪文字描述的物体。我们的work取得了非常好的结果。最近Unifying visual-semantic embeddings with multimodal neural lan- guage models.提出了多模态模型,他们用了两个pathwa,一个用作图片一个用作文本。
3.Model
在本文中,我们提出了一个神经网络及改了结合的框架去生成图片的描述。最近的Statistical Machine Translation(SMT)表明,给定一个序列模型,用端到端的模型直接直接最大化正确翻译的概率去达到state-of-art的效果是可行的。这些模型利用RNN编码,将变长的输入encode成一个固定长的多位向量,再进行解码。因此,很自然可以想到输入一张图片(代替输入句子),然后将它“翻译”为它的描述。
是模型的参数,
是一张图,
是其正确的描述。因为
代表很多句子且长度不固定,因此可以将其写成链式
memory 是用一个非线性函数
更新的,
为了做出上述的RNN,有两个重要的选择,的形式是什么及如何将图片和文字作为
输入。对于
,我们使用LSTM网络;对于图像的表达我们用CNN,文字我们用词嵌入表达。
LSTM-based Sentence Generator
LSTM的核心是记忆细胞,这个细胞被三个门控制,
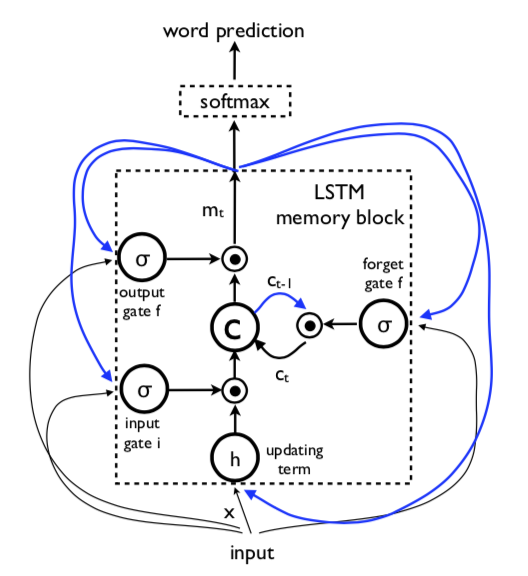
Training
LSTM模型用来预测句子中的每个词,在通过见过图片和输入词之后。所有的LSTM共享同样的参数。上一课的输出
输给
时刻的LSTM。展开的进程如下:
我们将每个词做成one-hot编码的集合,其维度和字典的大小一样。我们设置
的开始词和
的特殊停止词,表示出句子的开头和结尾。图片用CNN空间,词用词向量
,图像
只在t-1时间输入一次。我们测试过如果每个时间都输入图像的话,会造成噪声和过拟合。我们的loss是
。
这边有两种方法根据图片得到句子,一种是采样,一种是网格搜索。
4.Experiments
最主要的问题的是过拟合,但我们有几种防止过拟合的方法,一种是初始化CNN单元的权重,通过与训练模型(比如在ImageNet上的预训练模型)。而词向量模型我们没有初始化,但是我们有一些避免过拟合的技巧,我们用了dropout和模型融合。
我们用SGD及固定的学习率并且不加入动量,我们用512维的LSTM的memory和embeddings。
我们用MSCOCO测试。
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
收到机器翻译和目标检测的启发,介绍一种基于模型的attention方法,可以自动学习描述图像的内容。测试数据集为Flickr8k,Flickr30k and MSCOCO。
1.Introduction
相对于将整张图片压缩成一句静态的表述,attention机制与许静态的特征动态的放到前端。当一张图非常混乱的时候,这是非常重要的方法。在本文提出了hard attention机制和soft attention。

3.Image Caption Generation with Attention Mechanism
Encoder:convolutional features
Decoder:LSTM
最后
以上就是标致小伙最近收集整理的关于Image Caption(一) 论文及理解的全部内容,更多相关Image内容请搜索靠谱客的其他文章。


![UC Berkeley CS 61A (2022 Fall) Lecture 3 Control [Notes]Print and NoneMiscellaneous Python FeaturesConditional Statements](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)





发表评论 取消回复