两篇关于动量的联邦学习
[1] Xu A , Huang H . Double Momentum SGD for Federated Learning. 2021.
[2] Rothchild D , Panda A , Ullah E , et al. FetchSGD: Communication-Efficient Federated Learning with Sketching[J]. 2020.
数据孤岛包括逻辑和物理,逻辑包括各部门自己定义,物理包括存储和维护。
双动量随机梯度下降的联邦学习
1 背景
1.1 瓶颈
1、客户端漂移,不同数据分布可能存在极大的偏差,趋向发散,局部过拟合。
2、客户可能不稳定,网络连接较慢。
1.2 解决策略
1.减少方差,动量
2.平滑模型更新方向(凸优化)
2 方案
2.1 参数描述

2.2 方案
- 双动量SGD(DOMO)方法(双动量缓存,分别跟踪服务器和本地的更新方向)
- 局部的准确率无意义,因为趋向于过拟合。

2.2 方案解读
(1) 服务器端学习率
α
alpha
α, 动量常数
μ
s
mu_s
μs,服务器端动量混合常数
β
beta
β, 客户端学习率
η
eta
η, 本地动量常数
μ
l
mu_l
μl
(2) 初始化,服务器动量缓存
m
0
=
0
m_0=0
m0=0, 本地模型
x
0
,
0
(
k
)
=
x
0
x^{(k)}_{0,0} = x_0
x0,0(k)=x0, 本地动量缓存
m
0
,
0
(
k
)
=
0
m^{(k)}_{0,0} = 0
m0,0(k)=0
(3) 客户端:收到
x
r
x_r
xr和缓存均值后,初始为0
(4)每一轮训练,共P轮
选项1:
x
r
,
p
(
k
)
<
—
x
r
,
p
(
k
)
−
η
β
P
m
r
∗
I
p
=
0
x^{(k)}_{r,p}<—x^{(k)}_{r,p}-etabeta P m_r * I_{p=0}
xr,p(k)<—xr,p(k)−ηβPmr∗Ip=0,
m
r
,
p
+
1
(
k
)
=
μ
l
m
r
,
p
(
k
)
+
F
′
(
x
r
,
p
(
k
)
,
ξ
r
,
p
(
k
)
)
m^{(k)}_{r,p+1} = mu_l m^{(k)}_{r,p}+F^{'}(x^{(k)}_{r,p},xi^{(k)}_{r,p})
mr,p+1(k)=μlmr,p(k)+F′(xr,p(k),ξr,p(k))
选项I:
x
r
,
p
+
1
(
k
)
=
x
r
,
p
(
k
)
−
η
m
r
,
p
+
1
(
k
)
x^{(k)}_{r,p+1} = x^{(k)}_{r,p}-eta m^{(k)}_{r,p+1}
xr,p+1(k)=xr,p(k)−ηmr,p+1(k)
选项II:
x
r
,
p
+
1
(
k
)
=
x
r
,
p
(
k
)
−
η
m
r
,
p
+
1
(
k
)
−
η
β
m
r
x^{(k)}_{r,p+1} = x^{(k)}_{r,p}-eta m^{(k)}_{r,p+1}-etabeta m_r
xr,p+1(k)=xr,p(k)−ηmr,p+1(k)−ηβmr
客户端发送
d
r
(
k
)
d^{(k)}_r
dr(k)和
m
r
,
P
(
k
)
m^{(k)}_{r,P}
mr,P(k)到服务端。
服务器端:
m
r
+
1
=
μ
m
r
+
1
K
∑
k
=
1
K
d
r
(
k
)
m_{r+1} = mu m_r+frac{1}{K}sum^{K}_{k=1} d^{(k)}_r
mr+1=μmr+K1∑k=1Kdr(k)
x
r
+
1
=
x
r
−
α
β
P
m
r
+
1
x_{r+1} = x_r - alpha beta P m_{r+1}
xr+1=xr−αβPmr+1
将以上
m
r
+
1
,
1
K
∑
k
=
1
K
m
r
,
P
(
k
)
,
x
r
+
1
m_{r+1},frac{1}{K}sum^{K}_{k=1} m^{(k)}_{r,P},x_{r+1}
mr+1,K1∑k=1Kmr,P(k),xr+1发送到客户端。
在跨设备联合学习中,完全参与的收敛分析可以很容易地推广到部分参与。
2. 3方案解读(DOMO-S)

2.4 改进点
(1)
x
r
,
p
+
1
(
k
)
=
x
r
,
p
(
k
)
−
η
m
r
,
p
+
1
(
k
)
−
η
μ
s
P
m
r
∗
I
p
=
P
−
1
x^{(k)}_{r,p+1} = x^{(k)}_{r,p}-eta m^{(k)}_{r,p+1}-etamu_s P m_r * I_{p=P-1}
xr,p+1(k)=xr,p(k)−ηmr,p+1(k)−ημsPmr∗Ip=P−1(服务器+本地动量)
(2)
d
r
(
k
)
=
1
η
P
(
x
r
,
0
(
k
)
−
x
r
,
P
(
k
)
)
d^{(k)}_r = frac{1}{eta P}(x^{(k)}_{r,0}-x^{(k)}_{r,P})
dr(k)=ηP1(xr,0(k)−xr,P(k))
(3)
m
r
+
1
=
1
K
∑
k
=
1
K
d
r
(
k
)
m_{r+1} =frac{1}{K}sum^{K}_{k=1} d^{(k)}_r
mr+1=K1∑k=1Kdr(k)
2.5 思想(同时维护服务器和本地统计数据(动量缓冲区))
- 在培训开始时从服务器接收初始模型和统计数据。
- 在本地训练步骤中融合服务器动量缓冲区。
- 在发送到服务器之前,在本地模型更新中删除服务器动量缓冲区的影响。
- 聚合来自客户机的本地模型更新,以更新服务器节点上的模型和统计信息。
-DOMO是本地模型更新方向应该根据服务器动量缓冲区的方向进行调整,以解决客户端漂移问题。
-DOMO-S通过服务器动量缓冲区调整每个局部动量SGD训练步骤。
预动量 FedAvgLM:DOMO
内动量 FedAvgSM:DOMO- s
后动量 FedAvgSLM:服务器动量+局部动量SGD
DOMO收敛
(1)非凸光滑目标函数(L-利普西茨条件)
(2)局部随机梯度是局部全梯度的无偏估计,有界方差
(3)在客户端的分布比B = 0时更松散(非独立同分布的界)


证明:寻找一个辅助序列
{
z
r
,
p
}
{z_{r,p}}
{zr,p}, 满足比服务器和局部动量混合的更新规则简洁,同时还解决平均本地模型
{
x
r
,
p
}
{x_{r,p}}
{xr,p}.
z
r
,
P
=
z
r
+
1
,
0
z_{r,P} = z_{r+1,0}
zr,P=zr+1,0. 定理1得到了这个辅助序列,限定inconsistency bound 和divergence bound. 再分析
{
x
r
,
p
}
{x_{r,p}}
{xr,p}和
{
z
r
,
p
}
{z_{r,p}}
{zr,p}。divergence bound.度量不同客户间的差异度,只受本地动量影响,inconsistency bound 度量辅助变量和平均局部模型之间的差异,得到更简洁的更新规则。

证明:DOMO中的服务器动量缓冲区可改进Convergence of DOMO 的边界,服务器动量缓存不影响 divergence bound. 在学习速度较大时可以加速初始训练,由于不平等的缩放,这个改进分析还没有达到最优。
第二篇(ICML 2020)
同样这一篇也引进了动量,主要关注的问题是:稀疏的客户参与,使用Count Sketch 压缩模型更新,Count Sketch 满足线性、动量和错误累积在Sketch中可以解决,消除动量和误差累计,实现高压缩率和收敛。
1 瓶颈
- 通信效率
- 客户端稳定
- 客户端数据非独立同分布
2 流程

每一轮,客户端在私有数据集下计算梯度,使用Count Sketch压缩发送到服务器进行聚合,权重更新从错误累积中提取,FetchSGD不要求客户端本地的状态。研究独立同分布
{
P
i
}
{P_i}
{Pi}, 损失函数
L
:
W
∗
X
−
>
R
L:W * X->R
L:W∗X−>R,目标函数是权重平均的最小值,假设数据数量相同,可以简化为(2),全文还是主要研究(1)

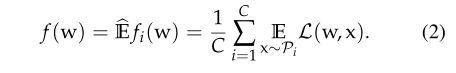
Count Sketch 是指随机化的数据结构,将向量随机投影到低维空间中,近似的恢复高维向量,本文将其当做压缩算子,蛮子线性:
(1)
S
(
g
1
+
g
2
)
=
S
(
g
1
)
+
S
(
g
2
)
S(g_1+g_2)=S(g_1)+S(g_2)
S(g1+g2)=S(g1)+S(g2)
(2)存在解压缩算子U(),返回原始向量的无偏估计
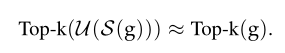
3 FetchSGD算法
(1) 第i个用户使用本地的一批(或全部)数据计算随机梯度
g
t
i
g^i_t
gti
(2)使用Count Sketch压缩
g
t
i
g^i_t
gti,将
S
(
g
t
i
)
S(g^i_t)
S(gti)发送到服务器
(3)因为满足线性性质,服务器聚合计算
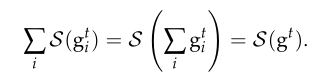
(4)Top-k并不是
g
t
g^t
gt的无偏估计,偏差由Top-k引入,可以累积错误,SGD收敛不能保证。Karimireddy等人证明偏误差梯度重新引入可以消除,可以收敛。
在一个零初始化的Count Sketch 中这样做,而不是在一个类似梯度的向量:
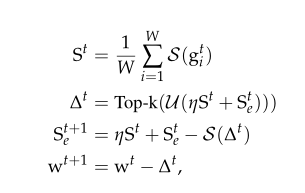
扩展改进:将动量只在客户端/服务端中进行叠加。
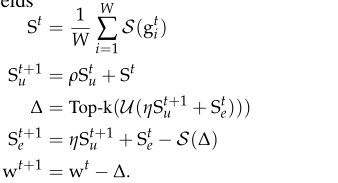

(1)
S
e
,
S
u
S_e, S_u
Se,Su分别指客户的累积和服务器的累积,压缩算子归0,在客户端和聚合有相同的种子
w
0
w_0
w0。
(2)随机选择W个用户,下载模型,计算梯度,压缩
(3)服务器聚合压缩算子,计算动量,错误反馈,解压缩,错误累积,更新。
(1)压缩服从一个收缩性质,应用 Stich 的结果,满足

(2)Ivkin证明Count Sketch可以满足上面这个性质,包括两轮,如果不包括高维元素,可从
S
(
e
t
)
S(e_t)
S(et)计算,服务器可以查询任意的
e
t
e_t
et,第二轮,FetchSGD不计算
e
t
i
e^i_t
eti或
e
t
e_t
et。
(3)作者提出假设:τ是关于k的函数,是通信和效用的均衡,但是涉及到梯度、动量和误差累积,下面做一个只关于梯度的假设。

(4)假设2:梯度向量的滑动和中存在重坐标
随机过程
{
g
t
}
t
{g_t}_t
{gt}t是(
I
I
I,
α
alpha
α)–滑动,当
g
t
g_t
gt分成
g
t
=
g
t
N
+
g
t
S
g_t= g^N_t+g^S_t
gt=gtN+gtS,信号+噪声,满足以下性质:
- 信号至少1- δ delta δ的概率, I 个连续的梯度加起来,满足 α − h e a v y alpha-heavy α−heavy或者是平均零对称噪声。
- 噪声是对称,界是 β beta β


实验:
1,使用了ReLu,损失面不是光滑的
2. 场景2的理论使用滑动窗口计数示意图来积累误差,但在实践中我们使用普通计数示意图。
3. 使用非零动量
4. 动量因子掩蔽,遵循Lin等人(2017)
5. 将S(∆t)的非零坐标归零,而不是减去S(∆t)。
现实世界的用户倾向于生成的数据大小遵循幂律分布(Goyal et al.,2017),所以大多数用户将拥有相对较小的本地数据集。调整k或Count Sketch的列数,压缩率,而不是改变学习率缩减。
最后
以上就是不安石头最近收集整理的关于联邦学习--论文汇集(四)两篇关于动量的联邦学习双动量随机梯度下降的联邦学习第二篇(ICML 2020)的全部内容,更多相关联邦学习--论文汇集(四)两篇关于动量的联邦学习双动量随机梯度下降的联邦学习第二篇(ICML内容请搜索靠谱客的其他文章。








发表评论 取消回复