文章目录
- 前言
- 多模态数据的好处
- 多模态学习的工作原理
- 模式的表示
- 模态转换
- 特征提取
- 融合与共同学习
- 结论
前言
我们对世界的体验是多模态的——我们看到物体,听到声音,感受质地,闻到气味和味道,然后做出决定。多模态学习表明,当我们的多种感官——视觉、听觉、触觉——都参与信息处理时,我们会理解并记住更多。通过组合这些模式,学习者可以组合来自不同来源的信息。
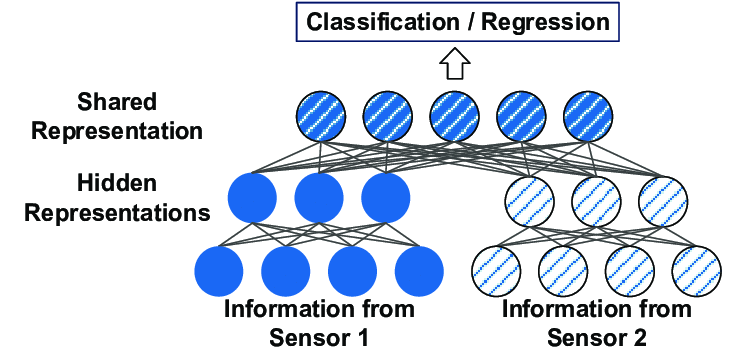
在深度学习方面,仅根据信息来源(图像、文本、音频、视频)训练模型的方法很常见。
但是还有一种方法可以构建同时包含两种数据类型(例如文本和图像)的模型。使用多模态数据不仅可以改进神经网络,而且还包括从所有来源中更好地提取特征,从而有助于进行更大规模的预测。
多模态数据的好处
模式本质上是信息的渠道。这些来自多个来源的数据在语义上是相关的,有时会相互提供补充信息,从而反映在单独使用单个模式时不可见的模式。这样的系统整合了来自各种传感器的异构、断开的数据,从而有助于产生更可靠的预测。
例如,在情绪检测器中,我们可以结合从 EEG 收集的信息和眼动信号,以结合和分类某人当前的情绪——从而结合两个不同的数据源进行一项深度学习任务。
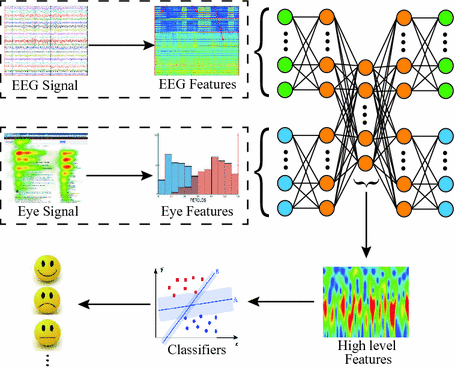
多模态学习的工作原理
深度神经网络已成功应用于单模态的无监督特征学习——例如。文本、图像或音频。在这里,我们的目标是从不同的模态进行信息融合,以提高我们网络的预测能力。总体任务主要可以分为三个阶段——个体特征学习、信息融合和测试。
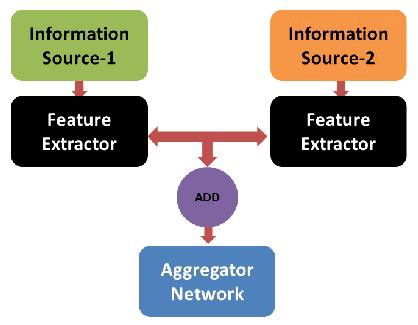
我们需要以下内容:
- 至少两个信息源
- 每个来源的信息处理模型
- 组合信息的学习模型
鉴于这些先决条件,让我们更详细地看一下多模态学习中涉及的步骤
模式的表示
第一个基本步骤是学习如何表示输入并以表达多种模态的方式总结数据。多模态数据的异质性使得构建此类表示具有挑战性。
例如,文本通常是象征性的,而音频和视觉形式将被表示为信号。有关更多详细信息,请查看这篇关于多模态学习的基础研究论文。
模态转换
第二步是解决如何将数据从一种模态转换(映射)到另一种模态。不仅数据是异构的,而且模态之间的关系通常是开放式的或主观的。来自两种或多种不同形式的(子)元素之间必须存在直接关系。
例如,我们可能希望将食谱中的步骤与显示正在制作的菜肴的视频对齐。为了应对这一挑战,我们需要衡量不同模态之间的相似性,并处理可能的长期依赖和歧义。
特征提取
需要通过构建最适合数据类型的模型从各个信息源中提取特征。从一个来源提取的特征是独立于另一个来源的。
例如,在图像到文本的翻译中,从图像中提取的特征是更精细的细节形式,如边缘和环境,而从文本中提取的相应特征是令牌的形式。
在从两个数据源中提取出对预测很重要的所有特征之后,是时候将不同的特征组合成一个共享表示了。
融合与共同学习
下一步是结合来自两个或多个模态的信息来执行预测。
例如,对于视听语音识别,唇部运动的视觉描述与音频输入融合以预测口语。来自这些不同模态的信息可能具有不同的预测能力和噪声拓扑,并且可能在至少一种模态中丢失数据。
例如,对于视听语音识别,唇部运动的视觉描述与音频输入融合以预测口语。来自这些不同模态的信息可能具有不同的预测能力和噪声拓扑,并且可能在至少一种模态中丢失数据。
在这里,我们可以对子网络进行加权组合,以便每个输入模态都可以对输出预测具有学习贡献(Theta)。与其他来源相比,这使得能够更多地包含来自不同来源的有用特征。
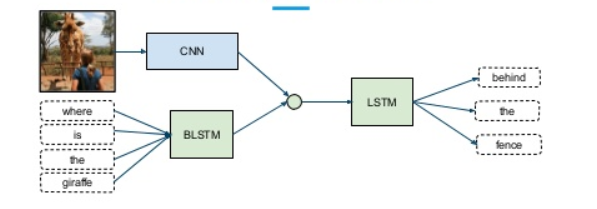
可以根据需要选择不同模态的模型架构——例如。文本数据的 LSTM 或图像的 CNN。然后我们可以组合这些特征,并通过聚合模型将其传递给最终的分类器。
结论
在处理多模态数据集时,首先要记住的是特征的聚合。从单个数据源提取特征之前的一切都遵循相同的规则和步骤,并且独立于其他数据源。信息融合,牢记每种数据类型的权重,是研究的主要领域。
最后
以上就是大气仙人掌最近收集整理的关于多模态深度学习简介前言多模态数据的好处多模态学习的工作原理结论的全部内容,更多相关多模态深度学习简介前言多模态数据内容请搜索靠谱客的其他文章。








发表评论 取消回复