决策树
基本知识:
1.决策树是一种利用结点和有向边组成的层次结构
2.分类or回归算法
3.监督学习
4.存在能够是数据集准确分类的树,无论是否真的存在这样的树,但是这是NP难问题
5.针对4,一般决策树的学习策略是以损失函数为目标函数的最小化
树种三种节点:
1.根结点: 没有入边,有零或者多条出边
2.内部结点:恰有一个入边、两个或者多个出边
3.叶子结点:恰有一个入边,没有出边
在决策树中,非终结点(根结点、内部结点)包含属性的测试条件,根据属性值得不同分成不同的孩子结点。每个叶子结点都有个类别号。
如下图所示:
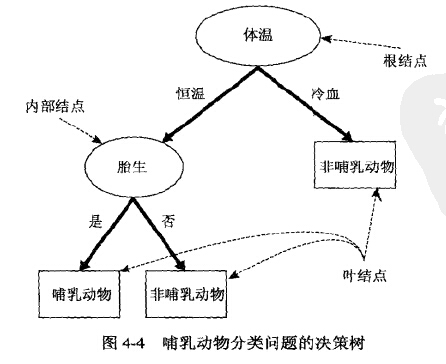
当我们构造好就决策树之后,只需要从根结点开始,将结点属性值对测试数据进行检测,根据检测结果选择不同的分支,最终到达叶子结点,叶子结点的类别就是分类的类别。
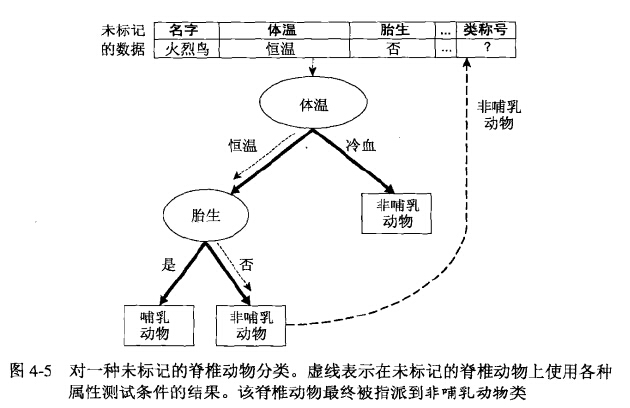
构建决策树的两个重点:
1.选择哪个属性进行划分?
2.如何选择属性?
选择属性方法
属性选择的标准:
选择的该属性,划分后孩子结点应该尽量的纯,或者说不纯度尽量的低
信息熵
P(Ci)
:表示
Ci
类的概率,
Ci
类出现的次数除以数据集的大小
K
类的数据集
H(D)=−∑i=Ki=1P(Ci)log2P(Ci)
其中:
0log20=0
熵表示了数据的不确定性,熵越大不确定性越大
显然:
0≤H(D)≤log2K
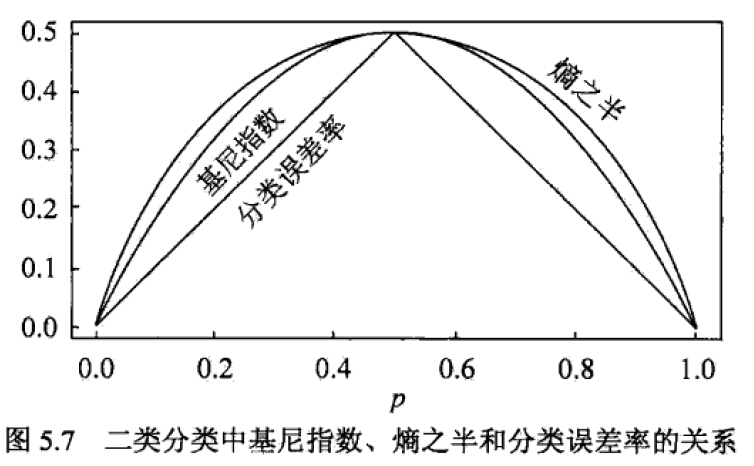
对于二类问题:
H(D)=−P(C1)log2P(C1)−(1−P(C1))log2(1−P(C1))
P(C1)
与熵
H(D)
的关系图
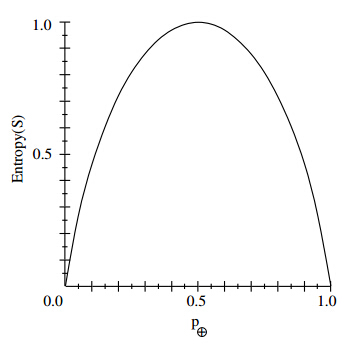
根据上图: P(C1)=0.5 的时候熵最大,这个时候两个数据量相等,不确定性最高。 P(C1) 越大或者越小,说明两类的数据量差别越大,数据量差不越大,数据的纯度越高,数据的不确定性也就越小,这时候熵也变小了。
信息增益
定义:
inforGain(D,A)=H(D)−H(D|A)
H(D)
:表示数据集的信息熵
H(D|A)
:表示在特征
A
的情况下数据集的条件熵
信息熵的计算上面已经给出,下面介绍条件熵
H(D|A)=P(A=a1)H(D,A=a1)+P(A=a2)H(D,A=a2)+...+P(A=am)H(D,A=am)
P(A=a2)
:表示特征
A
的取值是
H(D,A=a2)
:表示
A
的取值是
举个例子:
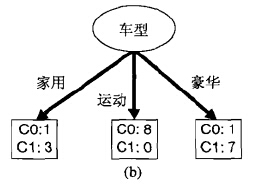
车型有三个取值:家用,运动,豪华
C0,C1 类的数量在上图中已经标注
计算信息熵:
C0 类共出现10次,出现概率 P(C0)=1020=12
C1 类共出现10次,出现概率 P(C1)=1020=12
H(D)=−P(C0)log2P(C0)−P(C1)log2P(C1)=log22=1
计算条件熵:
三种车型出现的概率
家用: P(A=a1)=420=15
运动: P(A=a2)=820=25
豪华: P(A=a3)=820=25
不同车型下的熵:
H(D,A=a1)=−14log214−−34log234=0.8112781
H(D,A=a2)=−88log288−−08log208=0
H(D,A=a3)=−18log218−−78log278==0.5435644
车型的信息增益
H(D,A)=H(D)−P(A=a1)H(D,A=a1)−P(A=a2)H(D,A=a2)−P(A=a3)H(D,A=a3)=0.6203186
同样可以计算出其他特征的信息增益
信息增益的解释:熵
H(D)
反应了对数据分类额不确定性,条件熵
H(D,A)
表示在特征
A
确定的条件下对数据集进行分类的不确定性。两者的差,表示了用特征
信息增益率
在《统计学习方法》中是下面的定义
信息增益率:信息熵与数据集熵的比值
inforGainRatio(D,A)=inforGain(D,A)H(D)
这里我之前一直不明白,对于每个特征除以原始数据的信息熵,这个只是把信息增益进行了缩放,对特征的选择没有影响的。
《统计学习方法》公式是错误的
可查看wiki
在《数据挖掘导论》中看到了下面的计算方式
inforGainRatio(D,A)=inforGain(D,A)SplitInfo
划分信息:
SplitInfo=−∑i=numFi=1P(F=vi)log2P(F=vi)
划分属性的个数:
numF
每个属性的取值:
v1,v2,..vnumF
每个属性的概率:
P(F=vi)
所以,当数据集中某个特征具有大量不同的取值时候,划分信息起到了作用,这个时候划分信息将会很大。在信息增益相同的时候,划分信息越大,信息增益率将会越小,越降低选取为分类特征的可能。
基尼系数
K
类数据集,每类数据出现的概率
基尼系数:
Gini(D)=1−∑i=Ki=1P(Ci)2
在选择属性的时候,设特征
A
的取值是:
Gini(D,A)=P(A=a1)Gini(D,A=a1)+P(A=a2)Gini(D,A=a2)+...+P(A=am)Gini(D,A=am)
在选择特征时根据基尼系数的变化作为评价标准
ΔGini=Gini(D)−Gini(D,A)
Gini(D)
表示数据集D的不确定性
Gini(D,A)
表示用特征A进行分裂属性的不确定性
比较
基尼系数,熵之半与分类误差率的关系
不同算法
| 属性选择 | 算法 | 备注 |
|---|---|---|
| 信息增益 | ID3 | 已弃用 |
| 信息增益率 | C4.5 | 改进的C5.0 |
| 基尼系数 | CART | 对属性二分 |
其他说明:
1.以信息熵、信息增益、基尼系数表示不纯度的时候,选取的特征趋向于选取具有大量不通值得属性。
2.信息增益率克服了上面的缺点
3.信息增益、信息增益率越大属性越有利于作为分类特征,基尼系数越小越有利于作为分类特征
算法伪代码

算法说明:
输入:训练数据集 E ,属性集
递归的方式构建建树
(1):函数 createNode() 为决策树建立新结点,决策树的结点或者是一个测试条件,记住 node.test_cond ,或者是一个类别标记,记住 node.label
(2):函数 find_best_split() 确定应当选择哪个属性作为划分训练记录的测试条件。如上面所说:信息增益,信息增益率,基尼系数
(3):函数 Classify() 为叶结点确定类别标号。若是完全建树,将一直进行下去,叶结点类别就是最后结点的类别,若是不完全建树,也就是在减树的过程中停止建树,停止建树的条件:1,样本数据量过少,2,分类前后信息增益变化不大,这个时候选取该子数据集中类别数量最多的类别标号作为该叶结点类别
(4):函数 stopping_cond() 通过检测是否所有记录都是一类,或者都具有相同属性值,决定是否终止决策树增长。
剪枝
先剪枝
在建树的同时进行剪枝
剪枝条件:
1.样本量过小
2.以该属性进行分裂时,信息增益低于某个阈值
优点:避免出现过分复杂的子树
缺点:无法确定阈值
后剪枝
构建好决策树后,再进行剪枝
剪枝规则:
1.子树中类别数量最多的类代替该子树
2.最长使用的分支代替子树
优点:防止过早停止决策树生长
缺点:建树浪费时间和空间
优缺点
ID3的缺点:
1:ID3算法在选择根节点和内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多是属性,在有些情况下这类属性可能不会提供太多有价值的信息。
2:ID3算法只能对描述属性为离散型属性的数据集构造决策树
C4.5算法主要做出了以下方面的改进
1:可以处理连续数值型属性
2:用信息增益率(Information Gain Ratio)来选择属性, 克服了用信息增益来选择属性时偏向选择值多的属性的不足。
3:缺失值处理 对于某些采样数据,可能会缺少属性值。在这种情况下,处理缺少属性值的通常做法是赋予该属性的常见值,或者属性均值。另外一种比较好的方法是为该属性的每个可能值赋予一个概率,即将该属性以概率形式赋值。这种处理的目的是计算信息增益,使得这种属性值缺失的样本也能处理。
C4.5的缺点:
1:算法低效,在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效
2:内存受限,适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行
这里参考
#总结
1.决策树是一种非参数模型,不需要先验假设,不假设类和其他属性服从一定的概率分布
2.找到最佳决策树是NP难问题,上面建树过程是一种贪心的,自顶向下的递归划分策略
3.决策树一旦建立,对未知样本分类很快,最坏时间复杂度
O(h)
,
h
<script type="math/tex" id="MathJax-Element-69">h</script>是树的最大深度
4.容易理解,可以形象的画出来
5.属性值是离散的比较好建模,当时连续值得时候需要离散化属性值
6.对噪声具有很好的抗干扰性
7.冗余属性不会对决策树的准确率有不利影响。两个属性相关性很强的时候是冗余属性,当其中一个被作为分裂属性的时候,另外一个将被忽略。当不相关属性很多的时候可能会使得树过于庞大
8.采用自顶向下递归的方式构建决策树,可能会出现碎片问题,解决该问题可以当样本数小于指定阈值的时候停止分裂
9.子树可能在决策树中多次出现
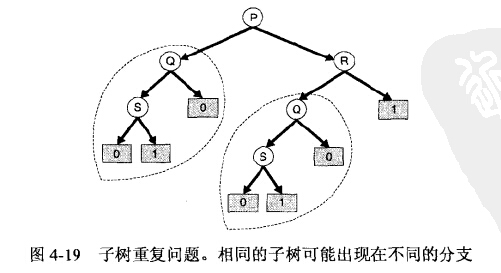
10.上面介绍的算法每次只能选择一个属性进行分类,对于多个属性进行分裂时候比较复杂
C5.0
C5.0算法是在C4.5算法的基础上提出的
C5.0和C4.5算法的对比:
1.都是通过计算信息增益率来划分结点,两者的共同
2.C5.0算法通过构造多个C4.5算法,是一种boosting算法。准确率更高
3.C5.0算法运行速度快,例如,C4.5需要9个小时找到森林的规则集,但C5.0在73秒完成了任务。
4.C5.0运行内存小。C4.5需要超过3 GB.(工作不会对早些时候完成32位系统),但C5.0需要少于200 mb。
5.C5.0算法,可以人为的加入客观规则
6.C5.0可以处理较大的数据集,特征可以是:数字,时间,日期,名义字段
7.C5.0可以加入惩罚项,(也就是第2条中boosting过程)
参考1:《统计学习方法》
参考2:《数据挖掘导论》
最后
以上就是从容冷风最近收集整理的关于决策树#总结的全部内容,更多相关决策树#总结内容请搜索靠谱客的其他文章。

![[JS]基础语法与表达式1.1初识JavaScript2.1Js的书写位置2.2认识输出语句2.3学会处理报错2.4变量声明提升(面试题比较多)3.1变量](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)






发表评论 取消回复