文章目录
- 一、哈希表
- 二、unordered_map
- 2.1 初始化
- 2.2 insert 插入元素
- 2.3 元素访问
- 2.4 删除元素 erase
一、哈希表
unordered_map 容器,无序容器的底层实现都采用的是哈希表存储结构,python的字典也是如此。关于哈希表(散列表)可以查看:https://zhuanlan.zhihu.com/p/45430524
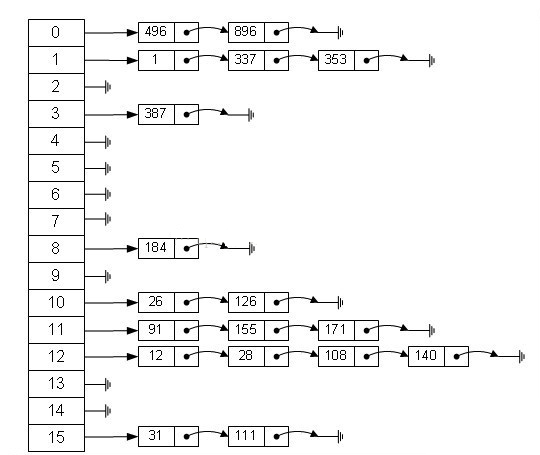
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
当使用无序容器存储键值对时,会先申请一整块连续的存储空间,但此空间并不用来直接存储键值对,而是存储各个链表的头指针,各键值对真正的存储位置是各个链表的节点。
STL 标准库通常选用 vector 容器存储各个链表的头指针。
不仅如此,在 C++ STL 标准库中,将图 中的各个链表称为桶(bucket),每个桶都有自己的编号(从 0 开始)。当有新键值对存储到无序容器中时,整个存储过程分为如下几步:
- 将该键值对中键的值带入设计好的哈希函数,会得到一个哈希值(一个整数,用 H 表示);
- 将 H 和无序容器拥有桶的数量 n 做整除运算(即 H % n),该结果即表示应将此键值对存储到的桶的编号;
- 建立一个新节点存储此键值对,同时将该节点链接到相应编号的桶上。
负载因子(load factor) :哈希表存储结构还有一个重要的属性。该属性同样适用于无序容器,用于衡量容器存储键值对的空/满程序,即负载因子越大,意味着容器越满,即各链表中挂载着越多的键值对,这无疑会降低容器查找目标键值对的效率;反之,负载因子越小,容器肯定越空,但并不一定各个链表中挂载的键值对就越少。
举个例子,如果设计的哈希函数不合理,使得各个键值对的键带入该函数得到的哈希值始终相同(所有键值对始终存储在同一链表上)。这种情况下,即便增加桶数是的负载因子减小,该容器的查找效率依旧很差。
无序容器中,负载因子的计算方法为:
负载因子 = 容器存储的总键值对 / 桶数
默认情况下,无序容器的最大负载因子为 1.0。如果操作无序容器过程中,使得最大复杂因子超过了默认值,则容器会自动增加桶数,并重新进行哈希,以此来减小负载因子的值。需要注意的是,此过程会导致容器迭代器失效,但指向单个键值对的引用或者指针仍然有效。
这也就解释了,为什么我们在操作无序容器过程中,键值对的存储顺序有时会“莫名”的发生变动。
C++ STL 标准库为了方便用户更好地管控无序容器底层使用的哈希表存储结构,各个无序容器的模板类中都提供表所示的成员方法。
| 成员方法 | 功能 |
|---|---|
| bucket_count() | 返回当前容器底层存储键值对时,使用桶的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少个桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的最大负载因子。 |
| rehash(n) | 尝试重新调整桶的数量为等于或大于 n 的值。如果 n 大于当前容器使用的桶数,则该方法会是容器重新哈希,该容器新的桶数将等于或大于 n。反之,如果 n 的值小于当前容器使用的桶数,则调用此方法可能没有任何作用。 |
| reserve(n) | 将容器使用的桶数(bucket_count() 方法的返回值)设置为最适合存储 n 个元素的桶数。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
二、unordered_map
unordered_map 包含的是有唯一键的键/值对元素。容器中的元素不是有序的。元素的位置由键的哈希值确定,因而必须有一个适用于键类型的哈希函数。如果用类对象作为键,需要为它定义一个实现了哈希函数的函数对象。因为键可以不通过搜索就访问无序 map 中的对象,所以可以很快检索出无序 map 中的元素。
unordered_map 必须能够比较元素是否相等。当容器中有相同的键时,对从包含多个元素的格子中检索到的元素进行确认和选择很有必要。容器默认会使用定义在 fimctional 头文件中的equal_to 模板。它会用 == 运算符来比较元素,所以当键相等时,容器会认为它们是相同的,这一点和 map 容器不同,map 容器使用的是等价。如果使用的键是没有实现 operator=() 的类类型,那就必须提供一个函数对象来比较键。
2.1 初始化
版式:td::unordered_map<T, T>
-
声明并直接初始化
std::unordered_map<std::string, size_t> people {{"A",11}, {"B", 22}, {"C", 33}};
这样就生成了一个包含 pair<string,size_t> 元素的容器,并用初始化列表中的元素对它进行了初始化。容器中格子的个数是默认的,它使用 equal_to() 对象来判断键是否相等。它会用定义在 string 头文件中的 hash 来对 string 进行哈希。如果没有提供初始值,默认的构造函数会生成一个空容器,它有默认个数的格子。 -
声明并直接初始化(声明容量)
std::unordered_map<std::string,size_t> people {{ {"A",11}, {"B", 22}, {"C", 33}}, 10};
当我们知道要在容器中保存多少个元素时,可以在构造函数中指定应该分配的格子的个数: -
用迭代器定义的一段 pair 对象范围来生成容器
std::vector<std::pair<string, size_t>>folks {{"A",11}, {"B", 22}, {"C", 33},{"D", 22},{"E", 15}, {"F", 17}};
std::unordered_map<string, size_t> neighbors {std::begin(folks), std::end(folks) , 500};
2.2 insert 插入元素
unordered_map 容器的成员函数 insert() 提供的能力和 map 谷器的这个函数相同。可以通过复制或移动来插入一个元素,可以使用也可以不使用提示符来指明插入的位置。可以插入初始化列表中指定的元素或由两个迭代器指定范围内的元素。
-
insert()调用是一个有右值引用参数的版本,所以 pair 对象会被移到容器中。insert()函数返回了一个 pair 对象:
成员变量 first 是一个迭代器,它指向插入的新元素;如果元素没有被插入,它指向的是阻止插入的元素。
成员变量 second 是一个布尔值,如果对象插入成功,它的值为 true。 -
插入初始化列表中的内容,无返回值,通常会使用 pair <T,T>来插入元素。
-
可以调用 unordered_map 容器的成员函数 emplace() 或 emplace_hint() 在容器的适当位置生成元素。
std:: unordered_map<std:: string, size_t> people {{"A",11}, {"B", 22}, {"C", 33}};
std::cout <<"people container has " << people.bucket_count()<<" buckets.n"; // 8 buckets
// 有右值引用参数的版本有返回值
auto pr = people.insert (std::pair<string, size_t> {"Jan", 44});// Move insert
std:: cout << "Element " << (pr.second ? "was" : "was not") << " inserted." << std::endl;
// 插入初始化列表中的内容,无返回值
people.insert({{"B", 21}, {"C", 22}})
// 插入容器(符合folks的数据格式)
td::unordered_map<std::string, size_t> folks; // Empty container
folks.insert(std::begin(people), std::end(people));// Insert copies of'all people elements
auto pr = people. emplace ("S", 64); // returns pair<iterator, bool>
auto iter = people.emplace_hint(pr.first, "F", 67); // Returns iterator
people.emplace_hint(iter, std::make_pair("G", 59)); //Uses converting pair<string, size_t>
// 初始化时,设定容器容量
size_t max_element_count {100};
people.reserve(max_element_count);
2.3 元素访问
-
这和 map 容器的操作是一样的。通过键来访问值,在下标中使用不存在的键时,会以这个键为新键生成一个新的元素,新元素中对象的值是默认的。
-
成员函数 at() 会返回参数所关联对象的引用,如果键不存在,会拋出一个 out_of_range 异常。当我们不想生成有默认对象的元素时,应该选择使用 at()
-
unordered_map 的迭代器是可以使用的,可以用基于范围的 for 循环来访问它的元素
people["A"] = 22; //赋值;
people["B"] = people["Jim"]; //赋值
++people ["C"] ; //值自增
for(const auto& person : people)
std::cout << person.first << " is "<< person.second <<std::endl;
// 访问格子
size_t index{1};
std::cout <<"The elements in bucket["<< index << "] are:n";
for(auto iter = people.begin(index); iter != people.end(index); ++iter)
std::cout <<iter->first << " is " <<iter->second <<std::endl;
// 访问格子
string key {"May"};
if(people.find(key) != std::end(people))
std::cout << "The number of elements in the bucket containing " << key << " is "<< people.bucket_size(people.bucket(key)) << std:: endl;
unordered_map 的成员函数 bucket_count() 返回的格子个数。bucket_size() 可以返回参数指定的格子中的元素个数。bucket() 返回的是格子的索引值,包含和传入的参数键匹配的元素。可以用不同的方式来组合使用它们。
2.4 删除元素 erase
unordered_map 的成员函数 erase() 来移除元素。
参数可以是标识元素的一个键或是指向它的一个迭代器。
当参数是键时,erase() 会返回一个整数,它是移除元素的个数,所以 0 表示没有找到匹配的元素。
当参数是迭代器时,返回的迭代器指向被移除元素后的元素。
也可以移除指定的一个元素序列
auto n = people.erase ("A"); // Returns 0 if key not found
auto iter = people.find ("B") ; // Returns end iterator if key not found
if(iter != people.end())
iter = people.erase (iter) ;// Returns iterator for element after "May"
//Remove all except 1st and last 移除[1st,last)中间所有元素
auto iter = people.erase(++std:rbegin(people),--std:rend(people));
拓展阅读
https://www.cnblogs.com/xiaolincoding/p/12311371.html
最后
以上就是开心指甲油最近收集整理的关于C++ STL unordered_map详解的全部内容,更多相关C++内容请搜索靠谱客的其他文章。



![[经典面试题]二分查找问题汇总](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)




发表评论 取消回复