拼音输入法-AI
一、 算法介绍与编程实现
算法基于二元字模型,基于隐马尔可夫模型进行实现。
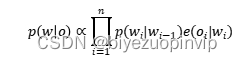

基于以上算式,依据拼音序列推断可能性最大的的中文字符串,即求解以下问题:

- 最终得到:
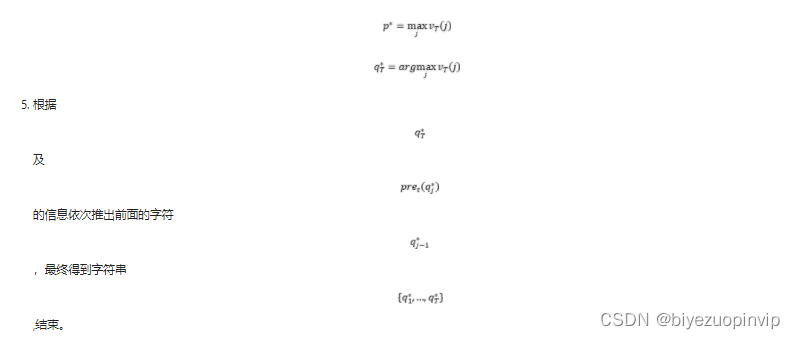
程序见 src 文件夹,其中 data_prep.py 将拼音字符表、二元字统计等内容以字典形式存储到 pkl 文件中;而 hmm.py 中的 predict 函数调用这些数据计算转移概率
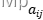
等参数,在此基础上按照 Viterbi 算法进行中文字符串的预测。
二、 效果展示
用网络学堂发布的“拼音输入法测试样例.txt”进行测试,设置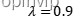
,得到字、句准确率如下。
| 测试字数 | 3643 |
|---|---|
| 测试句数 | 365 |
| 字准确率 | 0.7977 |
| 句准确率 | 0.3205 |
效果好的例子:
ren gong zhi neng ji shu fa zhan xun meng
人工智能技术发展迅猛
人工智能技术发展迅猛
jin nian qing kuang bu tai hao
今年情况不太好
今年情况不太好
ji dong che jia shi yuan pei xun shou ce
机动车驾驶员培训手册
机动车驾驶员培训手册
ni zai gan shen me a tuan zhang
你在干什么啊团长
你在干什么啊团长
效果不好的例子:
① 新闻中语料的频次不同于现实中的常用语:
wo qu gei ni mai yi ge ju zi
我去给你买一个橘子
我去给你买一个巨资
ta yang le yi zhi qing wa dang chong wu
他养了一只青蛙当宠物
他养了一致青瓦当宠物
② 新闻语料库可能未覆盖一些专有名词
wei ji bai ke shi yi ge wang luo bai ke quan shu xiang mu
维基百科是一个网络百科全书项目
违纪伯克是一个网罗伯克全数项目
gei a yi dao yi bei ka bu qi nuo
给阿姨倒一杯卡布奇诺
给阿姨到一杯咖不奇诺
③ 二元字模型只用到上一个字,存在缺陷,可能需要用到三元/四元模型
ni de li jie shi dui de
你的理解是对的
你的理解释对的
④ 对多音字的学习有所欠缺
qing bu yao shu ru qi guai de ju zi
请不要输入奇怪的句子
情不要输入奇怪的车子
综上,可以看出本次使用的模型有两个主要缺陷:
- 只用上一个字进行推断,没有结合前文的信息,因此需要考虑再用三元字模型进行修正。
- 对多音字的处理不当,没有对发射概率进行学习,因此会输出一些不常用的多音字(比如“车(ju1)”)。
这些都是值得改进的地方。此外如果再用一些日常对话的语料库,准确率应该也会有所提升。
三、 参数选择
改变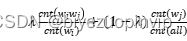
中的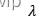
取值,得到准确率如下:
| 字准确率 | 句准确率 | |
|---|---|---|
| 0.6 | 0.7904 | 0.2904 |
| 0.7 | 0.7963 | 0.3014 |
| 0.85 | 0.8002 | 0.3178 |
| 0.9 | 0.7977 | 0.3205 |
| 0.95 | 0.7993 | 0.3205 |
| 1 | 0.8007 | 0.3233 |
可见平滑化处理对于本次学习并没有显著的帮助,而过小时准确率反而会下降.
最后
以上就是勤劳小蝴蝶最近收集整理的关于基于Python实现的拼音输入法AI拼音输入法-AI的全部内容,更多相关基于Python实现内容请搜索靠谱客的其他文章。

![[Python]控制终端输出文字](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)






发表评论 取消回复