一、问题描述
某次部署某业务系统时,执行es写入索引脚本报错如下:
{"error":"Content-Type header [application/x-www-form-urlencoded] is not supported","status":406}

环境:Elasticsearch7.0.1
二、分析处理
官网显示这是因为从ES6开始进行了严格 content-type 检查。从 Elasticsearch 6.0 开始,所有包含正文的 REST 请求还必须为该正文提供正确的上下文类型,每个传入的请求都需要为其包含的正文使用正确的上下文类型。更多参看Strict Content-Type Checking 。另外,ElasticSearch 7.x 默认不再持指定索引类型,默认索引类型是_doc。
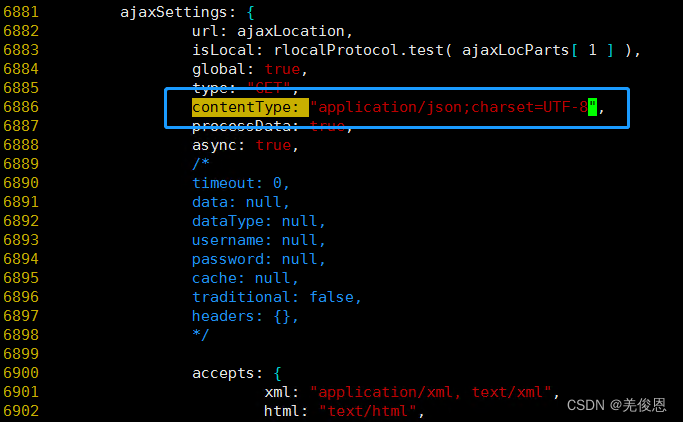
1)进入head安装目录_site/vendor.js的6886行附近修改
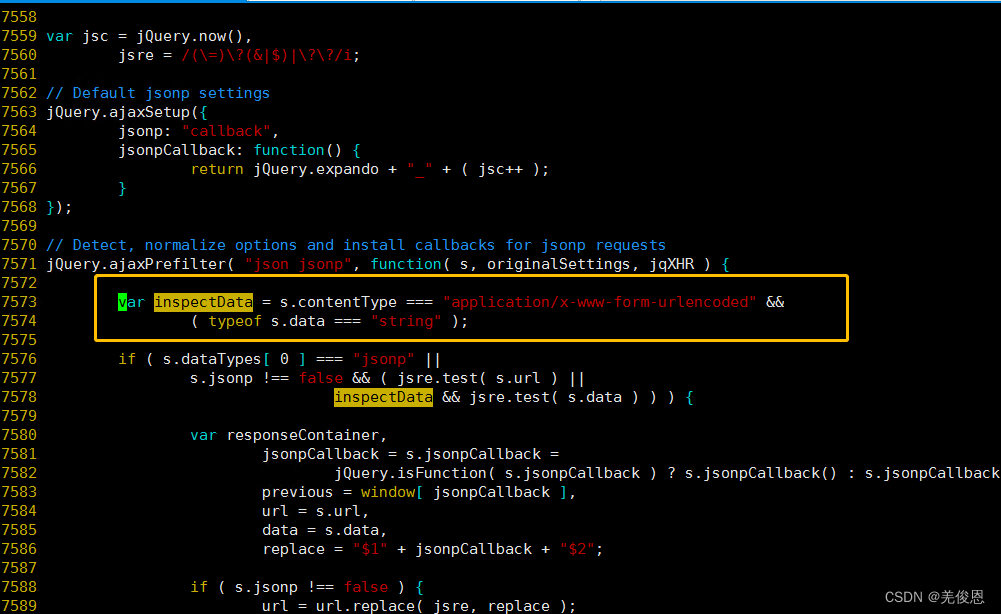
2)进入head安装目录_site/vendor.js的7573行附近,修改
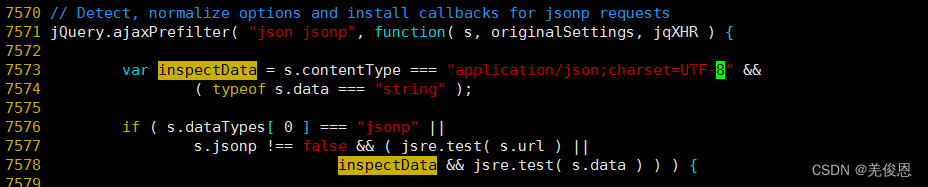
修改为:
重启ES和es-head插件后,发下执行es初始化脚本还是报同样错,
3)直接创建索引的脚本里指定请求头类型
curl -H “Content-Type: application/json” -XPOST es_ip:32000 -d ……
但是会报错root mapping definition has unsupported parameters,这是因为ElasticSearch 7.x 默认不再持指定索引类型,默认索引类型是_doc;且ElasticSearch 7.x 不再支持type字段。
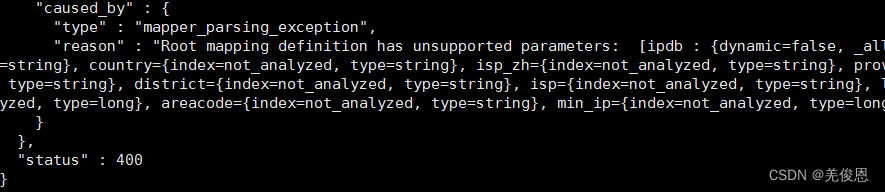
4)关于ES7.0的中index的type已经默认禁止使用后如何启用
更多参看:Removal of mapping types。
可以手动开启,请求里后跟?include_type_name=true,类似:PUT index/_mappings?include_type_name=true这样子,当成api里的一个参数。
es效果如下:
5)报错:{“error”:{“root_cause”:[{“type”:“mapper_parsing_exception”,“reason”:“No handler for type [string] declared on field [continent]”}]
这是因为到了6.X就彻底移除string了,可换成了text和keyword作为字符串类型。另外,"index"的值只能是boolean变量了。
修改:
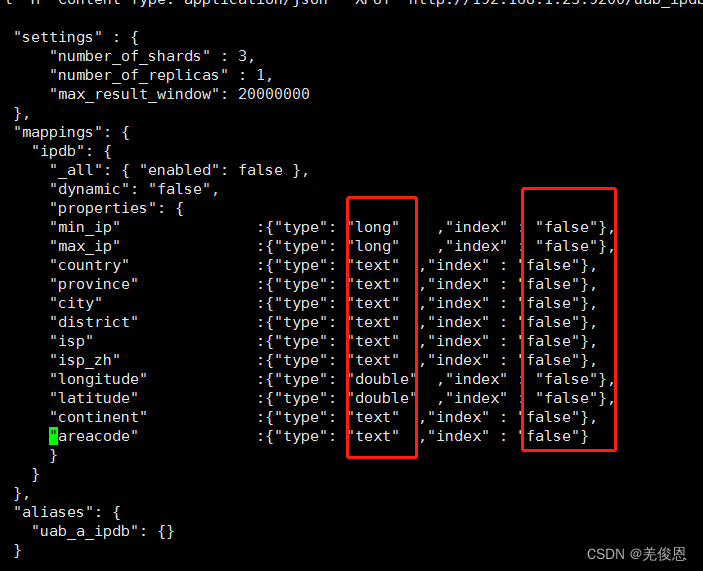
Failed to parse value [not_analyzed] as only [true] or [false] are allowed.
关于_all : {enabled=false}字段,es6.x默认已禁用全文索引,es7.0彻底移除该配置,在es脚本里需要移除该字段。另外dynamic:动态mapping,禁用后将不会自动创建field,但数据仍可以正常插入,这个es7里还支持。执行后效果如下:
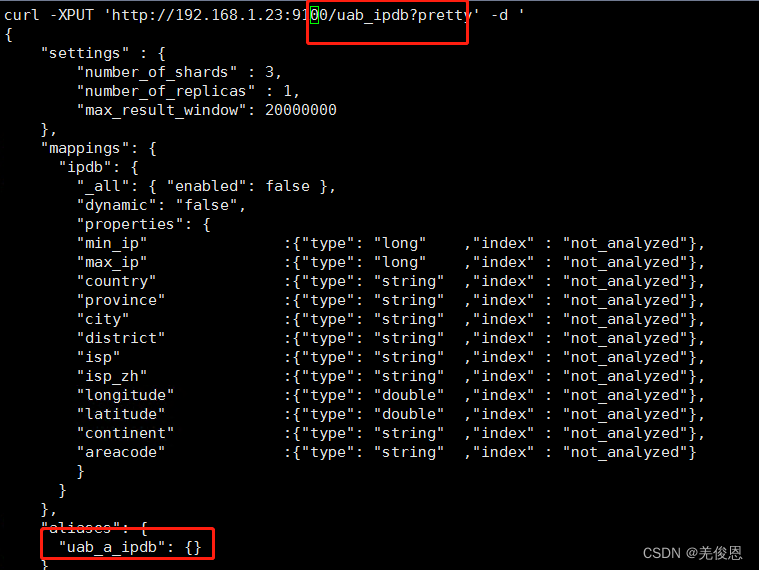
最终脚本请求文件头如下:
curl -H "Content-Type: application/json" -XPUT 'http://192.168.1.23:9200/uab_ipdb?include_type_name=true&&pretty' -d '{
……}'
es上查看,对应的索引已经建立好了:
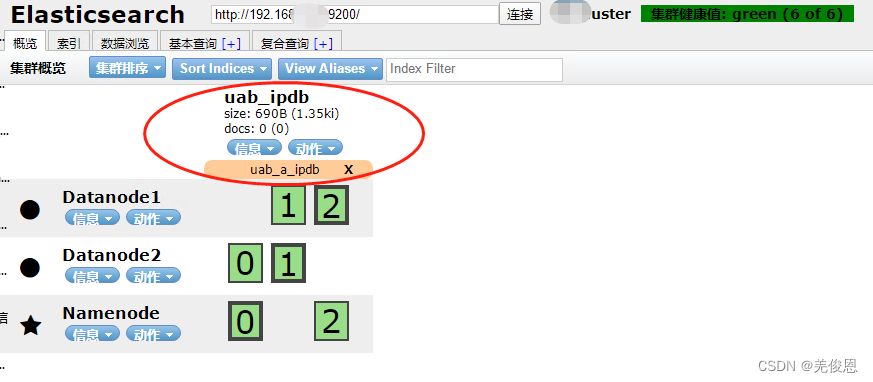
更多参看:ES-type类型转化;
三、附录:
1)关于移除type属性字段的说明
2.1 Elasticsearch 5.6.0
通过对 index 设置参数 index.mapping.single_type: true 就能够启用单 index 单 type 限制(一个 index 只能支持一个 type),同样该限制从 6.0 版本开始该限制会强制启用。
2.2 Elasticsearch 6.x
在 Elasticsearch 6.x 中,一个 index 只能支持一个 type,推荐的 type 名字为 _doc(这样可以在 API 方面向后兼容 7.x 。
在 Elasticsearch 6.8 中,Elasticsearch 引入了一个参数控制 type 开关:include_type_name,默认值为 true,表示仍使用 type,手动设置为 false 后,请求 es 的 API 将不再包含 type,而是使用类 PUT /{index}/_doc/{id} 的格式。
2.3 Elasticsearch 7.x
在 Elasticsearch 7.x 中,include_type_name 被默认置为 false,新的 index API 格式为 PUT /{index}/_doc/{id} 和 POST {index}/_doc 。需要注意的是,_doc 并不是一个 type ,而仅仅是 API 请求路径中永久的一部分。
2.4 Elasticsearch 8.x
在 Elasticsearch 8.x 中,include_type_name 已被删除,同时也表示 es 不再支持任何自定义 type 。
2)涉及的相关名词
Lucene:es是基于lucene分片(shard)存储的近实时的分布式搜索引擎。它使用java语言编写的存储与查询框架,通过组织文档与文本关系信息进行倒排索引,内部形成多个segment段进行存储,是es的核心组件,但不具备分布式能力。
segment:Lucene内部最小的存储单元,也是es的最小存储单元,多个小segment可合为一个较大的segment,并但不能拆分。
shard:es为解决海量数据的处理能力,在Lucene之上设计了分片的概念,每个分片存储部分数据,分片可以设置多个副本,通过内部routing算法将数据路由到各个分片上,以支持分布式存储与查询。
近实时:严格讲es并不是索引即可见的数据库,首先数据会被写入主分片所在机器的内存中,再触发flush操作,形成一个新的segment数据段,只有flush到磁盘的数据才会被异步拉取到其它副本节点,如果本次搜索命中副本节点且数据没有同步的话,那么是不会被检索到的;es默认flush间隔是1s,也可通过修改refresh_interval参数来调整间隔(为提升性能和体验,一版设置30s-60s)。
分布式:es天生支持分布式,配置与使用上与单机版基本没什么区别,可快速扩张至上千台集群规模、支持PB级数据检索;通过内部路由算法将数据储存到不同节点的分片上;当用户发起一次查询时,首先会在各个分片上完成提前批处理,处理后的数据汇总到请求节点再做一次全局处理后返回。
es中,存储数据的基本单位就是索引,一个index里面可以有多个type(废弃),而mapping就相当于表的结构定义,定义了什么字段类型等,你往index的一个type里添加一行数据就叫做一个document,每一个document有多个filed,每一个filed就代表这个document的一个字段的值。文档(Document) 相当于数据库中的row。字段(Field)相当于数据库中的column。
一个索引就是还有某些共有特性的文档的集合,一个索引被一个名称唯一标识,并且这个名称被用于索引通过文档去执行搜索,更新和删除操作。一个文档(document)就是一个基本的搜索单元。
主分片(Primary shard) 索引的子集,索引可以切分成多个分片,分布到不同的集群节点上。分片对应的是 Lucene 中的索引。
副本分片(Replica shard)每个主分片可以有一个或者多个副本。
分片和副本流程:
ES客户端将一份数据写入primary shard后,它会将分成成对的shard分片,并将数据进行复制,ES客户端取数据的时候就会在replica或primary 的shard中去读。ES集群有多个节点,会自动选举一个节点为master节点,这个master节点其实就是干一些管理类的操作,比如维护元数据,负责切换primary shard 和replica shard的身份之类的,要是master节点宕机了,那么就会重新选举下一个节点为master为节点。如果时非master宕机了,那么就会有master节点,让那个宕机的节点上的primary shard的身份转移到replica shard上,如果修复了宕机的那台机器,重启之后,master节点就会控制将缺失的replica shard 分配过去,同步后续的修改工作,让集群恢复正常。
最后
以上就是勤劳短靴最近收集整理的关于ES新建索引报错application/x-www-form-urlencode不再支持,错误代码406的全部内容,更多相关ES新建索引报错application/x-www-form-urlencode不再支持内容请搜索靠谱客的其他文章。








发表评论 取消回复