安装使用pocketsphinx
折腾了我一宿,终于搞定,识别率虽然高了,但是识别速度实在太慢了,明天再找方法吧。需要补充一下睡眠。
首先安装speechrecognition和pocketphinx,还有一些其他的依赖库,在安装sonwboy的时候都安装好了,所以就不再列出来了,因为我也不知道具体是哪些。
下载安装
sudo apt-get install python3-dev
sudo apt-get install libevent-dev
sudo apt-get install libpulse-dev
pip3 install speechrecognition
pip3 install pocketsphinx
现在就可以实现英文的识别了,如果需要中文的,那么就需要用到中文的包:
安装中文包
1.在下面网址下载好压缩文件https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/
2.解压后得到这几个文件
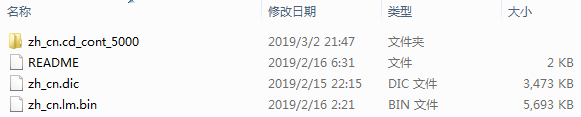
3.找到英文包的位置
一般会在/home/pi/.local/lib/python3.5/site-packages/speech_recognition/pocketsphinx-data/en-US中,进入目录后将上面的文件夹、.dic文件和.lm.bin文件的名称改为目录中对应文件的名称,删除原来的三个文件。
这个时候就可以识别中文了,但是准确率不是很高!
小范围提高准确度
所谓小范围提高准确度,就是把.dic文件中,不需要的内容删掉,只留下需要识别的内容。
例如:
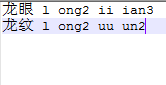
如果只留下这两个词,其他的都删掉,那么就会提高这两个词的识别率。
训练自己的模型
进入这个网址这个网址中,
http://www.speech.cs.cmu.edu/tools/lmtool-new.html

选择自己的.txt文件上传,内容是自己想要识别的内容,格式如图:

然后就会跳转到另一个网页:
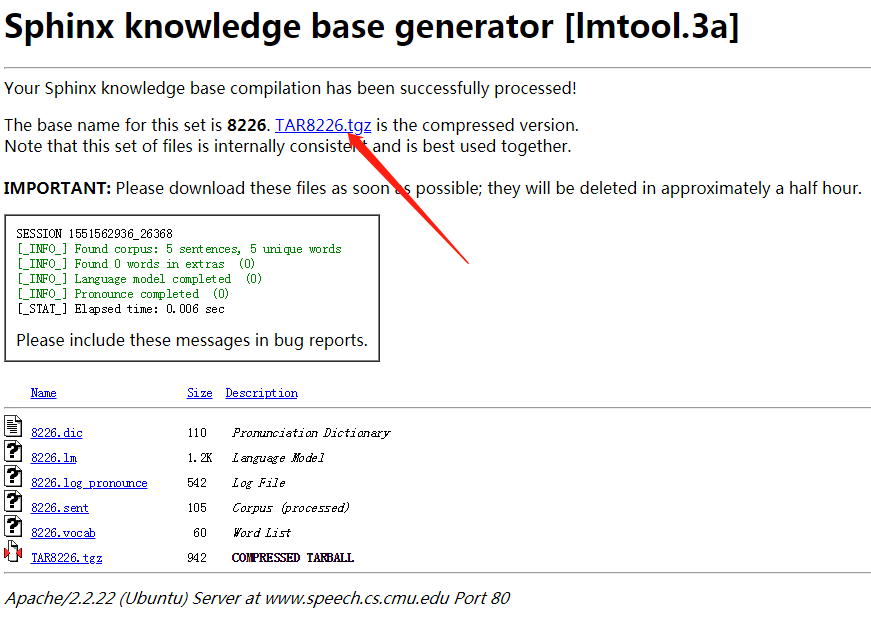
点击下载压缩包,解压后把其中.lm文件尾缀改成.lm.bin,文件名的改法同上,然后替换.lm.bin文件就好了。
这么做原以为自己训练会加快速度,但是实测中好像没有增加,但是好像增加了一点识别的准确度。
一个demo
import speech_recognition as sr
r = sr.Recognizer()
harvard = sr.AudioFile('my_word.wav') #t同文件夹下的录音文件
with harvard as source:
audio = r.record(source)
try:
print(r.recognize_sphinx(audio))
except sr.UnknownValueError:
print('not understand')
except sr.RequestError as e:
print('internet broken')
至此就结束了,希望能帮到大家!
最后
以上就是清新冬瓜最近收集整理的关于树莓派3b+指南(十六)安装使用pocketsphinx的全部内容,更多相关树莓派3b+指南(十六)安装使用pocketsphinx内容请搜索靠谱客的其他文章。








发表评论 取消回复