文章目录
- 一、目标检测综述
- 1.1 目标检测应用场景和挑战
- 1.2 目标检测算法基础知识
- 1.2.1 目标检测算法简介
- 1.2.2 Anchor和Anchor-Based
- 1.2.3 Anchor-Free方法(课6)
- 1.3 目标检测数据集
- 1.3.1 PASCAL VOC2012数据集
- 1.3.2 标注自己的PASCALVOC格式数据集
- 1.3.3 COCO数据集介绍以及pycocotools简单使用
- 1.3.3.1 coco数据集简介
- 1.3.3.2 coco数据集结构和目标检测标注信息
- 1.3.3.3 使用pycocotools读取coco
- 1.4 目标检测基础概念、评价指标
- 1.5 作业一:PaddleDetection快速上手
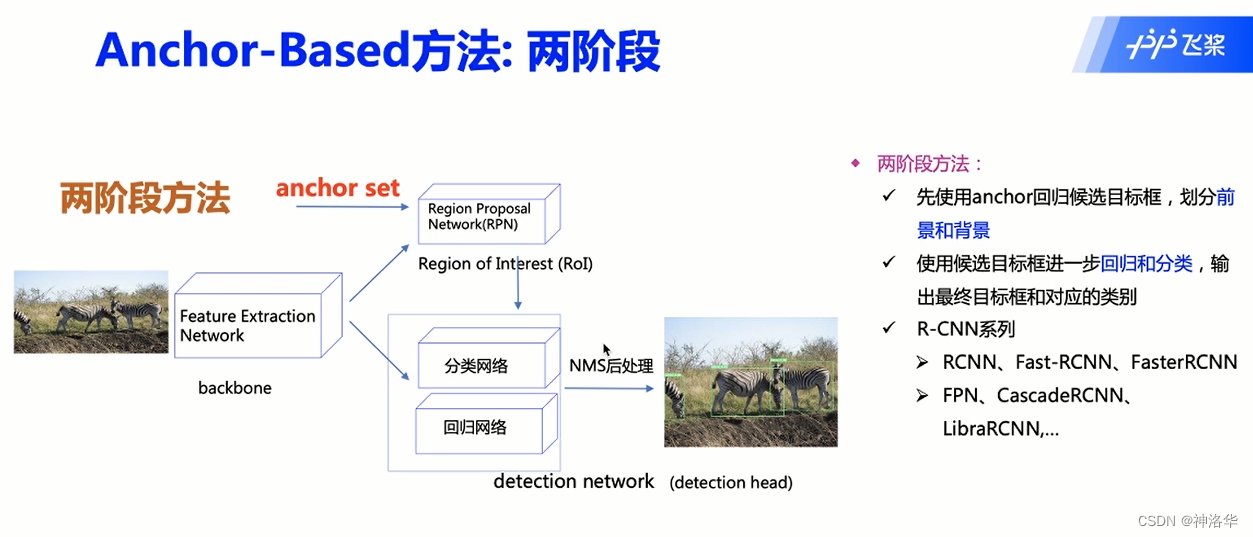
- 二、RCNN系列目标检测算法详解
- 2.1 两阶段检测算法发展历程
- 2.2 R-CNN
- 2.3 Fast R-CNN
- 2.3.1 Fast R-CNN框架和原理
- 2.3.2 Fast R-CNN正负样本匹配
- 2.3.3 `RoI pooling`
- 2.3.4 网络预测
- 2.3.4.1 分类器
- 2.3.4.2 边界框回归器
- 2.3.5 Fast R-CNN损失计算
- 2.3.6 Fast R-CNN总结
- 2.4 Faster R-CNN
- 2.4.1 Faster R-CNN网络结构
- 2.4.2 RPN
- 2.4.2.1 RPN网络结构
- 2.4.2.2 RPN网络的正负样本采样
- 2.4.2.3 RPN网络loss
- 2.4.3 Faster R-CNN损失计算
- 2.4.4 Fast R-CNN联合训练
- 2.4.5 R-CNN系列模型框架对比
- 2.5 Pytorch Faster R-CNN源码解析
- 2.6 PaddleDetection Faster R-CNN
- 2.6.1 生成proposals
- 2.6.2 RoI Align
- 2.6.3 BBox Head检测头
- 2.6.4 PaddleDetection模型库和基线
- 2.7 PaddleDetection快速上手项目对照讲解
- 2.8 作业二:印刷电路板(PCB)瑕疵检测
- 三、两阶段目标检测进阶算法
- 3.1 FPN多尺度检测
- 3.1.1 FPN结构和原理
- 3.1.2 FPN在Faster-RCNN中的实现
- 3.1.3 FPN的继续优化
- 3.2 Cascade RCNN(三个检测头级联调优)
- 3.2.1 RPN生成的Rol和真实框的loU阈值分析
- 3.3 Libra R-CNN
- 3.3.1 LibraR-CNN的特征融合
- 3.3.2 LibraR-CNN的采样策略
- 3.3.3 LibraR-CNN的回归损失函数
- 3.4 PaddleDetection两阶段检测模型优化策略
- 3.4.1 服务器端优化策略
- 3.4.2 移动端优化
- 3.5 工业应用:铝压铸件质检
全文参考:
- AI Studio课程目标检测7日打卡营
- 太阳花的小绿豆B站讲解视频《Faster RCNN理论合集》、github Faster R-CNN项目
一、目标检测综述
参考《目标检测综述》
1.1 目标检测应用场景和挑战

1.2 目标检测算法基础知识
1.2.1 目标检测算法简介
参考《小白学CV:目标检测任务和模型介绍》
目标检测介绍
目标检测或目标识别(object recognition)是计算机视觉领域中最基础且最具挑战性的任务之一,其包含物体分类和定位。为实例分割、图像捕获、视频跟踪等任务提供了强有力的特征分类基础。
目标检测模型
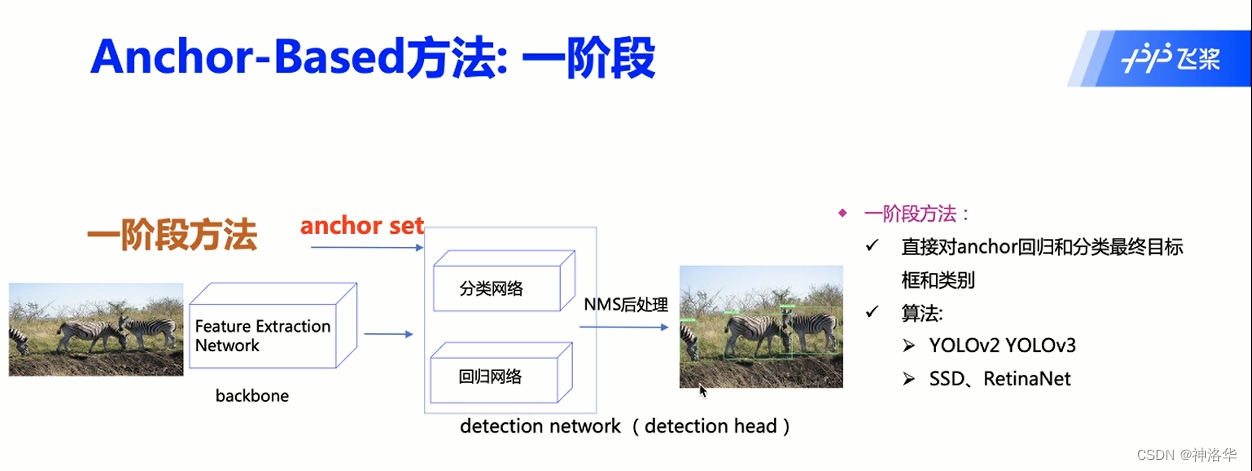
深度学习目标检测方法分为分为Anchor-Based(锚框法)和Anchor-Free(无锚框)两大类,根据有无区域提案阶段划分为双阶段模型和单阶段检测模型。
- 双阶段模型:将目标检测任务分为区域提案生成、特征提取和分类预测三个阶段。
- 区域提案生成阶段,检测模型利用搜索算法如选择性搜索(SelectiveSearch,SS)、EdgeBoxes、区 域 提 案 网 络(Region Proposal Network,RPN) 等在图像中搜寻可能包含物体的区域。
- 特征提取阶段,模型利用深度卷积网络提取区域提案中的目标特征。
- 分类预测阶段,模型从预定义的类别标签对区域提案进行分类和边框信息预测。
- 单阶段模型:单阶段检测模型联合区域提案和分类预测,输入整张图像到卷积神经网络中提取特征,最后直接输出目标类别和边框位置信息。这类代表性的方法有:YOLO、SSD和CenterNet等。

目标检测数据集
目前主流的通用目标检测数据集有PASCAL VOC、ImageNet、MS COCO、Open Images和Objects365。
目标检测研究方向
目标检测方法可分为检测部件、数据增强、优化方法和学习策略四个方面 。其中检测部件包含基准模型和基准网络;数据增强包含几何变换、光学变换等;优化方法包含特征图、上下文模型、边框优化、区域提案方法、类别不平衡和训练策略六个方面,学习策略涵盖监督学习、弱监督学习和无监督学习。

边界框(bounding box)
- 图片分类一般默认图片中只有一个主体,而目标检测任务中,图片通常含有多个主体。不仅想知道它们的类别,还想得到它们在图像中的具体位置。
- 在目标检测中,我们通常使用边界框(bounding box)来描述对象的空间位置。边界框是矩形的,表示方式有三种:
- (左上x,左上y,右下x,右下y)
- (左上x,左上y,宽,高)
- (中心x,中心y,宽,高)
- 目标检测数据集的常见表示:每一行表示一个物体,对于每一个物体而言,用“图片文件名,物体类别,边缘框”表示,由于边缘框用4个数值表示,因此对于每一行的那一个物体而言,需要用6个数值表示。
- 目标检测领域常用数据集:COCO(80类物体,330K图片,所有图片共标注1.5M物体)
1.2.2 Anchor和Anchor-Based
Anchor(锚框):在特征图(Feature Map)上,每个点以滑动窗口方式选择不同形状大小的窗口,即为锚框。
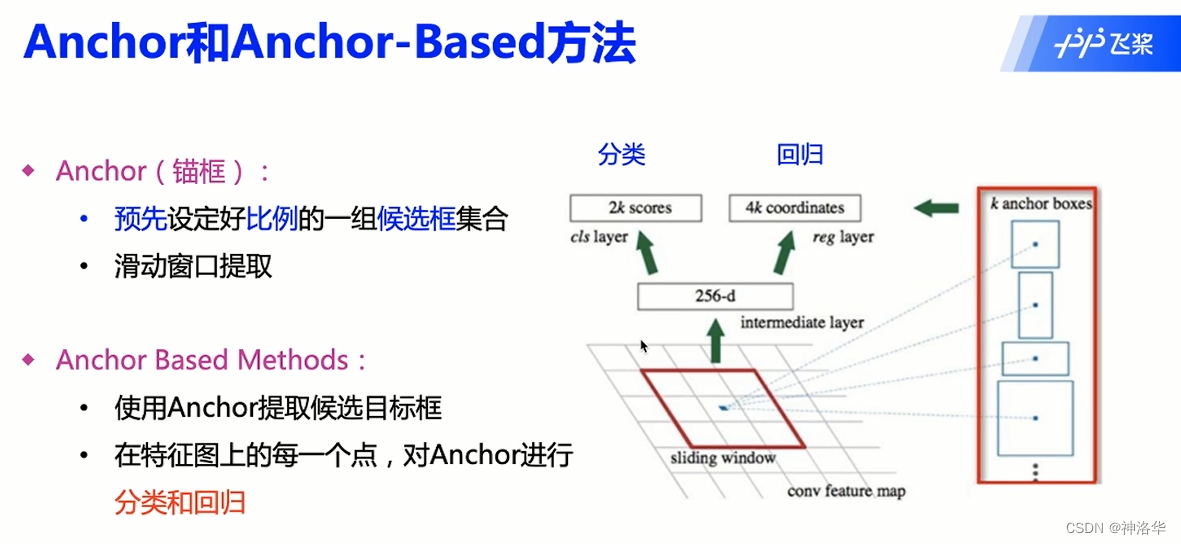
Anchor(锚框)方法缺点:
- Anchor需要设计( Anchor设置多少个?面积多大?长宽比如何?)
- Anchor数过多。整张图 Anchor数量很多,大量是负样本,如何解决正负样本数不平衡?
- 超参数很多,模型学习困难。如何设置超参数?
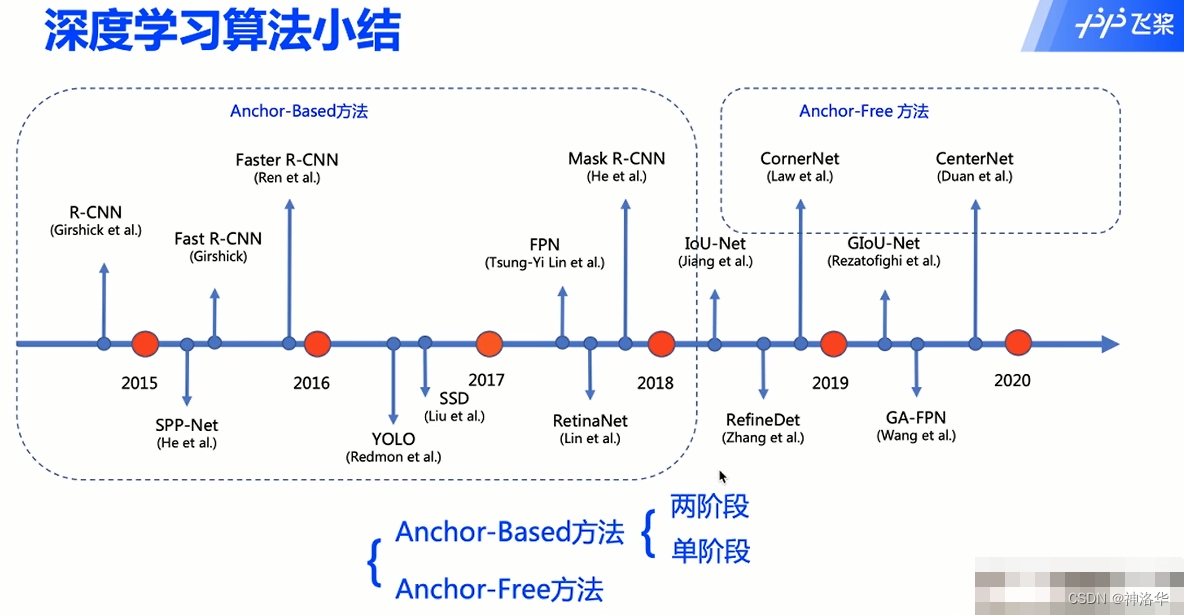
1.2.3 Anchor-Free方法(课6)
Anchor-Free方法有两类:
- 基于多关键点联合表达,比如先预测左上角、右下角,通过角点形成检测框
- 基于中心区域预测

1.3 目标检测数据集
1.3.1 PASCAL VOC2012数据集
参考博客《PASCAL VOC2012数据集介绍》、视频、官方发表关于介绍数据集的文章 《The PASCALVisual Object Classes Challenge: A Retrospective》、PASCAL VOC2012数据集地址
目前主流的通用目标检测数据集有PASCAL VOC、ImageNet、MS COCO、Open Images和Objects365。本节讲一下PASCAL VOC2012数据集。
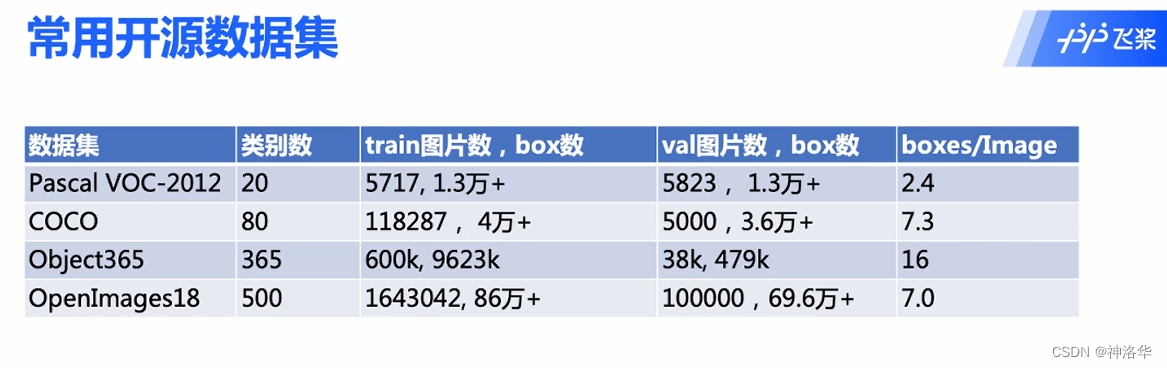
PASCALVOC挑战赛(The PASCAL Visual Object Classes)是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis,Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。
PASCALVOC挑战赛主要包括以下几类:图像分类(Object Classification)、自标检测(Object Detection),目标分割(Object Segmentation,动作识别(Action Classification,预测一个人在静止图像中执行的动作)、人体识别(Person Layout,预测人的每个部分(头、手、脚)的边界框和标签)等。

打开其官网地址,在Development Kit目录下就可以下载了。详细内容参考使用文档
PASCALVOC分类和检测任务分为四个大类,20个小类。
PASCALVOC 2012数据集文件结构:
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)
目标检测中,对于每个对象,都存在以下注释:
class:目标的类别bounding box:边界框。view:视图。“正面”、“后”、“左”或“右”。这些视图被主观地标记以指示对象“大部分”的视图。某些对象没有指定视图。truncated:表示检测对象是否被截断。例如腰部以上的人的图像,图片边缘的目标等等,不是目标的完整部分。occluded:表示边界框内的对象的重要部分被另一个对象遮挡。difficult:表示该对象被认为难以识别,例如,在没有大量使用上下文的情况下清晰可见但无法识别的对象。标记为difficult的对象目前在挑战评估中被忽略。
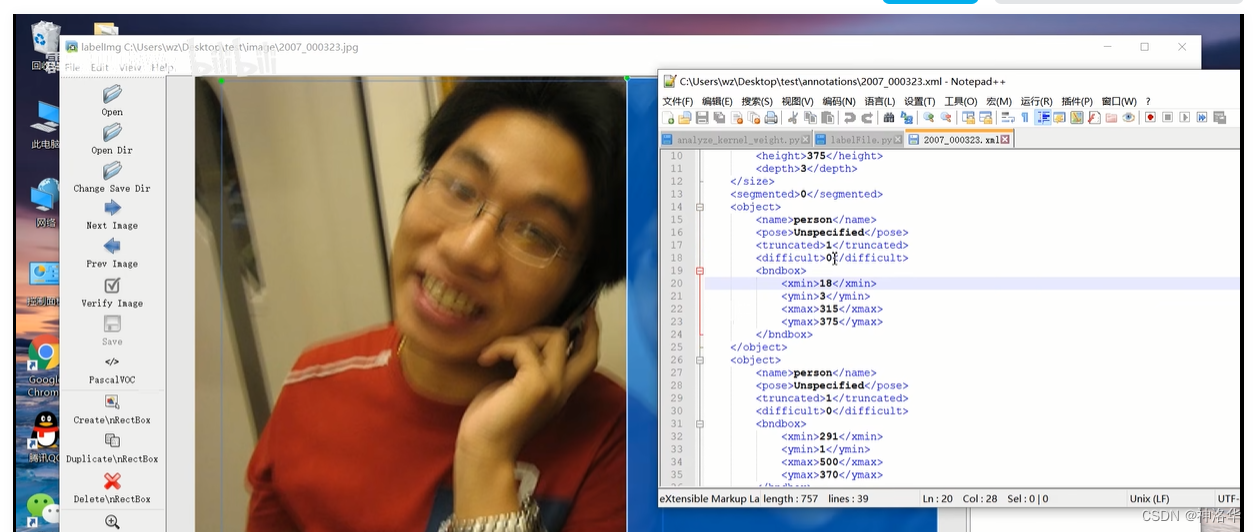
具体的,打开一个VOC2012/Annotations/2007_000033.xml标注信息文件看看:
<annotation>
<folder>VOC2012</folder> #文件夹名
<filename>2007_000033.jpg</filename> #文件名
<source> #数据来源
<database>The VOC2007 Database</database> #来自VOC2007数据集
<annotation>PASCAL VOC2007</annotation> #标注信息来自VOC2007数据集
<image>flickr</image> #来自网络分享
</source>
<size>
<width>500</width>
<height>366</height>
<depth>3</depth>
</size>
<segmented>1</segmented> #此图片是否被分割过
<object> #代表目标检测属性
<name>aeroplane</name> #目标类别
<pose>Unspecified</pose> #pose用不到
<truncated>0</truncated> #是否被截断
<difficult>0</difficult> #是否为困难目标
<bndbox> #真实框左上/右下坐标
<xmin>9</xmin>
<ymin>107</ymin>
<xmax>499</xmax>
<ymax>263</ymax>
</bndbox>
</object>
<object>
<name>aeroplane</name>
<pose>Left</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>421</xmin>
<ymin>200</ymin>
<xmax>482</xmax>
<ymax>226</ymax>
</bndbox>
</object>
<object>
<name>aeroplane</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>325</xmin>
<ymin>188</ymin>
<xmax>411</xmax>
<ymax>223</ymax>
</bndbox>
</object>
</annotation>
VOC2012/ImageSets/Main文件夹下包含目标检测任务的各个类别的训练验证集txt文件和总的训练验证集txt文件。VOC2012测试集是没有公开的,要提交成绩的话,应该使用trainval中包含的图片训练网络,在官网下载验证软件来使用VOC2012测试集测试。或者使用VOC2007测试集(已公开)测试。
txt文件中每一行是一个图片名。在各个类别的txt文件中,比如boat_train.txt,显示
2008_000189 -1
2008_000191 0 #困难样本,这张图片中的目标检测起来有困难
......
2008_004920 1 #正样本,这张图片中有船这个目标
2008_004931 -1 #负样本

1.3.2 标注自己的PASCALVOC格式数据集
github上有很多目标检测标注软件,比如https://github.com/heartexlabs/labelImg项目。LabelImg标注工具可生成xml标注文件(ImageNet使用的PASCAL VOC 格式)。此外,它还支持 YOLO 和 CreateML 格式。
安装方式有源码创建(可以看到作者的源代码,可以在此基础上进行编辑,新增功能等等)或者 Anaconda安装。
简单使用流程:
- 准备关于类别的文件信息:打开项目文件夹->data->predefined_classes.txt修改标注类别信息
- 设置图像文件所在目录(比如./image),以及标注文件保存目录(比如./annotation)。
- 打开软件:在当前文件夹路径栏输入powershell,打开powershell,切换为当前文件夹路径。输入
labelimg ./image ./classes.txt即可打开软件。 - 点击
'Create RectBox'标注图像,点击Save保存标注文件。 - 若要修改源代码在项目的libs->labelFile.py文件中修改
- 将刚刚标注的image文件和annotation文件放到下面annotation和JPEGImages文件夹下
- 生成对应train.txt,val.txt,trainval.txt文件。
- 像PASCALVOC数据集一样训练
或者是文件夹保持不变,以后编写自定义的数据读取函数来读取。

1.3.3 COCO数据集介绍以及pycocotools简单使用
coco官网地址、关于数据集的详细了解可以查看coco论文
参考博客《MS COCO数据集介绍以及pycocotools简单使用》、视频
训练COCO2017数据集相关代码可在train_coco_dataset中查看。
1.3.3.1 coco数据集简介
coco简介

- 目标级分割:上图d所示,将每一个目标实例单独划分出来。
- stuff类别:没有明确边界的材料和对象,比如天空。做图像风格或者Mask-RCNN会用到stuff 91类。一般目标检测用object 80类。

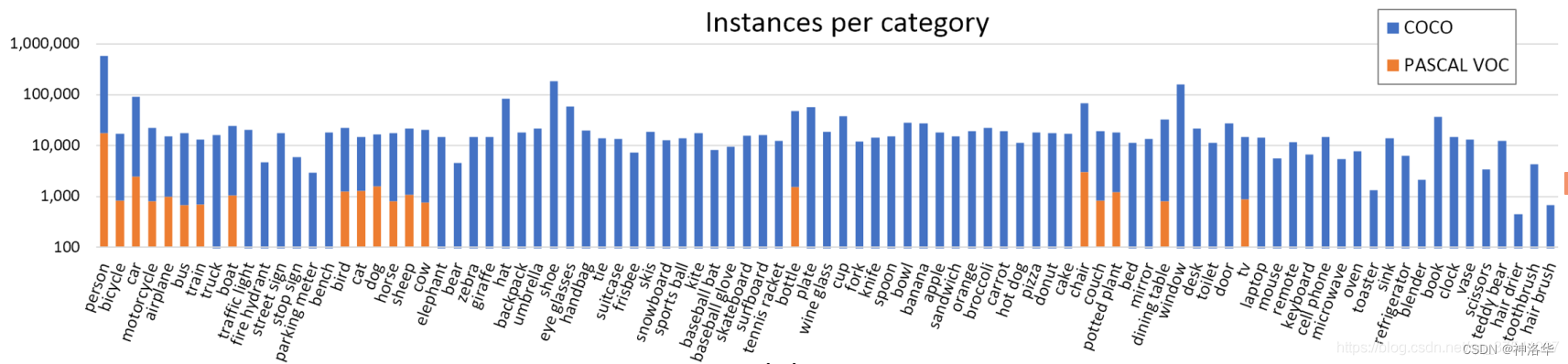
简单与PASCAL VOC数据集进行对比。下图是官方介绍论文中统计的对比图。通过对比很明显,coco数据集不仅标注的类别更多,每个类别标注的目标也更多。。一般想训练自己的数据集的话,可以先使用基于coco数据集的预训练权重,再在自己的数据集上微调。虽然coco数据集上预训练训练效果更好,但是更费时。比如使用Faster-CNN(backbone为VGG网络)模型,在coco2017训练集上使用8卡进行混合精度训练,训练26个epoch耗时6小时左右。
coco下载
coco数据集可以在官网最上方dataset→downlaod下载。
1.3.3.2 coco数据集结构和目标检测标注信息
下载后都解压到coco2017目录下,可以得到如下目录结构:
├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件。下面四个文件目标检任务测用不到
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
Tips:如果仅仅针对目标检测Object 80类而言,有些图片是空的,没有标注信息,或者标注信息是错的。这样训练之前要筛选掉有问题的数据。 否则可能出现目标边界框损失为nan的情况(标注框的宽高为0)。
MS COCO标注文件格式说明,可以通过此处文档查看。对着官方给的说明,我们可以自己用Python的json库自己读取看下,下面以读取instances_val2017.json为例:
import json
json_path = "/data/coco2017/annotations/instances_val2017.json"
json_labels = json.load(open(json_path, "r"))
print(json_labels["info"])
单步调试可以看到读入进来后是个字典的形式,包括了info、licenses、images、annotations以及categories信息:
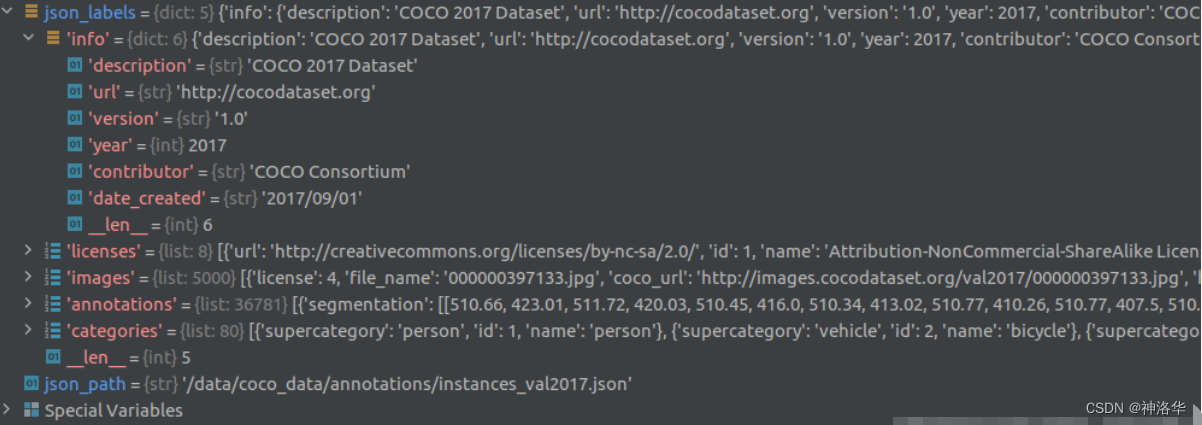
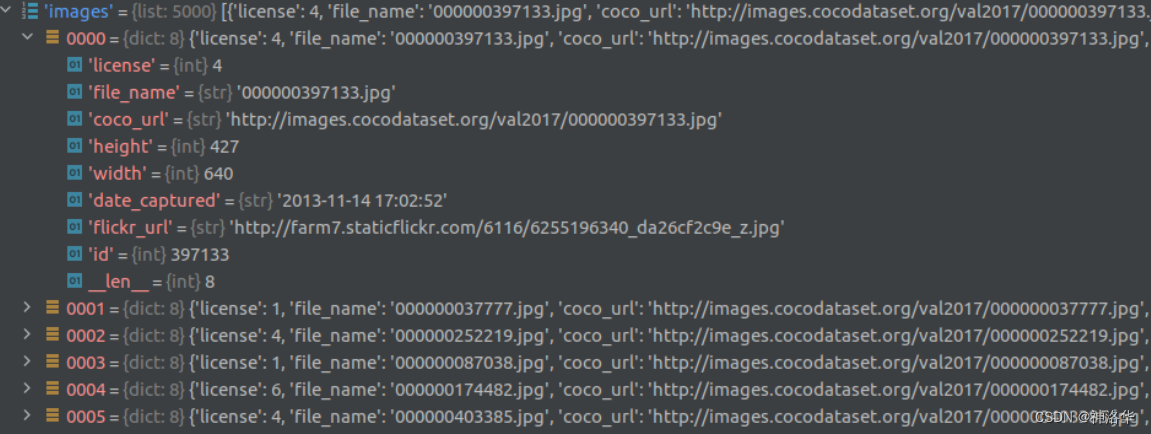
images是一个列表(5000个元素对应5000张图像),列表中每个元素都是一个dict,对应一张图片的相关信息。包括对应图像名称、url地址、图像宽度、高度、拍摄时间、分享地址、id等信息。
annotations是一个列表(36781个元素,对应数据集中所有标注的目标个数,而不是图像的张数),列表中每个元素都是一个dict对应一个目标的标注信息。包括目标的分割信息(polygons多边形)、目标边界框信息[x,y,width,height](左上角x,y坐标,以及宽高)、目标面积、对应图像id以及类别id等。iscrowd参数只有0或1两种情况,0代表单个对象,1代表对象集合(比如互相重叠的小目标认为是一个目标)。类别id也是stuff91下的类别索引,训练时一般只考虑iscrowd=0的情况。
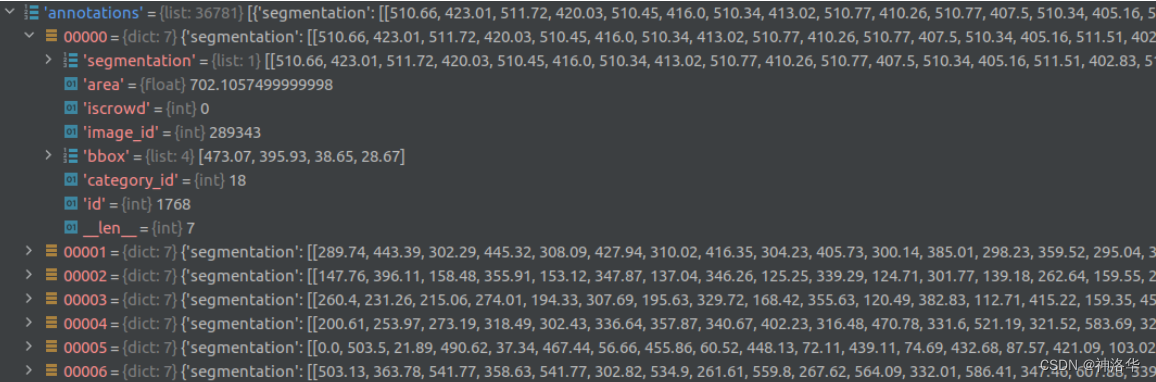
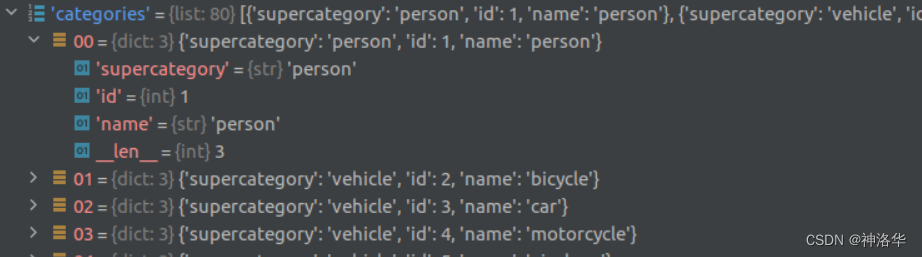
categories是一个列表(80个元素对应80类检测目标)列表中每个元素都是一个dict对应一个类别的目标信息。包括类别id、类别名称和所属超类(一些类别的统称)。类别id也是stuff91下的类别索引,所以只下载object 80时会发现有些索引没有,训练时需要将索引映射到1-80。
1.3.3.3 使用pycocotools读取coco
官方有给出一个读取MS COCO数据集信息的API:pycocotools。安装如下:
pip install pycocotools #Linux系统安装
pip install pycocotools-windows #windows系统安装
下面是使用pycocotools读取图像以及对应bbox信息的简单示例:
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "/data/coco2017/annotations/instances_val2017.json" #标签文件
img_path = "/data/coco2017/val2017"
# 载入coco标签文件
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys())) #标签文件所有图片索引
print("number of images: {}".format(len(ids))) #打印所有图片数量
# 遍历图片索引及对应的类别名称,转为字典类型
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有目标的annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# 获取图片名
path = coco.loadImgs(img_id)[0]['file_name'] #获取图片当中的第一个元素(图片信息)的图片名
# 读取图片
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# draw box to image
for target in targets:
x, y, w, h = target["bbox"]
x1, y1, x2, y2 = x, y, int(x + w), int(y + h)
draw.rectangle((x1, y1, x2, y2))
draw.text((x1, y1), coco_classes[target["category_id"]])
# 打印图片
plt.imshow(img)
plt.show()
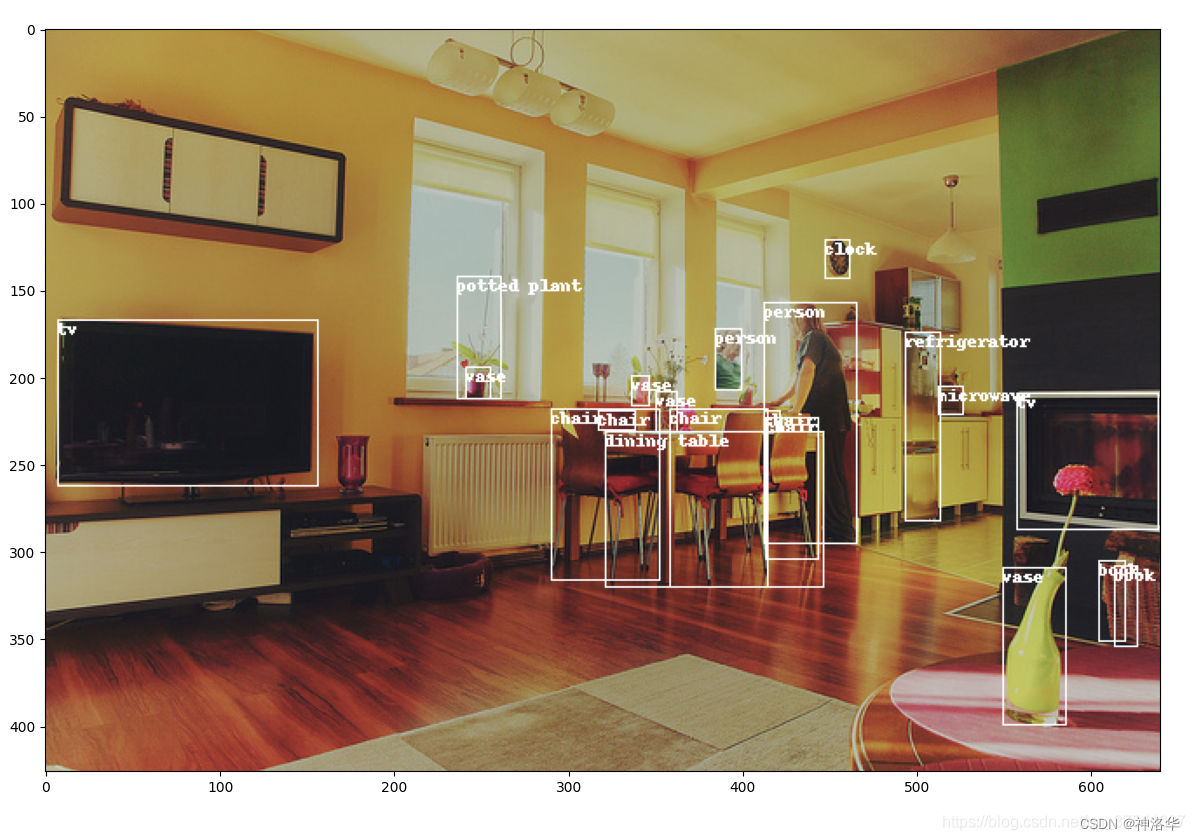
读取每张图像的segmentation信息、验证mAP请参考博客《MS COCO数据集介绍以及pycocotools简单使用》。
1.4 目标检测基础概念、评价指标
可参考《动手深度学习13:计算机视觉——目标检测:锚框算法原理与实现、SSD、R-CNN》
-
BBox、Anchor

-
RoI、Region Proposal、RPN、IoU

交并比(IoU):对于两个边界框,我们通常将它们的杰卡德系数(Jaccard 系数)称为交并比。给定集A和B, J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ . J(mathcal{A},mathcal{B}) = frac{left|mathcal{A} cap mathcal{B}right|}{left| mathcal{A} cup mathcal{B}right|}. J(A,B)=∣A∪B∣∣A∩B∣. -
目标检测评价指标:Precision、Recall 、AP、mAP
可参考《学习笔记1:线性回归和逻辑回归、AUC》
当前用于评估检测模型的性能指标主要有帧率每秒(Frames Per Second,FPS)、准确率(accuracy)、精确率(precision)、召回率(recall)、平均精度(Average Precision,AP)、平均 精度均值(mean Average Precision,mAP)等。
- FPS:即每秒识别图像的数量,用于评估目标检测模型的检测速度;
- P-R曲线:以Recall、Precision为横纵坐标的曲线
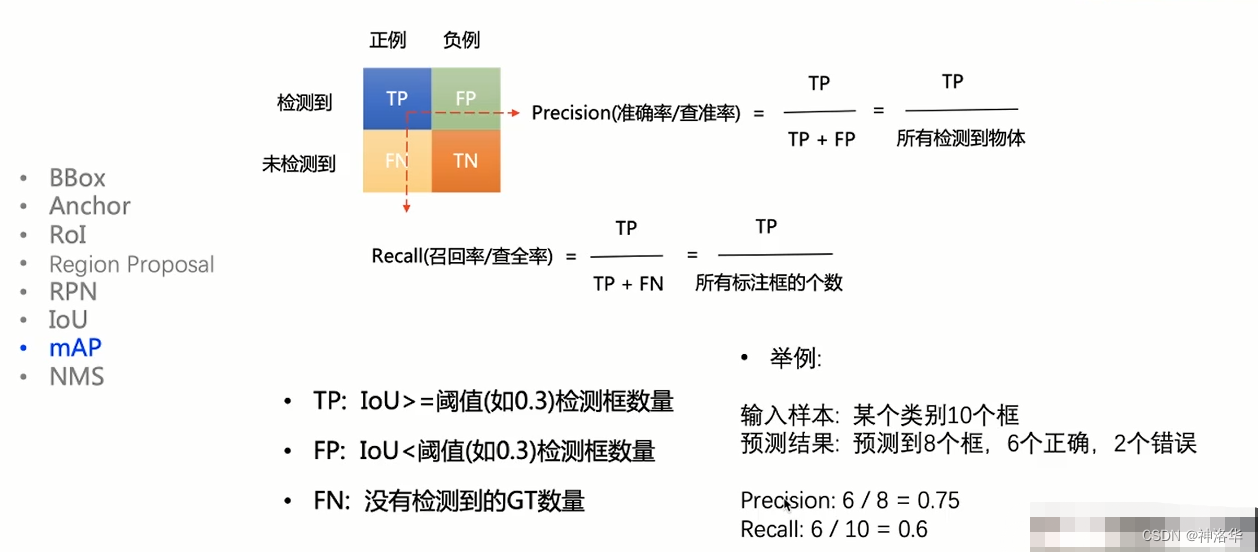
如下图所示,当检测框和标注框/真实框(GT)的IoU>设定阈值(比如0.3)时,可以认为这个检测框正确检测出物体。IoU>=阈值的检测框的数量就是TP。
- P-R曲线:以Recall、Precision为横纵坐标的曲线
- AP(Average Precision):对不同召回率点上的精确率进行平均,在PR曲线图上表现为某一类别的 PR 曲线下的面积;
- mAP(mean Average Precision):所有类别AP的均值
如下图所示,当检测框和标注框的IoU>设定阈值(比如0.3)时,可以认为这个检测框正确检测出物体。IoU>=阈值的检测框的数量就是TP。
- mAP举例说明
参考资料:https://cocodataset.org/#detection-eval
在coco评价指标中,我们经常看到这样的评测结果:

下面以实例来简单说明:

- 假设对以上三张图片的目标检测结果做评测(只检测图片中猫这个物体)。GT ID是图片中真实框的ID,预测框以Confidence(置信度)降序排列。OB表示以IOU=0.5来判断是否检测到物体。
- 下面依次取confidence阈值为[0.98,0.89.0.88,0.78,0.66,0.61,0.52],来判断是否正确匹配到物体,并计算此时的Recall、Precision,得到下图左侧表格。以此绘制P-R曲线,得到右图。
- 计算P-R曲线下的面积,Recall差*此点之后最大的Precision值为每一段的面漆,各段面积相加即为猫这个类的AP值
- 所有参与计算的预测框都是NMS处理之后的预测框
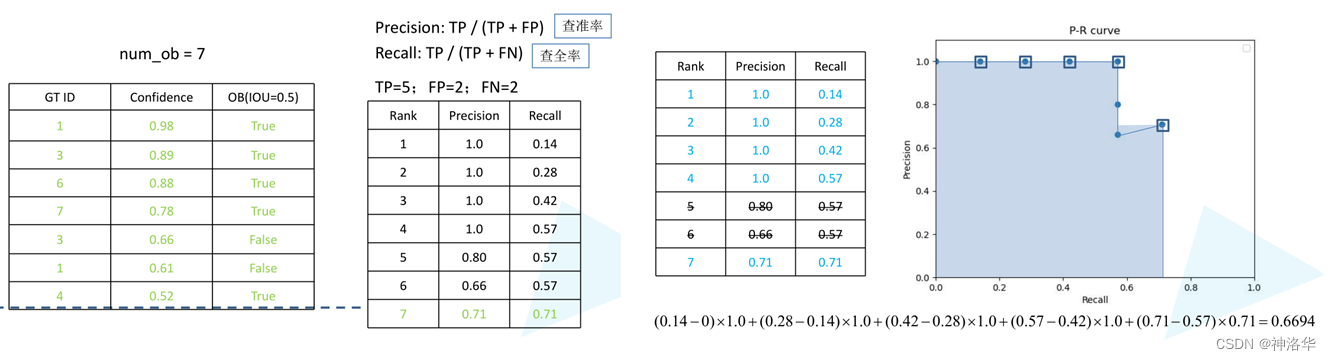
最后来说明coco的评测指标,下图中AP其实就是上面计算的mAP。
- A P I O U = 0.5 AP ^{IOU=0.5} APIOU=0.5表示IOU=0.5时的mAP,是PASCALVOC的评测指标。AP是IOU取从0.5到0.95,间隔为0.05的十个值情况下的mAP的均值,是coco数据集很重要的一个指标。IOU越大,表示要求的预测框和GT的重合度越来越高,定位越来越准。
- AP Across Scales:大、中、小目标的mAP。
- AP Recall(AR): A R m a x = 100 AR^{max=100} ARmax=100表示每张图片最多取100个预测框时的 Recall值。(预测结果越多召回率越大),对应左图指标中的maxdets=100。可以发现maxdets=10和maxdets=100的AR值差不多,说明图片中目标个数不是很多,基本都在10以内。
- AR Across Scales:大、中、小目标的召回率。
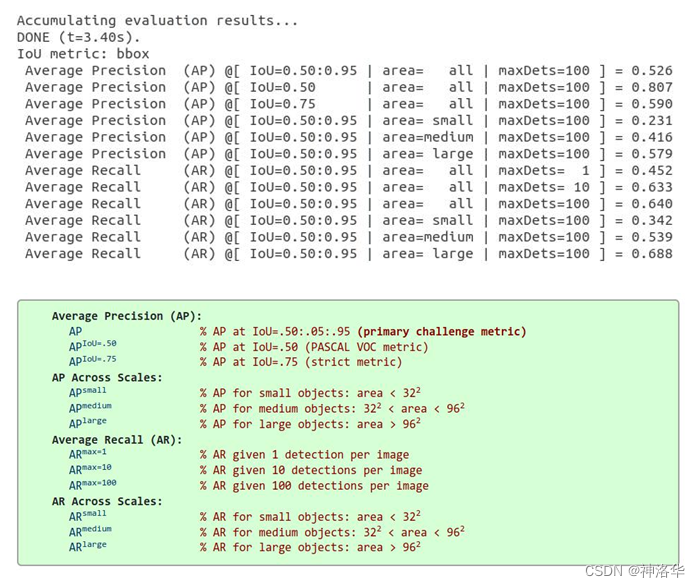
下面说一下需要关注的指标:
- 第一条、第二条分别是COCO和PASCALVOC的主要指标,需要关注
- 如果对定位精度要求比较高,可以关注IOU=0.75这个指标
- 根据目标检测尺度可以关注4-6行的指标
- 如果像上表maxdets=10和maxdets=100的AR值差不多,可以考虑减少预测框的数量
- NMS非极大抑制值(non-maximum suppression)
见《动手深度学习13:计算机视觉——目标检测:锚框算法原理与实现、SSD、R-CNN》的1.3.4章节
1.5 作业一:PaddleDetection快速上手
作业地址《PaddleDetection快速上手》、参考《PaddleDetection》第四章
二、RCNN系列目标检测算法详解
2.1 两阶段检测算法发展历程
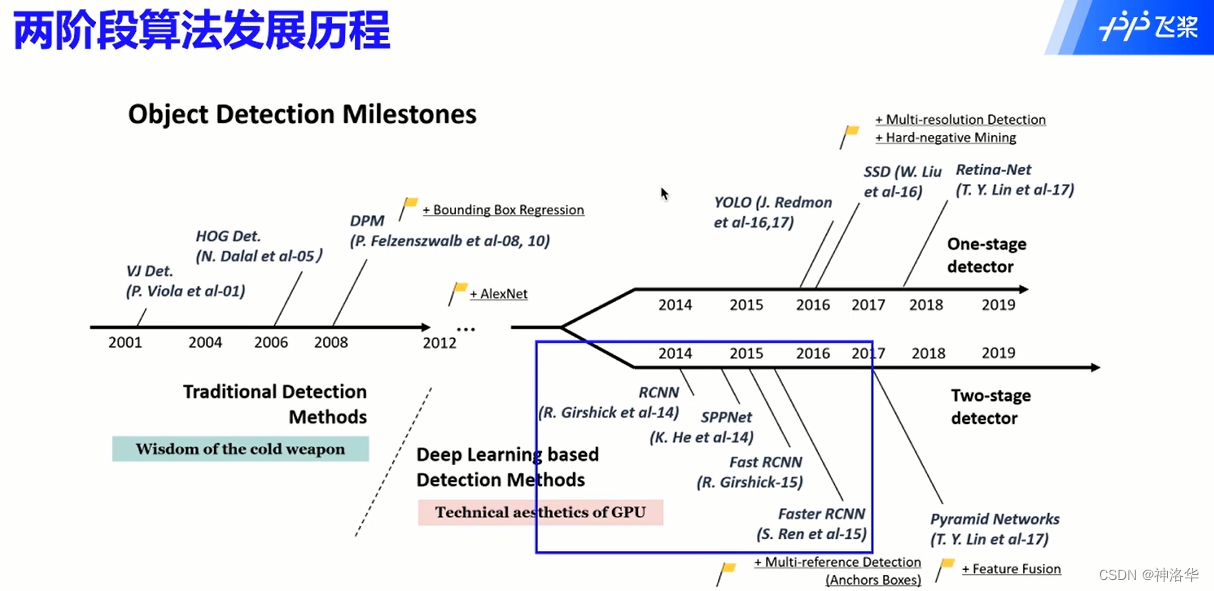
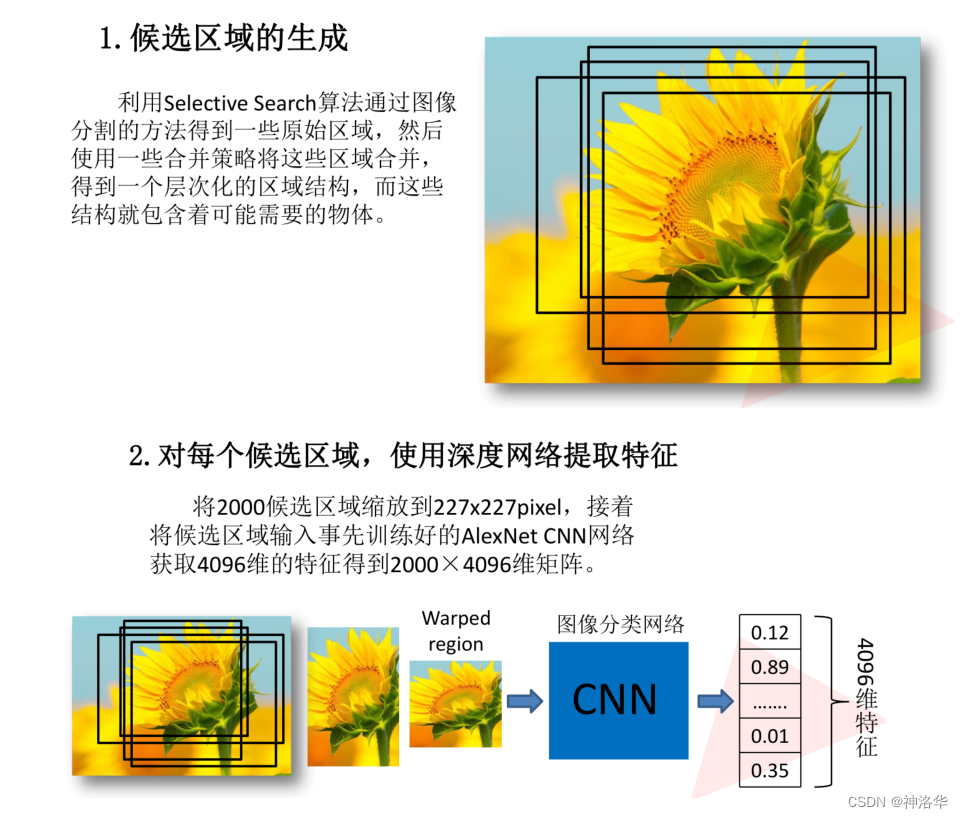
两阶段目标检测算法步骤:提取候选框→特征提取→分类器。R-CNN是用深度学习网络提取特征代替传统机器学习的图像特征提取方法,本节主要讲解两阶段算法RCNN系列。
2.2 R-CNN
R-CNN核心思想:对每张图片选取多个区域,每个区域都作为一个样本输入卷积网络(VGG)来提取特征,最后进行分类。
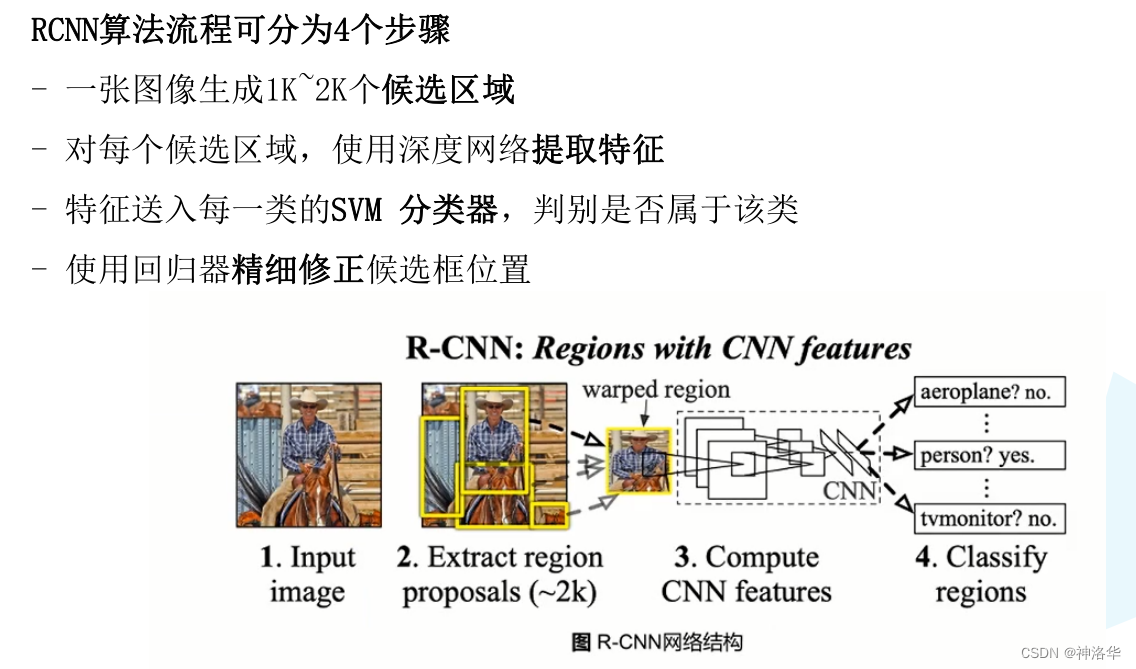
selective search(选择性搜索):机器学习目标检测算法中的做法,根据传统图像特征,比如尺寸、纹理、颜色的相似度提取大概2000个候选框。
通过SS算法得到的候选框位置还不是很准确,所以后面还需要用回归器精细修正候选框的位置,作为最终的预测框。
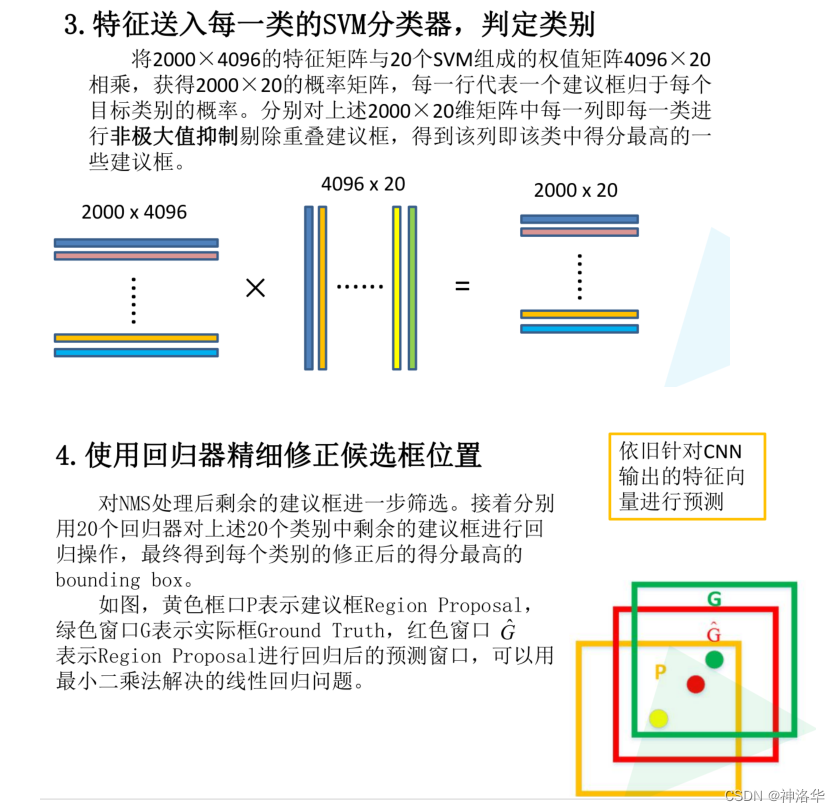
R-CNN三大不足:
- Selective Search基于传统特征提取的区域质量不够好
- 每个候选区域都需要通过CNN计算特征,且写入磁盘。这样计算量很大,训练时存储消耗多。
- 训练繁琐,耗时长。特征提取、SVM分类器是分模块独立训练,没有联合起来系统性优化。
2.3 Fast R-CNN
2.3.1 Fast R-CNN框架和原理
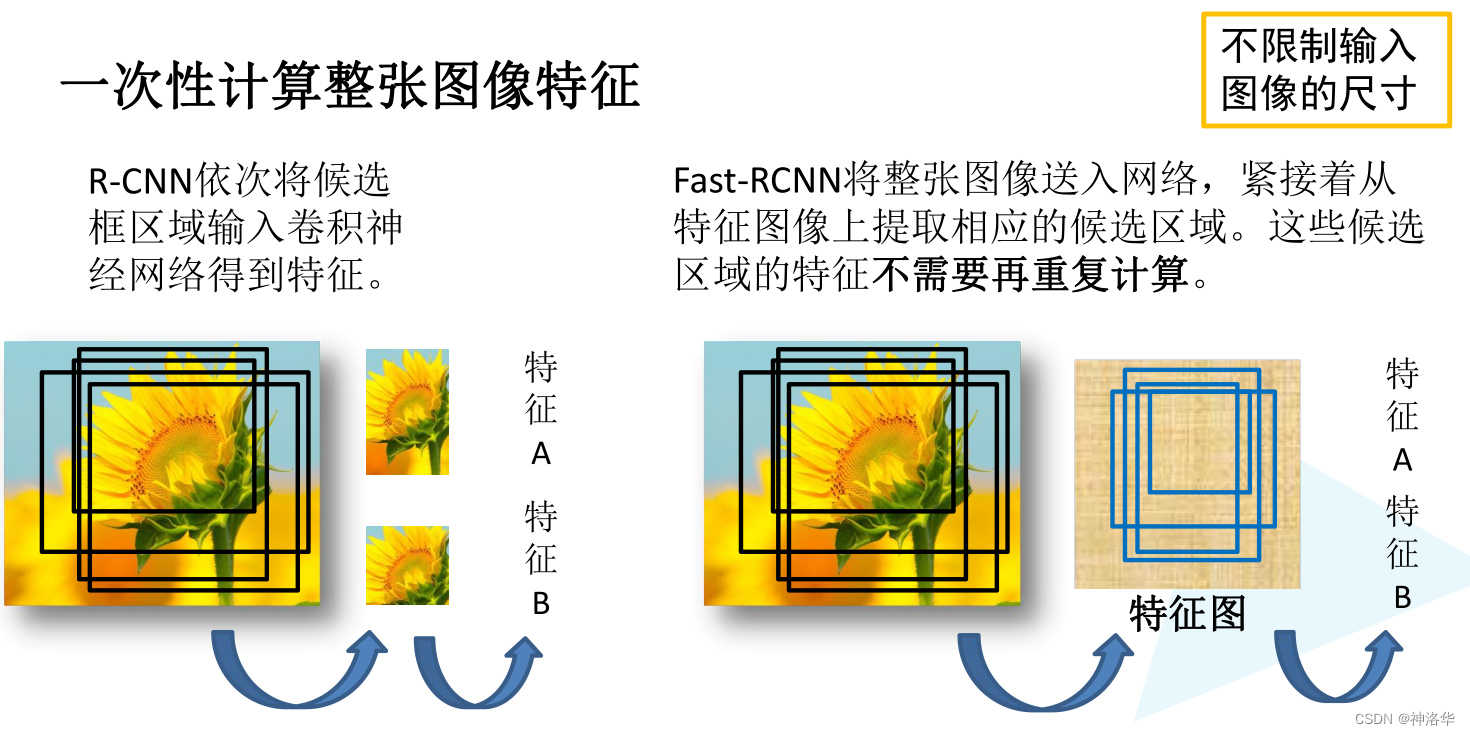
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(在Pascal VOC数据集上)
R-CNN的主要性能瓶颈在于:对于每个锚框都用CNN提取特征,独自计算,其实很多锚框是有重叠的。Fast R-CNN改进在于: 仅在整张图象上提取特征,如下图所示。
所以整个Fast R-CNN 算法流程可分为以下三个步骤:
如上图,主要计算如下:
- 输入为图像经过卷积神经网络,输出特征图的形状记为 1 × c × h 1 × w 1 1 times c times h_1 times w_1 1×c×h1×w1
- 假设选择性搜索生成了
n
n
n个候选区域,将这些区域输入
RoI pooling层(兴趣区域汇聚层),输出固定形状的RoIs, s i z e = n × c × h 2 × w 2 size=n times c times h_2 times w_2 size=n×c×h2×w2(RoI pooling后的特征图大小 h 2 × w 2 h_2 times w_2 h2×w2) - 通过全连接层将输出形状变换为 n × d n times d n×d的矩阵,其中超参数 d d d取决于模型设计
- 预测 n n n个RoIs的类别和边界框。全连接层的输出分别转换为形状为 n × q n times q n×q( q q q是类别的数量)的输出和形状为 n × 4 n times 4 n×4的输出,其中预测类别时使用softmax回归。
2.3.2 Fast R-CNN正负样本匹配
下图是论文的部分节选。
- 训练时,每张图像从SS算法生成的约2000个候选区域中筛选出64个进行训练。这64个分为正样本和负样本。
- 候选框和GT Box(目标真实框)的IoU大于0.5的是正样本,和所有GT Box的最大的IoU介于0.1-0.5之间的为负样本。

- 这些训练样本经过
RoI pooling层,缩放到统一的尺寸。
R-CNN中输入图像是统一缩放到227×227,而Fast R-CNN是不需要限制模型输入尺寸的。因为CNN的卷积层是可以处理任意尺度的输入的,但是全连接层输入必须是固定的长度,所以需要采用
RoI pooling层,将不同尺度的Region Proposal缩放到统一的尺寸。
2.3.3 RoI pooling
RoI pooling核心思想:候选框共享特征图,并保持输出大小一致。

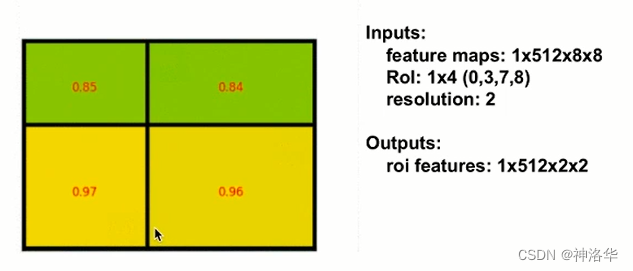
- Rol:1×4(0,3,7,8):前面的1是Rol的个数,4表示左上右下角四个点坐标。候选框左上角的点是特征图上的(0,3),右下角的点是(7,8)。
- resolution:表示期望最终输出候选框的大小,这里2表示是输出尺寸2×2的候选框。
- outputs:roi features这里的1是Rol个数,不再是图片的个数。
2.3.4 网络预测
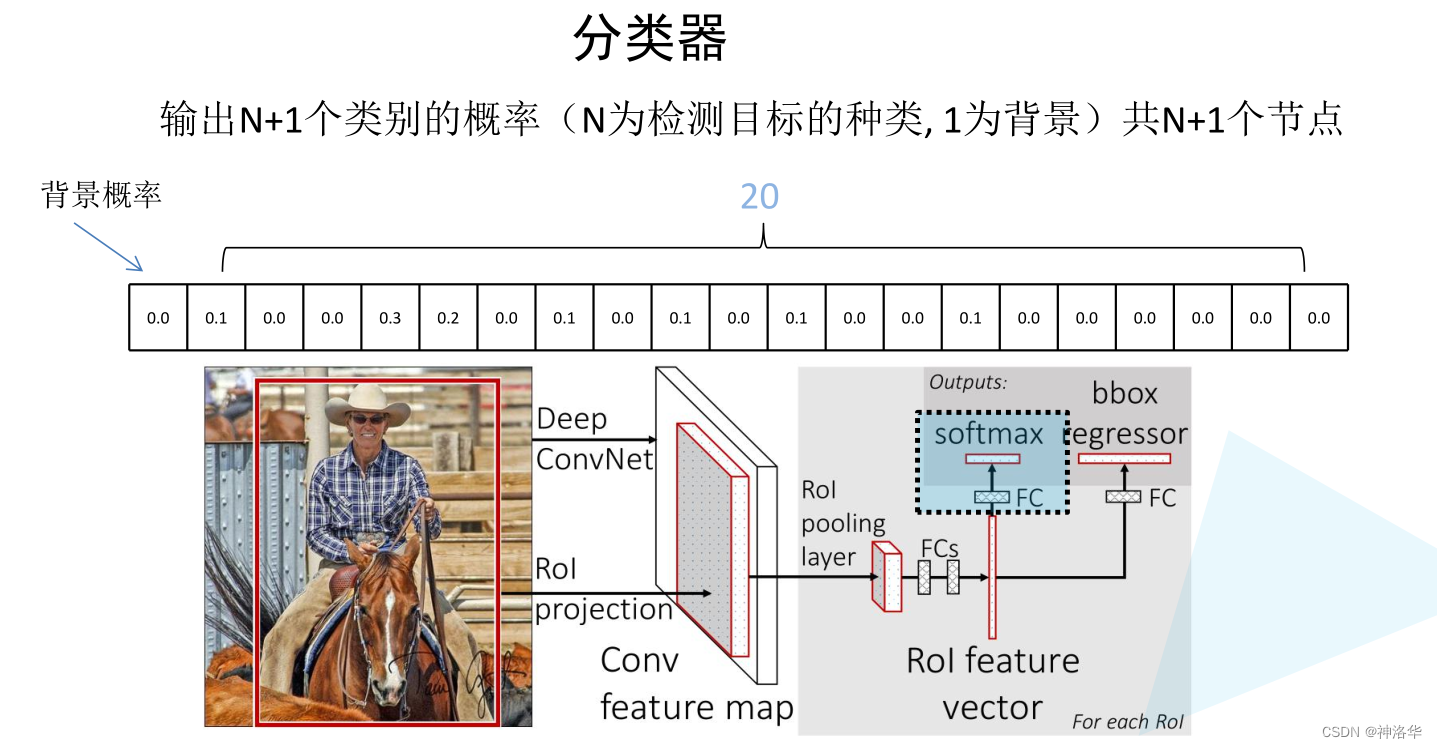
2.3.4.1 分类器
如下图所示:
- 输入图片经过SS算法得到候选区域,在特征图上映射得到约2000个候选区域的特征输出矩阵。
- 选取64个作为正负样本,经过
RoI pooling layer缩放到统一的尺度,再展平操作后经过两个全连接层,得到RoI Feature vector。 - RoI Feature vector并联两个FC全连接层。其中一个FC层经过softmax输出预测目标的概率,另一个用于预测边界框回归参数(也就是预测框的位置)。
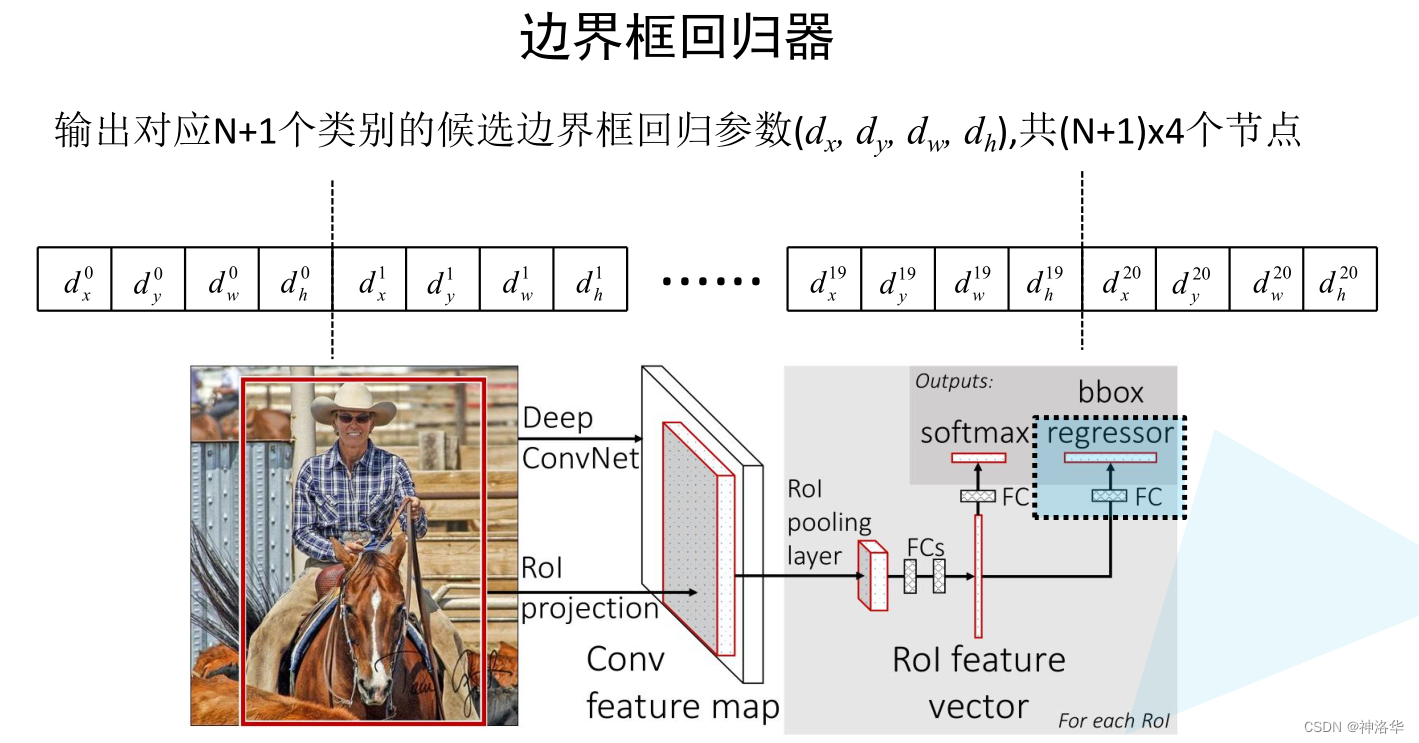
2.3.4.2 边界框回归器
边界框回归器会对预测框的每个类别都预测出四个边界框回归参数,如下图所示 :
下图是论文中,根据预测框回归参数得出预测框位置信息的公式,由此将橙色候选框调整到最终的红色预测框。

2.3.5 Fast R-CNN损失计算

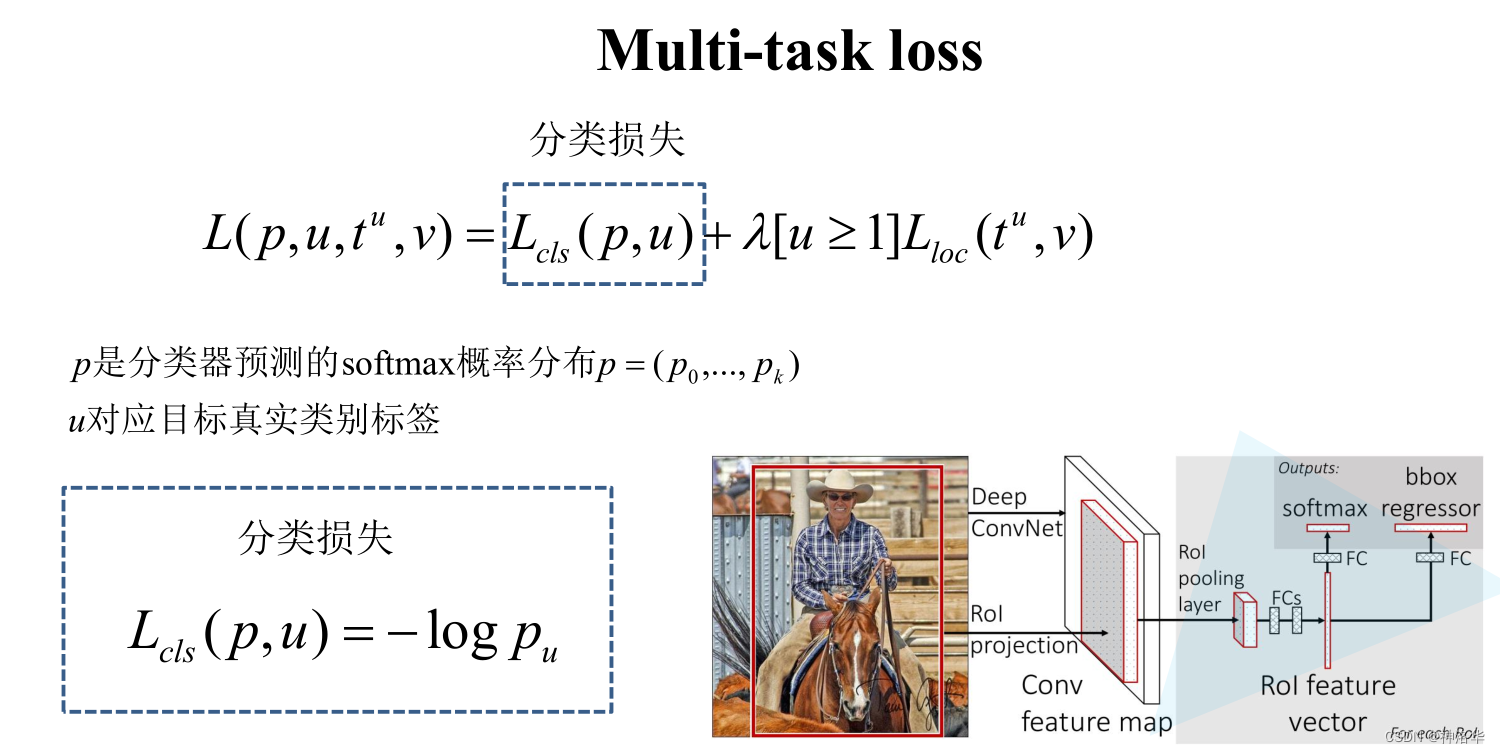
分类器损失用的是多分类交叉熵(Pytorch中的CrossEntropyLoss)

- 真实框GT的回归参数,参考边界框回归器那幅图。 v x = ( G x − P x ) / P w v_x=(G_x-P_x)/P_w vx=(Gx−Px)/Pw, v w = l n ( G w / P w ) v_w=ln(G_w/P_w) vw=ln(Gw/Pw)。另两个参数同理。
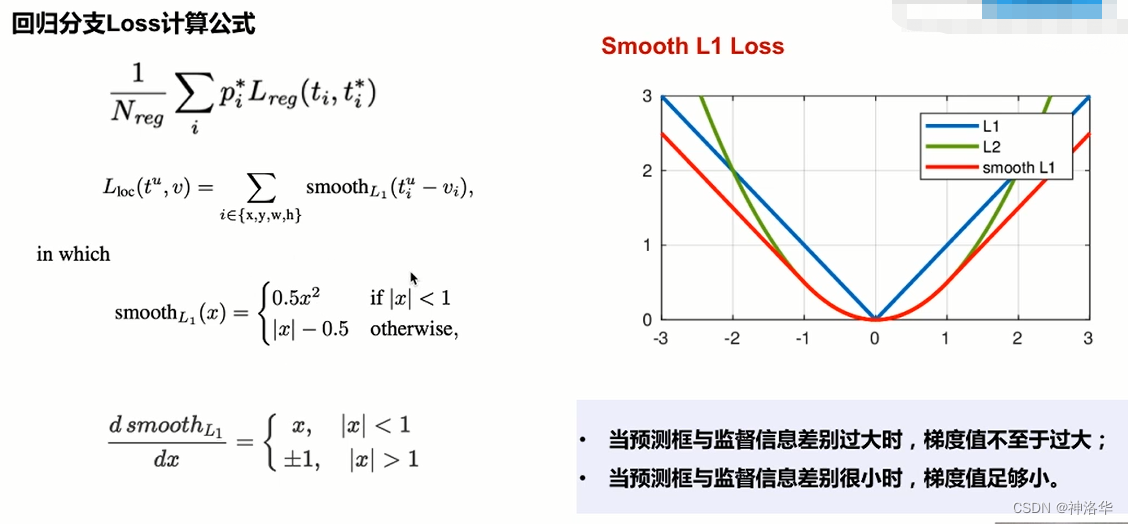
- L l o c L_loc Lloc有四项,分别是即回归参数[x,y,w,h]分别的 s m o o t h L 1 smooth_L1 smoothL1之和。
- s m o o t h L 1 smooth_L1 smoothL1计算公式如上图,是结合了L1损失和L2损失。
- λ系数用于平衡回归损失和分类损失
- [u≥1]:这一项表示u≥1时值为1,否则为0 。u表示目标的真实标签,u≥1说明候选区域含有某一个目标类别,即为正样本。所以[u≥1]表示只计算正样本的回归损失,负样本都是背景,没必要计算回归损失。
2.3.6 Fast R-CNN总结
- 通过SS算法得到候选区域(不限制输入图像尺寸)
- 使用VGG16对整张图片提取特征,得到Featrue Map。将候选区域将映射到Featrue Map上,得到候选区域的特征矩阵
- RoI池化为每个候选区域返回固定大小的特征矩阵RoI Feature vector(7×7)。
- RoI Feature vector经过展平和全连接层,得到类别概率和回归参数。
- svm分类器替换为softmax多分类器,利用Softmax Loss(分类训练) 和Smooth L1 Loss(回归训练),实现分类分支和回归分支的联合训练。
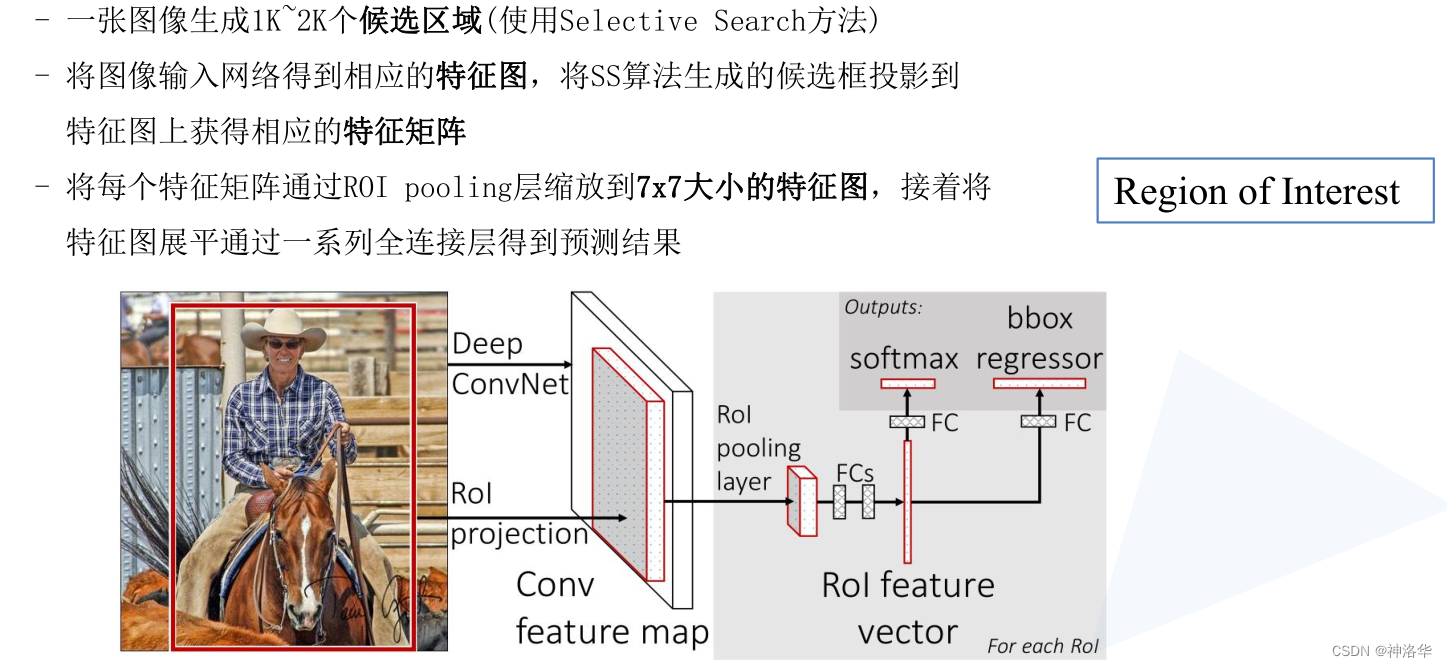
2.4 Faster R-CNN
在Fast R-CNN中,SS部分生成候选框需要2秒左右,而剩下的部分只需要零点几秒。所以SS生成候选框部分已经成为制约Fast R-CNN的一个瓶颈。
在Faster R-CNN中,使用了RPN(区域提议网络region proposal network)代替启发式搜索Selective Search来生成候选区域(锚框),候选区域从2000个减少到约300个,并且质量大大提升。Faster R-CNN推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。

2.4.1 Faster R-CNN网络结构
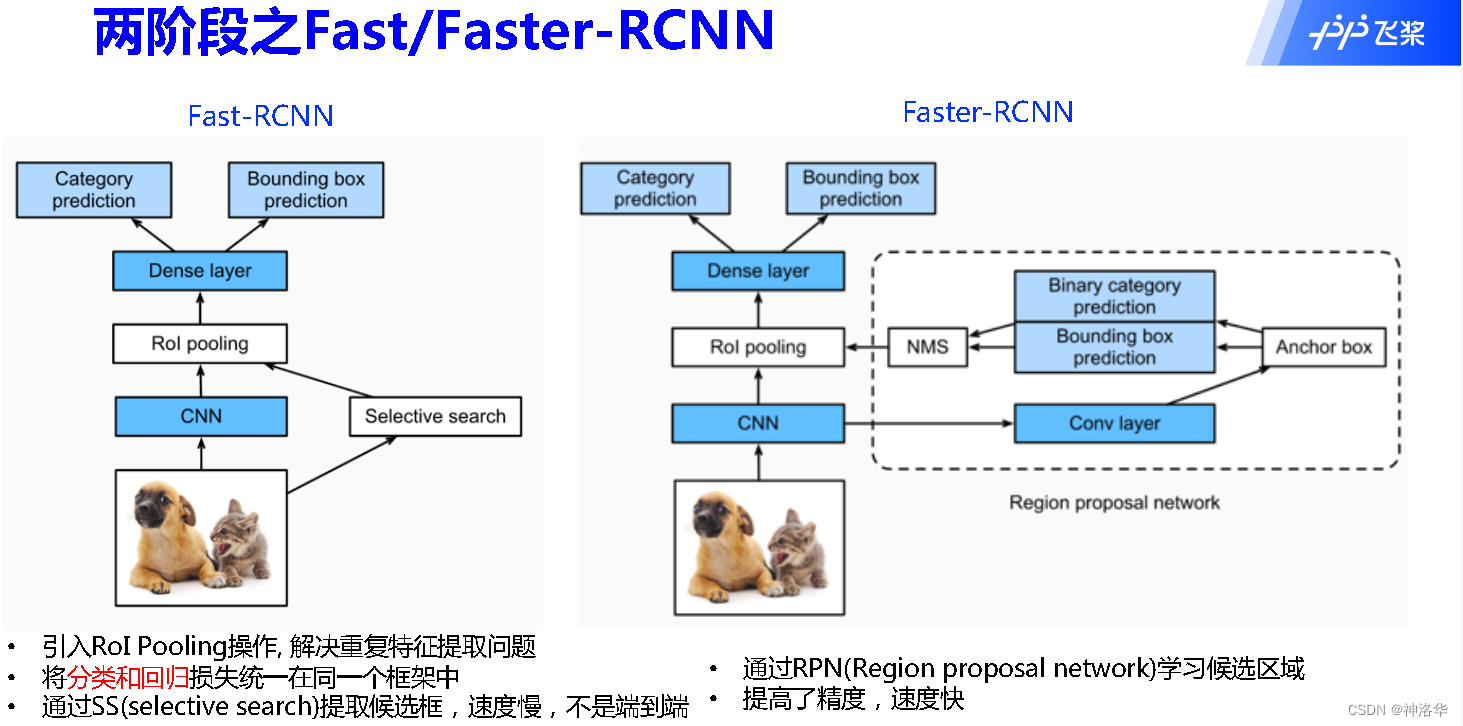
所以可以认为Faster R-CNN=RPN+Fast R-CNN。注意:RoI在RPN部分是没有的。
Faster R-CNN阶段一:
- 原始图片输入CNN网络得到特征图Featrue Map
- Featrue Map上每个点都作为中心点,生成大量不同尺寸的锚框Anchor。每个Anchor生成两个分支。
- 二元分类预测:判断这个锚框框住的是背景还是目标物体
- 边界框预测:回归分支,判断锚框和真实边界框的偏移量- RPN生成的锚框经过NMS处理,再进入Rol 池化层输出为统一大小,提取锚框对应的特征。
阶段二:
对候选区域进行分类并预测物体的位置。
2.4.2 RPN
2.4.2.1 RPN网络结构
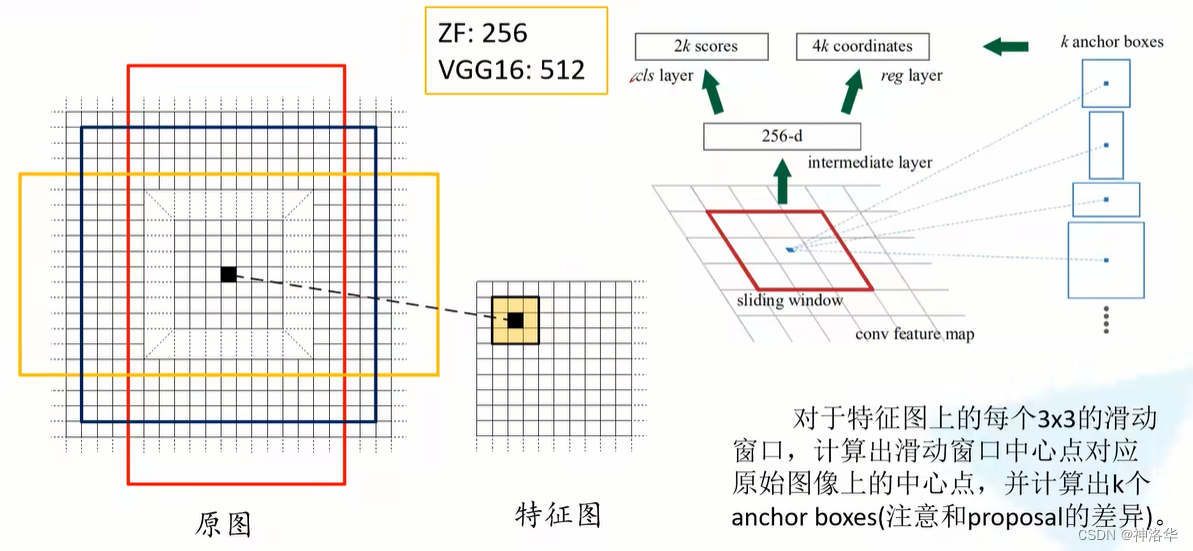
-
conv featrue map:即之前提到的Backbone骨干网络输出的特征图,用来作为RPN网络的输入。 -
在
conv featrue map使用3×3的滑动窗口(即3×3的卷积层),生成一个长度为256(对应于ZF网络)或512(对应于VGG16网络)维的矩阵。这个矩阵经过两个全连接层得到两个分支:- 分类分支,判断候选框是背景或者前景的概率(也就是候选框是否包含目标);
- 回归分支,预测非背景的边界框回归参数
- 论文中是说用全连接层得到两个分支,但代码中是用1×1卷积实现的
-
Anchor box:- 找出滑动窗口中心点对应原图上的点(锚点),计算锚点的位置。(缩放步距 s w = i n t ( W i m a g e W f e a t r u e − m a p ) s_w=int(frac{W_{image}}{W_{featrue-map}}) sw=int(Wfeatrue−mapWimage),锚点x坐标=滑动窗口中心点坐标x*s。y坐标同理得到)
- 以每个锚点为中心生成k个Anchor box。每个Anchor都需要预测类别参数和回归参数,所以两个分支预测参数数量分别是2k和4k。
作者在论文中定义k=9。即3种尺度(128,256,512)和3种高宽比(1:1,2:1,1:2)组成的9组Anchor。这个取值是经验所得。
- 3×3的滑动窗口是通过stride=1,padding=1,kenerl_zise=3的卷积层实现的,所以feature map上每个点都可以滑动到。只是有些窗口越界了。卷积后得到的特征矩阵的shape和featrue map的shape完全一样。对于一幅W*H的feature map,对应原图就有W*H*k个锚点。
-
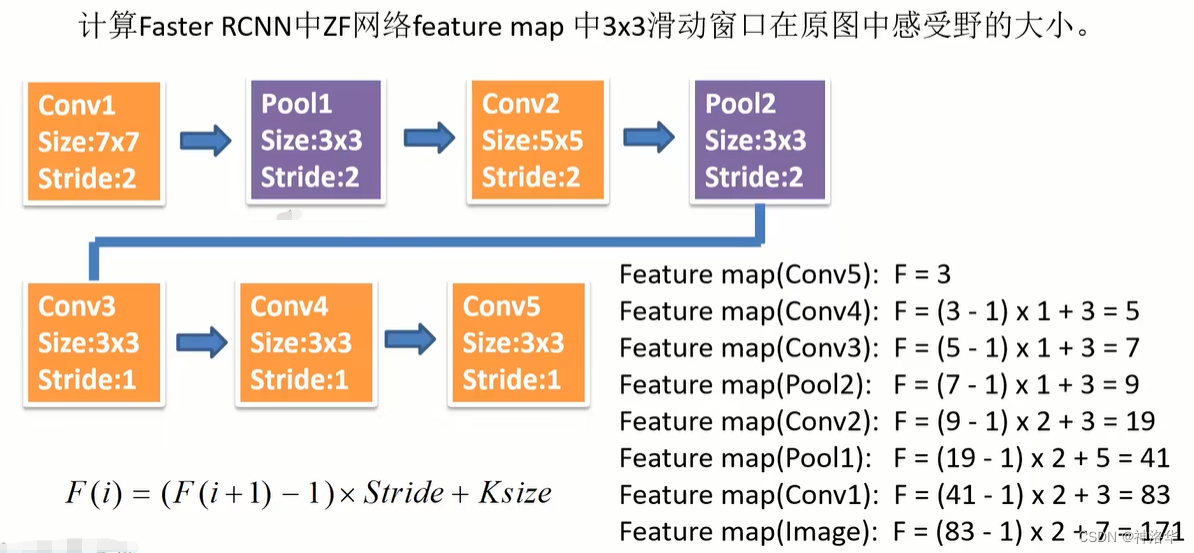
Backbone=ZF网络,输出特征图的channel=256,每个滑动窗口在原图感受野为171;Backbone=VGG16,输出特征图channel=512,每个滑动窗口在原图感受野为228。
为什么窗口感受野小于Anchor box尺度时也能预测出目标呢?(比如ZF网络窗口感受野171,而生成的Anchor box尺度有256和512。作者认为通过一个小的感受野去预测一个更大的目标是可能的,比如我们通过一个物体的局部有可能大概猜出物体的完整边界)
- 将这些anchor box(21600个)和RPN两个分支的输出联合,经过回归参数调整为proposals。最终得到RPN网络的输出的最终候选框proposals(约2000个),进入到后续网络计算。
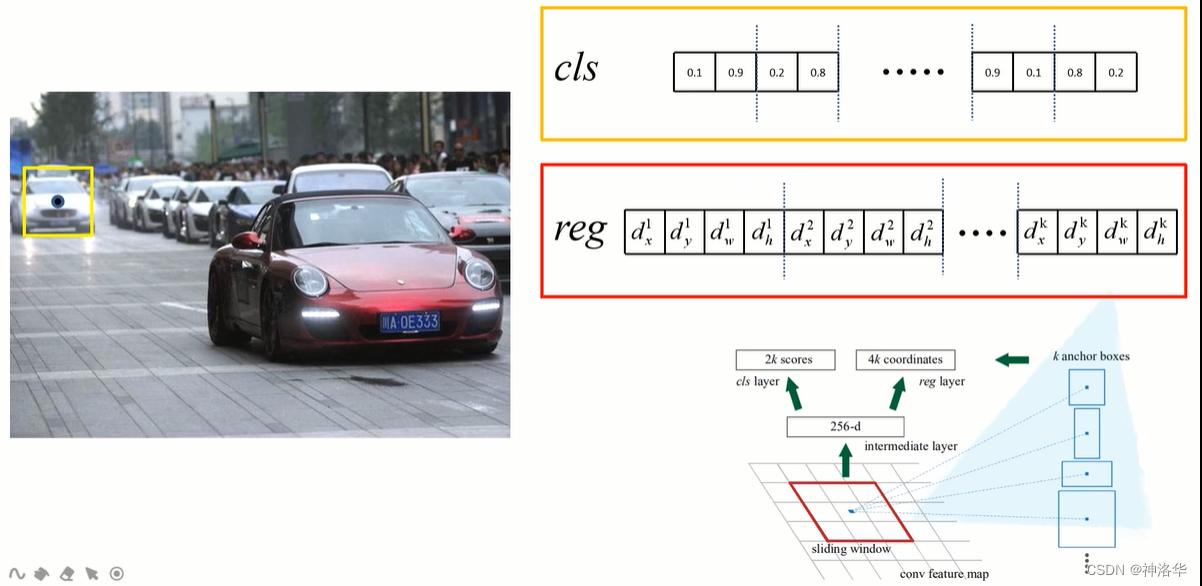
- 如下图所示,输入一张1000×600×3的图像,输出特征图大小为60×40×256。每个像素点生成9个锚框,共生成21600个锚框。
- 分类分支有1×18×60×40个参数,回归分支有1×36×60×40个参数。
- 去除越界的Anchor,大概剩下约6000个Anchor。利用边界框回归参数,将其调整为6000个
候选框proposals。 - RPN生成的这6000个proposals有大量的重叠,使用NMS方法,设置IoU阈值=0.7,每张图片得到约2000个候选框,作为RPN网络的最终输出。(selective search算法得到的候选框个数也是约2000个)
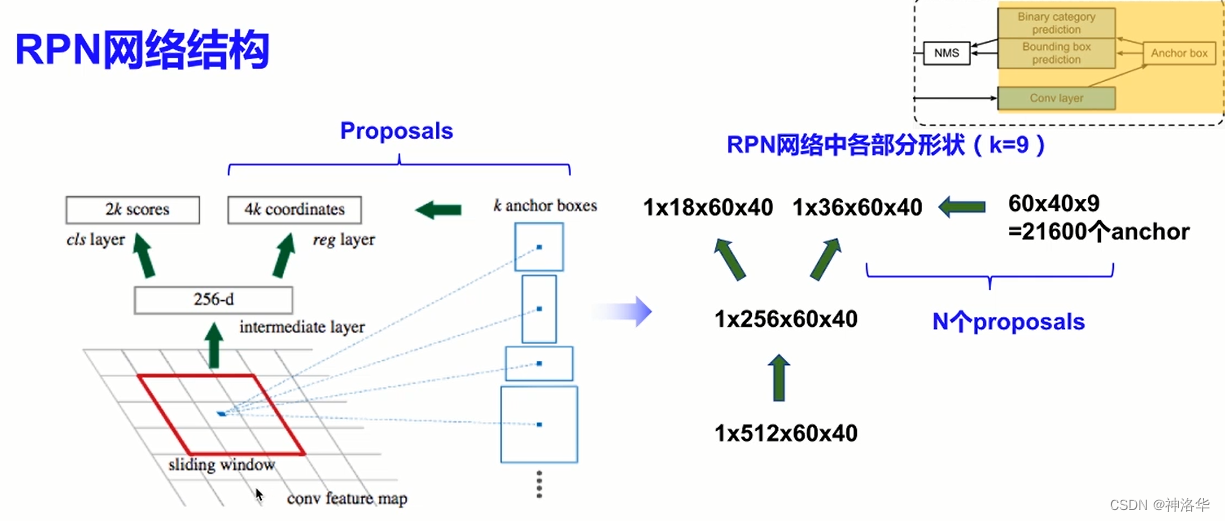
总结:RPN其实类似一个很粗糙的目标检测。
- RoI pooling需要CNN输出的Featrue Map和锚框
- CNN的输出进入一个卷积层,然后生成一堆锚框(启发式搜索或者别的方式)。根据提取的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
- 使用nms,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
RPN作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。
2.4.2.2 RPN网络的正负样本采样
- 在训练集中,我们将每个候选框视为⼀个训练样本。为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(offset)标签。
- 预测时,我们为每个图像生成多个候选框,预测所有候选框的类别和偏移量,最后只输出符合特定条件的预测边界框。


- anchor和真实框的IoU在0.3-0.7之间的anchor会被忽略,既不作为正样本,也不作为负样本。
- 右下角橙色anchor是正样本(1.2.4.5.6),3号anchor是负样本,7号anchor被忽略
2.4.2.3 RPN网络loss
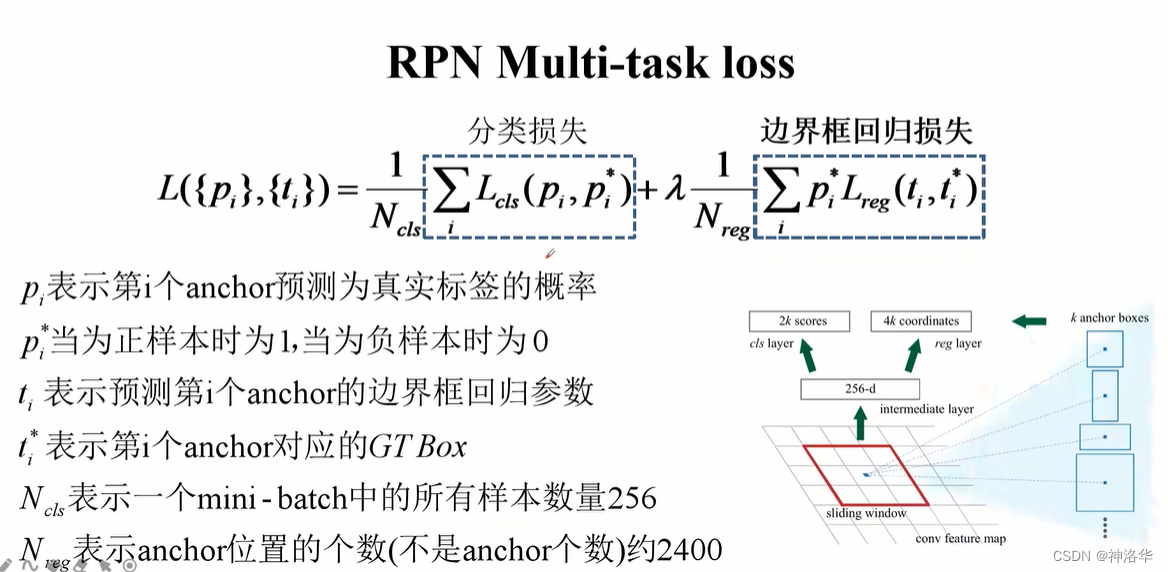
- RPN网络的loss是两分支loss加权和。回归分支 ∑ p i ∗ sum p_{i}^{*} ∑pi∗,这里乘以 p i ∗ p_{i}^{*} pi∗表示只计算正样本的偏移量loss(正样本 p i ∗ = 1 p_{i}^{*}=1 pi∗=1)
- 分类分支loss是二分类交叉熵loss,回归分支是smooth L1 loss。
- 作者说这个公式可以继续化简。 N c l s N_{cls} Ncls表示一个batch中所有样本数量256, N r e g N_{reg} Nreg表示锚点的个数(60×40=2400),λ=10,所以 λ 1 N r e g = 1 240 ≈ 1 N c l s lambdafrac{1 }{N_{reg}}=frac{1}{240}approx frac{1}{N_{cls}} λNreg1=2401≈Ncls1。Pytorch官方实现的Faster R-CNN中, λ 1 N r e g lambdafrac{1 }{N_{reg}} λNreg1取值就是 1 N c l s frac{1}{N_{cls}} Ncls1。
- smooth L1 loss在
2.3.5 Fast R-CNN损失计算中有讲过
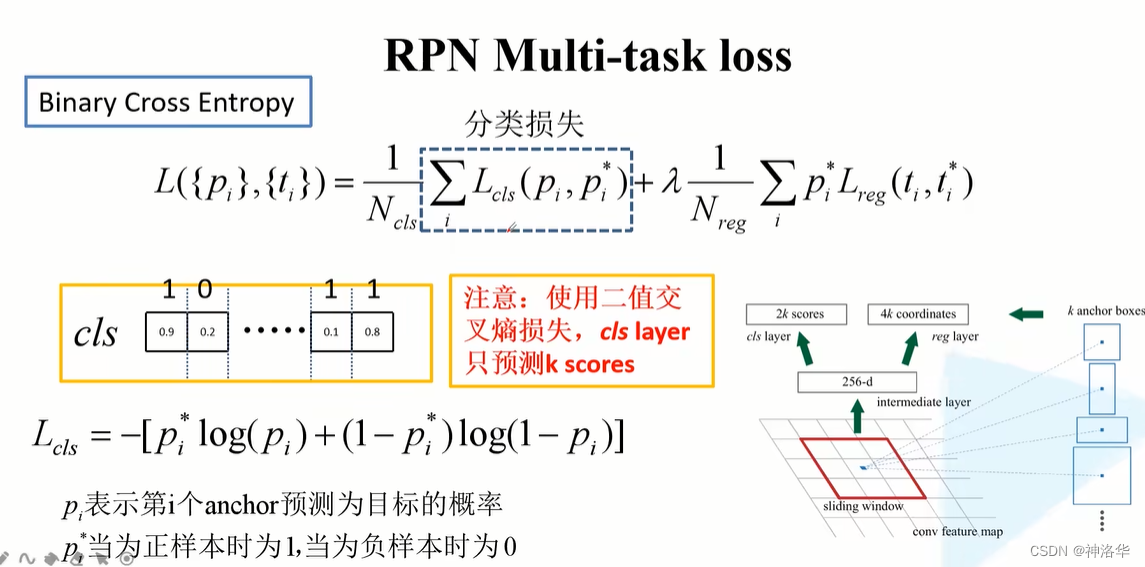
分类损失
回归损失

注意:候选框的回归参数是网络预测出来的,而GT box的回归参数是按照上面公式计算的,和2.3.5 Fast R-CNN损失计算中计算方式一样。
2.4.3 Faster R-CNN损失计算
这部分内容和 2.3.5 Fast R-CNN损失计算是一样的,不再赘述。

2.4.4 Fast R-CNN联合训练
现在的Fast R-CNN是直接采用RPN Loss+ Fast R-CNN Loss的联合训练方法,两者加在一起直接进行反向传播,而原论文中是二者分开训练的。

以下内容是《目标检测7日打卡营》Day2在Faster R-CNN原理详解中讲到的。估计是PaddleDetection中的Faster R-CNN这么做的把。
2.4.5 R-CNN系列模型框架对比
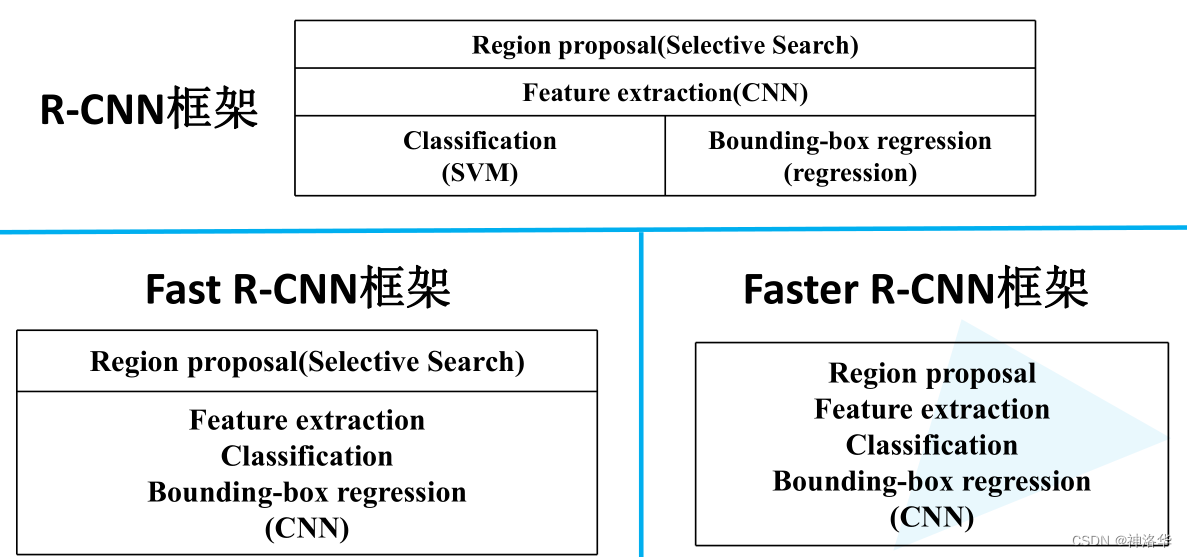
- R-CNN:分成三个部分。SS生成Region proposal,CNN进行特征提取(feature extraction),训练SVM分类器和边界框回归器分别进行类别预测和定位边界框。
- Fast R-CNN:分成两个部分,SS生成Region proposal,以及CNN实现剩下三个步骤
- Faster R-CNN将这四部分内容都融合在一个CNN网络中,所以是一个端到端的检测模型。
2.5 Pytorch Faster R-CNN源码解析
2.6 PaddleDetection Faster R-CNN
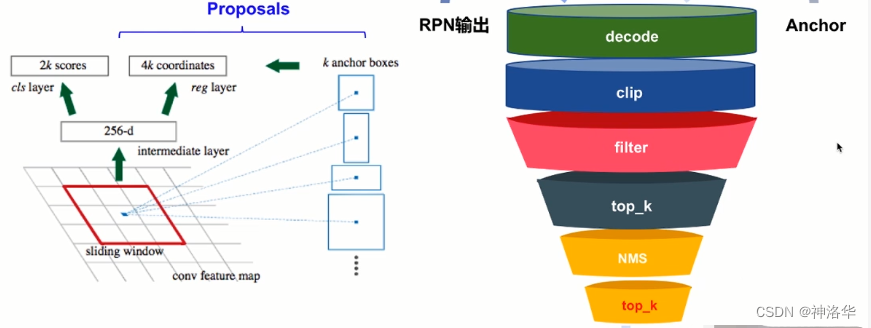
2.6.1 生成proposals
RPN两分支输出和anchor结合得到最终的RPN网络输出proposals,再输入后续网络。proposals生成过程如下:
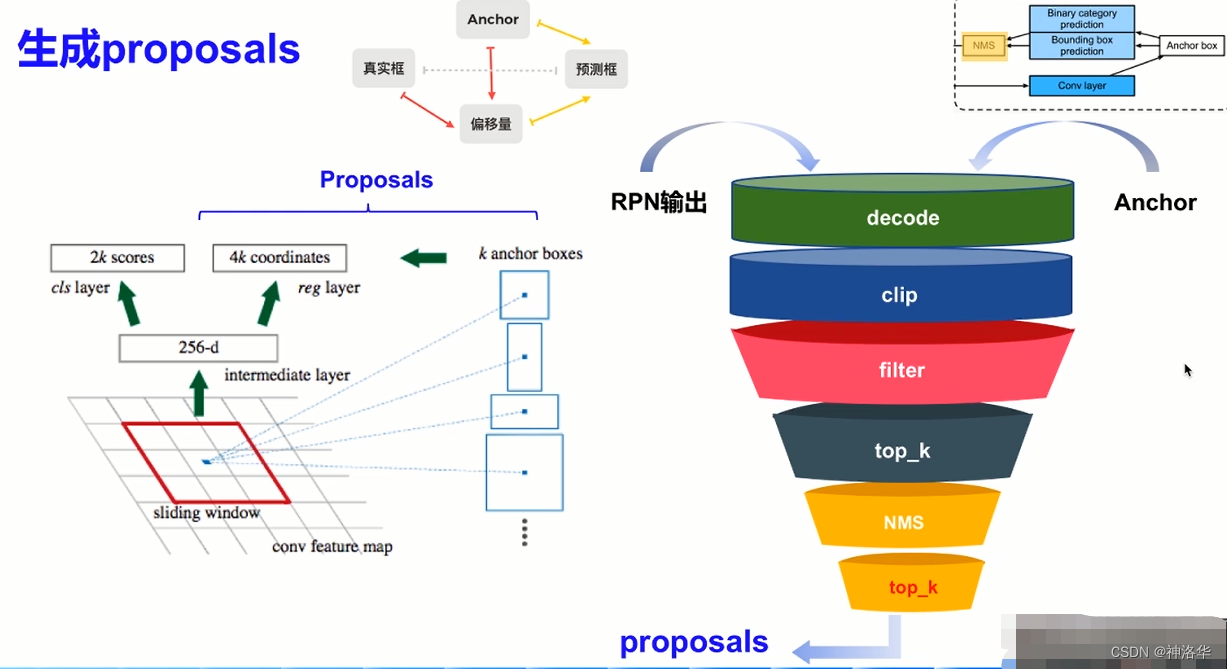
- decode: 两分支输出和anchor一起解码得到预测框(根据Anchor和偏移量得到预测框,和之前的根据Anchor和真实框得到偏移量是相反的过程)
- clip:将预测框位置限制在图片范围之内(21600个减少到6000个)
- filter:过滤面积太小的预测框
- top_k:排序,取预测分数最大的k个锚框
- NMS:去掉一些重叠、接近的锚框
- top_k:继续过滤低分的锚框,得到约2000个proposals。
2.6.2 RoI Align
在2.3.3中我们讲到了RoI pooling,但是这种方法也有一些不足。Rol Pooling在两次取整近似时,会导致检测信息和提取出的特征不匹配。
- 候选框的位置取整。当Rol位置不是整数时,Rol的位置需要取整
- 提取特征时取整。划分4个子区域做maxpooling,框的长度需要做近似取整。

Mask R-CNN将兴趣区域汇聚层RoI pooling替换为了兴趣区域对齐层RoI align,RoI pooling在无法均分时有填充,但对于像素级标号来说,这种填充会造成像素级偏移。这样在边界处标号预测不准。
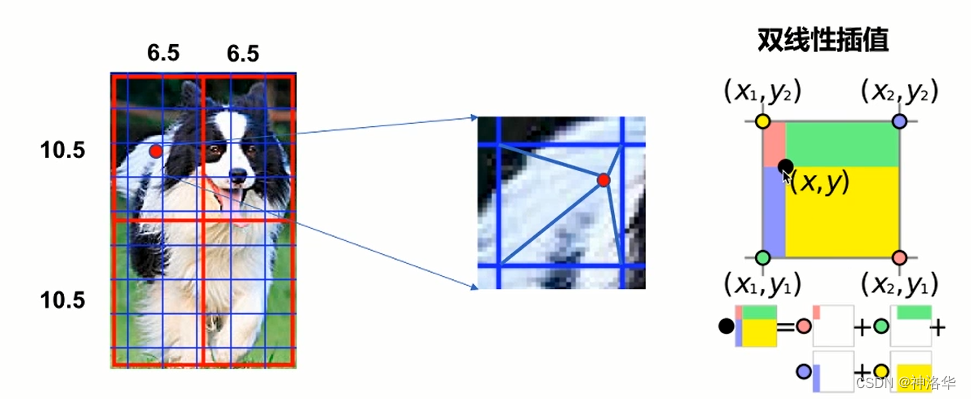
RoI Align:是候选框RoI在特征图上进行特征抽取的过程,使用双线性插值(bilinear interpolation)的方法代替坐标取整的过程,保留特征图上的空间信息。

如上图所示,RoI Align划分子区域时,不进行近似取整,保留小数。这样要解决一个问题:如何通过子区域得到Rol对应的特征输出?
RoI pooling:右上图蓝色网格交叉点可理解为特征图上每个像素点的位置。RoI pooling中经过近似取整,红蓝线重合,每个子区域可以用蓝色交叉点的位置表示。RoI Align:在区域内均匀的取N个点,找到特征图上离每个点最近的四个点,再通过双线性插值的方式,得到点(比如下图红色点)的输出值。最后对N个点取平均得到区域的输出。- 双线性插值:某个点的输出,根据周围四个点的值及这个点到周围四个点的距离,加权求和得到这个点的输出。
2.6.3 BBox Head检测头
BBox Head结构
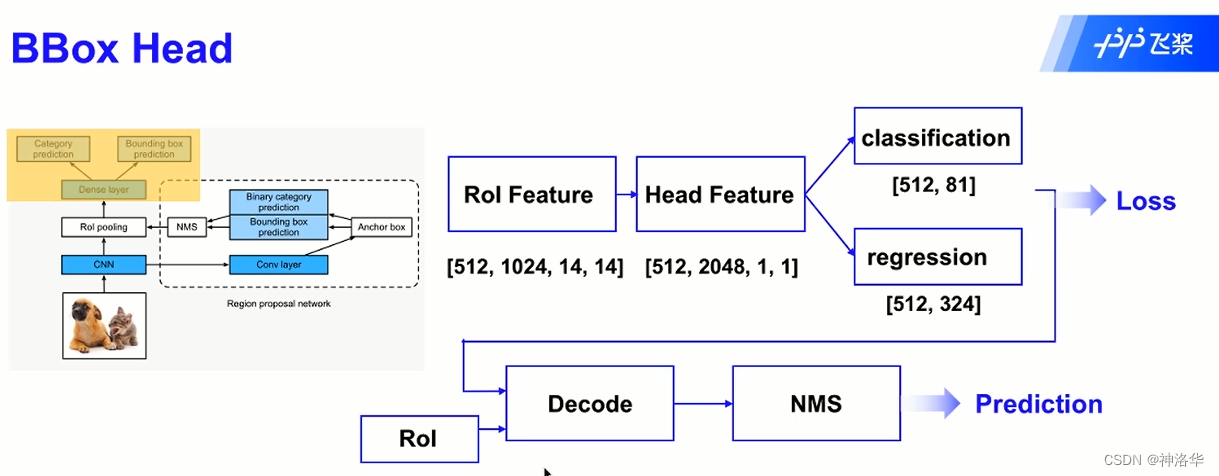
训练阶段:
- backbone采用VGG16网络,输出特征图有512个通道。ROI pooling layer将其下采样到14×14的尺度。这样所有region proposal对应了一个7*7*512维度的特征向量RoI Features作为全连接层的输入(卷积实现)。
- RoI Features经过一系列卷积得到Head Features(尺寸为1×1)。
- Head Features经过两个fc网络分别进行分类和回归。分类分支需要分出物体的类别(之前只是判断候选框是否含有物体),回归分支继续对候选框位置微调。(81是类别数,324是4×81)
预测阶段:
BBox Head部分输出和RoI进行解码得到预测框,经过后处理(NMS等)得到最终预测结果。
BBox Head训练

为了保证正样本存在,RoI和真实框共同参入采样,这样采样结果可能直接包含真实框。
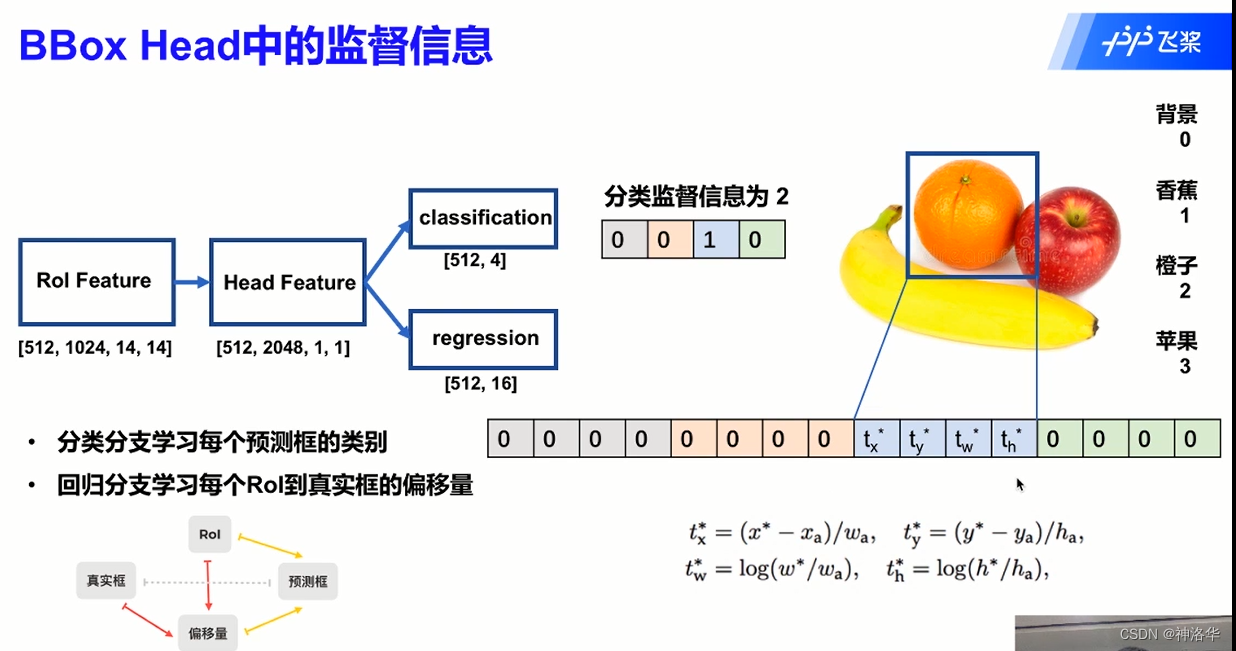
- 分类分支[512,4]中,4表示类别个数。比如上图预测框预测出橙子,即预测类别为2,用[0,0,1,0]表示。
- 回归分支[512,16],16代表四个类别,每个类别需要4个监督值。在类别2位置上根据监督值生成偏移量,其它位置生成0 。
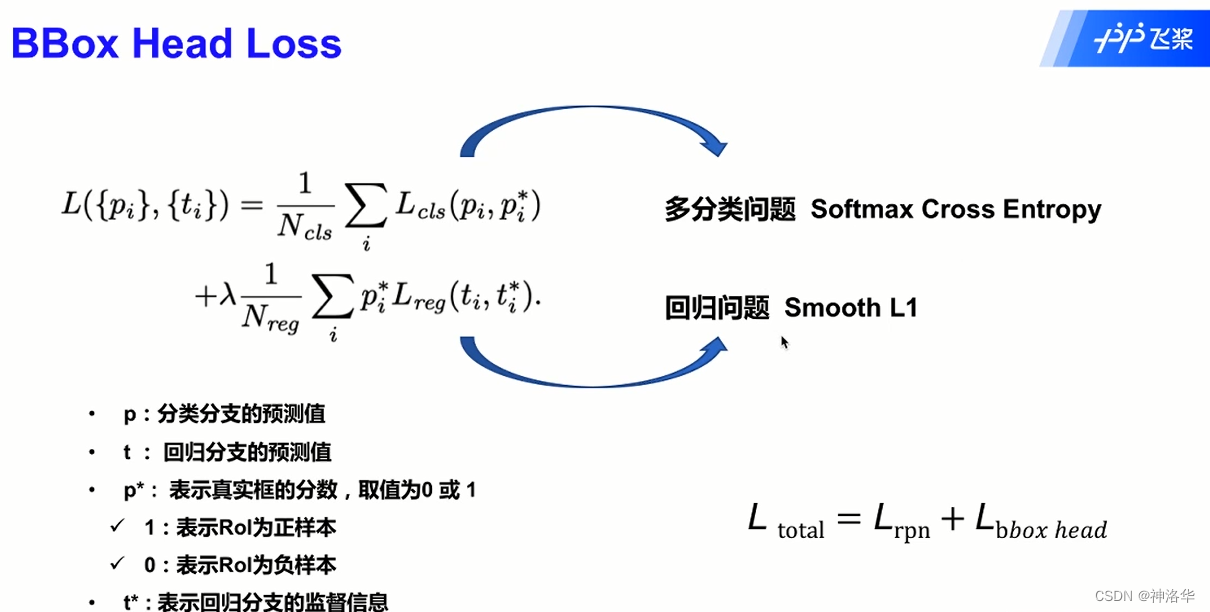
最终loss是RPN部分loss和BBox Head部分loss的和,即两部分网络一起训练。
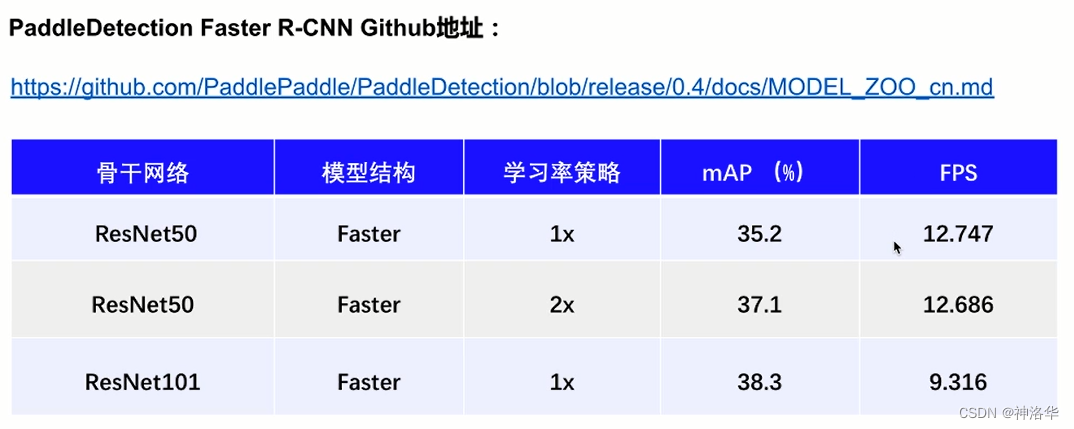
2.6.4 PaddleDetection模型库和基线
详细的见《模型库和基线》
2.7 PaddleDetection快速上手项目对照讲解
项目地址:《PaddleDetection快速上手》
在之前讲过,使用faster_rcnn进行目标检测,可运行以下代码开始训练:
# 选择配置开始训练。可以通过 -o 选项覆盖配置文件中的参数
! python -u tools/train.py -c configs/hw_configs/faster_rcnn_r50_vd_fpn_roadsign_coco_template.yml -o use_gpu=true --eval
我们打开配置文件work/hw_configs/faster_rcnn_r50_roadsign_coco_template.yml看看。
# FasterRCNN检测模型的结构
FasterRCNN:
backbone: ResNet
rpn_head: RPNHead
roi_extractor: RoIAlign
bbox_head: BBoxHead
bbox_assigner: BBoxAssigner #阶段2对RoI进行正负样本匹配和分配标签的过程
# 检测模型的backbone,这里使用的是ResNet50
ResNet:
# norm_type
norm_type: affine_channel
# depth
depth: 50
# feature_maps
feature_maps: 4
# freeze_at
freeze_at: 2
# ResNetC5
ResNetC5:
# depth
depth: 50
# norm_type
norm_type: affine_channel
# 检测模型的RPNHead
RPNHead:
# 根据特征图尺寸,在特征图的每个位置生成N个大小、长宽比各不同anchor
# N = len(anchor_sizes) * len(aspect_ratios),这里是特征图上每个像素点生成15个anchor
# 具体实现参考[API](fluid.layers.anchor_generator)
anchor_generator:
# 生成anchor的anchor大小,以绝对像素的形式表示,以正方形边长表示面积
anchor_sizes: [32, 64, 128, 256, 512]
# 生成anchor的高宽比
aspect_ratios: [0.5, 1.0, 2.0]
# anchor在宽度和高度方向上的步长
stride: [16.0, 16.0]
# 在框回归delta中使用
variance: [1.0, 1.0, 1.0, 1.0]
# 具体实现参考[API](fluid.layers.rpn_target_assign)
rpn_target_assign:
# 每个图像中RPN示例总数,即每张图采样256个anchor
rpn_batch_size_per_im: 256
# 正样本个数占比
rpn_fg_fraction: 0.5
# 和任何ground-truth boxes的IoU都低于阈值 rpn_negative_overlap 的anchor被判定为负类别
rpn_negative_overlap: 0.3
# 和任意一个groundtruth box的 IoU 超出了阈值 rpn_positive_overlap 的anchor被判定为正类别
rpn_positive_overlap: 0.7
# 超出图像外部 straddle_thresh 个像素的RPN anchors会被删除
rpn_straddle_thresh: 0.0
# 是否使用随机采样来选择foreground boxes和background boxes
use_random: true
生成propose的过程分为训练阶段和预测阶段。将anchor和RPN两个分支的输出联合,经过一些后处理,最终得到RPN网络的输出proposals(最终候选框)
# 训练阶段时 propose 产生阈值
train_proposal:
min_size: 0.0 #筛除面积较小的anchor
nms_thresh: 0.7 #NMS筛选
pre_nms_top_n: 12000 #第一次top_k排序筛选
post_nms_top_n: 2000 #第一次top_k排序筛选
# 测试阶段时 propose 产生阈值
test_proposal:
min_size: 0.0
nms_thresh: 0.7
pre_nms_top_n: 6000
post_nms_top_n: 1000
# RoIAlign
# 具体实现参考[API](paddle.fluid.layers.roi_align)
RoIAlign:
# ???
resolution: 14 #最终RoI特征图的大小
# 插值格中采样点的数目
sampling_ratio: 0 #每个区域均匀采样点的个数N
# 乘法性质空间标尺因子,池化时,将RoI坐标变换至运算采用的标度,默认值为1.0
spatial_scale: 0.0625
# BBoxAssigner
# 求rpn生成的roi跟gt bbox之间的iou,然后根据阈值进行过滤,保留一定数量的roi
# 再根据gt bbox的标签,对roi进行标签赋值,即得到每个roi的类别
# 具体实现参考[API](fluid.layers.generate_proposal_labels)
BBoxAssigner:
# 每张图片抽取出的的RoIs的数目
batch_size_per_im: 512
# Box 回归权重
bbox_reg_weights: [0.1, 0.1, 0.2, 0.2]
# box与某个groundtruth的IOU 在[bg_thresh_lo, bg_thresh_hi]区间,则该box被标记为background
bg_thresh_hi: 0.5 #IoU阈值
bg_thresh_lo: 0.0
# 在单张图片中,foreground boxes占所有boxes的比例
fg_fraction: 0.25 #采样中正样本占比
# foreground重叠阀值,用于筛选foreground boxes
fg_thresh: 0.5
# BBoxHead,省略了解码过程
BBoxHead:
# BBoxHead(head=None, box_coder=BoxCoder, nms=MultiClassNMS, bbox_loss=SmoothL1Loss, num_classes=81)
# 具体实现参考[code](ppdet.modeling.roi_heads.bbox_head.BBoxHead)
head: ResNetC5
# nms
# 具体实现参考[API](fluid.layers.multiclass_nms)
nms:
# 基于 score_threshold 的过滤检测后,根据置信度保留的最大检测次数
keep_top_k: 100
# 在NMS中用于剔除检测框IOU的阈值,默认值:0.3
nms_threshold: 0.5
# 过滤掉低置信度分数的边界框的阈值。如果没有提供,请考虑所有边界框
score_threshold: 0.05
2.8 作业二:印刷电路板(PCB)瑕疵检测
参考《作业二:RCNN系列模型实战》、《PCB瑕疵检测RCNN系列——mAP 99.4解决方案》
印刷电路板(PCB)瑕疵数据集:数据下载链接,是一个公共的合成PCB数据集,由北京大学发布,其中包含1386张图像以及6种缺陷(缺失孔,鼠标咬伤,开路,短路,杂散,伪铜),用于检测,分类和配准任务。我们选取了其中适用与检测任务的693张图像,随机选择593张图像作为训练集,100张图像作为验证集。
三、两阶段目标检测进阶算法
3.1 FPN多尺度检测
3.1.1 FPN结构和原理
FPN原理
FPN(feature pyramid networks)要解决的一个问题,就是目标多尺度的问题。
卷积神经网络有多层卷积,得到对应原图不同缩放程度的特征图。浅层网络分辨率高,学习的是细节特征;深层网络分辨率低,学习的是全局特征。原来多数的目标检测算法都是只采用顶层特征做预测,另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而 FPN不一样的地方在于预测是在不同特征层独立进行的。目标大就在深层网络中做预测,目标小就在浅层网络中做预测。
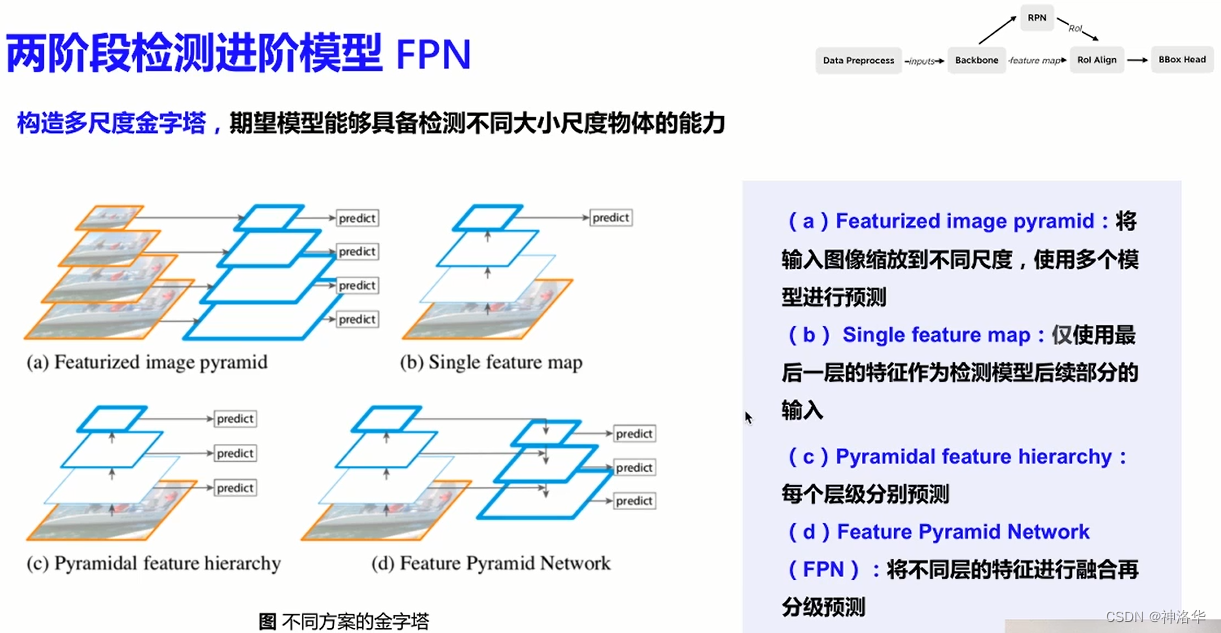
- a. 图像金字塔
- b. SPP net,Fast RCNN,Faster-RCNN是采用这种方式,只用骨干网络的最后一层的特征,这样对小物体不够友好。
- c.无融合,只是利用不同层的不同尺度的特征做预测,SSD采用这种方式。这样不会增加额外的计算量。缺点是没有用到足够底层的特征,在处理小物体(特征一般只出现在较低的特征层)时效果表现得不够好。
- d. FPN的做法,多尺度特征融合。顶层特征通过上采样和低层特征做融合,这样各个不同尺度的特征都具有较强的语义信息。原文FPN骨干网络采用ResNet,另外每层都是独立预测的。
FPN网络结构
FPN输入就是骨干网络每层的输出,但是二者互相独立。 FPN包含两个部分:第一部分是自底向上的过程,第二部分是自顶向下和侧向连接的融合过程。
自底向上的过程:现代的CNN网络一般都是按照特征图大小划分为不同的stage(特征图分辨率相同的所有卷积层归类为一个stage),每个stage之间特征图的尺度比例相差为2。在FPN中,每个stage对应了一个特征金字塔的级别(level),并且每个stage的最后一层特征被选为对应FPN中相应级别的特征。以ResNet为例,选取conv2、conv3、conv4、conv5层的最后一个残差block层特征作为FPN的特征,记为{C2、C3、C4、C5}。这几个特征层相对于原图的步长分别为4、8、16、32。
自顶向下过程:通过上采样(up-sampling)的方式将顶层的小特征图(例如20)放大到上一个stage的特征图一样的大小(例如40)。这样的好处是既利用了顶层较强的语义特征(利于分类),又利用了底层的高分辨率信息(利于定位)。上采样的方法可以用最近邻差值实现。
侧向连接:类似于残差网络的侧向连接结构,使高层语义特征和底层的精确定位能力结合。侧向连接将上一层经过上采样后和当前层分辨率一致的特征,通过相加的方法进行融合。这里为了修正通道数量,相加前会二者都会进过一次1×1的卷积。相加后的结果进行3×3卷积作为最终FPN网络的输出(P2、P3、P4、P5)。
简单概括来说就是:自下而上,自上而下,横向连接和卷积融合
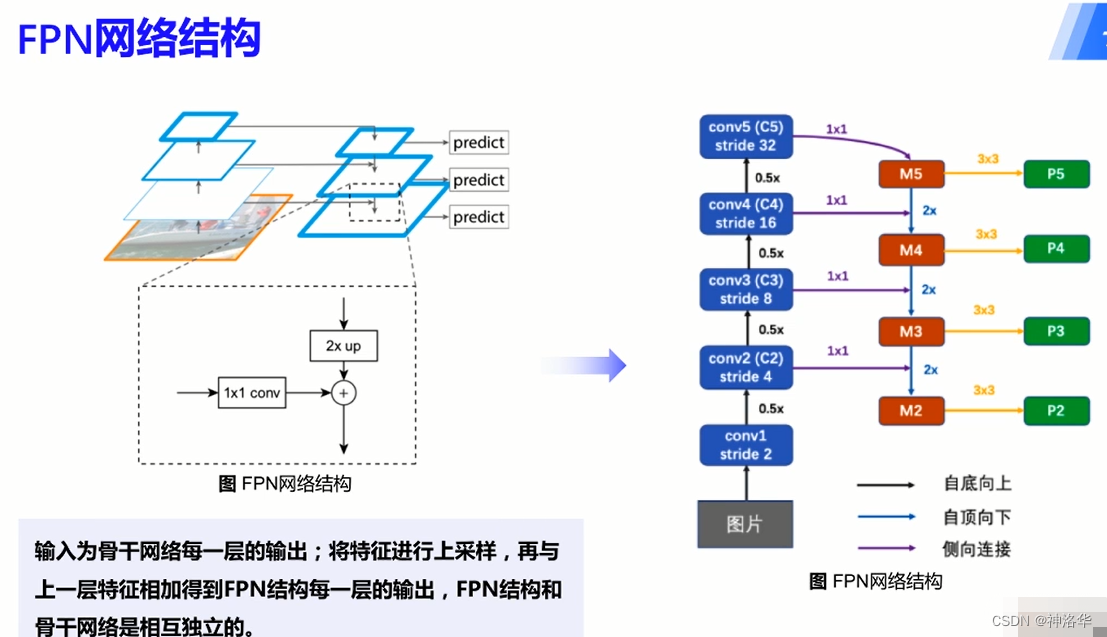
3.1.2 FPN在Faster-RCNN中的实现
FPN在
Faster-RCNN加入FPN后出现变化(RPN和 RoI Align两处不同)
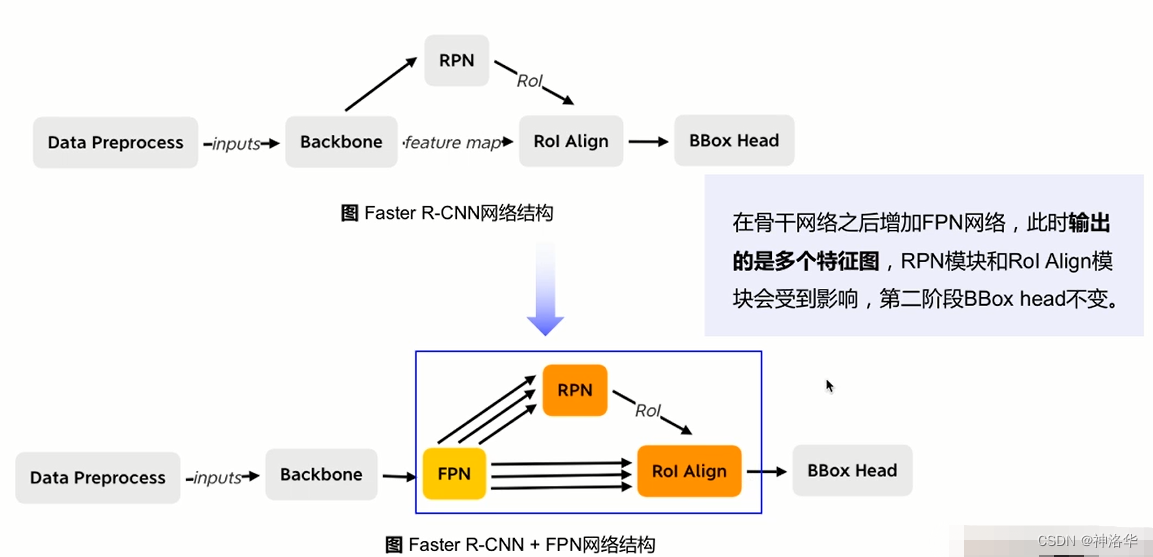
FPN下的RPN网络
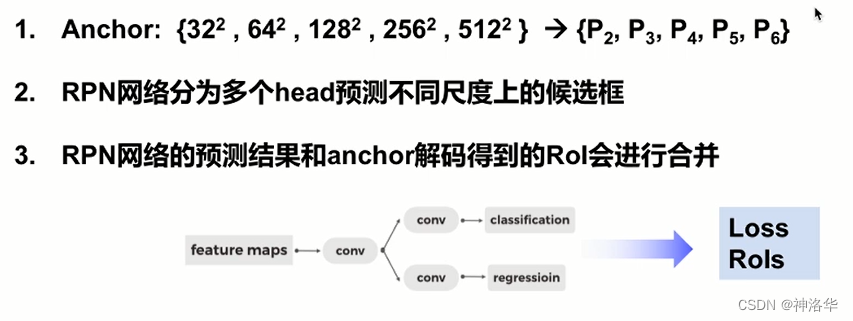
- Anchor
- 原先Faster-RCNN中Anchor是在一张特征图上采样得到的。每个像素点选择不同尺寸和高宽比的Anchor(比如 yml配置文件中的 anchor_sizes: [32, 64, 128, 256, 512],aspect_ratios: [0.5, 1.0, 2.0])。
- FPN输出不同尺度的特征图,这样就可以将面积不同的Anchor分配到不同尺度的特征图上,而高宽比不变。比如FPN输出P2只生成32大小的Anchor:{ P 2 , P 3 , P 4 , P 5 , P 6 P_{2},P_{3},P_{4},P_{5},P_{6} P2,P3,P4,P5,P6} → A n c h o r rightarrow Anchor →Anchor{ 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 32^{2},64^{2},128^{2},256^{2},512^{2} 322,642,1282,2562,5122}。(P6是P5下采样得到的)
- 后续Anchor和真实框做正负样本匹配、采样、监督信息分配,和之前一样。
- RPN为多个head预测不同尺度上的候选框
- 之前Faster-RCNN中,RPN网络输入一张特征图,经过3×3卷积,再分别经过1×1卷积得到分类分支和回归分支。然后计算loss和输出候选框RoI。
- 加入FPN后,RPN输入多个尺度的特征图,这样就需要用多个head预测不同尺度上的候选框。不同的head之间权重共享(作者也做了不共享权重的实验,发现最终结果的精度近似,说明FPN产生的不同尺度的特征图具有相似的信息)
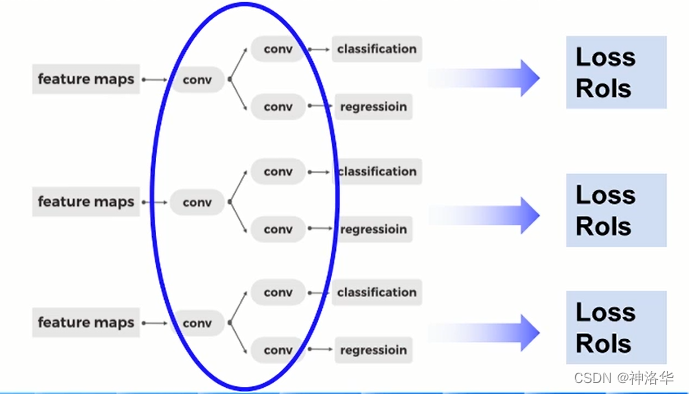
- 不同head输出的RoI进行合并。在FPN结构下,每个head的预测结果和Anchor解码都会输出候选框RoI。最终会将这些RoI进行合并。合并时根据候选框的分数进行排序,取top_k个(比如2000个)输入下一阶段。
FPN结构下的 RoI Align
RoI Align:是候选框RoI在特征图上进行特征抽取的过程,使用双线性插值的方法代替坐标取整的过程。
RoI Align输入是RPN阶段输出的候选框RoIs,还有FPN结构下的输出的多层特征(比如(P2、P3、P4)。之前只有一张特征图,现在就需要将RoIs分配到不同层级特征图上,然后不同层级分别做自己的RoI Align,最终输出的特征进行合并。RoIs分配方法如下:(最终大尺寸的RoI分配到深层去学习,小尺寸的RoI分配到浅层去学习)
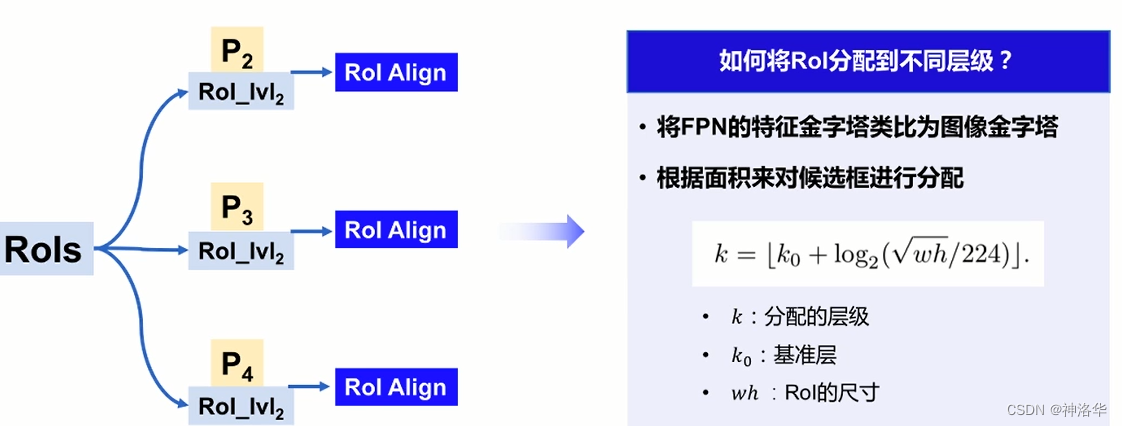
224的由来:图片分类中,一般网络输入尺寸大小是224×224,这里把RoI类比为分类的大小,在此基础上做比较。
FPN模型效果
下图学习策略的1×、2×表示迭代次数,比如分别迭代9w次和18w次。
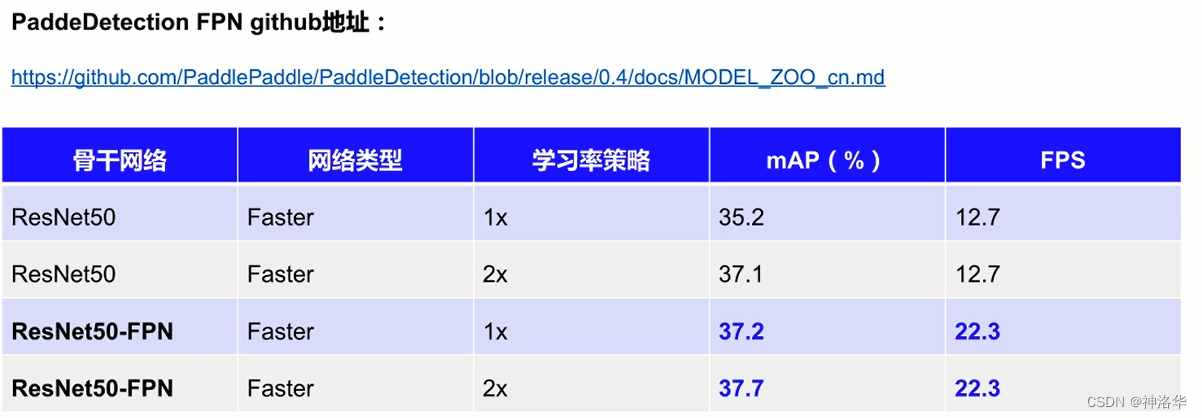
从上图可以看到,Faster-RCNN加入FPN后,精度和预测速度都提高了。精度提升是因为二者在RoI Align之后的一系列卷积、池化操作是不同的,RPN部分的通道数也是不同的。
3.1.3 FPN的继续优化
参考《目标检测中的各种FPN》
-
单向融合:自上而下单向融合的FPN,是当前物体检测模型的主流融合模式。如我们常见的Faster RCNN、Mask RCNN、Yolov3、RetinaNet、Cascade RCNN等。
-
简单双向融合:PANet是第一个提出从下向上二次融合的模型,并且PANet就是在Faster/Master/Cascade RCNN中的FPN的基础上,简单增了从下而上的融合路径,PANet的提出证明了双向融合的有效性。
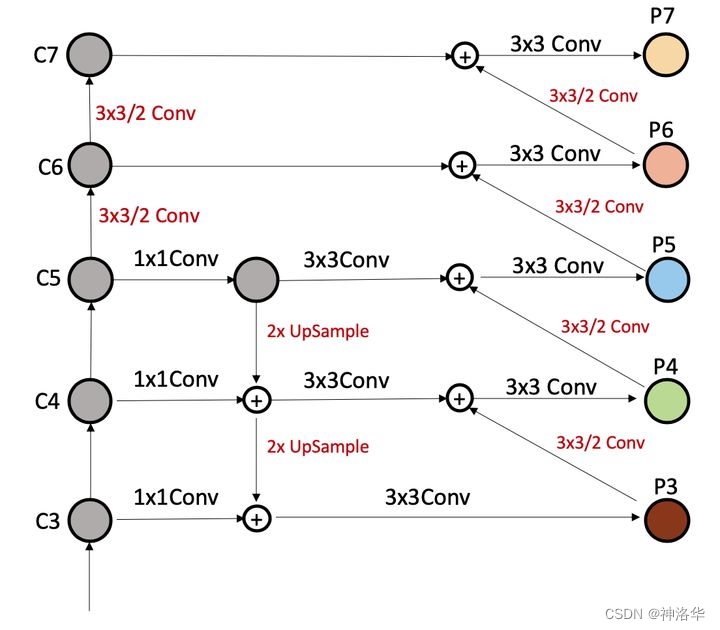
-
复杂双向融合:PANet的双向融合比较简单,ASFF、NAS-FPN、BiFPN等提出更复杂的双向融合。
3.2 Cascade RCNN(三个检测头级联调优)
3.2.1 RPN生成的Rol和真实框的loU阈值分析
loU表示两个检测框之间的重叠程度,目标检测中用来评价预测框的质量。CascadeR-CNN重点分析了FasterR-CNN中RoI和真实框的loU匹配过程。
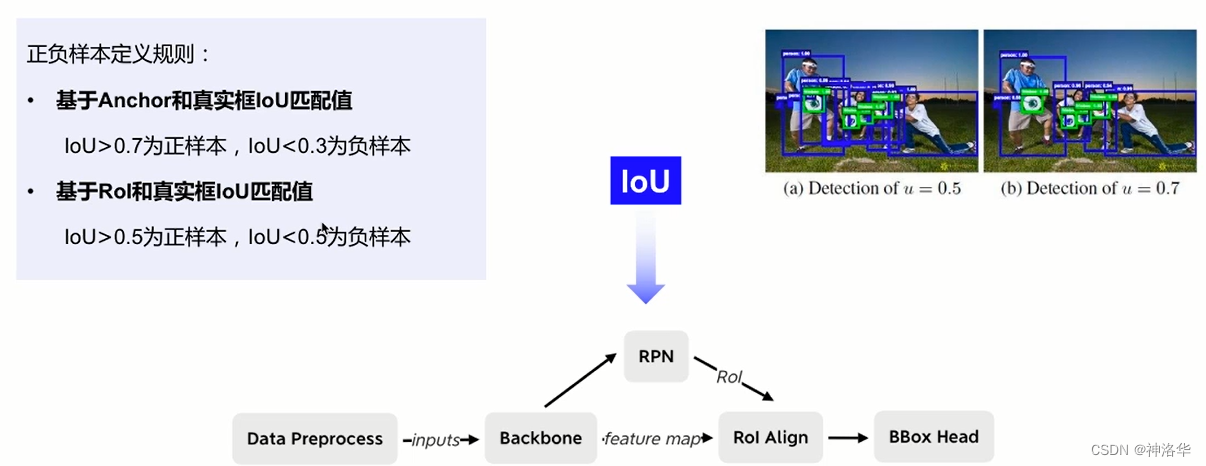
RoI和真实框的loU匹配过程中,IoU阈值是0.5,这个阈值会不会太低而带来噪声,即产生较多的误检框。那么一个直接的想法是阈值提高到0.7,这样第二阶段RoI质量会高很多。但是这样做最终检测性能反而会下降。这是因为:
- IoU阈值提高,用于训练的正样本会呈指数级减少,第二阶段训练会过拟合
- IoU阈值提高回导致输入的候选框和设定的阈值不匹配。
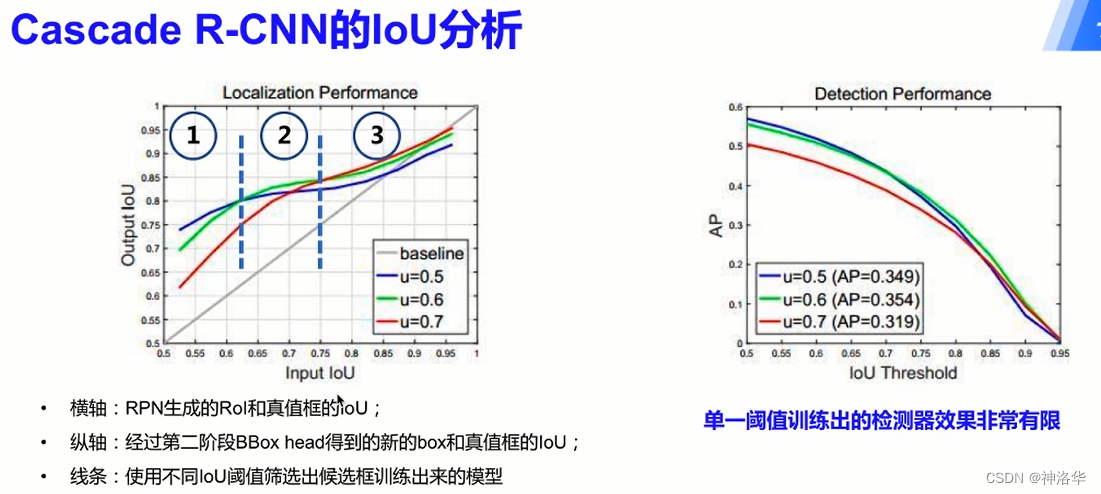
-
左上图横轴表示了RPN生成的RoI质量,纵轴表示了二阶段BBox head输出的最终预测框的质量。
- baseline表示不对第二阶段的RoI做调整。输入框和输出框质量是一样的。
- 区域➀:RPN生成的RoI质量比较低的时候,阈值取0.5效果最好(y值最大,蓝色线)
- 区域➁:RPN生成的RoI与真实框的IoU在大概0.62到0.75之间的时候,阈值取0.6效果最好(绿色线)
- 区域➂:RPN生成的RoI质量比较高的时候,阈值取0.7效果最好(红色线)
- 结论:RPN生成的Rol和真实框的loU,和训练器训练用的loU阈值较为接近时,训练器的性能最优。
-
右上图可以看出,单阈值训练的检查器性能有限,且单纯的一直增加loU阈值,检测器效果变差。所以考虑引入多个head对阈值进行调整。
3.2.2 FasterR-CNN的不同改进
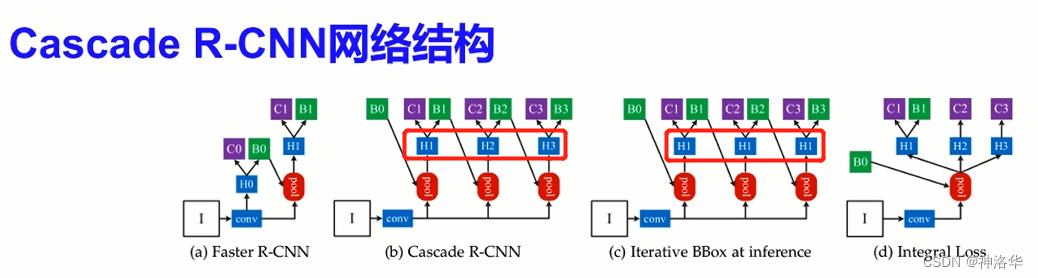
不同改进方式:
- IterativeBBox :同上,但是三次微调时的权重共享。问题是不同微调阶段得到的RoI质量不同,这样共享的权重就没办法满足不同阶段输入的变化了(微调一次的质量低一些,第三次高一些)
- Integral Loss :三次微调并联完成,共用同样的Rol,设置不同loU阈值引出三个分支。问题是输入的RoI质量分布也不均匀。一般低质量的Rol较多,会分到低loU阈值的分支;而高质量的Rol较少,这个分支就容易过拟合。
- CascadeR-CNN:对box三次微调,每次BBoxhead的偏移量和 Rol解码作为下个阶段的Rol输入(之前只微调一次),作者最终选择这种结构,通过级联的方式不断地提高预测框的质量(循序渐进)。
- CascadeR-CNN预测时,选第三次微调的偏移量,对RoI修正之后得到预测框。而类别是三次检测头的分类分支,预测结果取平均(后续有改进)。
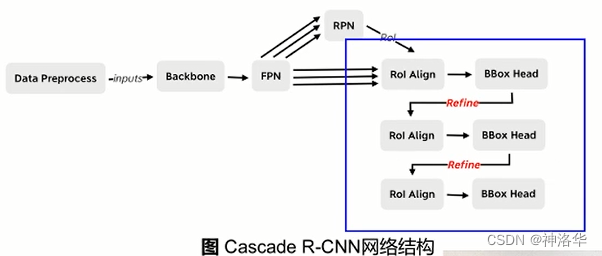
最终CascadeR-CNN结构图如下,BBox Head输出的偏移量应用到RPN输出的RoI上得到微调后的RoI,进入到下一次正负样本选择、RoI Align抽取等等。总共做三次微调得到最终的预测框。每次微调预测框质量都会提升,这样下一个检测头的loU阈值提高了,也不会刷下太多的正样本,这样保证了每个检测头都有足够的训练样本,避免了过拟合。
*CascadeR-CNN模型效果(coco2017数据集,FPS是单卡V100预测速度)
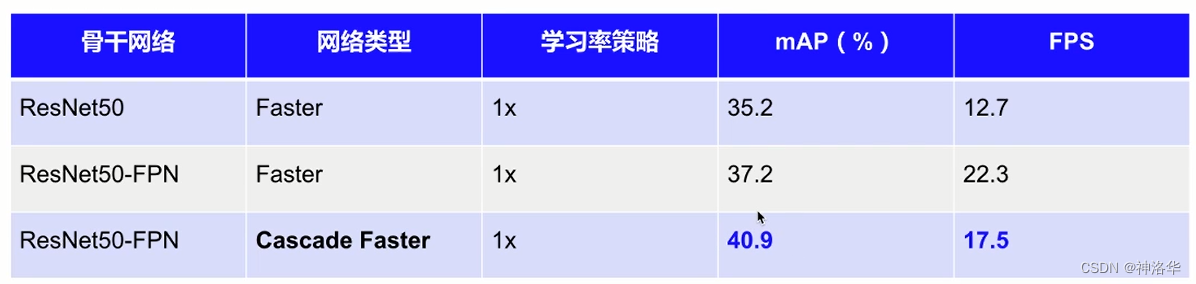
CascadeR-CNN在检测头部分是原来三倍的计算量,所以训练和推理速度下降了。
3.3 Libra R-CNN
对于检测中的不平衡问题,作者从三个方法来进行讨论:
- Feature level→提取出的不同level的特征图特征,怎么才能真正地充分利用?→FPN特征融合
- Sample level→采样的候选区域是否具有代表性?→采样策略
- Objective level→损失函数能不能引导目标检测器更好的收敛→Loss
3.3.1 LibraR-CNN的特征融合
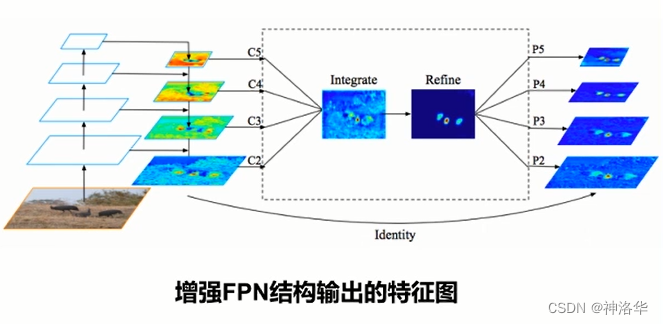
- Rescale:将RPN输出的不同层级的特征图,通过差值或下采样的方法统一到同一层级上(默认C4层)
- Integrate:将统一后的特征图进行特征融合,融合方式就是平均: C = 1 L ∑ l m i n l m a x c l C=frac{1}{L}sum_{l_{min}}^{l_{max}}c_{l} C=L1∑lminlmaxcl
- Refine:使用non-local结构对融合特征进一步加强
- Strengthen:将优化后的特征与不同层级上的原始特征加和,得到增强FPN结构的输出。
3.3.2 LibraR-CNN的采样策略
BBox Head训练阶段采样策略如下:

- 从正样本中随机采样,可能造成正样本的类别不平衡
- 从负样本中随即采样,可能造成负样本IoU数值分配不平衡(比如负样本很多,随机采样会发现采到的负样本和真实框的IoU大部分集中在0-0.005这个很小的区间,这是因为负样本的IoU分布不均匀。太多IoU值很低、质量很差的负样本会干扰训练)
针对两种不平衡,作者采用下面两种方式:
- 正样本分类分别采样
- 负样本大于阈值的分桶采样,如果某个桶采样数不够,用低于阈值的样本随机采样补齐

3.3.3 LibraR-CNN的回归损失函数
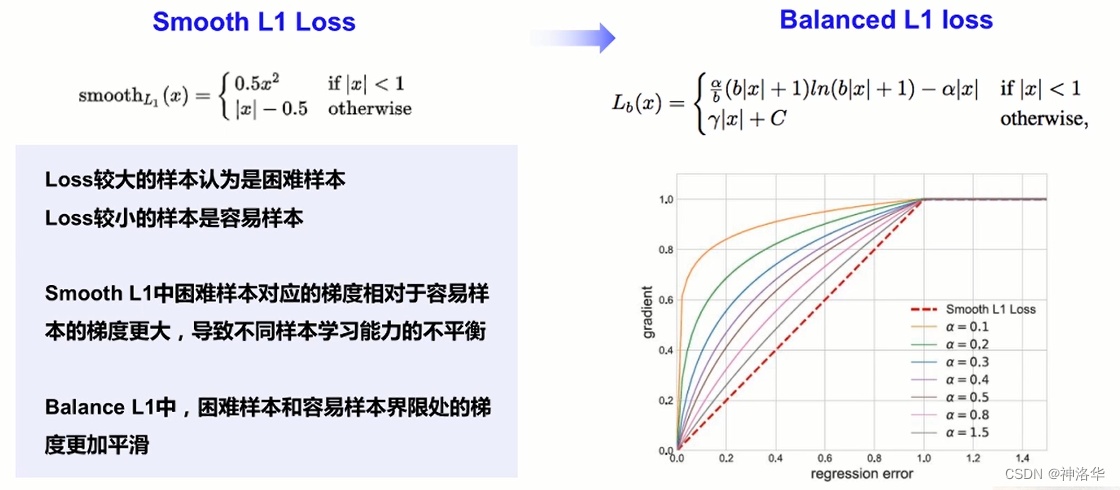
右上图红色虚线表示困难样本梯度对应容易样本梯度的变化很大,这样不同样本学习能力不平衡。
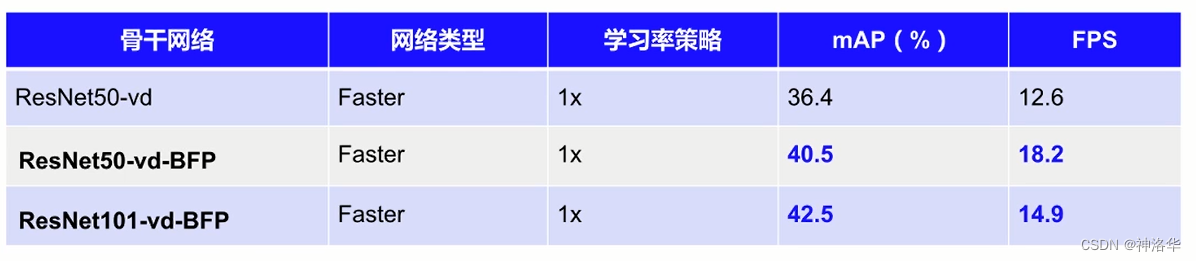
LibraR-CNN模型效果:
3.4 PaddleDetection两阶段检测模型优化策略
3.4.1 服务器端优化策略
基线方案:ResNet50-vd+FPN+CascadeRCNN
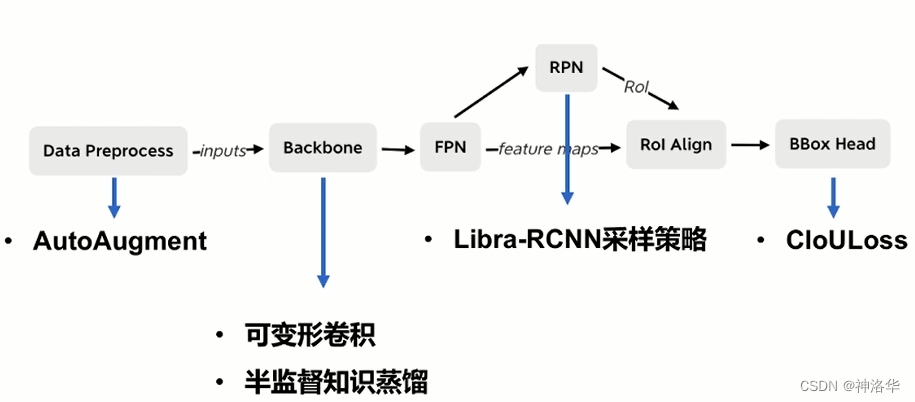
- 数据预处理
- AutoAugment:自动寻找数据预处理策略。不同的视觉任务、不同数据集的特点是不一样的,这样数据增强的策略也不一样。AutoAugment通过强化学习搜索出目标任务有哪些常用的预处理操作和顺序,找出最有效的策略。
- 其它优化方式。
- backbone部分
- 可变形卷积:让卷积核多学习一个偏移量,这样卷积核就可以落到我们更感兴趣的区域当中
- 半监督知识蒸馏:应用在图像分类上,可以让ResNet50-vd在ImageNet上精度提高3.27%,这样也有助于检测任务。
- RPN部分
- LibraR-CNN采样策略
- BBox Head部分
- 引入CIoULoss:IoULoss是直接将预测框和真实框的IoU的值直接作为回归分支的Loss。CIoULoss在此基础上考虑了物体之间中心点的距离和它们的长宽比,这样可以更有效的表示预测结果的质量。
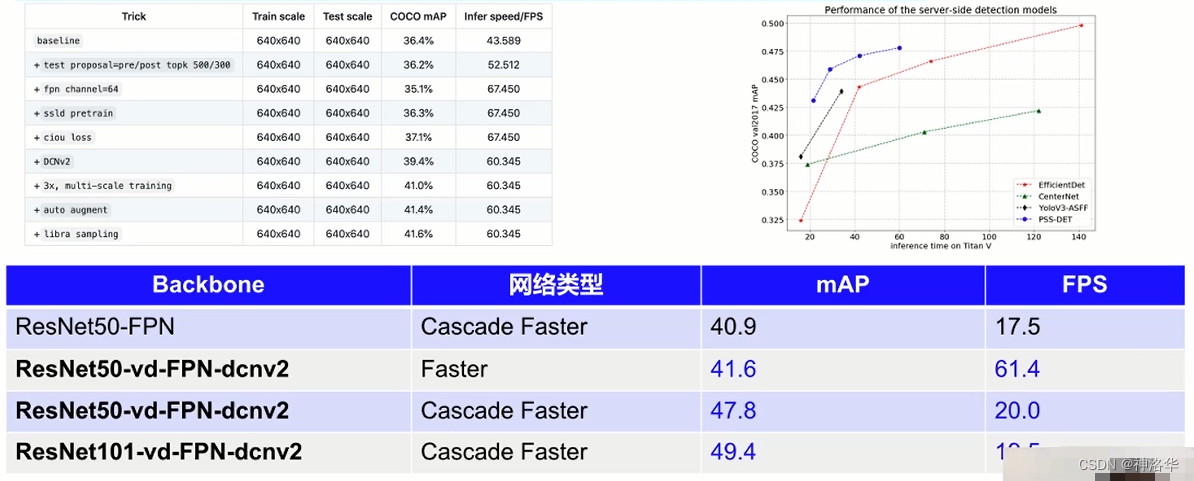
结合以上优化策略,飞桨提供了一种面向服务器端实用的目标检测方案PSS-DET(Practical Server Side Detection)。基于COCO2017目标检测数据集,V100单卡预测速度为为61FPS时,COCO mAP可达41.6%;预测速度为20FPS时,COCO mAP可达47.8%。
服务器端模型优化效果:(以标准的Faster RCNN ResNet50_vd FPN为基准)
3.4.2 移动端优化
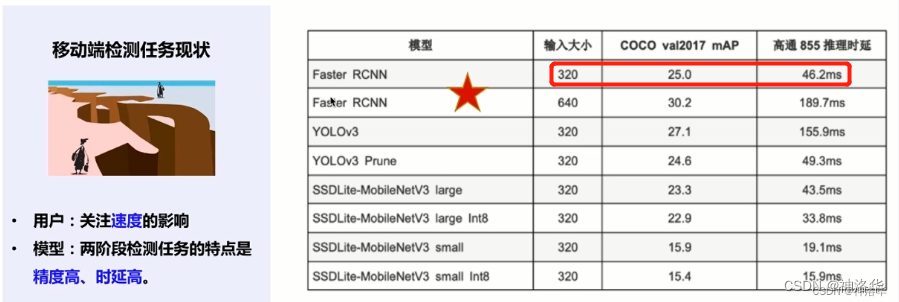
移动端更主要的是关注目标检测模型的推理速度。二阶段模型比单阶段模型速度更慢,但是其精度更高,特别是检测尺寸小的物体时。所以还是考虑在二阶段模型基础上优化其速度。下图是PaddleDetection各模型在移动端推理速度对比。可以看出输入大小是320时,Faster RCNN推理速度不输给一些单阶段模型。
移动端优化策略
基线方案:MobileNetv3+FPN+CascadeRCNN
- AutoAugment数据预处理
- 半监督知识蒸馏提升骨干网络
- DataPreprocess
- 微调FPN结构
- BalanceL1Loss
- 调整学习率策略:使用余弦学习率衰减策略替代阶梯性学习率衰减策略,提高精度和鲁棒性。
- 调整FPN部分的通道数,减少RPN生成的候选框个数
微调FPN结构

- 减少FPN输出层:如上图最左侧所示,原始FPN是最终输出五个特征图P2到P6。为了提升速度,减少输出层,将其缩减为P2到P4。此时发现RPN阶段输出的候选框,对大尺寸物体的召回率较低。
- 考虑到第一点的问题,对FPN模块添加下采样(P4经过卷积池化,直接下采样得到P5和P6。比之前上采样、加和等简化很多)。这样更多的层级有利于召回更多正样本。上表第二行可见大尺寸物体召回率提升明显。
移动端模型优化效果:

3.5 工业应用:铝压铸件质检
工业质检背景
铝压铸方式加工的产品统称铝压铸件,离变壳体就是铝压铸成型的,可用于发动机的机壳。离变壳内流动着汽油,所以其检测是汽车行业重中之重。如果壳体有缺陷,就可能造成发动机漏油事故。


铝压铸件视觉检测难点:

由检测框的面积来对缺陷大小进行评定。
铝压铸件视觉检测方案:
- 针对缺陷大小,采用精准标注,利用边界框的回归来实现缺陷大小的计量
- 采用两阶段算法FasterR-CNN,利用ResNet101+FPN的方式,实现了对各个尺度缺陷的检测。
- 本项目中,单张图像的图片大小为40963000,入网尺寸为20481500,降低了resize缩放对小目标缺陷精度的影响。
- 模型的训练和部署使用Tesla4显卡,最终被部署在一个windows环境下,采用c#调用C++预测程序(dll)方式实现,实现了高效的检测。
- 最终检测精度为95%,预测速度为200mS

最后
以上就是暴躁洋葱最近收集整理的关于目标检测打卡营上:VOC/COCO数据集、评测指标&Faster R-CNN等两阶段检测算法的全部内容,更多相关目标检测打卡营上:VOC/COCO数据集、评测指标&Faster内容请搜索靠谱客的其他文章。








发表评论 取消回复