文章目录
- 前言
- 一、解决问题
- 二、基本原理
- 三、改进办法
前言
作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!关注免费领取深度学习算法学习资料!
一、解决问题
本文尝试引入一种结合道路上下文信息与全阶段特征融合的RCFSNet算法中的协同双注意力模块,能够在遮挡场景中表现出色,尝试解决目标检测中的遮挡问题。
二、基本原理
原文链接

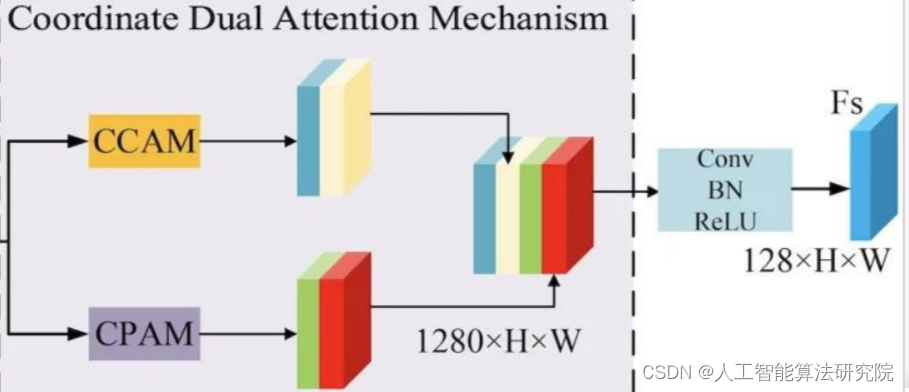
协同双注意力机制由协同通道注意力机制和协同空间注意力机制组成。在协同通道注意力中,融合特征图首先经过池化核大小为(1,W)与(H,1)的池化操作处理,随后采用reshape操作将特征图变形为H×320与W×320的特征图,特征图被输出通道数为1的1D卷积核学习相邻通道的依赖关系,随后采用变形操作将特征图变形为320×1×1的特征图。分别采用sigmoid函数获取特征图结合宽度、高度信息的通道权重,输入特征图结合权重生成两个通道特征加权的特征图。
在协同空间注意力机制中,首先采用通道平均池化和最大池化操作压缩通道特征信息,随后采用拼接与卷积操作融合特征图。分别采用卷积核大小为(1,W)与(H,1)的卷积操作压缩特征图的空间信息,随后采用expand操作恢复特征图尺寸到1×H×W。采用sigmoid函数获取特征图在宽度和高度维度的空间权重,输入特征图结合权重生成两个空间特征加权的特征图。
将协同双注意力机制生成的融合特征图采用拼接操作进行融合,随后采用输出通道数为128的1×1卷据核生成补充的道路特征图,其中128对应编码器特征图E3的通道数。
三、改进办法
部分代码如下:
class CDAM2(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, k_size=9):
super(CDAM2, self).__init__()
self.h = 256
self.w = 256
self.relu1 = nn.ReLU()
self.avg_pool_x = nn.AdaptiveAvgPool2d((self.h, 1))
self.avg_pool_y = nn.AdaptiveAvgPool2d((1, self.w))
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1 = nn.Conv1d(256, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.conv2 = nn.Conv1d(256, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.conv11 = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.conv22 = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
self.convout = nn.Conv2d(64 * 5 * 4, 64*5, kernel_size=3, padding=1, bias=False)
self.conv111 = nn.Conv2d(in_channels=64*5*2, out_channels=64*5*2, kernel_size=1, padding=0, stride=1)
self.conv222 = nn.Conv2d(in_channels=64*5*2, out_channels=64*5*2, kernel_size=1, padding=0, stride=1)
# 横卷
self.conv1h = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=(self.h, 1), padding=(0, 0), stride=1)
# 竖卷
self.conv1s = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=(1, self.w), padding=(0, 0), stride=1)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d) or isinstance(m, nn.Conv1d):
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
# x: input features with shape [b, c, h, w]
n, c, h, w = x.size()
y1 = self.avg_pool_x(x)
y1 = y1.reshape(n, c, h)
y1 = self.sigmoid(self.conv11(self.relu1(self.conv1(y1.transpose(-1, -2)))).transpose(-1, -2).reshape(n, c, 1, 1))
y2 = self.avg_pool_y(x)
y2 = y2.reshape(n, c, w)
# Two different branches of ECA module
y2 = self.sigmoid(self.conv22(self.relu1(self.conv2(y2.transpose(-1, -2)))).transpose(-1, -2).reshape(n, c, 1, 1))
yac = self.conv111(torch.cat([x * y1.expand_as(x), x * y2.expand_as(x)],dim=1))
avg_mean = torch.mean(x, dim=1, keepdim=True)
avg_max,_ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.cat([avg_max, avg_mean], dim=1)
y3 = self.sigmoid(self.conv1h(avg_out))
y4 = self.sigmoid(self.conv1s(avg_out))
yap = self.conv222(torch.cat([x * y3.expand_as(x), x * y4.expand_as(x)],dim=1))
out = self.convout(torch.cat([yac, yap], dim=1))
return out
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
YOLO系列算法改进方法 | 目录一览表
????????☁️1. 添加SE注意力机制
????????☁️2.添加CBAM注意力机制
????????☁️3. 添加CoordAtt注意力机制
????????☁️4. 添加ECA通道注意力机制
????????☁️5. 改进特征融合网络PANET为BIFPN
????????☁️6. 增加小目标检测层
????????☁️7. 损失函数改进
????????☁️8. 非极大值抑制NMS算法改进Soft-nms
????????☁️9. 锚框K-Means算法改进K-Means++
????????☁️10. 损失函数改进为SIOU
????????☁️11. 主干网络C3替换为轻量化网络MobileNetV3
????????☁️12. 主干网络C3替换为轻量化网络ShuffleNetV2
????????☁️13. 主干网络C3替换为轻量化网络EfficientNetv2
????????☁️14. 主干网络C3替换为轻量化网络Ghostnet
????????☁️15. 网络轻量化方法深度可分离卷积
????????☁️16. 主干网络C3替换为轻量化网络PP-LCNet
????????☁️17. CNN+Transformer——融合Bottleneck Transformers
????????☁️18. 损失函数改进为Alpha-IoU损失函数
????????☁️19. 非极大值抑制NMS算法改进DIoU NMS
????????☁️20. Involution新神经网络算子引入网络
????????☁️21. CNN+Transformer——主干网络替换为又快又强的轻量化主干EfficientFormer
????????☁️22. 涨点神器——引入递归门控卷积(gnConv)
????????☁️23. 引入SimAM无参数注意力
????????☁️24. 引入量子启发的新型视觉主干模型WaveMLP(可尝试发SCI)
????????☁️25. 引入Swin Transformer
????????☁️26. 改进特征融合网络PANet为ASFF自适应特征融合网络
????????☁️27. 解决小目标问题——校正卷积取代特征提取网络中的常规卷积
????????☁️28. ICLR 2022涨点神器——即插即用的动态卷积ODConv
????????☁️29. 引入Swin Transformer v2.0版本
????????☁️30. 引入10月4号发表最新的Transformer视觉模型MOAT结构
????????☁️31. CrissCrossAttention注意力机制
????????☁️32. 引入SKAttention注意力机制
????????☁️33. 引入GAMAttention注意力机制
????????☁️34. 更换激活函数为FReLU
????????☁️35. 引入S2-MLPv2注意力机制
????????☁️36. 融入NAM注意力机制
????????☁️37. 结合CVPR2022新作ConvNeXt网络
????????☁️38. 引入RepVGG模型结构
????????☁️39. 引入改进遮挡检测的Tri-Layer插件 | BMVC 2022
????????☁️40. 轻量化mobileone主干网络引入
????????☁️41. 引入SPD-Conv处理低分辨率图像和小对象问题
????????☁️42. 引入V7中的ELAN网络
????????☁️43. 结合最新Non-local Networks and Attention结构
????????☁️44. 融入适配GPU的轻量级 G-GhostNet
????????☁️45.首发最新特征融合技术RepGFPN(DAMO-YOLO)
最后
以上就是虚拟小懒猪最近收集整理的关于【YOLOv7/v5系列算法改进NO.46】融合DLinkNet模型中协同双注意力机制CDAM2前言一、解决问题二、基本原理三、改进办法的全部内容,更多相关【YOLOv7/v5系列算法改进NO内容请搜索靠谱客的其他文章。








发表评论 取消回复