文章目录
- 一、寄存器
- 1.1 通用寄存器GR
- 1.2 浮点寄存器FR
- 1.3 子程序调用时寄存器的保存方式
- 二、运行时栈
- 2.1 运行时栈的基本概念
- 2.2 运行时栈字节对齐
一、寄存器
1.1 通用寄存器GR
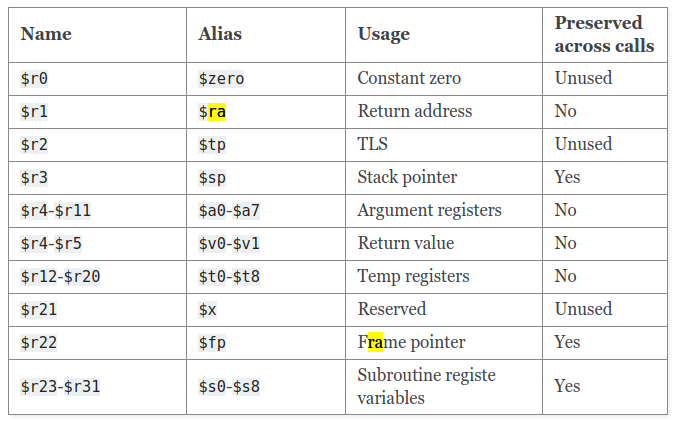
在LoongArch体系中,有32个通用寄存器,除了0号寄存器始终为0外,其他31个寄存器物理上没有区别。但系统人为添加了一些约定,给了它们特定的名字和使用方式。
PC不属于GR,只有一个,记录当前指令的地址。PC寄存器不能被指令直接修改,它只能被转移指令、例外陷入和例外返回指令间接修改。不过PC可以作为一些非转移类指令的源操作数而被直接读取,PC的宽度总是与GR一致。
对以上通用寄存器详细说明:
$zero寄存器中存放的值永远是零,且不能改变,这个寄存器的用途主要是方便编码。$ra是一个临时寄存器,控制流到达callee瞬间的$ra的值是callee的返回地址,且这个值只会被备份在栈帧中,callee返回指令是jirl $r0,$ra,0。$tp用于支持 TLS ( thread-local storage ),是用户程序中一段线程独有的空间( TLS block )。TLS block容纳可执行文件及其所需动态库的所有.tbss和.tdata段,从而支持c的 _Thread_local 的变量( errno 是一个典型)。原理是,归纳基础,在装载时求出TLS block的大小,从堆区分配空间赋值给$tp(推广一下,调用栈也是TLS);归纳步骤,在用户程序调用pthread接口创建线程时故技重施。也就是说,$tp由c库维护,用户程序不应修改这个寄存器。如程序没有运行在c库之上,比如对于系统软件,$tp只是一个没有用到的寄存器罢了$sp在整个程序执行过程中恒指向调用栈栈顶,是一个保存寄存器。控制流到达callee瞬间的$sp的值被称作$sp on entry,是一个frame pointer。。- 通用寄存器有8个用于整型参数传递,寄存器名字依次是
$a0~$a7(编号依次是$r4~$r11),$a0和$a1也用于存放返回结果值;浮点寄存器也有8个用于浮点传递参数,寄存器名称依次是$fa0~$fa7,$fa0和$fa1也用于存放返回的浮点结果值。 $t0~$t8寄存器为临时寄存器,不需要暂存其值。$fp是一个保存寄存器,但如果过程的栈帧可变,编译器会使用这个寄存器作为 frame pointer (栈帧不变部分的地址加常数偏移量,也指存放该值的寄存器)。所以,栈帧不变的函数的frame pointer是$sp,栈帧可变的函数的frame pointer是$fp。
1.2 浮点寄存器FR
在LoongArch体系中,也有32个浮点寄存器,$fa0~$fa7为参数寄存器,共8个,$fa0和$fa1也用于存放返回的浮点结果值;$ft0~$ft15为临时寄存器,共16个。
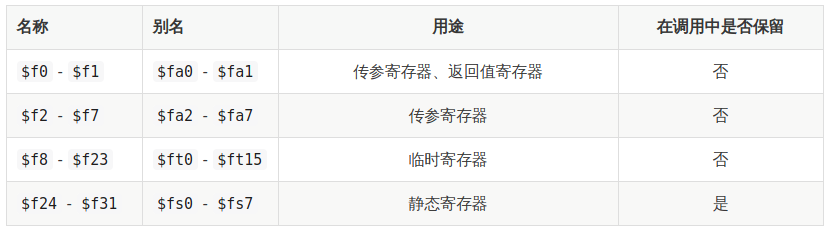
当浮点寄存器中记录的是一个单精度浮点数或字整数时,数据总是出现在浮点寄存器的[31:0]位上,此时浮点寄存器的[63:32]位可以是任意值。
条件标志寄存器CFR
CFR总共有8个,记为fcc0~fcc7,每一个都可以读写,位宽均为1比特。浮点比较的结果将写入条件标志寄存器中比较结果为true置为1,否则置为0。浮点分支指令的判断条件来自于条件标志寄存器。
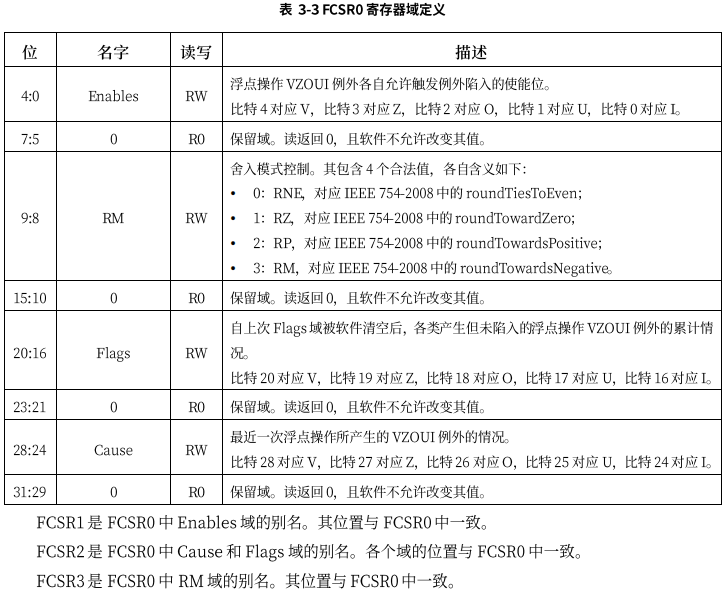
浮点控制状态寄存器FCSR
FCSR总共有4个,记为fcsr0~fcsr3,位宽均为32。其中fcsr1~fcsr3是fcsr0中部分域的别名,即访问fcsr1~fcsr3其实是访问fcsr0的某些域。当软件写fcsr1~fcsr3时,fcsr0对应的域被修改而其余比特保持不变。fcsr0的各个域的定义如下:
1.3 子程序调用时寄存器的保存方式
寄存器就像是全局变量一样,我们很难得知什么时候、哪一个函数更改了它的值。若要想安全地访问寄存器,最保险的方法是,每次在调用别的函数前,把寄存器的值保存到栈中。也就是说,在函数开始执行时,把所有寄存器的值压栈,而在函数内部执行return 指令返回的时候,把寄存器的值出栈,恢复函数调用前的状态。通过这个方法,各个函数就都可以随意使用所有的寄存器了。
这个方法的确是最安全的,但效率非常低。访问栈等价于访问机器内存,和单纯使用寄存器相比,访问内存的速度明显下降,所以要尽可能减少栈的使用次数。函数调用时并不是所有寄存器的值都需要保存,之所以要保存一个寄存器的值,是因为我们不想去更改这个寄存器的值。也就是说,如果是函数不会使用(不会变更)的寄存器,那么这个寄存器的值就不用保存。
此外,程序调用约定中指定了 caller-save 寄存器以及 callee-save 寄存器两种分类,以最大限度地重复利用寄存器。利用这个约定,可以进一步减少访问栈的次数。
caller-save寄存器。由"函数"自己决定是否需要保护,操作由"主调函数"完成。为了防止被“被调函数”改变寄存器的值,在"主调函数"中调用“被调函数”之前将寄存器的值先入栈,待“被调函数”返回到"主调函数"后出栈。这类寄存器包括:参数寄存器(r4~r11/a0~a7)、临时寄存器(r12~r20/t0~t7)。callee-save寄存器。是为了确保函数调用前后"主调函数"中这些寄存器的值不变,操作由"被调函数"完成。在"被调函数"中一旦用到这些寄存器,就在首次用到时候就入栈保护,并在“被调函数”返回前出栈恢复数值,如此返回到"主调函数"后"主调函数"中这些寄存器的值不变。这类寄存器包括:保存寄存器(r23~r31/s0~s8、r22/fp、r3/sp)。
二、运行时栈
2.1 运行时栈的基本概念
常说的进程栈则是进程的运行时栈,运行时栈主要用来传递参数(寄存器不够用时)、存储程序的返回信息(寄存器不够用时)、保存寄存器中的值(临时存储一下,待寄存器需要的时候再复制回去)、以及存储局部变量。运行时栈的增长方向和地址增长方向相反,见下图。
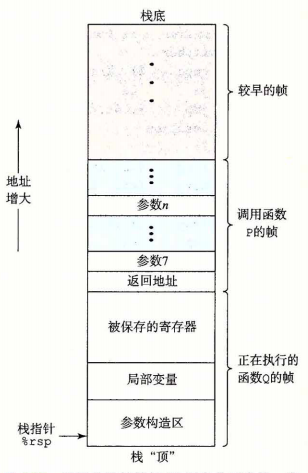
栈有三个常用概念,栈低、栈帧和栈顶。栈帧是栈上存放信息的每一个位置,栈低是栈的最低部的栈帧,栈顶则是最顶部的栈帧。栈顶指针是栈顶的地址值,永远存放在寄存器$sp(x86是%rsp)中,寄存器$fp指向当前函数的栈帧开始处,CPU是通过改变寄存器$sp和寄存器$fp的值来控制运行时栈的。
栈采用后进先出的内存管理,其内存不需要显示释放和申请,在需要栈内存的时候,只需要将栈顶扩充($sp值减小),释放栈内存的时候,将栈顶缩小($sp值增大)。编译器为函数在入口处生成一个函数头(Prologue),在返回处生成一个函数尾(Epilogue),它们负责调整$sp和$fp寄存器以生成新的栈帧或者释放一个栈帧,并生成必要的寄存器保存和恢复代码。
sp -> -64 [ empty : ] ^ (lower address)
-56 [ tmp 1: _t0 ] |
-48 [ tmp 0: _t0 ] |
-40 [ loc 0: e ] |
-32 [ spill arg 3: d ] |
-24 [ spill arg 2: c ] | stack growth
-16 [ spill arg 1: b ] |
-8 [ spill arg 0: a ] |
fp -> +0 [ old fp ] |
+8 [ return address ] | (higher address)
思考一个问题,$fp寄存器指向当前函数的开始处栈帧,$sp寄存器指向栈顶,则使用$fp或$sp都可以访问栈上的元素,是不是说只用$sp寄存器管理栈就ok,不需要用$fp?
-
大部分函数可以只用
$sp来管理栈帧。如果在编译时能够确定函数的栈帧大小,编译器可以在函数头分配所需的栈空间(通过调整$sp),这样在函数栈帧里的内容都有一个编译时确定的相对于$sp的偏移,也就不需要帧指针$fp了。// 函数原型 int testF(){ int a = 1; return a; } // 生成LoongArch上面对应的汇编码 testF: addi.d $r3,$r3,-32 st.d $r22,$r3,24 addi.d $r22,$r3,32 addi.w $r12,$r0,1 # 0x1 st.w $r12,$r22,-20 ldptr.w $r12,$r22,-20 or $r4,$r12,$r0 ld.d $r22,$r3,24 addi.d $r3,$r3,32 jr $r1 -
但有时候可能无法在编译时确定一个函数的栈帧大小。在某些语言中,可以在运行时动态分配栈空间,如C程序的
alloca调用,这会改变$sp的值。这时函数头会使用$fp寄存器,将其设置为函数入口时的$sp值,函数的局部变量等栈帧上的值则用相对于$fp的常量偏移来表示。
2.2 运行时栈字节对齐
许多计算机系统对基本数据类型的合法地址做了一些限制,要求某种类型对象所在的地址必须是某个值K的倍数。如char是1字节,short是2字节,int、float是4字节,long、double、char*是8字节。这种对齐限制简化了处理器和内存系统之间接口的硬件设计,比如我们在内存中读取一个8字节长度的变量,如果这个变量所在的地址是8的倍数,那么就可以通过一次内存操作完成该变量的读取。倘若这个变量所在的地址并不是8的倍数,可能就需要执行两次内存读取,因为该变量被放在两个8字节的内存块中了。
栈的字节对齐,实际是指栈顶指针必须是16字节的整数倍。栈对齐使得在尽可能少的内存访问周期内读取数据,不对齐堆栈指针可能导致严重的性能下降。所以在做编译器时要对程序实施数据对齐,也就需要定制一个标准:
- 任何内存分配函数(alloca, malloc, calloc或realloc)生成的块的起始地址都必须是16的倍数。
- 函数的栈帧的边界都必须是16字节的倍数。
- 在栈上传递的参数和局部变量,都要满足字节对齐,栈指针(
$sp)的起始地址必须要是16的倍数。
【参考书籍】
《计算机体系结构基础》第3版
《深入理解计算机系统》第3版
《计算机体系结构量化研究方法》第5版
最后
以上就是开心舞蹈最近收集整理的关于寄存器和运行时栈的全部内容,更多相关寄存器和运行时栈内容请搜索靠谱客的其他文章。








发表评论 取消回复