-
TSV文件的抽取
TSV是Tab-separated values的缩写,即制表符分隔值。使用制表符分隔数据字段的文件被称为制表符文件。制表符文件中的数据以表格结构储存,每一行储存一条记录,每条记录的各个字段间使用制表符分隔。
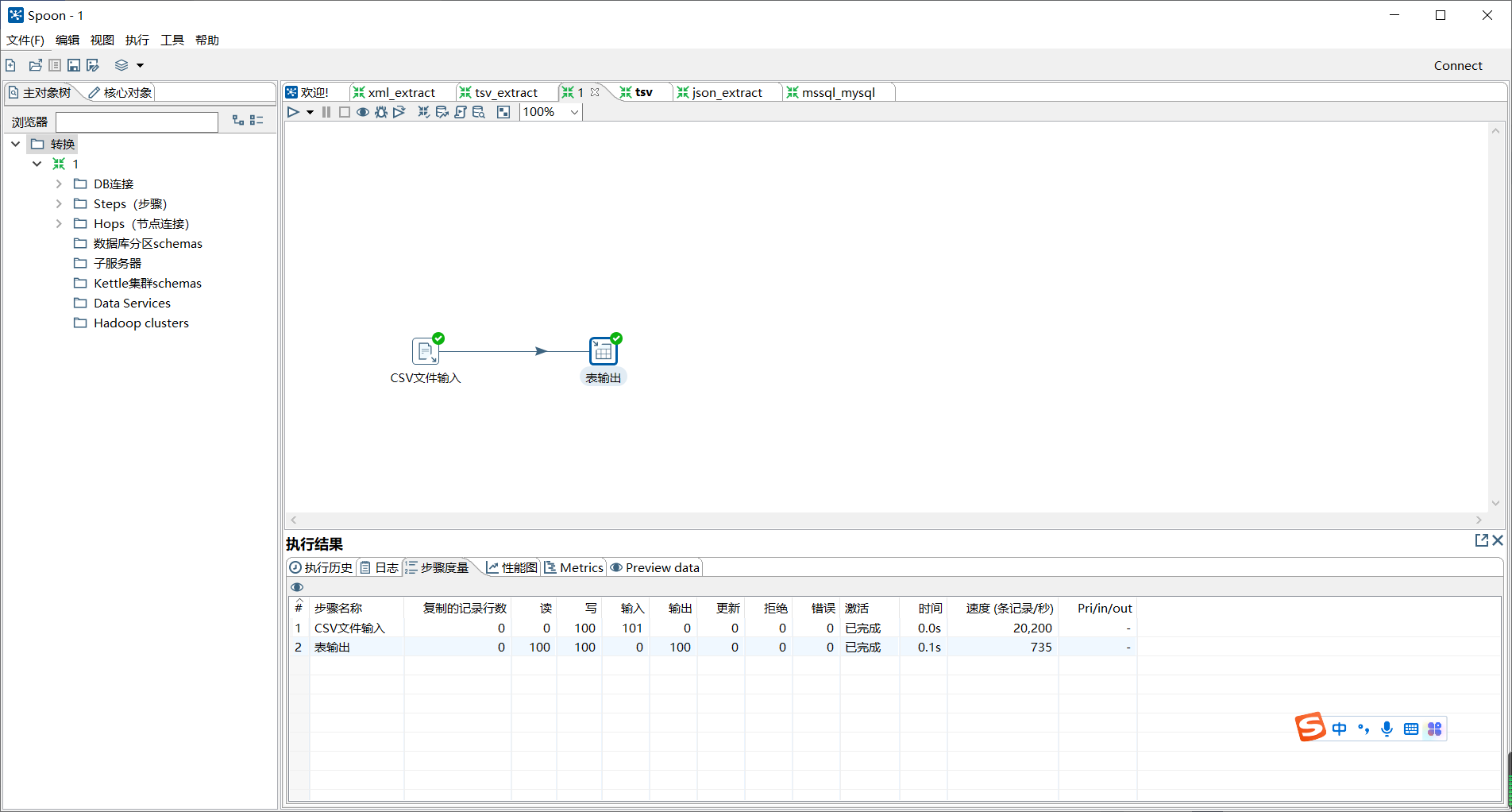
通过使用Kettle工具,创建一个转换tsv_extract,添加“文本文件输入”控件、“表输出”控件以及Hop跳连接线,如图所示: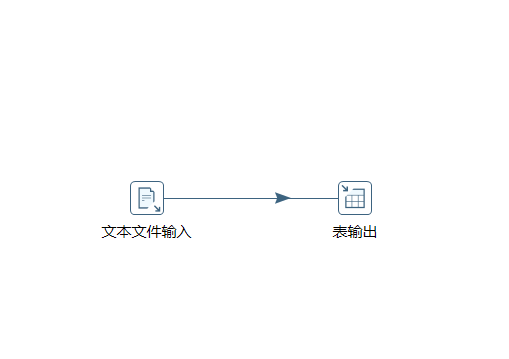
双击“文本文件输入”控件,进入“文本文件输入”界面;
单击【浏览】按钮,选择要抽取的文件tsv_extract.tsv,如图所示: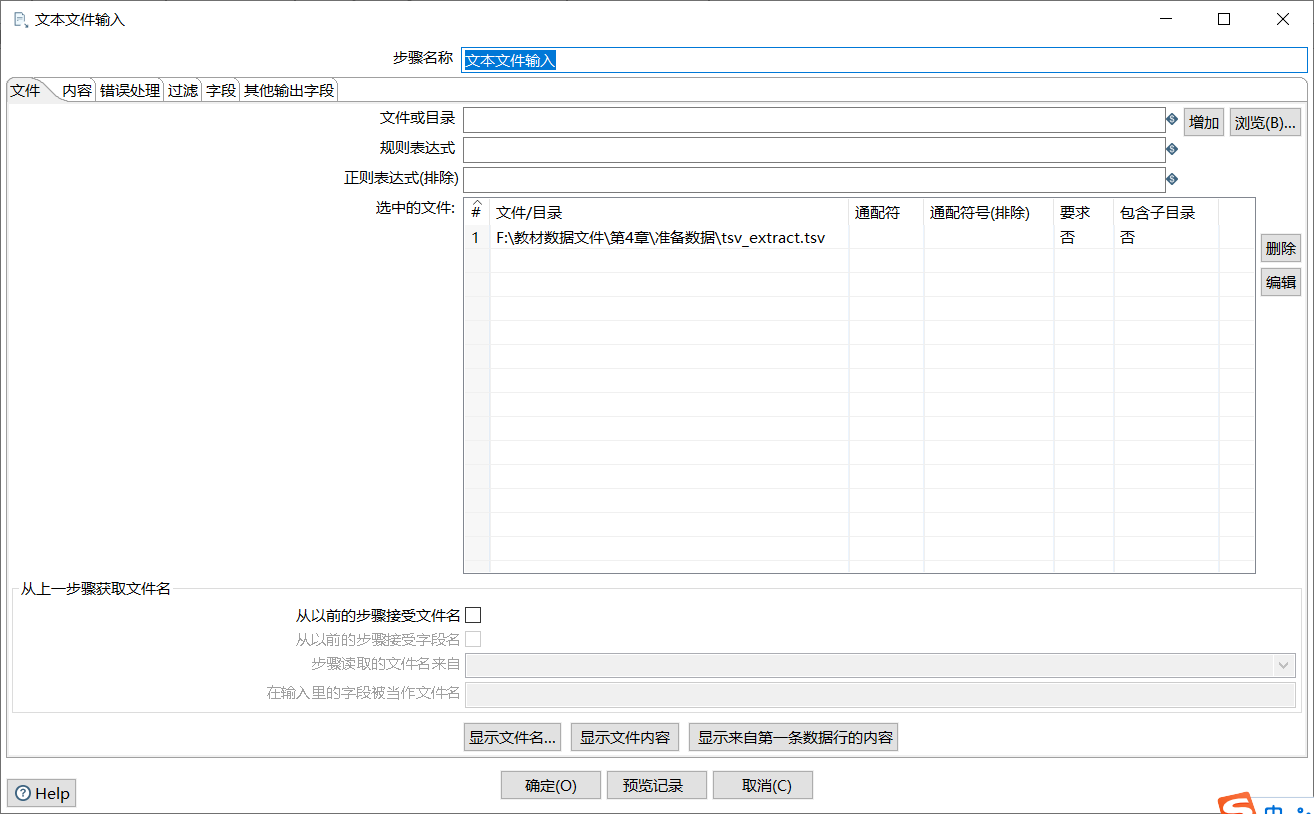
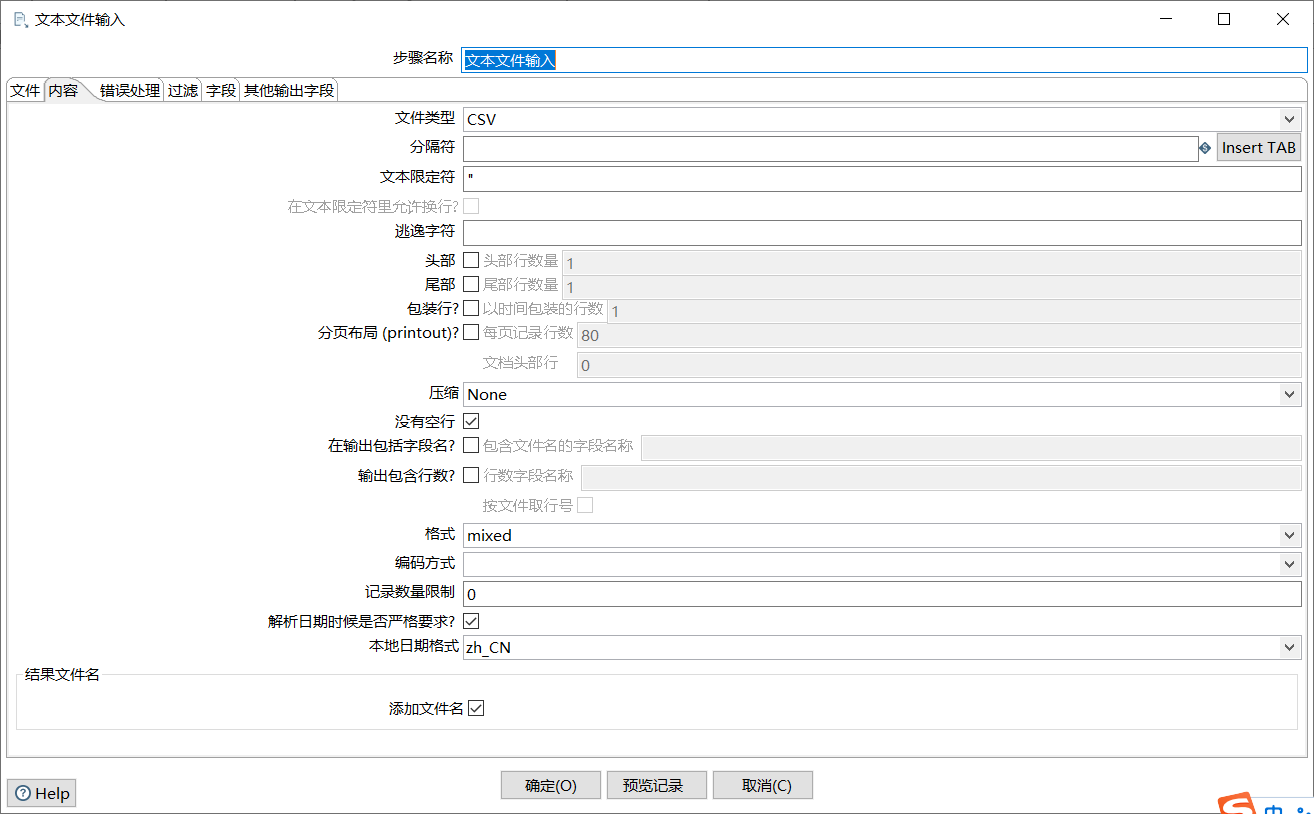
单击“内容”选项卡,清除分隔符处默认分隔符“;”并单击【Insert TAB】按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框;
单击【预览记录】按钮,查看文件tsv_extract.tsv的数据是否成功抽取到文本文件输入流中。如图所示:
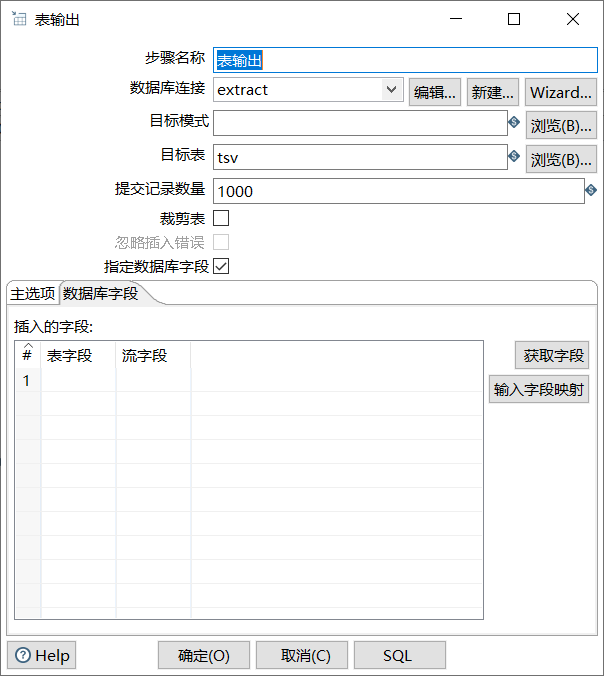
双击“表输出”控件,进入“表输出”控件的配置界面,如图所示:
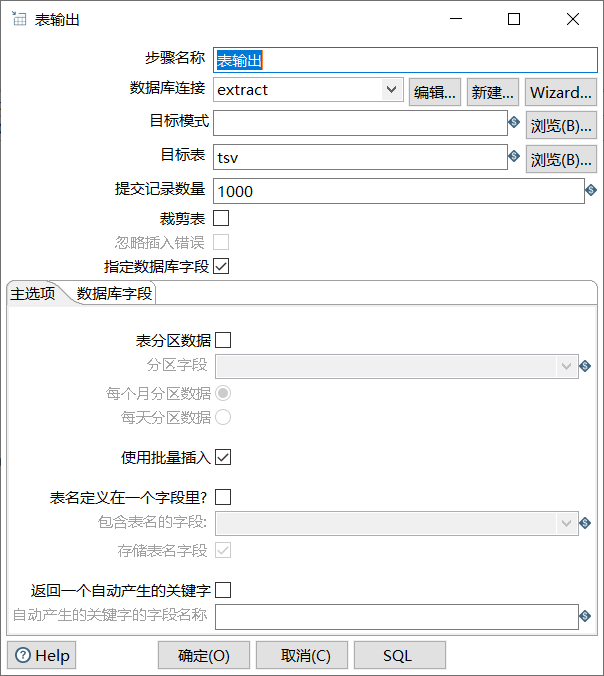
单击目标表右侧的【浏览】按钮,获取目标表,即数据表tsv。如图所示:
单击转换工作区顶部的开始运行按钮,运行创建的tsv_extract转换,如图所示即为成功。
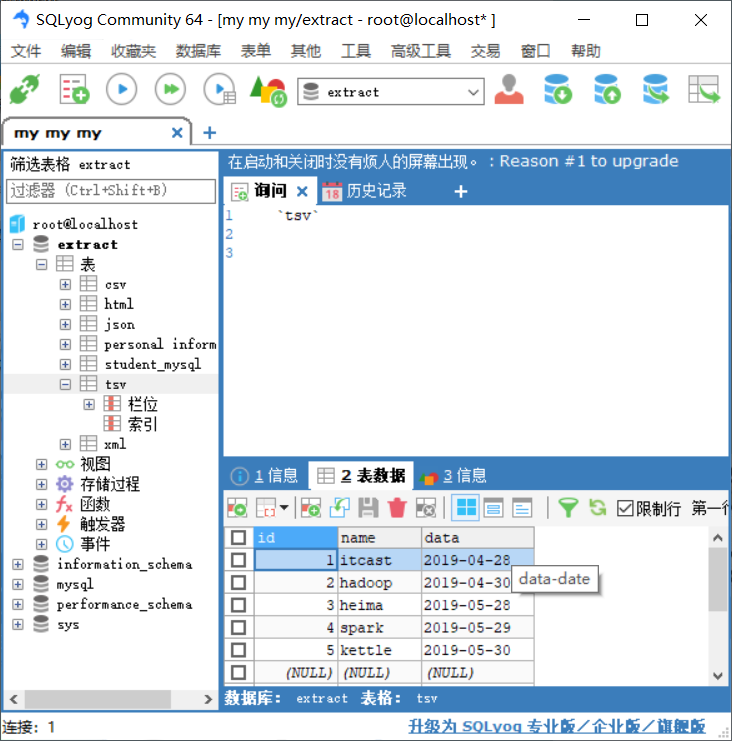
通过SQLyog工具,查看数据表tsv是否已成功插入五行数据。
-
CSV文件抽取
CSV是Comma-Separated Values的缩写,即逗号分隔值。CSV文件是用逗号分隔数据字段的文件,因此也被称为逗号分隔值文件,有时会使用字符来替代逗号实现分隔,因此,也被称为字符分隔文件。CSV文件是以纯文本形式存储表格数据(数字和文本),纯文本意味着该文件是一个字符序列。
通过使用Kettle工具,创建一个转换csv_extract,并添加“CSV文件输入”控件、“表输出”控件以及Hop跳连接线,具体如图所示。
双击“CSV文件输入”控件,进入“CSV文件输入”界面;
单击【浏览】按钮,选择要抽取的文件csv_extract.csv。
如图所示:
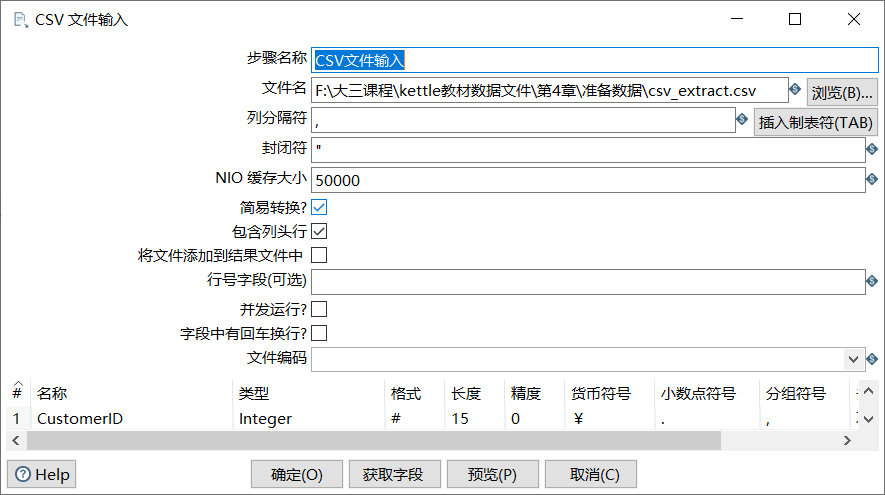
单击【获取字段】按钮,Kettle自动检索CSV文件,并对文件中的字段类型、格式、长度、精度等属性进行分析。
如图所示:

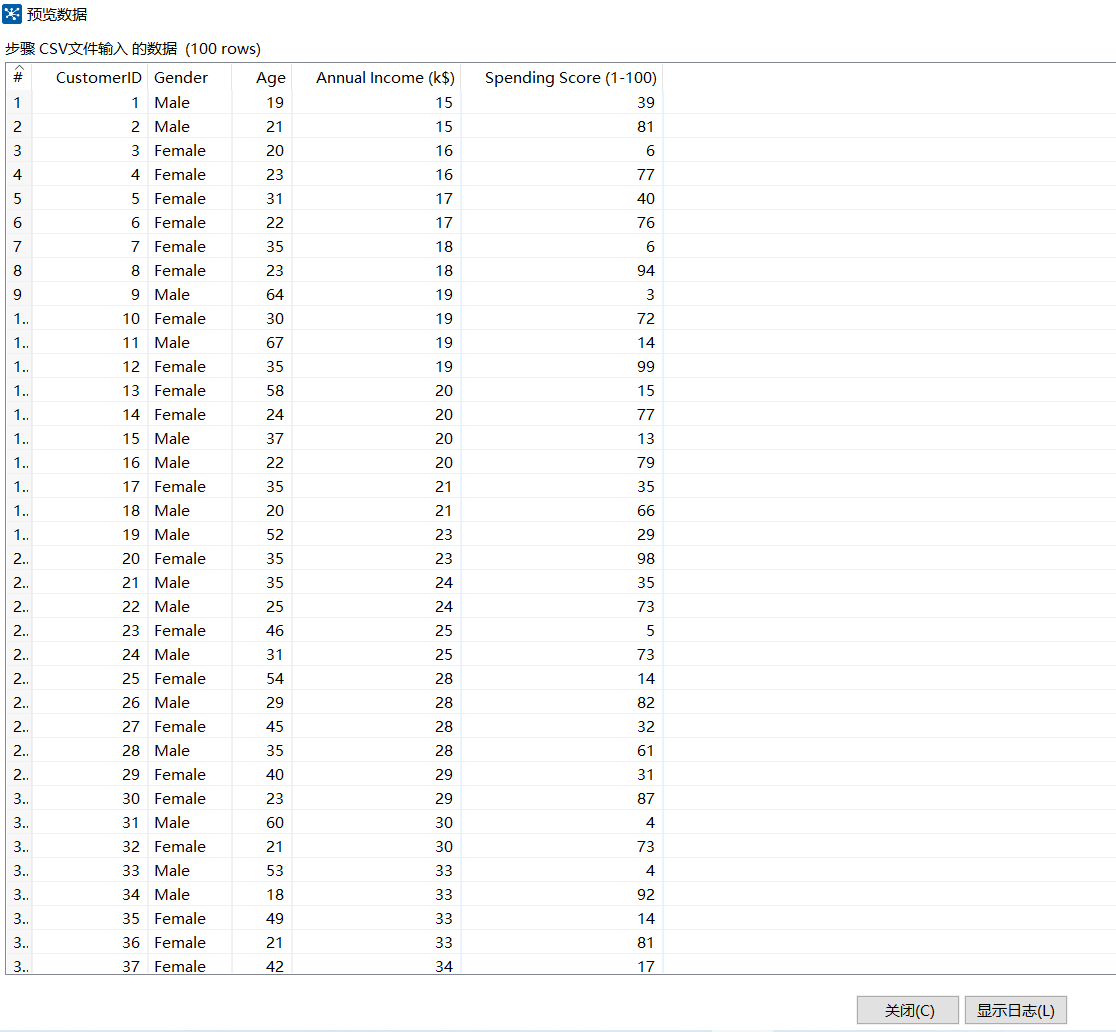
单击【预览】按钮,查看文件csv_extract.csv的数据是否抽取到CSV文件输入流中。
如图所示:
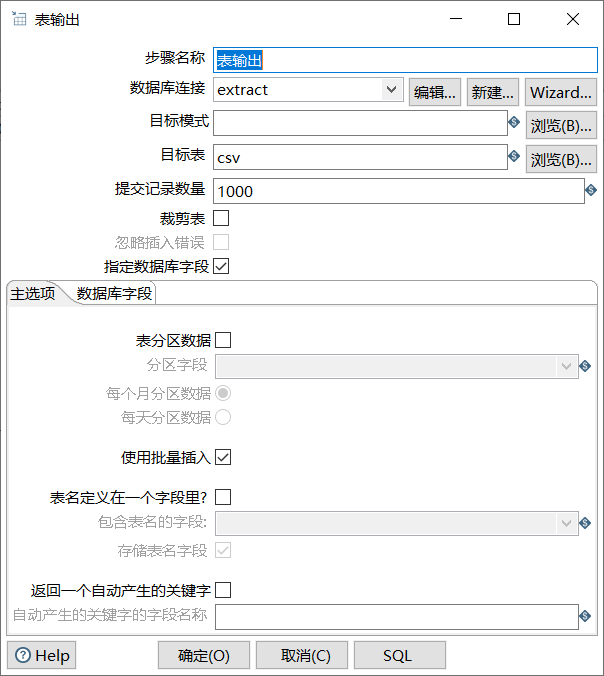
双击“表输出”控件,进入“表输出”控件的配置界面;
单击目标表右侧的【浏览】按钮,获取目标表,即数据表csv;勾选“指定数据库字段”的复选框;
具体如图所示:
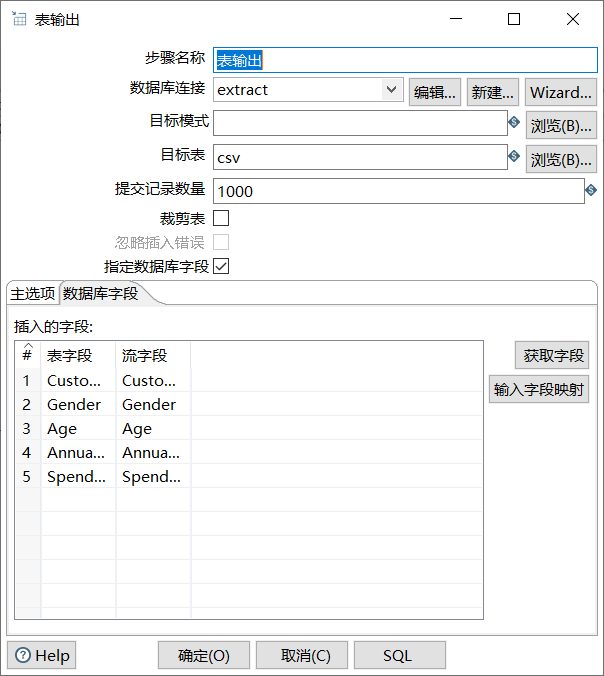
“表输出”控件配置的最终效果,具体如图所示:
单击转换工作区顶部的开始按钮,运行创建的csv_extract转换。
结果如图所示:
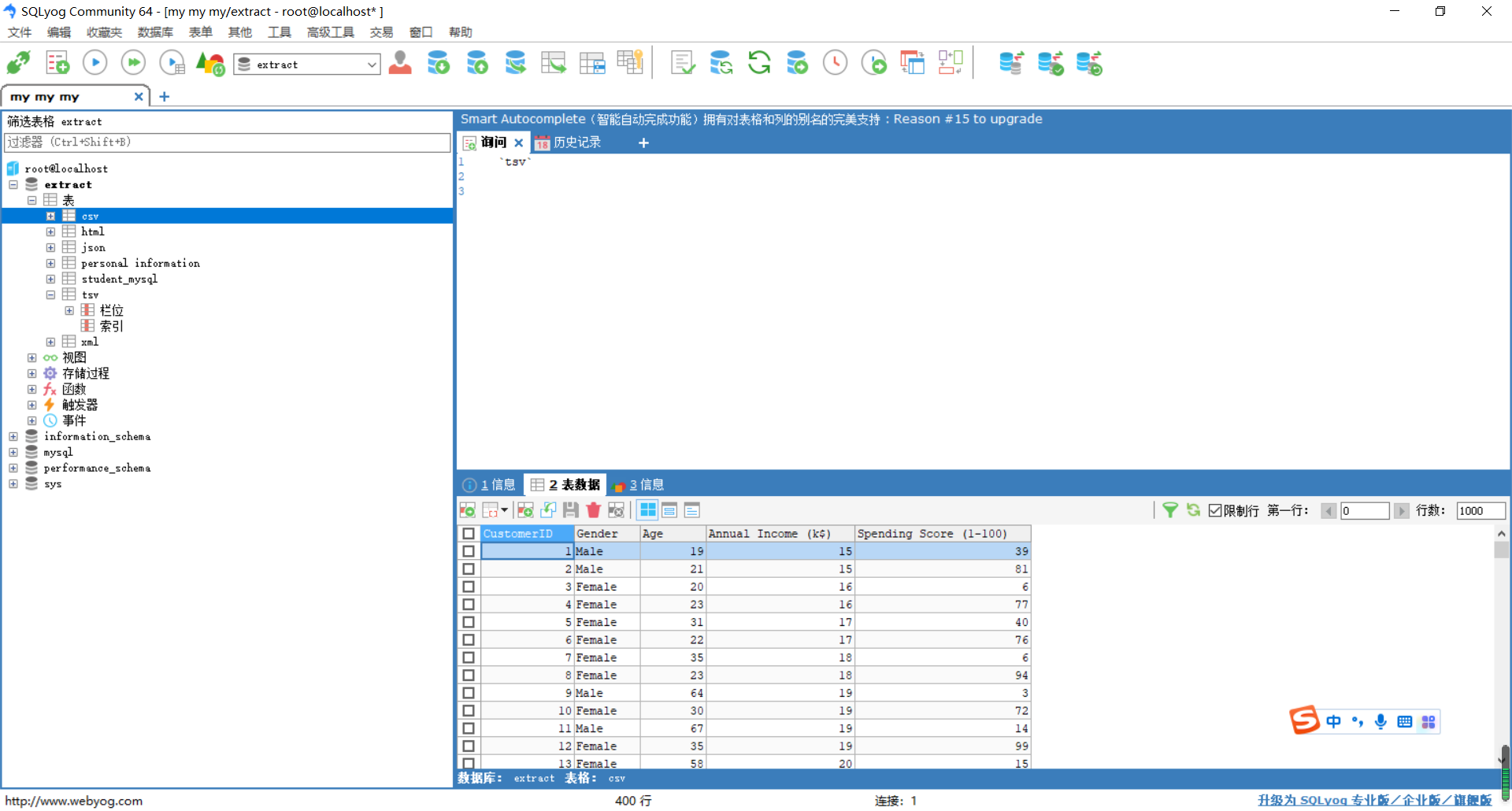
通过SQLyog工具,查看数据表csv是否已成功插入100行数据。
-
HTML网页的数据抽取
HyperText Markup Language,简称HTML,即超文本标记语言,它包含了一套标记标签,主要用于创建和描述网页。HTML可以以文档的形式展示,HTML文档中包含HTML标签和纯文本。
通过使用Kettle工具,创建一个转换转换html_extract,并添加“自定义常量数据”输入控件、“HTTP client”查询控件和“Java代码”脚本控件。
具体如图所示:
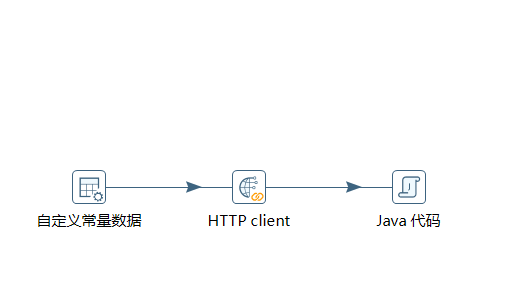
双击“自定义常量数据”控件,进入“自定义常量数据”界面。
具体如图所示:
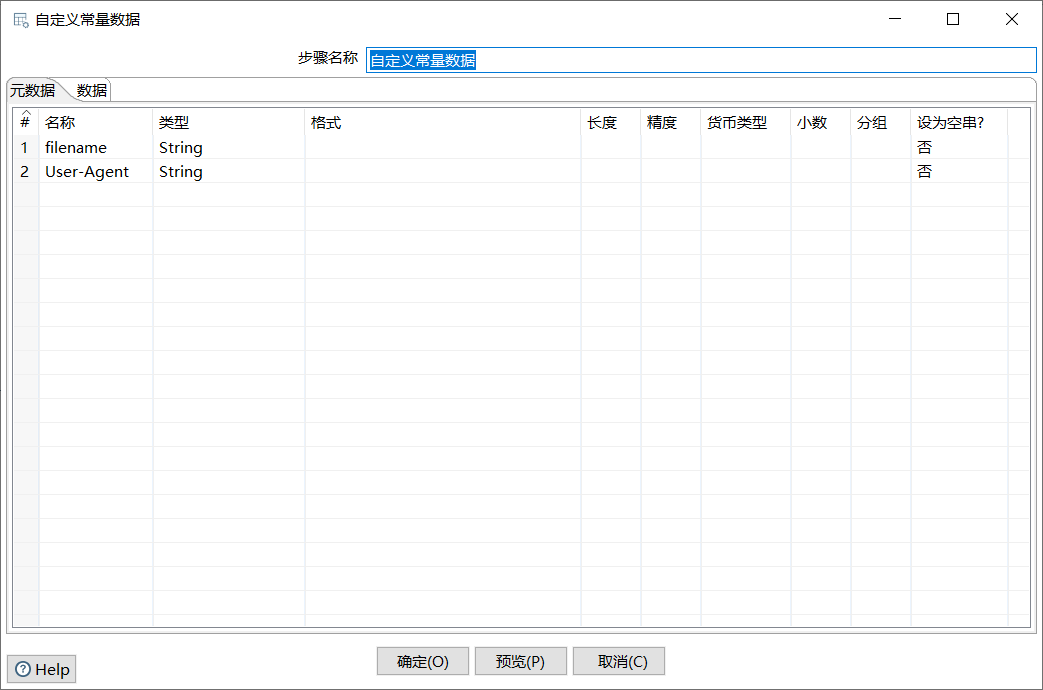
单击“元数据”选项卡,定义一个字段常量filename并指定数据类型String;单击“数据”选项卡,添加html形式数据所在的URL,即https://movie.douban.com/chart。
具体如图所示:
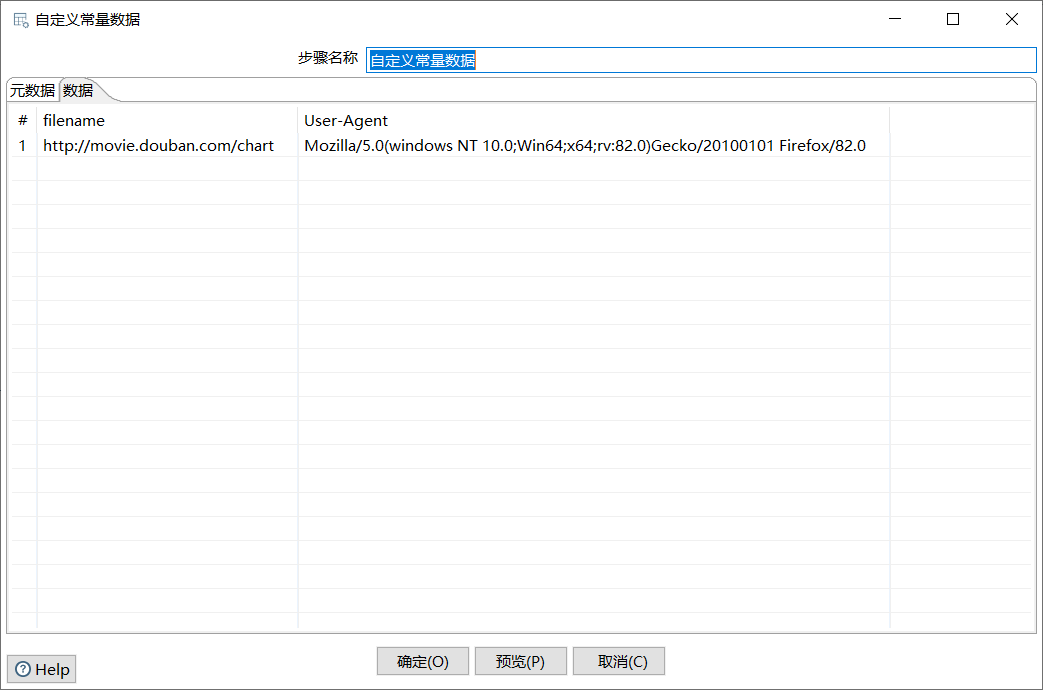
双击“HTTP client”控件,进入“HTTP web service”界面;
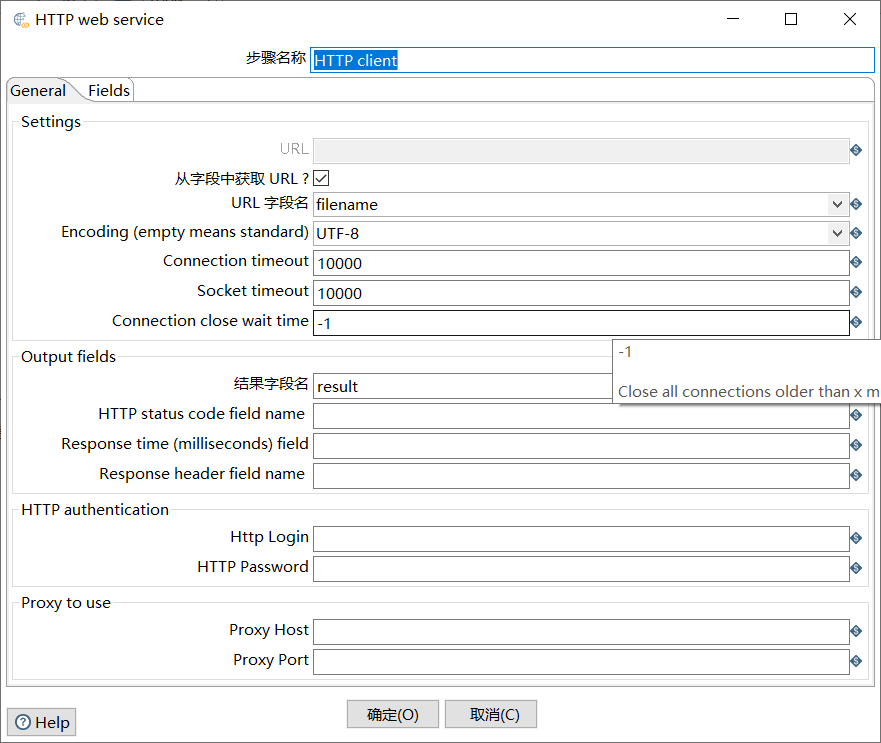
勾选图4-40的“从字段中获取URL?”的复选框;在“URL字段名”处的下拉框中选择URL字段名,即filename;在“结果字段名”处指定结果字段名称,这里选择默认的结果字段result。
如图所示:
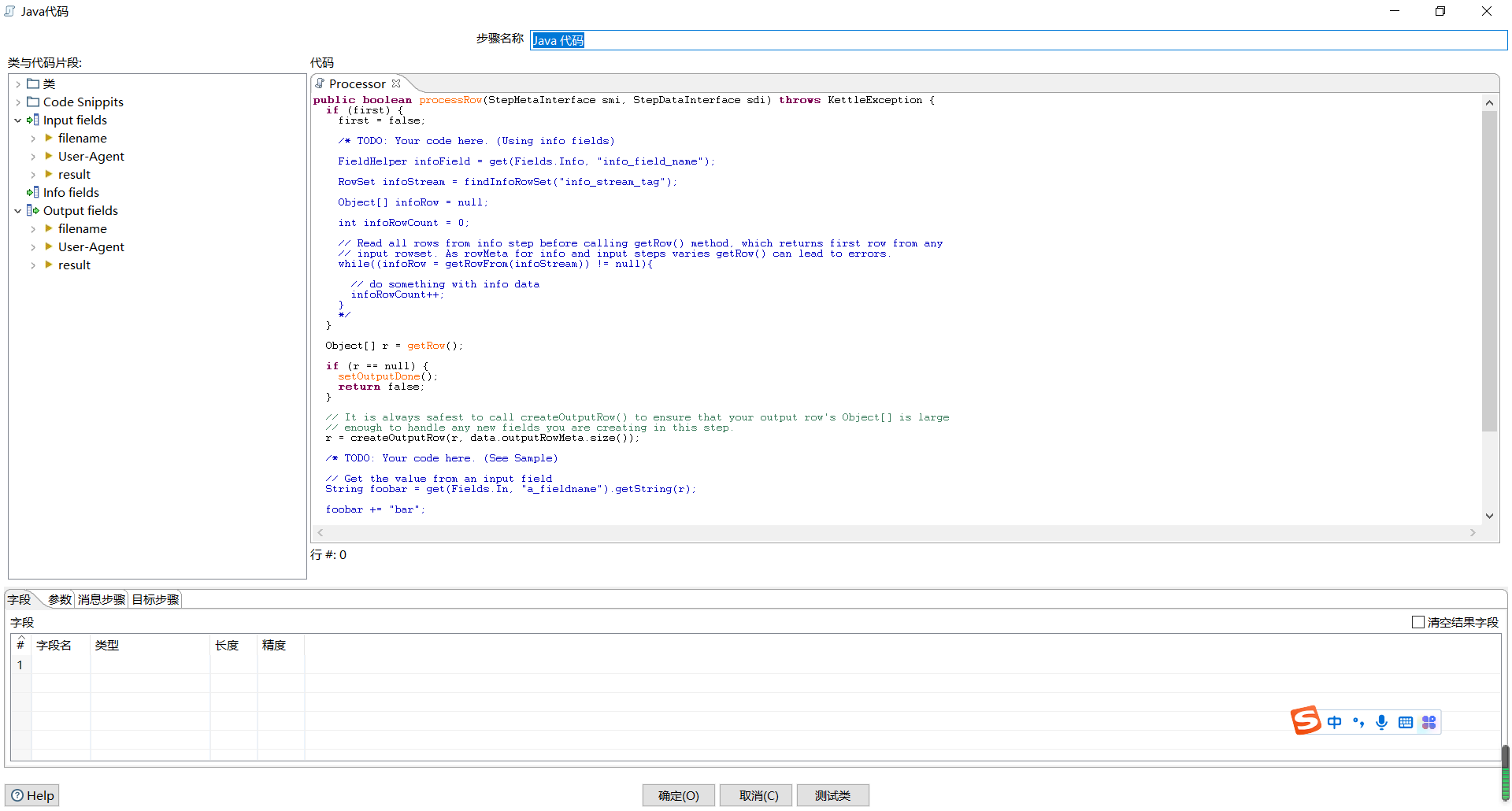
双击“Java”控件,进入“Java代码”界面;
双击“Code Snippits”→ “Common use”→ “Main”,添加Java脚本代码的主方法,即程序入口。
如图所示:
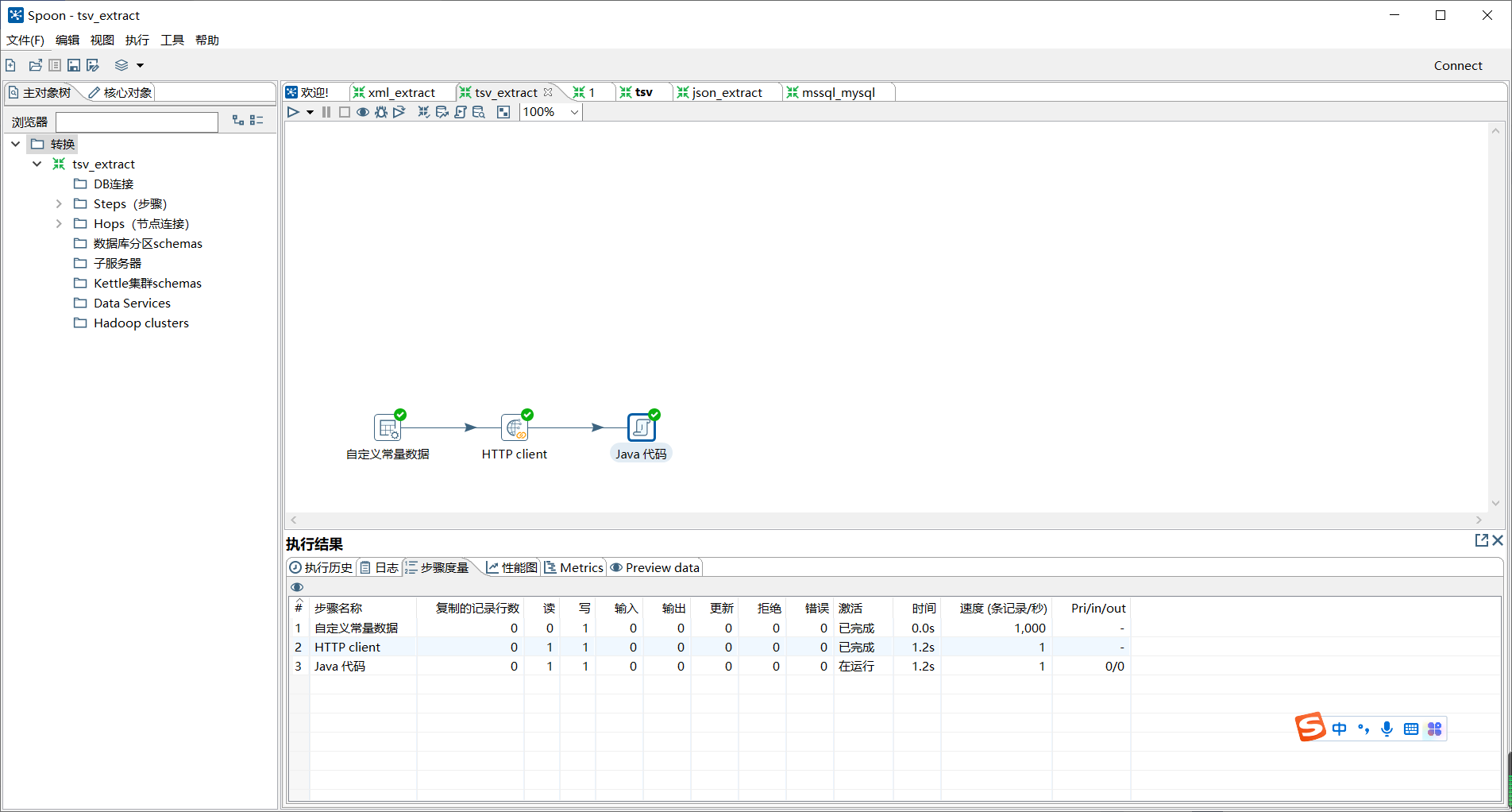
单击转换工作区顶部的开始按钮,运行创建的html_extract转换;
如图所示:
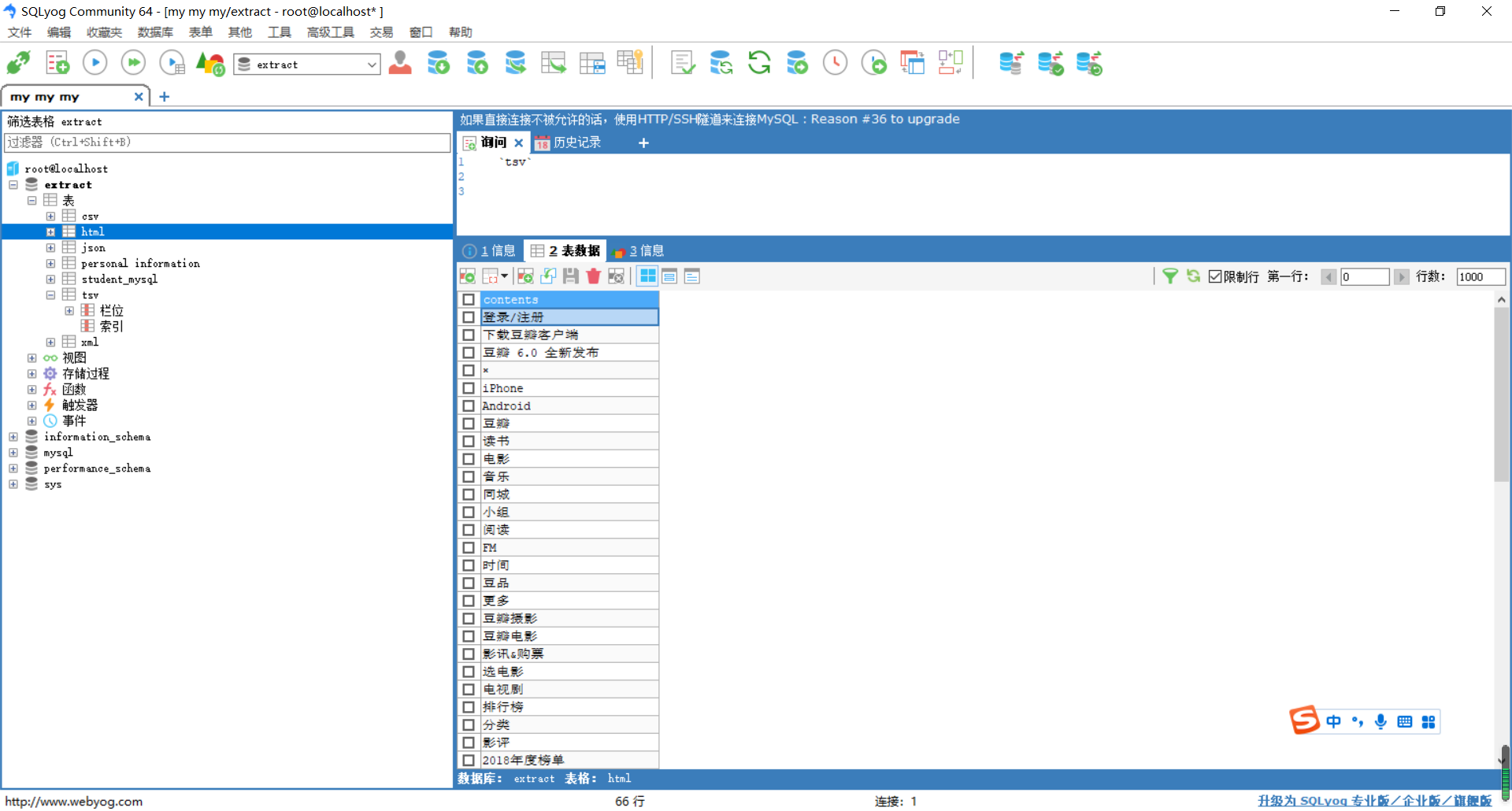
通过SQLyog工具,查看数据表html是否已成功插入66行数据。
如图所示:
-
XML文件的数据抽取
XML是一种可扩展标记语言,也是一种元标记语言,所谓“元标记”就是开发者可根据自己的需要自定义标记。XML是一种很像HTML的标记语言,但是它们也有很大的区别,譬如XML被设计出来主要用于传输和存储数据,其焦点是数据的内容,而HTML被设计出来主要用于显示数据,其焦点是数据的外观;XML中的标签是没有被预定义的,都是由XML文档的创作者发明的,HTML中的标签是预定义的,其文档中使用的标签必须是在HTML标准中定义过的,对于用户自己定义的标签是不可使用的。
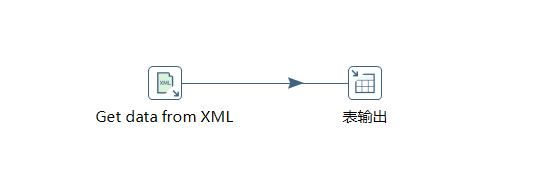
通过使用Kettle工具,创建一个转换转换xml_extract,并添加“Get data from XML”控件、“表输出”控件以及Hop跳连接线。
具体如图所示:
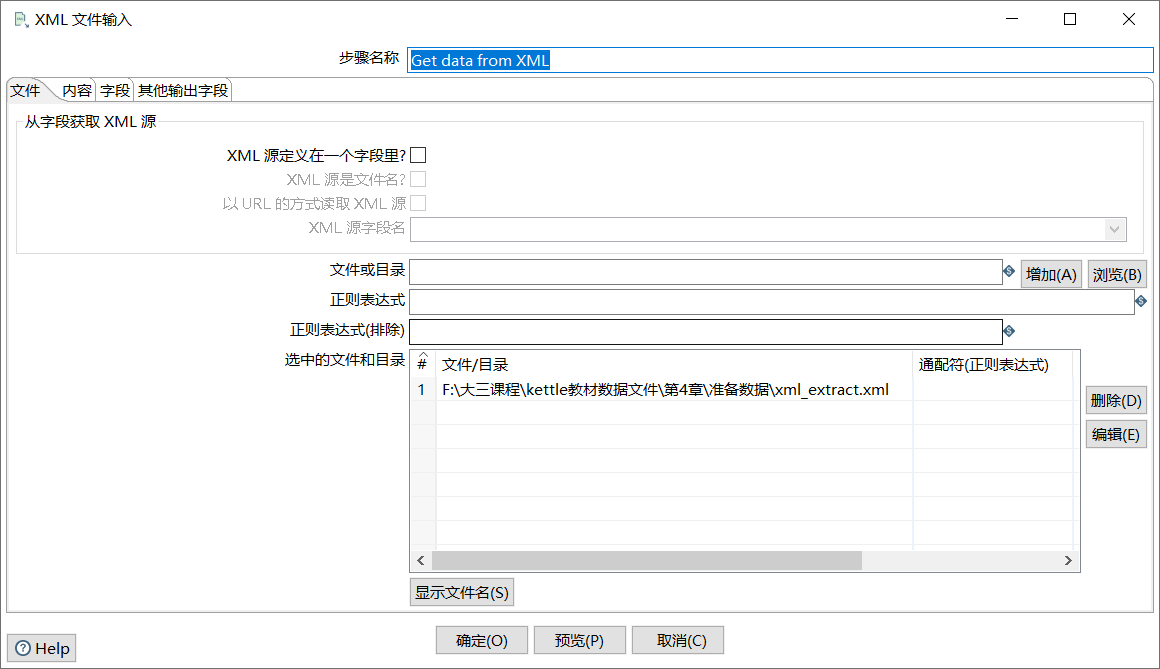
双击“Get data from XML”控件,进入“XML文件输入”界面;
单击【浏览】按钮,选择要抽取的XML文件xml_extract.xml;
如图所示:
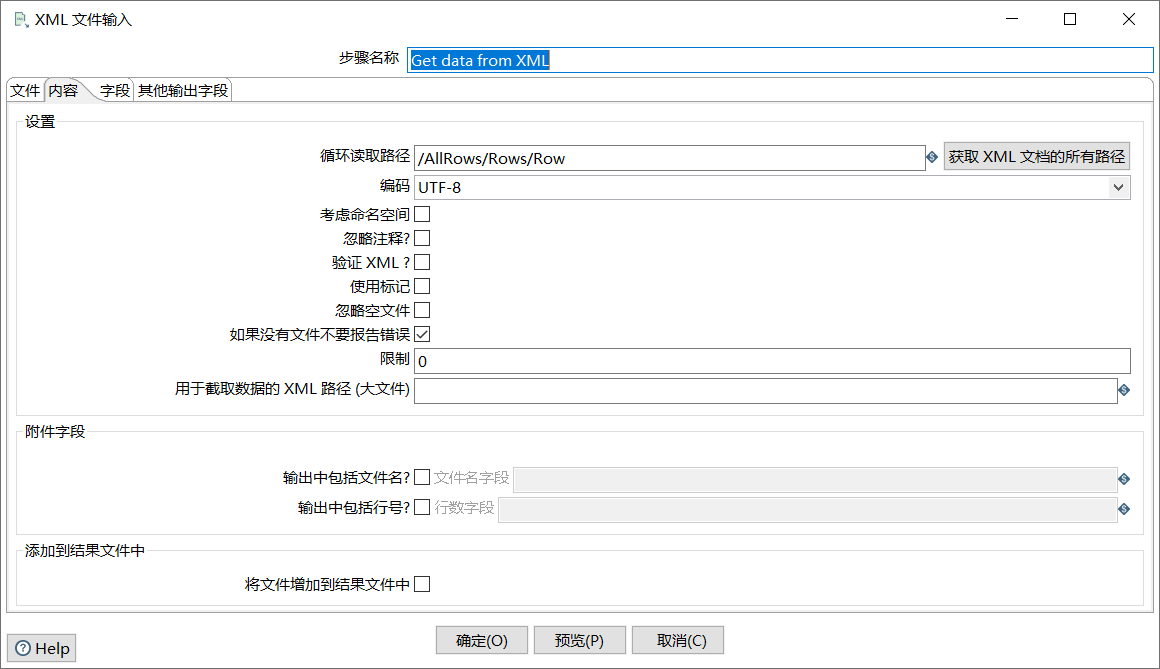
单击“内容”选项卡,单击【获取XML文档的所有路径】选择循环读取路径,即/AllRows/Rows/Row。
如图所示:
单击“字段”选项卡,添加要抽取的字段。如图所示:
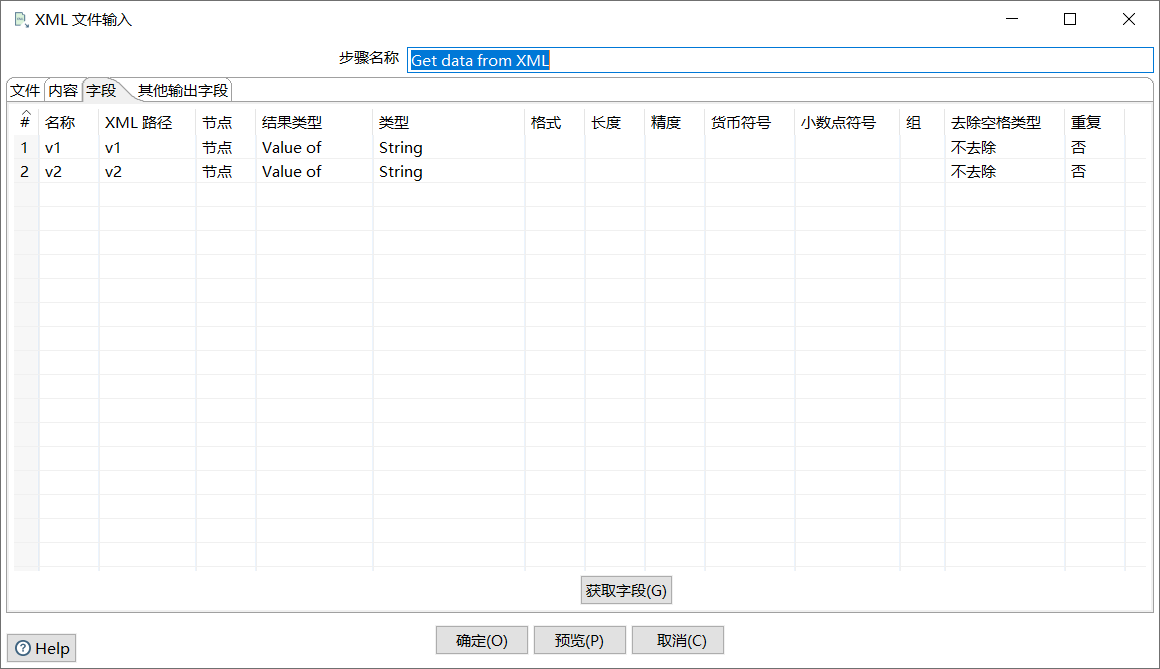
双击“表输出”控件,进入“表输出”配置界面;
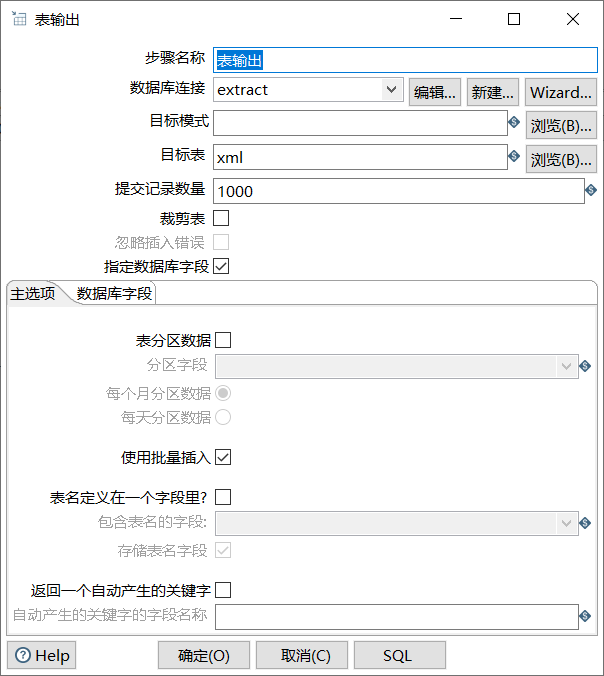
单击目标表右侧的【浏览】按钮,选择输出的目标表,即xml数据表;勾选“指定数据库字段”的复选框,用于将数据表xml的字段与XML文件xml_extract.xml文件中的字段进行匹配;
具体如图所示:
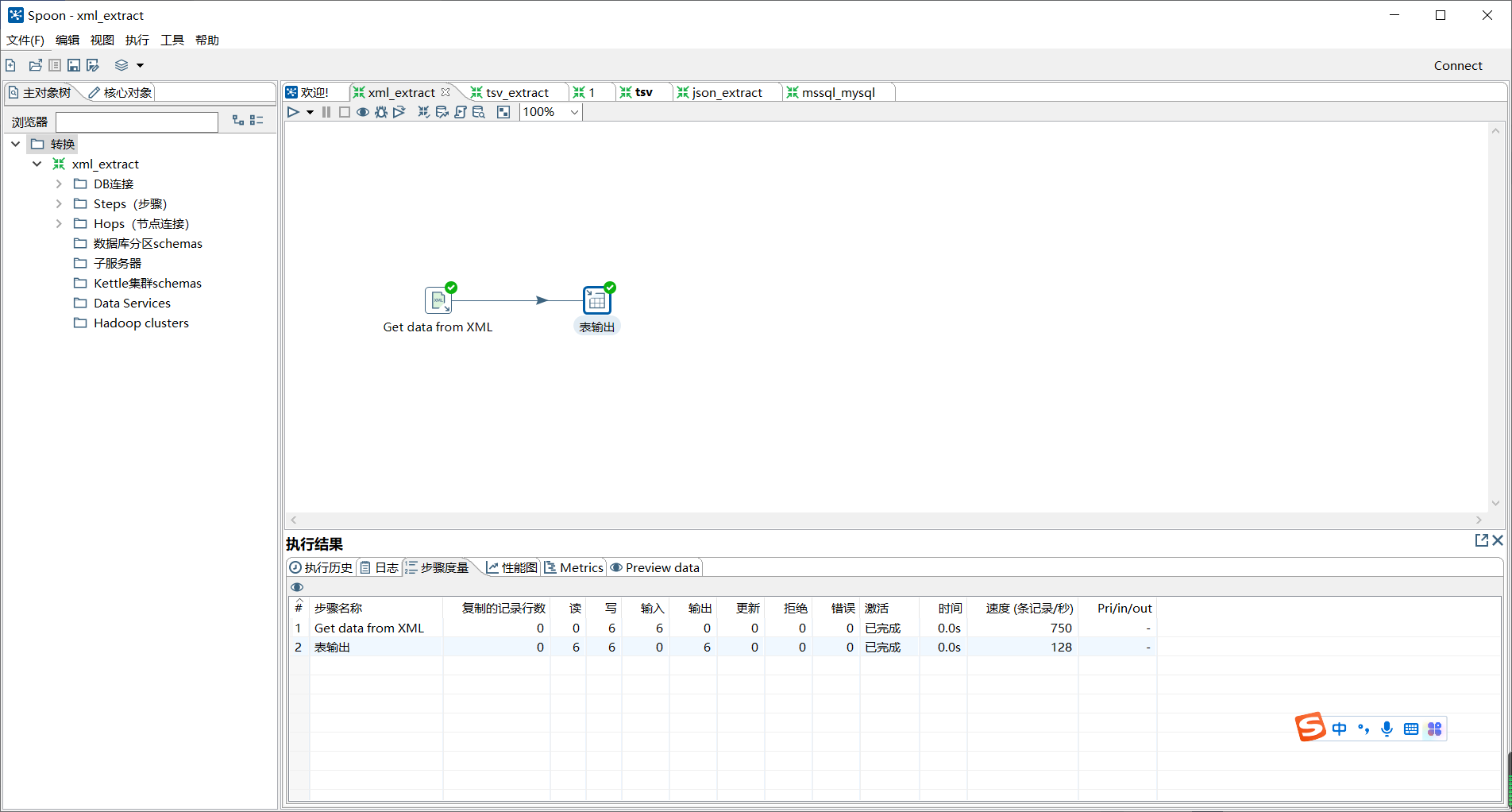
单击转换工作区顶部的开始按钮,运行创建的xml_extract转换。
如图所示:
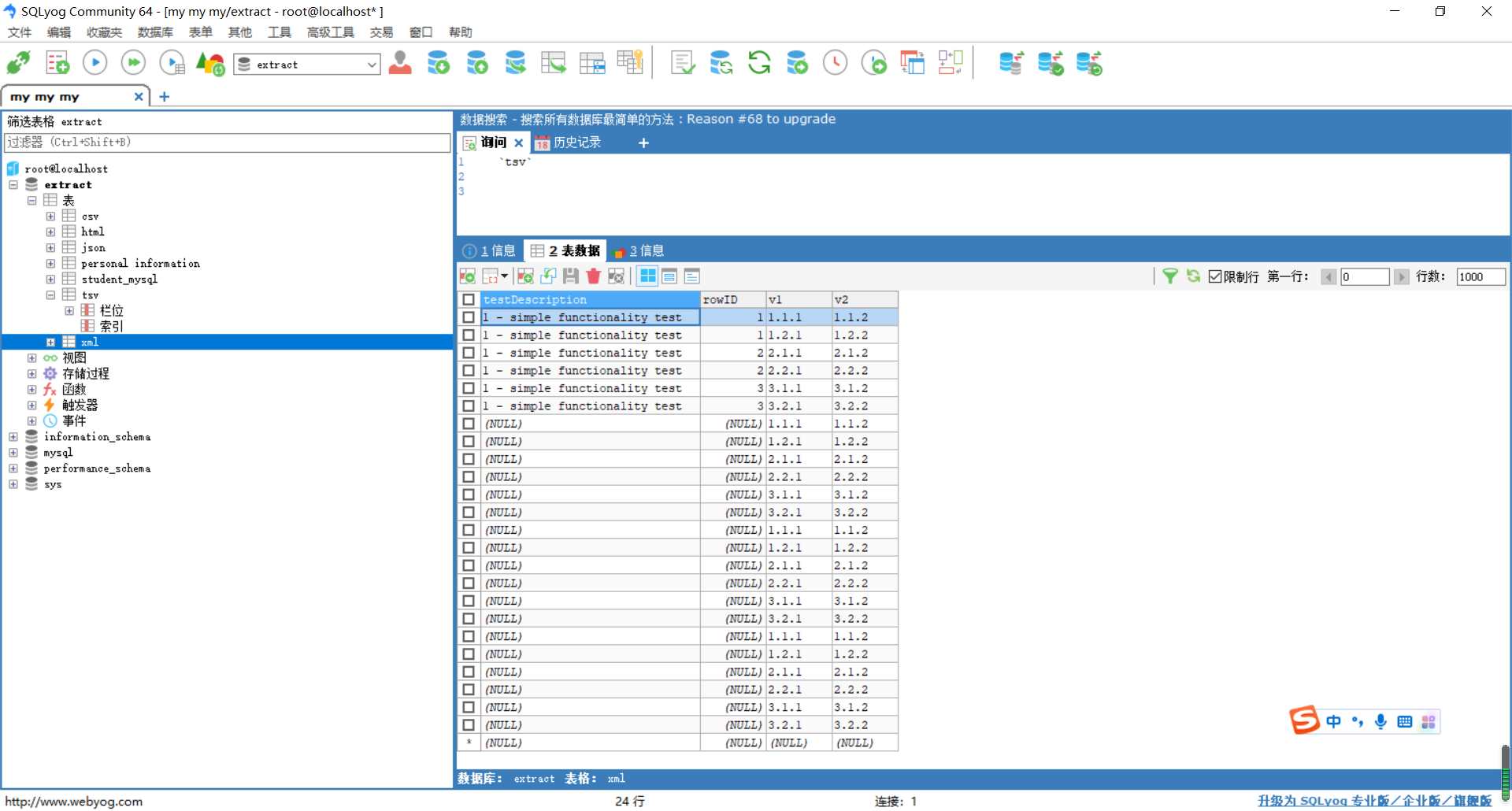
通过SQLyog工具,查看数据表xml是否已成功插入6条数据。
如图所示:
-
JSON文件的数据抽取
JSON(JavaScript Object Notation,即JS对象标记)是一种轻量级的数据交换格式,它是基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,从JavaScript脚本语言中演变而来的,采用完全独立于编程语言的文本格式来存储和表示数据。
双击“JSON input”控件,进入“JSON输入”界面;
单击【浏览】按钮,选择要抽取的JSON文件json_extract.json;单击【增加】按钮,将所选择的文件添加到“选中的文件和目录”处。
如图所示:
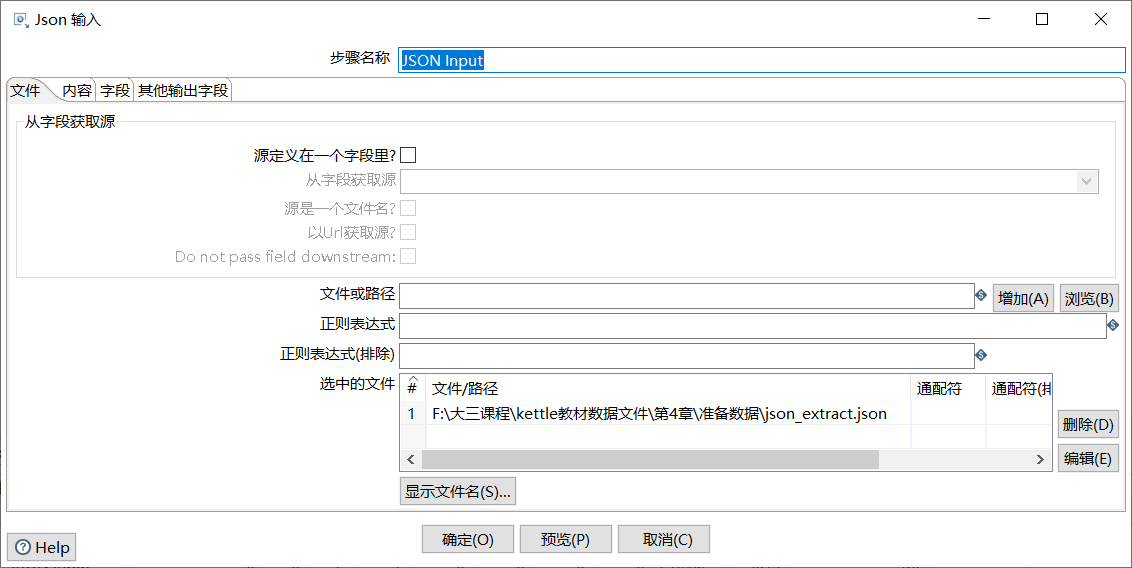
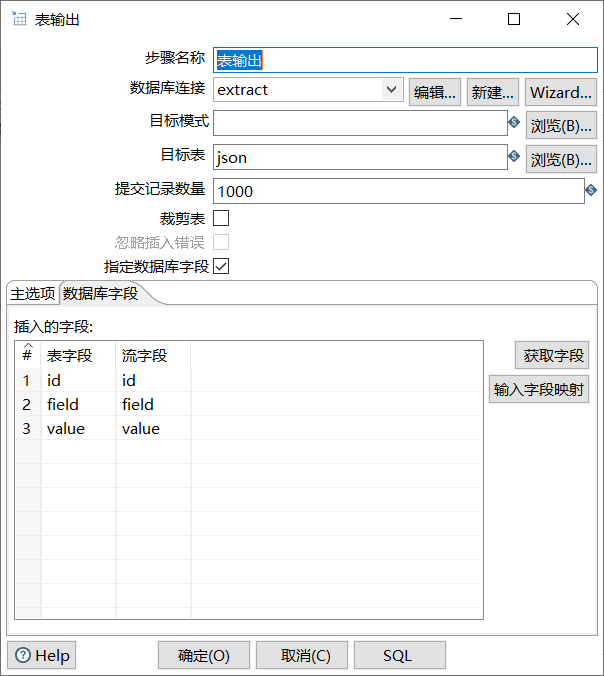
单击“字段”选项卡,添加要抽取的数据字段(这里采用分层抽取数据字段,先抽取id和data字段,再从data字段中抽取field和value字段)。
如图所示:
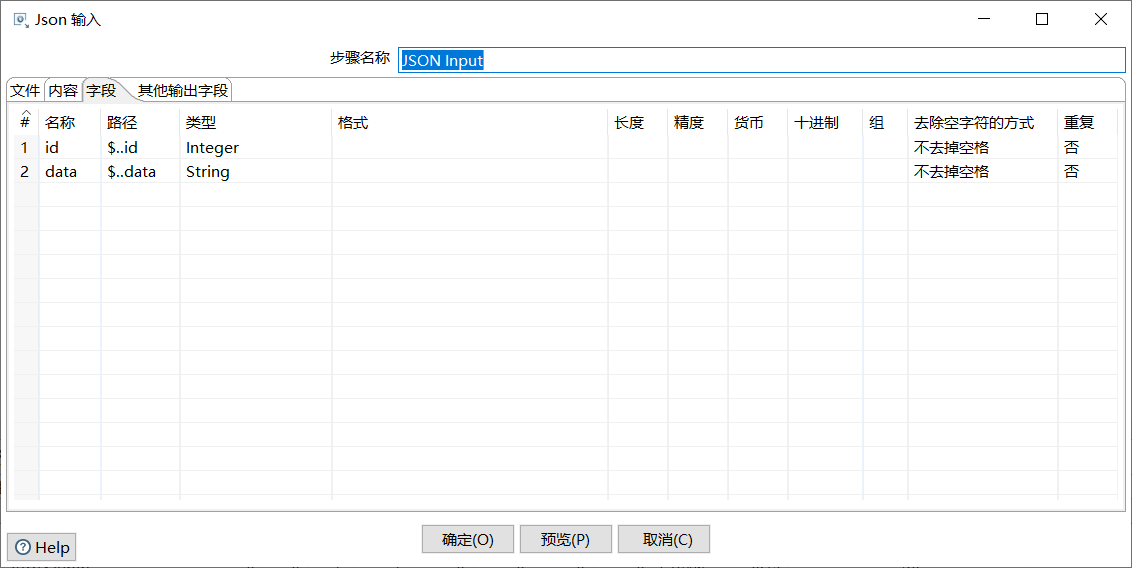
双击“JSON input 2”控件,进入“JSON输入”界面;
勾选“源定义在一个字段里?”的复选框;在“从字段获取源”处的下拉框中选择字段名,即data。
如图所示:
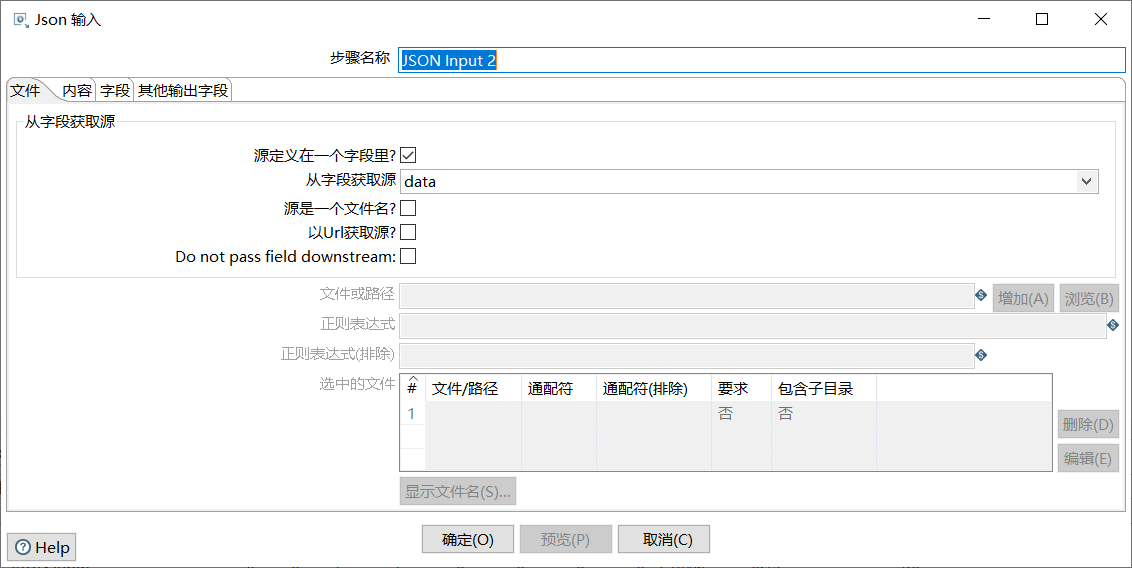
单击“字段”选项卡;添加从字段data中抽取的field和value字段。
如图所示:
双击“表输出”控件,进入“表输出”配置界面;
单击目标表右侧的【浏览】按钮,选择输出的目标表,即数据表json;勾选“指定数据库字段”的复选框,用于将数据表json的字段与JSON文件json_extract.json中的字段进行匹配。
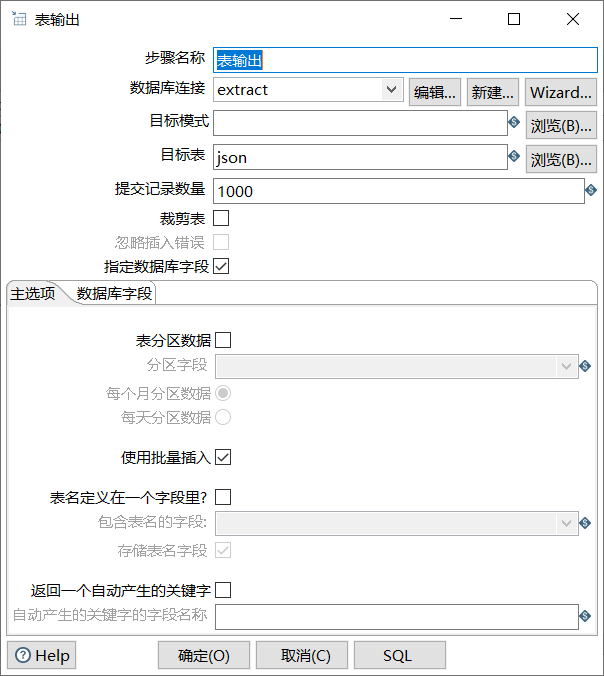
“表输出”控件配置的最终效果。
如图所示:
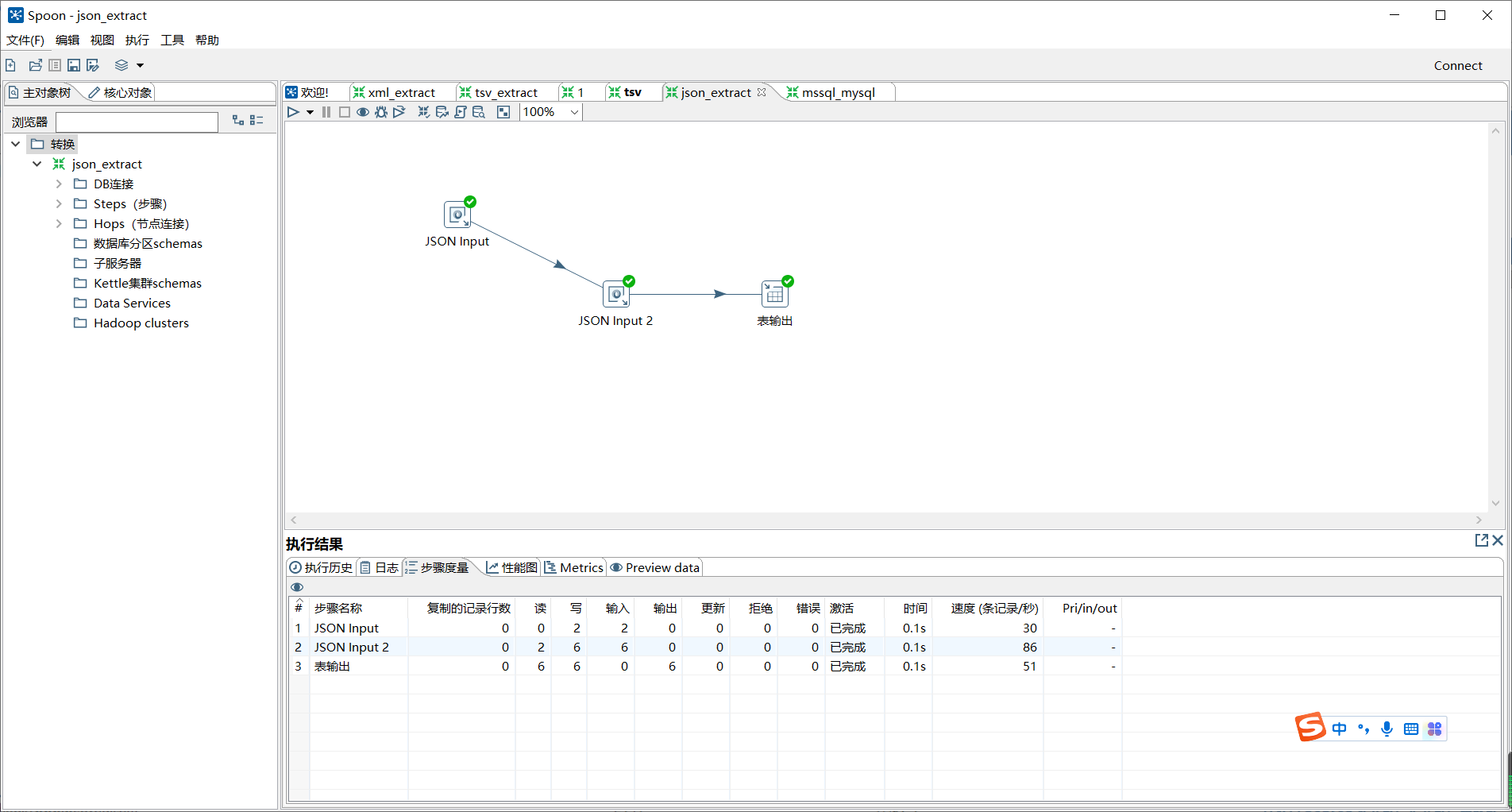
单击转换工作区顶部的开始按钮,运行创建的json_extract转换。
如图所示:
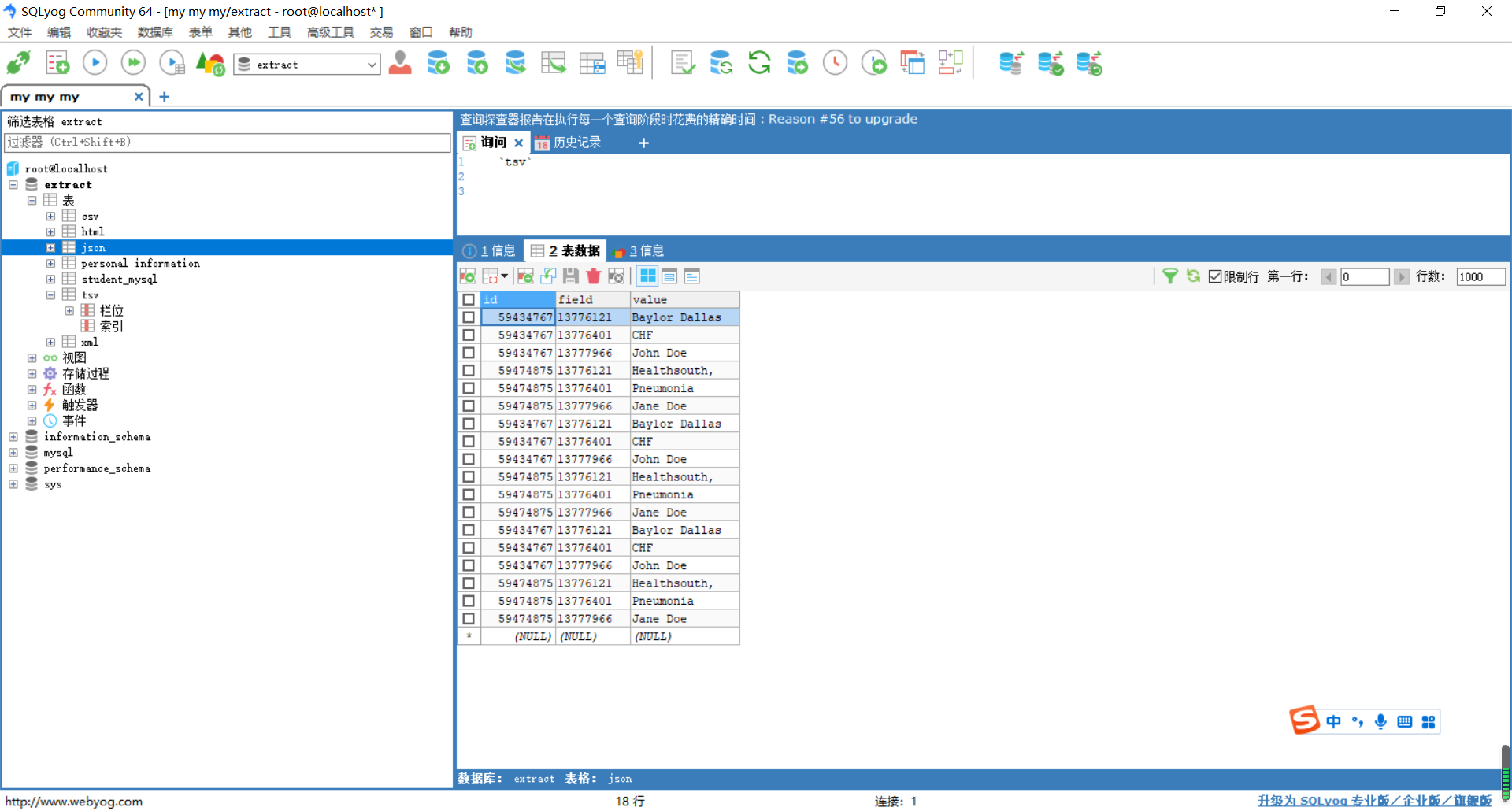
通过SQLyog工具,查看数据表json是否已成功插入6条数据;
如图所示:
-
抽取非关系型数据库的数据
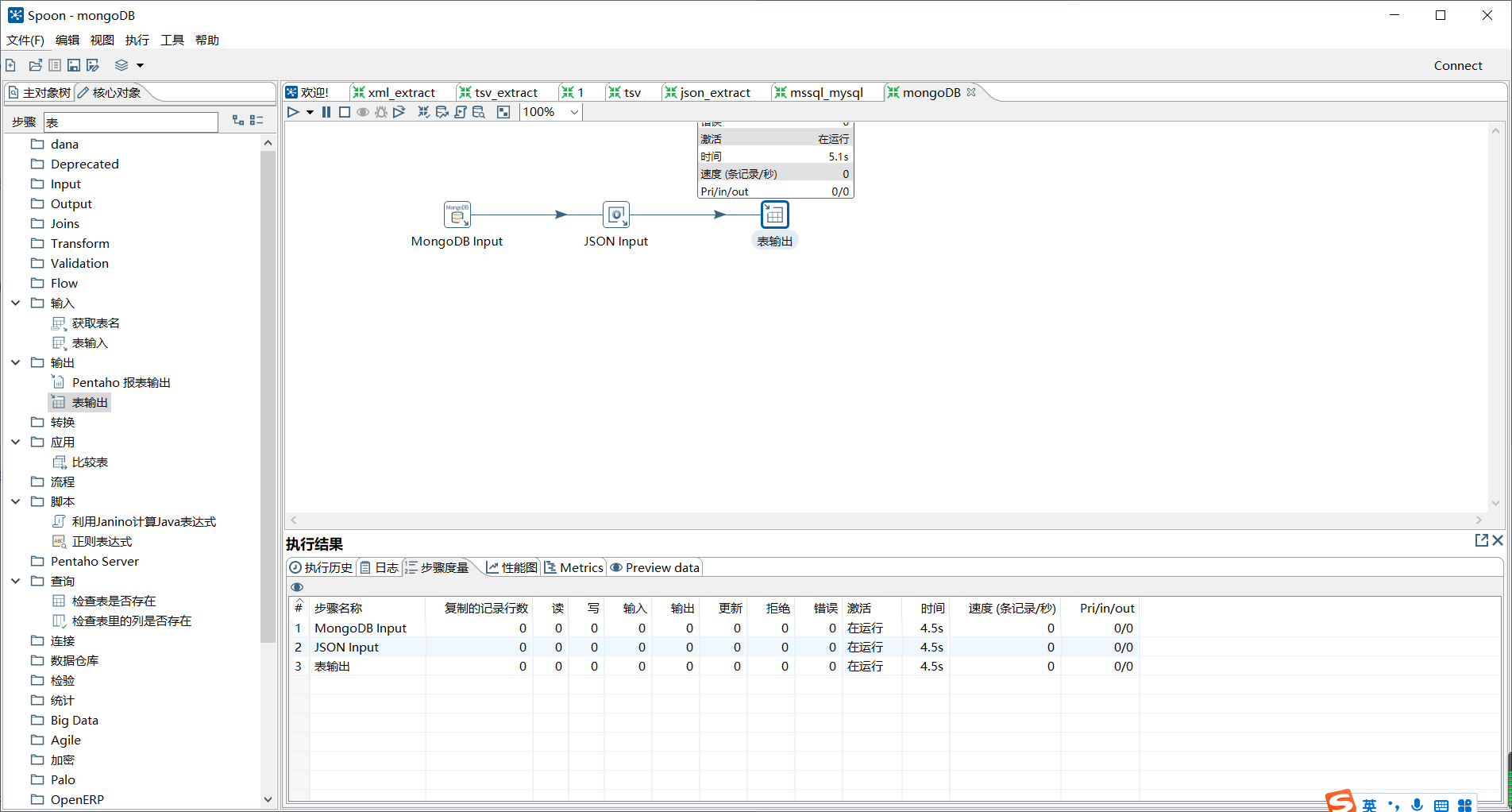
通过使用Kettle工具,创建一个转换mongodb_mysql_extract,并添加“MongoDB input”控件、“JSON input”控件、“表输出”控件以及Hop跳连接线。
具体如图所示:
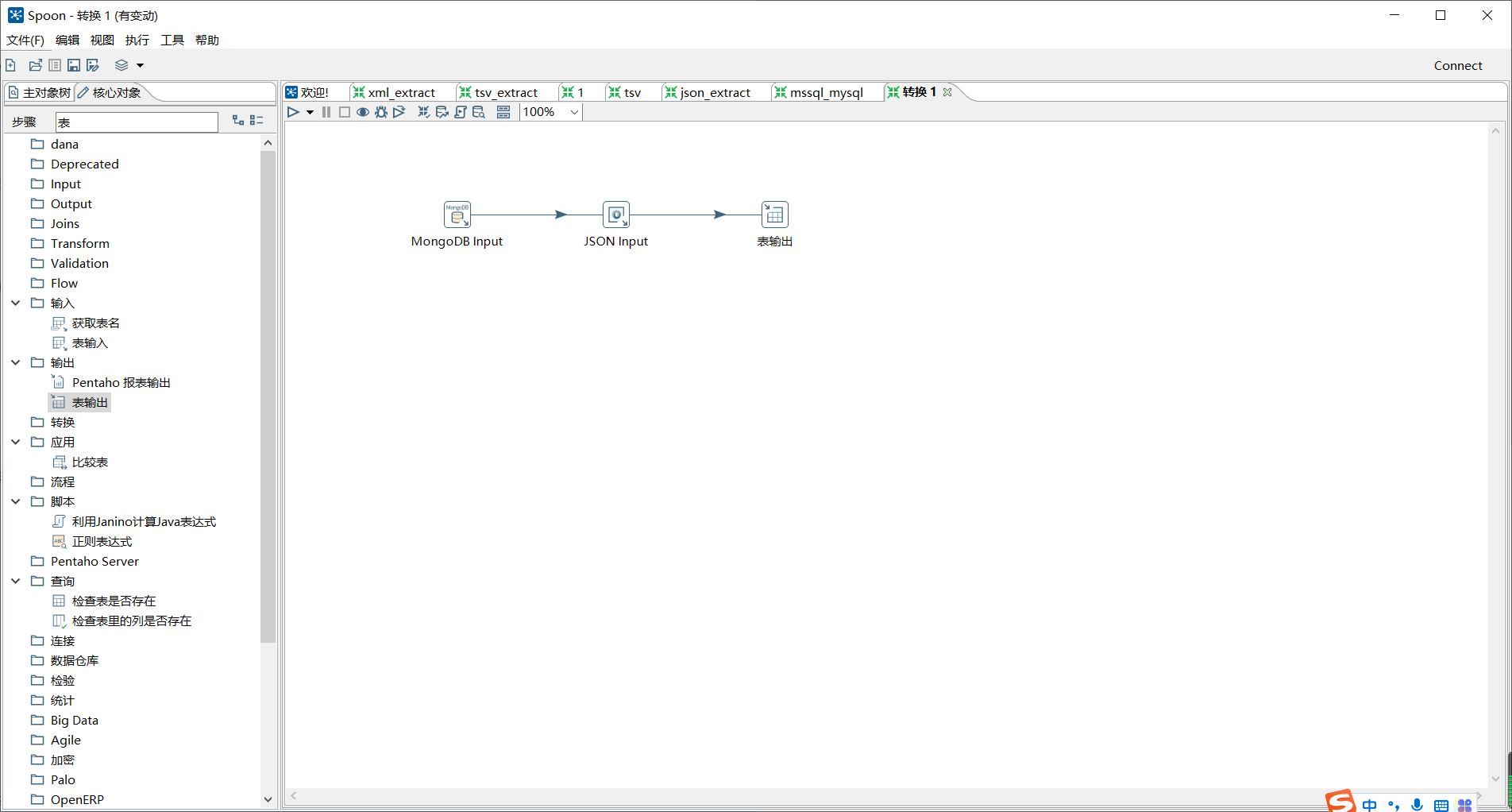
双击“MongoDB input”控件,进入“MongoDB input”配置界面;
单击“Input options”选项卡,指定数据库和数据表,即在“Database”处添加数据库mongodb_mysql,在“Collection”处添加集合Personal information;
如图所示:
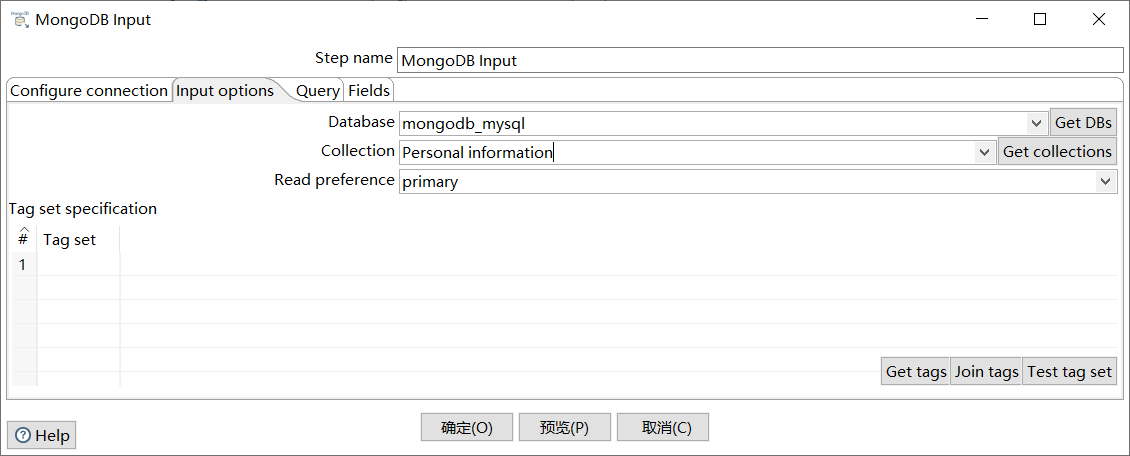
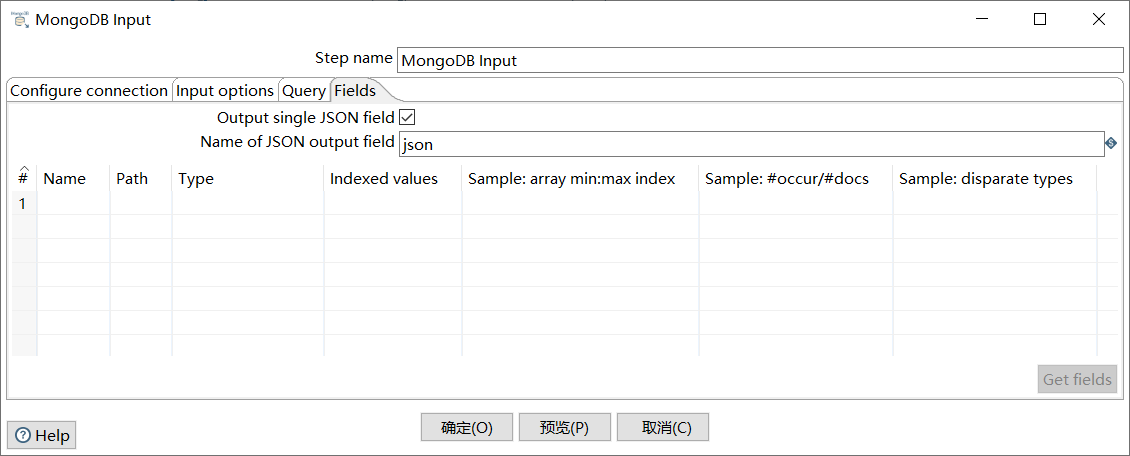
单击“Fields”选项卡,勾选“Output single JSON field”的复选框,并在“Name of JSON output field”处指定输出的字段名为json;
如图所示:
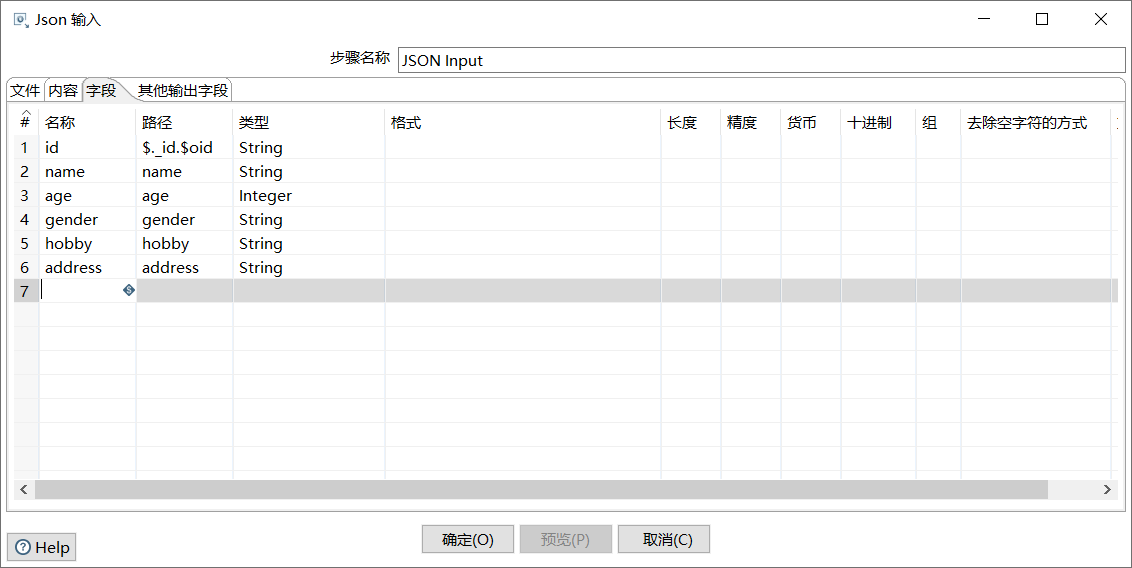
双击“JSON input”控件,进入“JSON input”配置界面;
单击“文件”选项卡,配置数据的获取源,勾选“源定义在一个字段里?”的复选框,在“从字段获取源”的下拉框中选择从json字段获取数据;
单击“字段”选项卡,添加要抽取的数据字段;
如图所示:
单击转换工作区顶部的开始按钮,运行创建的mongodb_mysql_extract转换;
具体效果如图所示:
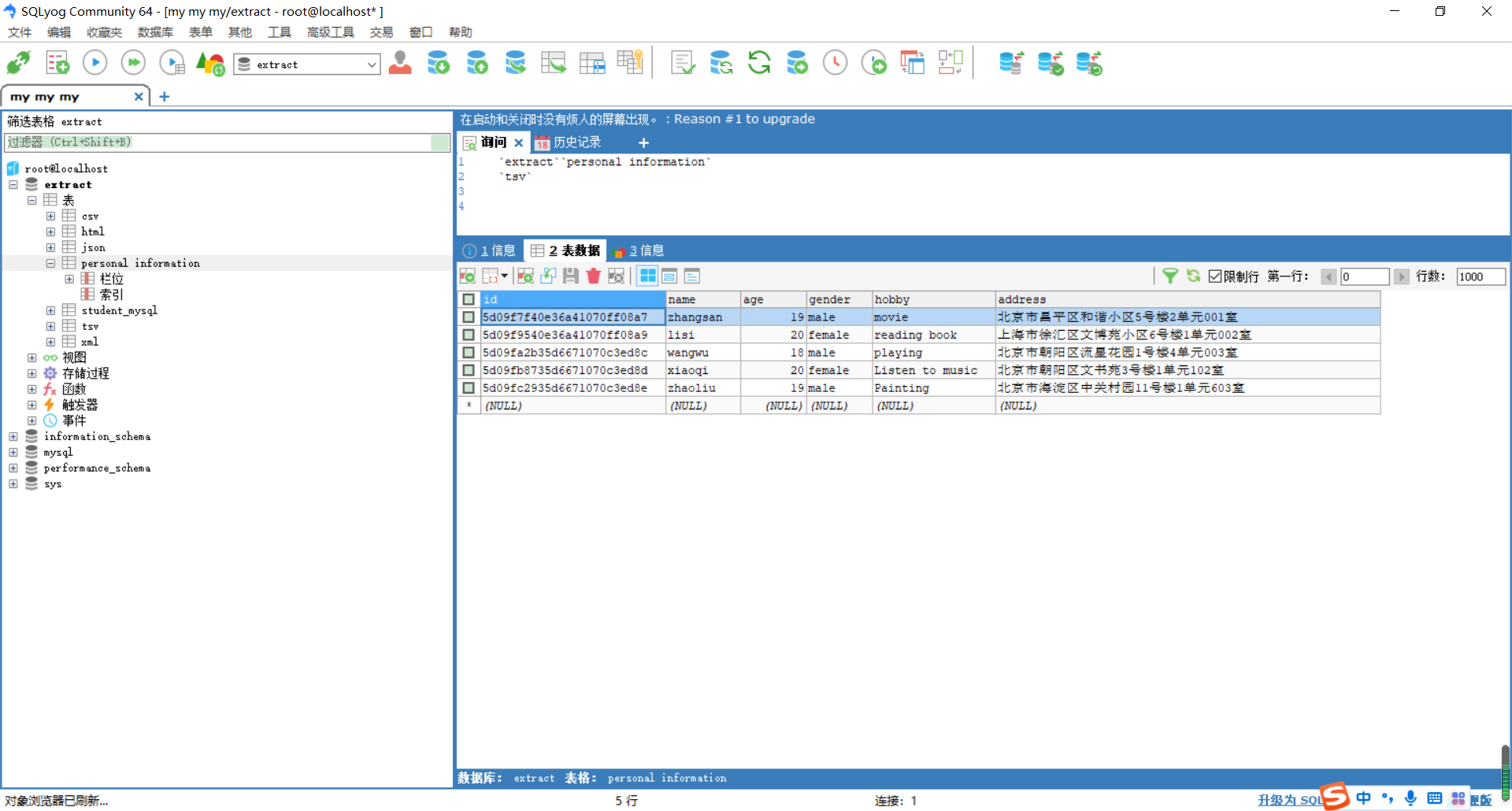
通过使用SQLyog工具,查看数据表Personal information是否已成功插入5条数据;
如图所示:
最后
以上就是妩媚短靴最近收集整理的关于数据抽取(加图)的全部内容,更多相关数据抽取(加图)内容请搜索靠谱客的其他文章。








发表评论 取消回复