论文解读:Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning (2018 ACL)
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | Deep Dyna-Q (DDQ) |
| 2 | 所属领域 | 问答系统,强化学习 |
| 3 | 研究内容 | 任务型多轮对话 |
| 4 | 核心内容 | Dyna架构,Q学习 |
| 5 | GitHub源码 | https:// github.com/MiuLab/DDQ |
| 6 | 论文PDF | https://www.aclweb.org/anthology/P18-1203.pdf |
一、动机:
- 任务完成型对话(Task-completion Dialogue)可以被建模为一个强化学习问题,其需要获得智能体与环境的真实交互数据,但是不同于一些模拟类游戏(Atari、AlphaGo等),如果出现故障,任务完成对话系统可能会产生大量的实际成本,同时如果重头训练一个具有真实用户交互的强化学习模型消耗过大。
- 目前解决这类问题的一个方法是使用用户模拟器(User Simulator),其可以只使用少量的真实用户的交互数据,在理论上可以无限制地与模拟器进行交互并训练强化学习模型。然而用户模拟器通常不具备真实对话者的复杂性(即恢复非常的简单),同时,不可避免地会受到带有偏向的对话设计的影响,与模拟器和真实用户对话依然产生很大的差异,与此同时,现如今很难找到一个合理的评价指标来衡量模拟器的性能,使得是否继续使用模拟器来训练强化学习备受争议。
二、方法
本文提出一种以Dyna架构为主的任务完成型对话方法。Dyna架构原始图如下所示:
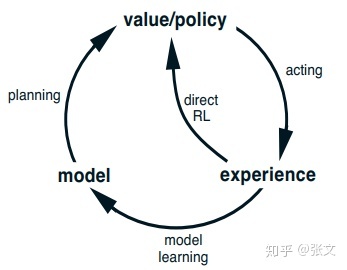
强化学习一般分为基于模型的方法(model-based)和不基于模型的方法(model-free)。前者是根据训练好的模型作为一个模拟器,来直接与智能体进行交互,其不需要获得经验数据。其也叫做间接强化学习。典型的model-based就是动态规划法。但模型绝大多数时候不能准确的描述真正的环境的转化模型,那么使用基于模型的强化学习算法得到的解大多数时候也不是很实用。model-free则是完全依靠交互数据,通常需要大量的真实场景的交互,也称作直接强化学习。
因此Dyna框架旨在将二者结合起来
本文提出的方法如下图(c):
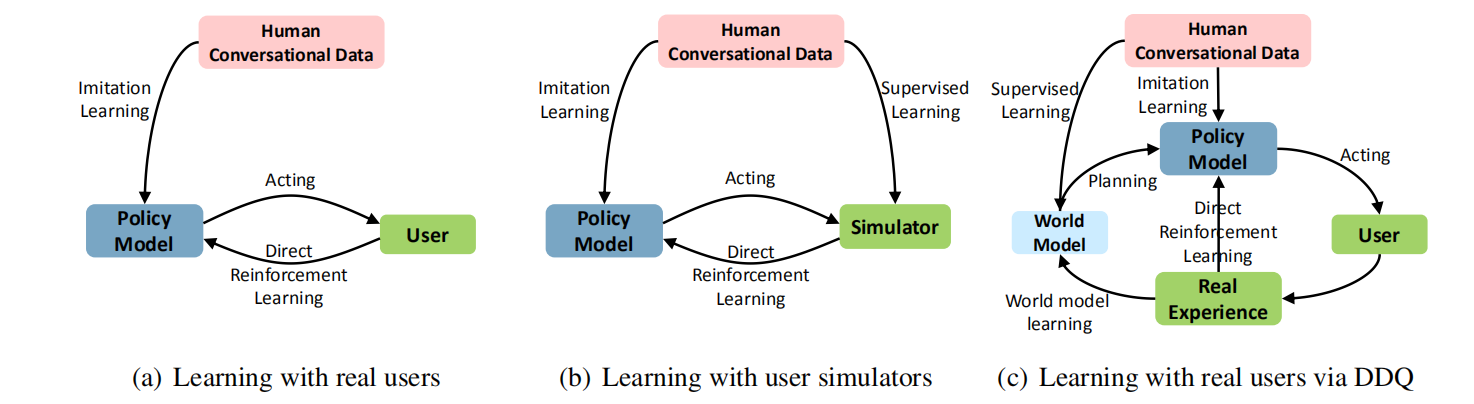
- 对比Dyna框架,其添加了一个model部分,本文叫做world model。其次经验数据可以用于两个角度:一方面可以使用监督学习训练world model,以作为model-based的方法,模拟交互;另一方面则可以直接让智能体学习策略,即model-free的方法。因此对话策略可以通过经验来提升效果,也可以通过训练的world model实现规划(planing)。
- 传统的Dyna框架是结合Q学习,其是一种基于离散表格的学习方法,通过使用表格来保存状态、动作和价值,并采用查表的方法实现model-based,这种传统的方法无法适用于大规模或无穷状态的学习,因此使用基于神经网络的方法,并提出 Deep Dyna-Q (DDQ) 算法
三、贡献
- 我们介绍了Deep Dyna-Q,据我们所知,这是第一个结合了任务完成对话策略学习计划的深度RL框架。
- 我们证明了任务完成对话智能体可以通过RL与实际用户进行交互,从而可以有效地动态调整其策略。 这将显着提高非平凡任务的成功率。
四、任务型对话框架
现如今的任务型对话主要采用pipeline流水线模式,包含三个架构,分别如下:
(1)自然语言理解(NLU):自然语言理解目标是为了识别用户的意图以及完成语义槽填充,包括:
- 用户意图识别(user intent identification):本质上属于短文本多类分类问题,常用方法包括基于词典模板、历史意图和日志分析以及用户画像;
- 语义槽填充(Slot Filling):从大规模的语料中抽取实体query的属性slot值。本质上是实现定义好槽,然后采用实体识别等信息抽取工具将相应的事件实体填充到预定义的槽。由于其本质是抽取实体,所以可以建模为序列标注问题
(2)对话管理:用于控制对话的过程,负责识别出下一步采用什么动作,多采用强化学习的reward驱动的实现。
(3)自然语言生成:通常可以使用端到端的方式进行自然语言生成。
五、本文方法
框架图如下所示:
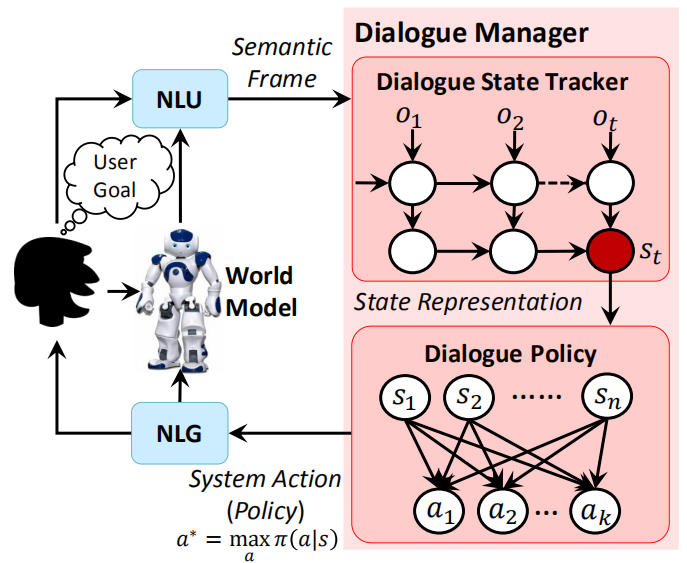
主要包含5个模块:
(1)自然语言理解(Natural Language Understanding):包括意图识别和语义槽填充;
(2)状态追踪器(State Tracking):追踪当前的对话状态;
(3)对话策略(Dialogue Strategy):根据当前状态实现状态转移;
(4)基于模型的自然语言生成器(Natural Language Generation);
(5)world model:用于模拟与智能体交互,产生动作和奖励。
整个流程简述为:
- 先初始化一个对话策略和world model(可以使用预训练的方式);
- 直接强化学习:与真实用户进行交互;
- world model learning:使用真实的经验数据训练一个模拟器;
- planing规划:使用模拟器模拟产生数据与智能体交互实现提升
下面具体从这三个流程进行展开描述:
5.1、直接强化学习
(1)该部分选择深度Q网络(DQN),并将对话过程建模为一个马尔可夫决策过程。当当前出处在某一个对话状态时,智能体根据当前的策略选择一个动作,利用
ϵ
epsilon
ϵ 贪心策略,以一定的概率随机选择一个动作或选择最优动作,以平衡探索与开发。
(2)动作价值Q采用多层感知机模型;
(3)当完成一轮对话,系统将获得一个即时奖励,整轮对话结束后,获得一个epsoide;
(4)loss函数定义为:
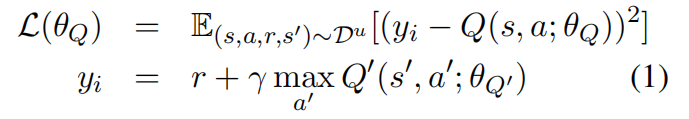
梯度计算为:
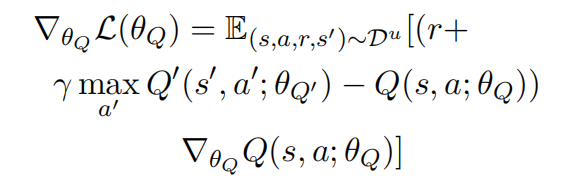
5.2、world model训练
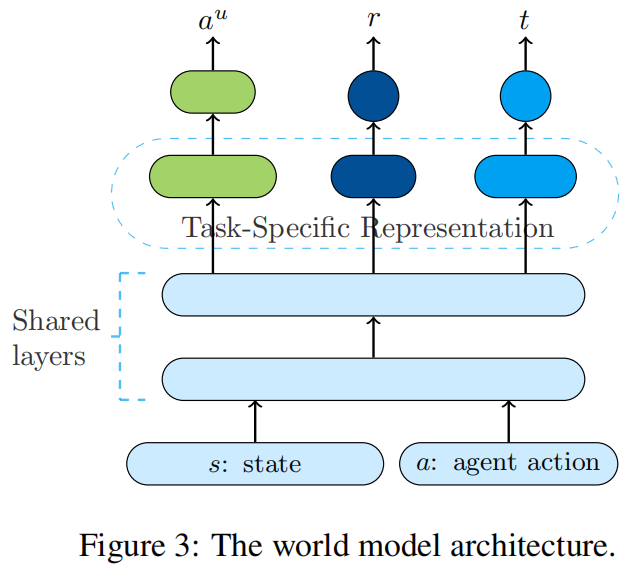
如图所示,由于是多个输出,所以该模型是多任务学习的硬共享架构,底层多层网络共享参数,顶层分别有task-specific的模块。模型输入当前的状态和动作,标签则分别是执行的动作后的回复、奖励以及是否终止符号,可以使用传统的梯度下降训练。
5.3、规划
- (1)world model用于生成一系列的模拟经验数据来提升对话效果,每执行一次直接强化学习,系统将会进行多次规划。
- (2)作者定义两个replay buffer,一个用于存储真实经验,另一个用来存储模拟经验。学习和规划则使用共享参数的DQN模型
- (3)world model的输入包括当前的对话状态 s s s 和智能体上一次执行的动作 a a a,模型输出生成对用户提问的回答 a u a^u au、即时奖励 r r r 以及一个对话终止判别符 t t t(0或1):
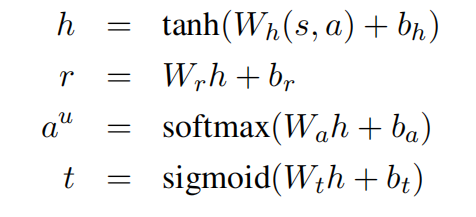
六、实验分析
如下图选择DQN模型训练。K表示每一次执行一次直接强化学习后,执行规划的次数,当K=0时则退化为原始的DQN模型,对于不同的K,随着epoch的增长success rate值变化对比:
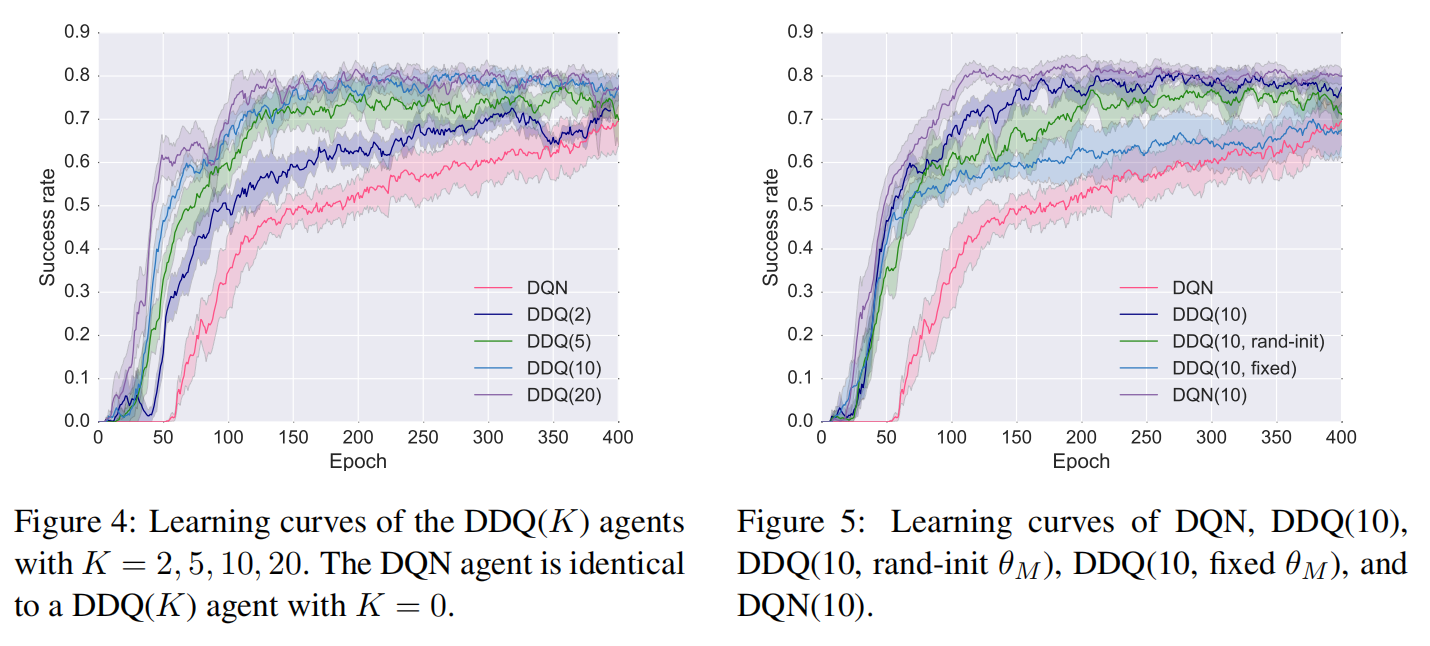
七、总结
- (1)本文提出一种有效的方法,可以避免昂贵的大量真实数据的依赖;
- (2)接下来的挑战时如何在world model上平衡探索与开发之间的关系。在规划中,探索意味着尝试采取可能改善世界模型的行动,而探索意味着尝试在给定当前模型的情况下以最佳方式行事。为此,我们希望智能体在环境中进行探索,但又不要太大,以至于性能将大大降低。
最后
以上就是玩命荷花最近收集整理的关于论文解读:Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning论文解读:Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning (2018 ACL)的全部内容,更多相关论文解读:Deep内容请搜索靠谱客的其他文章。








发表评论 取消回复