目录
1.什么是决策树
2.决策树的三个算法
3.决策树的三个算法的剪枝方式
4.决策树的应用场景
5.决策树的原理与sklearn中的接口对应关系
1.什么是决策树
决策树是一种基本的分类与回归方法。决策树模型呈现树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定位在特征空间与类空间上的条件概率分布。其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。决策树学习通常包括3ge个步骤:特征选择、决策树的生成和决策树的修剪。主要涉及到3个算法,ID3、C4.5、CART算法。
CART算法详解以及之间的比较:https://www.cnblogs.com/gczr/p/7119517.html?utm_source=itdadao&utm_medium=referral
2.决策树的三个算法
2.1 ID3算法
ID3算法使用信息增益作为评判标准,不能处理缺失值和连续值,比较偏向选择类别数较多的特征。
对于分类系统,C为分类数,类别的取值分别为C1,C2,C3,...,Cn,而每一类出现的概率为:P(C1),P(C2),P(C3),...,P(Cn)。
所以该分类系统的信息熵为:
信息增益是针对一个一个特征的,就是看一个特征,系统有它和没它的信息量分别是多少,它两的差值就是该特征给系统带来的信息量,即信息增益。
信息增益的计算公式如下:

2.2 C4.5算法
C4.5算法使用信息增益率作为评判标准,所以比较偏向于取值数量少的属性,可以处理连续属性和缺失值。
属性A的分裂信息:
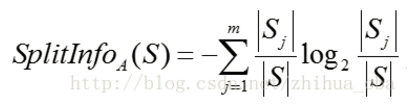

通过属性A分裂之后样本集的信息增益:
![]()
通过属性A分裂之后的样本集的信息增益率:
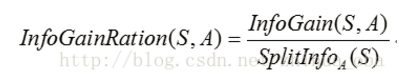
连续性属性的离散化处理:
对于连续性属性的离散化处理的核心思想是:将连续性属性的N个取值从小到大排序,通过二分法将属性A的所有属性值分为两部分(共有N-1中划分方法,二分的阈值是相邻两个属性值的中间值);计算每种划分方式的信息增益,选择信息增益最大的划分方法的阈值作为属性A二分的阈值。详细流程如下:

找打了连续属性的最好的二分阈值,此时依据该二分阈值将连续属性划分为2部分的离散属性,然后计算所有属性的信息增益率来选择信息增益率最大的属性作为分类特征。
缺失值处理:





2.3 CART
CART是分类与回归树,既可以用于回归,用可以用于分类。在分类问题中评判标准是基尼指数,在回归问题中的评判标准是平方误差。CART也可以处理连续值与缺失值,处理方式同C4.5

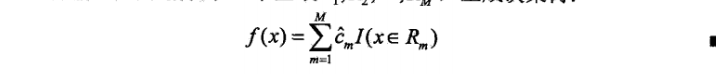
在回归问题中,对于分类特征,比如分类特征的取值为0,1,2,3,4,那么就按照二分法获得二分阈值0.5, 1.5, 2.5,3.5,用这些阈值来划分,小于等于阈值和大于阈值。
 xie'f,
xie'f,



3.决策树中三个算法的剪枝方式
剪枝方式有预剪枝和后剪枝。
决策树ID3、C4.5、CART剪枝参考西瓜书和统计学习方法
4.sklearn中的决策树
在sklearn中只有ID3树和CART树。树的剪枝都是预剪枝。都是事先设定了各种参数,然后在训练过程中如果达到参数的设定就停止分支。sklearn中的决策树都是二叉树。
最后
以上就是默默荔枝最近收集整理的关于决策树学习的全部内容,更多相关决策树学习内容请搜索靠谱客的其他文章。








发表评论 取消回复