
【从零开始学机器学习第 03 篇】
摘要:手写 Sklearn 的 train_test_split 函数。
之前两篇文章以酒吧的红酒故事引出了 kNN 分类算法,根据已倒好的酒(样本),预测新倒的酒(预测)属于哪一类,文章见文末。
预测方法我们使用了两种,一种是根据欧拉公式逐步手写,思路清晰直观。另外一种方法是模仿 Sklearn 中的 kNN 算法,把代码封装起来以调用库的形式使用,更加精简。
然而这样做忽略了一个重要的问题,我们把全部的红酒样本都拿来生成 kNN 模型进行预测。而模型预测的准确率怎么样,并不清楚也无从验证。这在实际运用中有很大问题,比如说,根据股市数据做了一个模型,然后就直接参照这个模型就去投资股票了,结果模型预测趋势跟实际走势大相径庭,那就惨了。
所以我们希望生成一个模型后,能有一个测试集先来测试一下模型,看看效果怎么样,然后进一步地调整并生成一个尽可能好的模型。
这样的话,就需要把原始样本分成一大一小两份,比如 70% 和 30%,大的一份用来训练(train)生成模型,一份用来最后测试(test)模型。因为测试集本身有标签参照,跟模型预测的标签一对比就能知道模型效果如何。
下面我们仍然以葡萄酒数据集为例,把数据集划分为训练集和测试集建立模型,最后测试模型效果。
这份葡萄酒数据集来源于1988 年意大利的葡萄酒产地,属于 sklearn 自带的分类数据集,Sklearn 自带好几个常用的分类和回归数据集,之后会一一拿来做例子。
这份数据集包含 178 个样本,13 个数值型特征:alcohol酒精浓度、color_intensity 颜色深度等(我们在第一课就使用了这两个特征)。
标签(y值) 是葡萄酒的 3 种分类,用 [0,1,2] 表示。
加载数据集
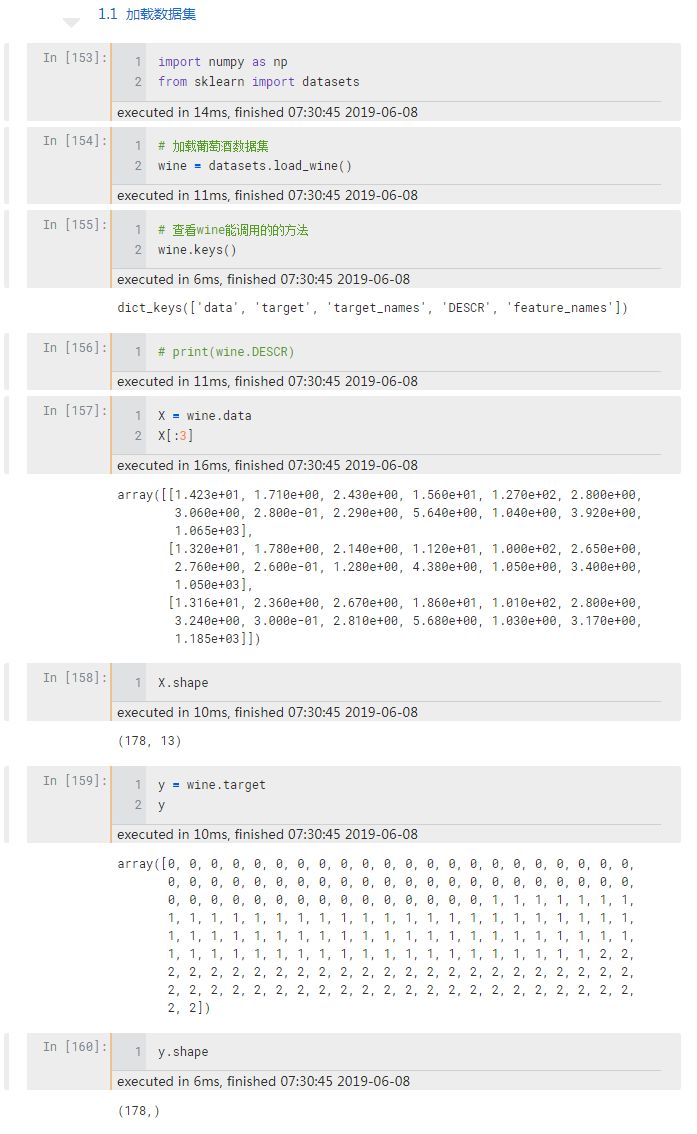
样本 X 是 178 行 13 列的矩阵,标签 y 是一个 178 元素的向量,接下来准备划分训练集和测试集。
Sklearn 调包划分数据集
先来调用 Sklearn 数据集划分函数 train_test_split :
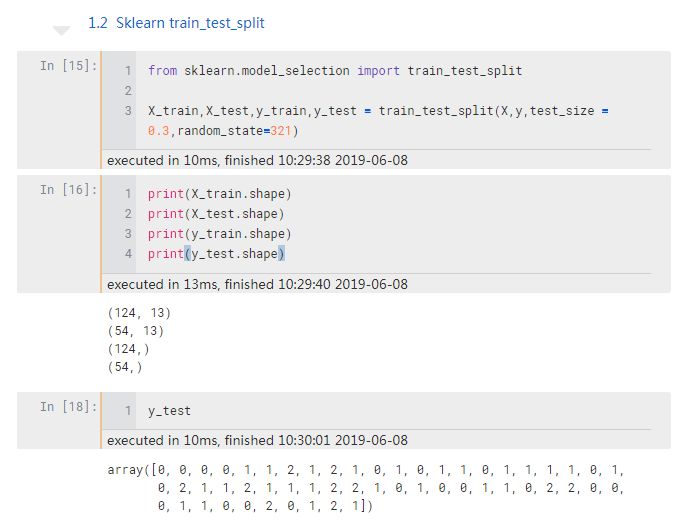
test_size 是测试集比例,random_state 是一个随机种子,保证每次运行都能得到一样的随机结果
Sklearn 只用两行代码就可以划分好数据集,虽然简单但是它背后是怎么划分的我们并不清楚,为此,下面来手写一下以更好理解。
手写 train_test_split 函数
观察到原始数据集的标签值是从 0 到 2 有序排列的,所以不能直接划分,要先把数据集打乱保证随机抽样。打乱可以用 numpy 的 permutation 函数,它会返回打乱后的数据集的索引,这个函数的妙处就在于根据索引就能同时匹配到 X 和 y。二者是一一对应的。
数据集整体打乱后设置一个划分比例,比如 0.3,表示测试集和训练集的比例是 0.7:0.3,结合索引就分别能得到训练样本和标签的数量。
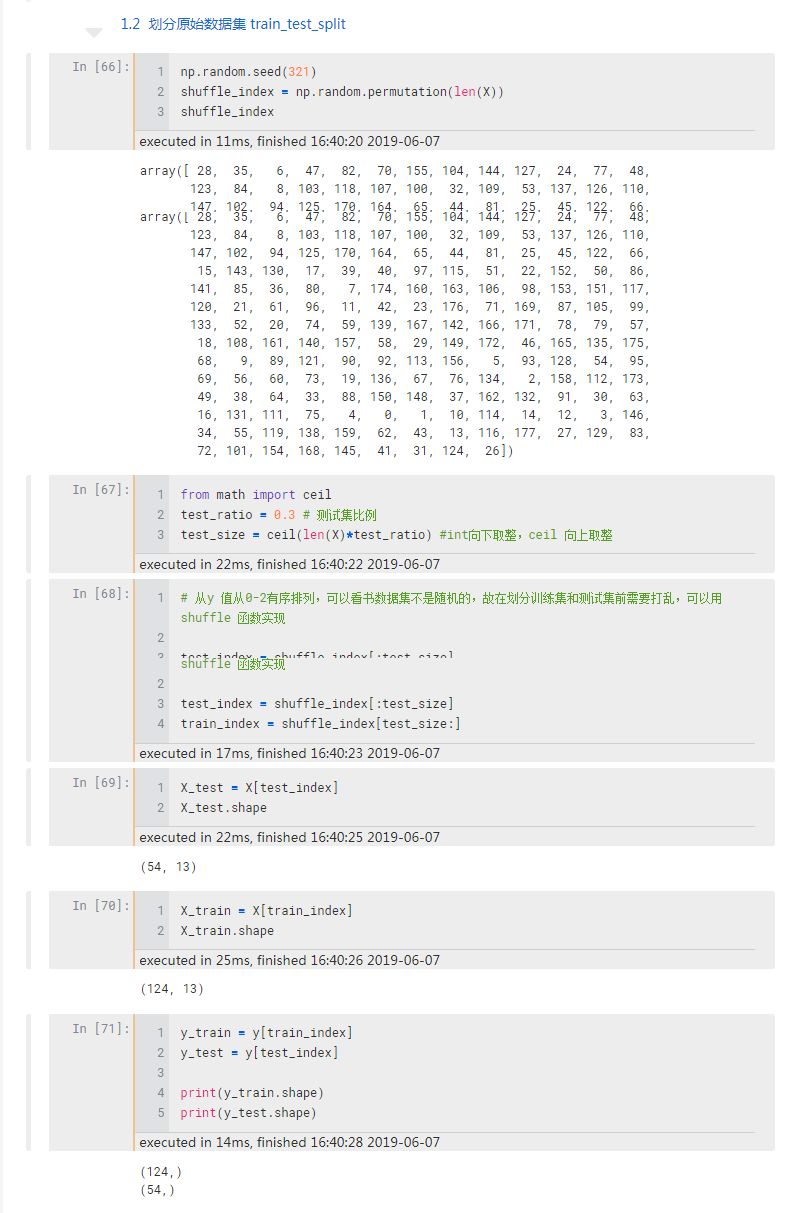
因 Sklearn 中的 train_test_split 是向上取整,所以为了保持一致使用了向上取整的 ceil 函数,ceil (3.4) = 4;int 虽然也可以取整但它是向下取整的, int (3.4) = 3。
在打乱数据之前,添加了一行 random.seed (321) 函数,它的作用是保证重新运行时能得到相同的随机数,若不加这句代码,每次得到的结果都会不一样,不便于相互比较。
可以看到,手写函数比 Sklearn 调用的代码多很多,可不可以也像 Sklearn 那样只用几行代码完成数据集划分呢?可以的,只需要把上面的函数封装成一个库再调用即可。
封装 train_test_split 函数
封装很简单,只需要两步。
首先,把代码写成一个函数存到一个 .py 程序:
1import numpy as np
2from math import ceil
3
4def train_test_split(X, y, test_ratio=0.3, seed= None):
5 assert X.shape[0] == y.shape[0], 'X y 的行数要一样'
6 if seed:
7 np.random.seed(seed)
8 shuffle_index = np.random.permutation(len(X))
9 test_size = ceil(len(X) * test_ratio)
10 test_index = shuffle_index[:test_size]
11 train_index = shuffle_index[test_size:]
12 X_train = X[train_index]
13 X_test = X[test_index]
14 y_train = y[train_index]
15 y_test = y[test_index]
16 return X_train, X_test, y_train, y_test
这里添加了一个 assert 断言保证 X y 的行数一致。train_test_split 函数有四个参数:
test_ratio 是测试集比例,设置了一个默认值 0.3,意思就是当在 jupyter notebook 中调用这个函数的时候如果不指定该参数,它会默认设置为 0.3,如果想换一个比例了,手动设置这个参数就可以了。
seed = None 的意思是提供了一个随机种子选项,如果对随机结果没有要求,那么使用默认的 None 就可以,如果想固定一个随机结果,那么就需要设置该参数,比如前面我们设置了一个 321 ,任何一个数都可以,每个数的得出的随机结果不一样。
接着,将程序命名为 model_selection.py文件(跟 Sklearn 保持一致)存储到 .ipynb 目录的文件夹中,然后调用该函数即可。
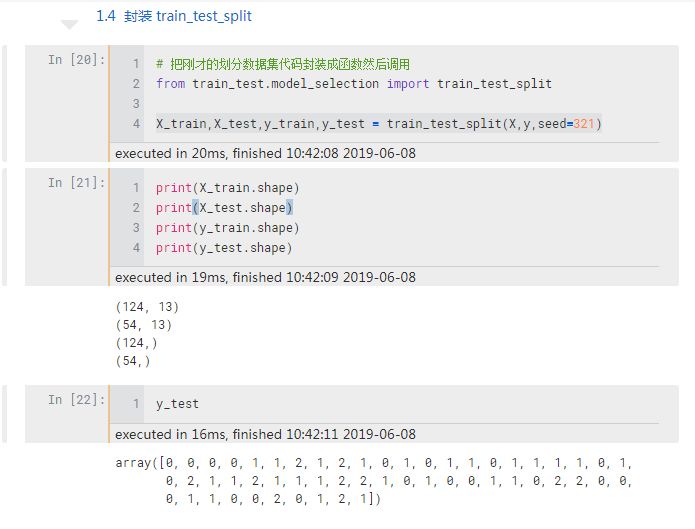
可以看到和 Sklearn 一样,也只需要两行代码就可以调用我们自己写的封装函数了。如果你有练习过一些机器学习的案例,就知道这两行代码非常常见,但以前你可能只是机械地完成这个操作,不清楚它背后具体是怎么划分的,现在手写这个函数后,对这两行代码的含义就会有更清晰地认识。
另外说一个小知识点。如何在 jupyter notebook 中调用 .py程序,比较好的选择是把程序做成一个包再调用。
方法很简单,只需要程序同级目录下新建一个 __init__.py的空白程序就可以了。
文件目录层级如下:
1kNN/
2 train_test_split.ipynb
3 train_test/
4 __init__.py
5 model_selection.py
__init__.py文件的作用是将程序所在的文件夹变成一个 Python 模块,事实上我们调用的 Python 模块,包中都有这样一个文件。
是不是不难理解?
这样我们把模型划分好了,完成了准备工作,接下来传给 kNN 模型预测出结果 y_predict ,然后跟 y_test 对比,就可以计算出模型分类的准确率如何,即模型能准确预测出多要红酒分类正确。
我们在下一篇文章中用两个实际数据集介绍如何计算 kNN 模型分类的准确率。
本文的 jupyter notebook 代码,可以在公众号后台回复「kNN3」得到,加油!
系列文章:
【从零开始学机器学习02】Sklearn 中的 kNN 封装算法
【从零开始学机器学习01】手写机器学习最简单的 kNN 算法
最后
以上就是饱满超短裙最近收集整理的关于idea2020.2中@test是怎么测试的_Sklearn 划分训练集和测试集的全部内容,更多相关idea2020.2中@test是怎么测试的_Sklearn内容请搜索靠谱客的其他文章。








发表评论 取消回复