文章目录
- 1. COCO标注数据结构
- 2. 代码
在 COCO 官方数据集里,train 的数据集标注有 6 个 .json 文件,captions 打头的两个是用于 image caption 的,person_keypoints 打头的两个是用于 object keypoint 的,这里我需要的是 image segmentation,所以只说怎么做 instances 的 json 文件啦~
1. COCO标注数据结构
instances_train2017.json 和 instances_val2017.json 结构是一样的,一个用于训练一个用于测试。都符合下面的大框架:
{
"info": info, # dict
"licenses": [license], # list[dict]
"images": [image], # list[dict]
"annotations": [annotation], # list[dict]
"categories": [category] # list[dict]
}
其中:info、license 的结构如下
info{ # 数据集描述
"year": int,
"version": str,
"description": str,
"contributor": str,
"url": str,
"date_created": datetime,
}
license{
"id": int,
"name": str,
"url": str,
}
前面两个都没什么影响,主要在于 image,annotations 和 categories:
# 图片数据,id, file_name, width, height比较重要
"image": [
{
"id": int, # 图片id,每张图片id唯一
"width": int,
"height": int,
"file_name": str,
"license": int,
"flickr_url": str,
"coco_url": str,
"date_captured": datetime,
},
...
],
# 数据类别描述
"categories": [
{
'id': 1, # 对应在mask里的像素值
'name': 'person', # 类别名称
'supercategory': 'person', # 父类别
},
{
'id': 2,
'name': 'vehicle',
'supercategory': 'bicycle',
},
{
'id': 3,
'name': 'vehicle',
'supercategory': 'car',
},
...
],
# 数据标注
"annotation": [
{
"id": int, # 对象id,一张图片可能有多个对象
"image_id": int, # 图片id,和image中的id对应
"category_id": int, # 类别id,和categories中的id对应
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
},
...
]
annotations 中 segmentation 的格式取决于这个实例是单个对象还是一组对象。如果是单个对象,那么 iscrowd = 0,segmentation 使用 polygon 格式。但是这个对象可能被其他东西遮挡,导致分成了几个部分,此时需要用多个 polygon 来表示,所以 segmentation 其实是两层的列表。如果是一组对象,那么 iscrowd = 1,此时 semgentation 使用的就是 RLE 格式。
segmentation 使用 polygon 格式:
"segmentation": [ # 对象的轮廓点坐标
[
x1,y1,
x2,y2,
...
xn,yn
],
...
],
2. 代码
其实创建自己数据集标注的话,不用那么麻烦,只要写入一些我们训练必须的数据即可。我自己做分割实际只写了 images,annotations 和 categories。
框架是这样的:大字典里包含 3 个键 images,annotations 和 categories,每个键的值都是一个列表,列表里又包含了 n 个字典。
对于 images 来说,列表中的字典个数其实就是训练数据集图片的数量。对于 annotations ,列表中字典的个数是训练数据集中对象的个数,因为一张图像中可能包括多个对象。而 categories 的列表中字典个数等于你的数据集的类别个数,其中 categories id 就是类别在 mask 上对应的像素值。
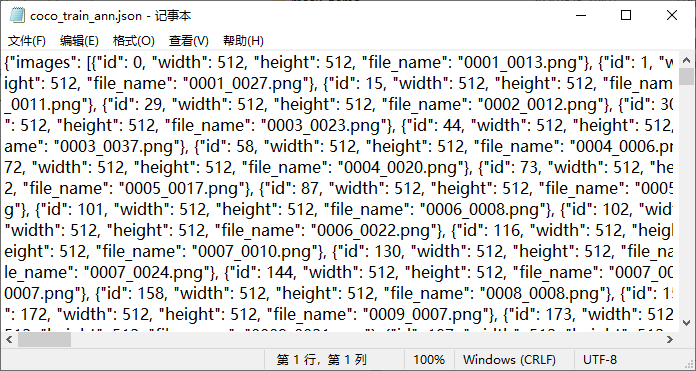
{
"images": [{"id": 0, "width": 23, "height": 18, "file_name": "0001.png"}, {}, {}, ..., {}],
"annotations": [{"id": 0, "image_id": 0, "segmentation": [[...], [...], ..., []], "category_id": 1, "iscrowd": 0, "area": 8996.0, "bbox": [5, 366, 187, 126]}, {}, ..., {}],
"categories": [{"id": 1, "name": "car"}, {}, ..., {}]
}
由于 matlab 提取目标 polygon 很方便,所以决定“曲线救国”,先用 matlab 提取好 polygon,再读取来生成 annotation 啦,代码写的仓促,决定优化一下再上传啦~
补充很关键的一点:关于图像坐标系统和矩阵坐标系统的关系
图像坐标系统:原点 (0,0) 在左上角,向右和向下分别代表 x 和 y 轴,(x, y) 分别是 (纵轴, 横轴)。这种模式常见于 OpenCV 和各种公开数据集的 json 标注文件(VOC、COCO 等)。

矩阵坐标系统:当图像以矩阵坐标系统表示时,坐标 (x, y) 代表的其实是矩阵的 (行, 列),也就是 (横轴, 纵轴)。这种模式常见于 Python 中 Numpy 和 Matlab 编程,因为它们都将图像按照矩阵来处理。

在准备数据时,注意两者的区别,要转换也很简单,x 和 y 的位置进行对调即可。
最后
以上就是无情山水最近收集整理的关于COCO数据集标注 & 代码1. COCO标注数据结构2. 代码的全部内容,更多相关COCO数据集标注内容请搜索靠谱客的其他文章。








发表评论 取消回复