目录
1、线程存在的问题
2、池化技术
3、线程池
4、Java中的线程池
5、线程池的原理
5.1、七大核心参数
5.2、初始化核心线程
5.3、addWorker:添加工作线程
5.4、worker:工作线程
5.5、runWorker:运行工作线程
5.6、getTask:获取到任务
5.7、reject:拒绝策略
5.7.1、抛出错误
5.7.2、主线程调用任务
5.7.3、丢掉头部
5.7.4、丢掉
5.7.5、抛出错误
6、计算线程池的线程数
6.1、IO密集型
6.2、CPU密集型
6.3、动态设置
6.3.1、setCorePoolSize:动态设置核心线程数
6.3.2、setMaximumPoolSize:动态设置核心线程数
6.4、动态设置队列容量
7、线程监控
1、线程存在的问题
- 线程频繁的创建与销毁产生性能开销
- 线程最多同时执行与CPU核心数量相等的数量,多出来的线程会导致上下文切换问题。
2、池化技术
为了解决线程的使用问题,JAVA采用了线程池技术。线程池就是一种典型的池化技术,类似的还有对象池,内存池,连接池等技术。
3、线程池
线程池的基本思想就是,提前创建一系列的线程,保存在线程池中,需要的时候从线程池中取出线程。
4、Java中的线程池
Executors提供了四种不同线程池的工厂方法进行构建。
- newFixedThreadPool:固定线程数的线程池
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } - newSingleThreadExecutor:只有一个线程的线程池
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } - newCachedThreadPool:可以缓存的线程池,理论上来说,有多少请求,就可以创建多少线程来对请求进行处理
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); } - newScheduledThreadPool:提供了按照周期执行的线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }
一个简单的示例代码:
public class FixedThreadPoolExample {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
executorService.execute(new Task());
System.out.println("END");
}
private static class Task implements Runnable {
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println("FixedThreadPoolExample");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}5、线程池的原理
5.1、七大核心参数
线程池的构造函数的源码如下。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}可以看到,整个线程池共有七个参数。
- int corePoolSize:核心线程数,代表始终保持存活并消费等待队列中任务的线程数量
- int maximumPoolSize:最大线程数,核心线程数+临时线程数
- long keepAliveTime:非核心线程存活时间,非核心线程数在辅助处理完工作之后,就会被销毁,这是销毁之前的存活时间
- TimeUnit unit:存活时间单位
- BlockingQueue<Runnable> workQueue:等待(阻塞)队列,任务队列,所有的任务都会先在这里进行排队,等待线程消费
- ThreadFactory threadFactory:线程工厂,创建线程的工厂
- RejectedExecutionHandler handler:拒绝策略,在等待队列已满,线程数量达到最大线程数时执行的策略
整个线程池就是由这七个参数进行创建的,根据参数,我们可以得到一个大致结论,那就是整个线程池由工作线程,等待队列,线程工厂,拒绝策略组成。
当一个线程池得到任务,它会根据以下步骤进行执行:
- 任务提交进入线程池
- 判断线程池线程数是否已经达到核心线程数,若是未达到,则创建核心线程,开始执行任务。
- 若核心线程已全部创建完成,就将任务放置到阻塞队列,工作线程可以消费队列中的任务
- 若阻塞队列已满,就判断线程池是否达到最大线程数,若是未达到,就创建临时线程,开始消费任务
- 若是达到最大线程数,就执行拒绝策略。
因此,线程池能够实现线程复用,就是依靠等待队列
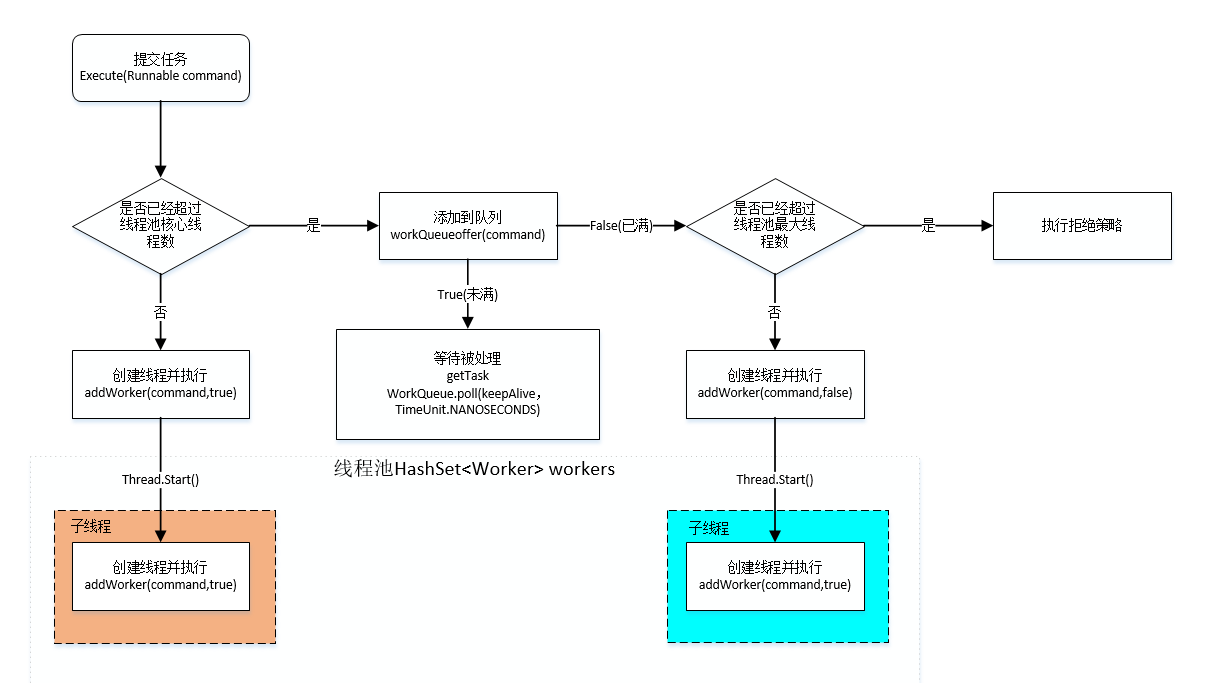
如果等待队列满了,那么只有两种方式可以选择,一个是将工作线程增加,一个是直接拒绝。
- 增加消费的线程数量
- 拒绝新的任务
拒绝策略既然叫拒绝策略,那一定是有很多的策略可以选择。
- 报错(默认)
- 直接丢弃任务
- 普通线程直接调用task.run()
- 队列中部的等待最久的任务丢弃,然后将当前任务添加到阻塞队列
- 自定义(如存储起来,等待队列空间释放后进行重试)
5.2、初始化核心线程
因为线程池里的线程是延迟初始化的,所以执行任务的第一件事就是先初始化核心线程。
如果不希望延时初始化,可以使用线程池的线程预热来达到提前完成核心线程创建的目的。
executorService.prestartAllCoreThreads()//线程预热
非空判定,无需赘述
if (command == null)
throw new NullPointerException();
int c = ctl.get(),ctl是一个比较特殊的类型。AtomicInteger是原子类,采用位运算进行线程表示
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)),它的高3位是线程状态,低29位表示线程数量,通常经过位运算获得对应的线程数量。
//原子类int,计数使用
//它的高3位是线程状态,低29位表示线程数量,通常经过位运算获得对应的线程数量。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0))
int c = ctl.get();
workerCountOf(c) < corePoolSize,workerCountOf()计算工作线程数量,判断工作线程是否已经达到核心线程数corePoolSize。
如果没有超过,addWorker(),添加工作线程,同时执行command。
如果添加失败,可能是其他线程添加成功,因此重新获取,c = ctl.get()。
//workerCountOf()计算工作线程数量
//判断工作线程是否已经达到核心线程数corePoolSize
if (workerCountOf(c) < corePoolSize) {
//判断是否添加工作线程成功
if (addWorker(command, true))//成功就返回
return;//重新获取
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)),isRunning()判断线程状态,workQueue.offer()添加到阻塞队列
if (! isRunning(recheck) && remove(command)),isRunning()再次判断线程状态,因为操作不是原子性的,所以还是要再判断一次。如果是非运行状态,remove()移除任务
reject(command),拒绝执行
else if (workerCountOf(recheck) == 0),再次统计工作线程数,如果等于0,即工作线程数为0,需要进行添加。
//isRunning()判断线程状态
//workQueue.offer()添加到阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
//获取计数
int recheck = ctl.get();//isRunning()再次判断线程状态,如果是非运行状态
//就将,remove()移除任务
if (! isRunning(recheck) && remove(command))//拒绝执行
reject(command);//否则计算工作线程数,如果为0
else if (workerCountOf(recheck) == 0)//添加工作线程
addWorker(null, false);
}
else if (!addWorker(command, false)),如果添加到等待队列失败,就要尝试添加工作线程。此时添加的是扩容线程,即非核心的线程
如果不成功,就执行拒绝策略,reject(command),拒绝执行。
//如果添加到等待队列失败,就要尝试添加工作线程。此时添加的是扩容线程(非核心)。
else if (!addWorker(command, false))
//如果不成功,就执行拒绝策略
reject(command);
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}5.3、addWorker:添加工作线程
这是一个非常长的代码,但是可以分段来看。
首先就是自旋,然后是否定判断,判断哪些情况不能添加工作线程。
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
在线程状态,任务,等待队列等条件满足的时候,不能添加。
接下来又是一个自旋。
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}获取到当前的工作线程数量
//获取到当前的工作线程数量
int wc = workerCountOf(c)
如果线程数量过大,或者线程的数量大于核心/最大线程数,将不再创建新的工作线程
//如果wc数量大于最大数量
if (wc >= CAPACITY ||
//或wc大于等于核心/最大线程数
wc >= (core ? corePoolSize : maximumPoolSize))//不再创建新的工作线程
return false;
CAS操作,变更线程数量,因为可能是多线程变更,所以需要加锁锁定
break retry,跳出循环
//CAS操作,变更线程数量,因为可能是多线程变更,所以需要加锁锁定
if (compareAndIncrementWorkerCount(c))
//跳出循环
break retry;
if (runStateOf(c) != rs),如果线程运行时状态发生了改变
continue retry,跳转至下一个循环
//如果线程运行时状态发生了改变
if (runStateOf(c) != rs)
//跳转至下一个循环
continue retry;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}接下来要初始化工作线程
w = new Worker(firstTask),新建一个worker,包含firstTask,第一个任务
final Thread t = w.thread,建立一个final的线程,从worker中获取
//新建一个worker,包含firstTask,第一个任务
w = new Worker(firstTask);
//建立一个final的线程,从worker中获取
final Thread t = w.thread;
if (t != null) 如果生成的线程不为null
如果生成的线程不为null
if (t != null)
这段代码是添加ReentrantLock,确保调用时的安全。
//获取到ReentrantLock,这个ReentrantLock是从this获取的
final ReentrantLock mainLock = this.mainLock;
//添加锁
mainLock.lock();
int rs = runStateOf(ctl.get()),获取到线程状态,线程状态有五种
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)),可以看到小于0的线程只有正在运行,如果线程状态为正在运行,或线程状态为关闭并且工作任务为null,即可添加工作线程
if (t.isAlive()),如果线程存活,抛出错误,此时主要检查线程是否已经开始运行
workers.add(w),添加工作线程到容器workers之中。其中,works为一个HashSet容器。
显然这是一个容器,set容器,存储全部的工作线程
int s = workers.size(),获取到工作线程的数量
if (s > largestPoolSize),如果工作线程的数量大于largestPoolSize(线程池最大线程数),目的是做数据监控
largestPoolSize = s,数值替换
workerAdded = true,新的工作线程添加成功,workerAdded为true
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
private final HashSet<Worker> workers = new HashSet<Worker>();
try {
//获取线程状态
int rs = runStateOf(ctl.get());//可以看到小于0的线程只有正在运行,如果线程状态为正在运行
if (rs < SHUTDOWN ||
//或线程状态为停止并且首个任务为空
(rs == SHUTDOWN && firstTask == null)) {//判断worker生成的线程是否存活,如果被执行,则会被抛出错误
//因为线程一旦开始运行,就证明已经具有任务,无法继续分配
if (t.isAlive())
throw new IllegalThreadStateException();//添加至工作线程之中
workers.add(w);//获取到工作线程的数量
int s = workers.size();//如果工作线程的数量大于largestPoolSize(线程池最大线程数)
if (s > largestPoolSize)//更新线程池最大线程数
largestPoolSize = s;//新的工作线程添加成功,workerAdded为true
workerAdded = true;
}
}
mainLock.unlock(),finally,最终解锁,加锁必解锁
finally {
mainLock.unlock();
}
如果添加成功,线程开始运行,并且将将运行成功状态workerStarted置为true
if (workerAdded) {
t.start();
workerStarted = true;
}
if (! workerStarted),如果启动失败
addWorkerFailed(w),将工作线程从容器中移除
finally {
if (! workerStarted)
addWorkerFailed(w);
}
//五种线程状态
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
//worker是一个hashset容器
private final HashSet<Worker> workers = new HashSet<Worker>();
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//新建一个worker,包含firstTask,第一个任务
w = new Worker(firstTask);
//建立一个final的线程,从worker中获取
final Thread t = w.thread;
if (t != null) {
//获取到ReentrantLock,这个ReentrantLock是从this获取的
final ReentrantLock mainLock = this.mainLock;
//添加锁
mainLock.lock();
try {
//获取线程状态
int rs = runStateOf(ctl.get());
//如果线程状态小于停止,可以看到只有RUNNING是小于SHUTDOWN的,所以是运行状态
if (rs < SHUTDOWN ||
//或线程状态为停止并且首个任务为空
(rs == SHUTDOWN && firstTask == null)) {
//判断worker生成的线程是否存活,如果被执行,则会被抛出错误
//因为线程一旦开始运行,就证明已经具有任务,无法继续分配
if (t.isAlive())
//抛出错误
throw new IllegalThreadStateException();
//添加至工作线程之中
workers.add(w);
//获取到工作线程的数量
int s = workers.size();
//如果工作线程数量超过了目前为止记录的最大线程数量
if (s > largestPoolSize)
//更新记录
largestPoolSize = s;
//将添加标志改为true
workerAdded = true;
}
} finally {
//解锁
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;5.4、worker:工作线程
worker实现了Runnable接口,继承了AbstractQueuedSynchronizer,目的是后续加锁。
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}worker实现了Runnable接口,必然有重写的run方法,run方法执行的是runWorker方法,之后再说
worker中有一个属性thread,是线程Thread类,它的赋值在构造方法中
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
getThreadFactory()是线程工厂,newThread()方法在线程工厂里。
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
5.5、runWorker:运行工作线程
runWorker方法是worker类重写的run方法中调用的方法。
while (task != null || (task = getTask()) != null):while循环保证当前线程不结束,直到task为null
w.lock():开启锁,目的是在这个worker执行任务时,需要等待执行完成,才可以结束这个worker(终止线程),以确保安全执行。
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt():中断判定,执行中断。
beforeExecute(wt, task):这里是空的实现,可以重写实现监控
task.run():执行任务的run方法
afterExecute(task, thrown):这里是空的实现,可以重写监控方法
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//while循环保证当前线程不结束,直到task为null
while (task != null || (task = getTask()) != null) {
//开启锁,目的是在这个worker执行任务时,需要等待执行完成
//才可以结束这个worke(终止线程),以确保安全执行。
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
//中断标志
wt.interrupt();
try {
//这里是空的实现,可以重写实现监控
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//这里是空的实现,可以重写监控方法
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}5.6、getTask:获取到任务
获取到任务方法,getTask()
//获取到原子类
int c = ctl.get();
//获取到当前线程运行状态
int rs = runStateOf(c);
检测当前线程状态,如果线程状态为终止,需要清理线程池,去除全部计数,返回null
//检测当前线程状态,如果线程状态为终止,需要清理线程池,更改计数,返回null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
获取当前线程数
//获取到当前线程数
int wc = workerCountOf(c);
是否允许超时timed,判定条件为allowCoreThreadTimeOut为true,或wc大于核心线程数
可以通过改变allowCoreThreadTimeOut的状态为true,这样就能将核心线程数量降低
//是否允许超时,判定条件为
//allowCoreThreadTimeOut为true
//或wc大于核心线程数
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
如果线程计数大于最大线程数,或允许超时判断为true,或(线程计数大于1或任务队列为null)进行CAS操作,减少工作线程数量,返回null,销毁此线程
//如果线程计数大于最大线程数
//或允许超时判断为true
//或线程计数大于1或任务队列为null
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
//CAS操作,将减少工作线程数量
if (compareAndDecrementWorkerCount(c))
//表示销毁当前线程
return null;//继续循环
continue;
}
根据是否允许超时timed来判断是否进行超时阻塞
超时阻塞方法:workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
阻塞方法:workQueue.take()
如果此时允许超时,这里的超时时间是keepAliveTime,证明当前线程为临时线程,如果一段时间内没有能够获取到任务,说明任务队列已经没有任务,r为null,进入下一次循环。
如果此时不允许超时,则一直阻塞,此时的线程是核心线程,这个核心线程将始终阻塞在这里,等待新的任务进入等待队列。
try {
//是否允许超时
Runnable r = timed ?
//超时阻塞方法,运用于临时线程
//当线程为临时线程,存活时间即是超时时间//线程将会在超时结束后进入下一循环
//在下一循环中,此线程将会被销毁
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
//阻塞方法,运用于核心线程
//当前线程为核心线程,核心线程将会在此处保持阻塞,直到新的任务进入队列
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
如果获取到的线程不为null,返回线程(即任务)
if (r != null)
return r;
private Runnable getTask() {
boolean timedOut = false;
for (;;) {
//获取到原子类
int c = ctl.get();
//获取到当前线程运行状态
int rs = runStateOf(c);
//检测当前线程状态,如果线程状态为终止,需要清理线程池,更改计数,返回null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
//获取到当前线程数
int wc = workerCountOf(c);
//是否允许超时,判定条件为
//allowCoreThreadTimeOut为true
//或wc大于核心线程数
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//如果线程计数大于最大线程数
//或允许超时判断为true
//或线程计数大于1或任务队列为null
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
//CAS操作,将减少工作线程数量
if (compareAndDecrementWorkerCount(c))
//表示销毁当前线程
return null;
continue;
}
try {
//是否允许超时
Runnable r = timed ?
//超时阻塞方法,运用于临时线程
//当线程为临时线程,存活时间即是超时时间,线程将会在超时结束后进入下一循环
//在下一循环中,此线程将会被销毁
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
//阻塞方法,运用于核心线程
//当前线程为核心线程,核心线程将会在此处保持阻塞,直到新的任务进入队列
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}5.7、reject:拒绝策略
拒绝策略的方法如下,其有四种具体实现
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}5.7.1、抛出错误
直接抛出错误。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}5.7.2、主线程调用任务
可以看到,只要e(线程池)没有结束,那么就会调用r.run(),那么是谁调用的呢?是调用线程池的线程,可以说是主线程直接执行任务。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}5.7.3、丢掉头部
将等待队列的头部任务丢掉,因为头部的任务一定是等待最久的任务。
然后将新任务加入
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}5.7.4、丢掉
这里什么都没写,意味着任务会直接消失。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}5.7.5、抛出错误
这个类似第一个的处理方式
public void rejectedExecution(Runnable r, java.util.concurrent.ThreadPoolExecutor executor) {
throw new RejectedExecutionException();
}6、计算线程池的线程数
计算线程池到底需要设置多少线程,需要看它是IO密集型还是CPU密集型
6.1、IO密集型
CPU利用率不高,通用的公式是2N+1
6.2、CPU密集型
因为CPU利用率高,导致上下文切换频繁,通用的公式是N+1
6.3、动态设置
线程池的线程数还可以动态进行设置,线程池提供了两个方法
- setCorePoolSize:设置核心线程数
- setMaximumPoolSize:设置最大线城数
ThreadPoolExecutor executor =
new ThreadPoolExecutor(1, 10, 120, TimeUnit.SECONDS, new LinkedBlockingDeque<>());
executor.setCorePoolSize(10);
executor.setMaximumPoolSize(20);6.3.1、setCorePoolSize:动态设置核心线程数
通过修改this.corePoolSize来替换核心线程数
如果当前的工作线程数大于新设置的核心线程数,执行中断操作,中断多余线程
//如果当前的工作线程数大于新设置的核心线程数
if (workerCountOf(ctl.get()) > corePoolSize)
//执行中断操作
interruptIdleWorkers();
如果当前的核心线程数小于当前线程数
查看工作队列与差额的大小,取小的那个,以此作为循环计数
循环执行,添加工作线程,如果此时工作队列是空的,停止添加,等待execute方法进行添加
//如果当前的核心线程数小于当前线程数
if (delta > 0) {
//查看工作队列与差额的大小,取小的那个,以此作为循环计数
int k = Math.min(delta, workQueue.size());//循环执行,添加工作线程
//如果此时工作队列是空的,停止添加,等待execute方法进行添加
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
public void setCorePoolSize(int corePoolSize) {
if (corePoolSize < 0)
throw new IllegalArgumentException();
int delta = corePoolSize - this.corePoolSize;
this.corePoolSize = corePoolSize;
if (workerCountOf(ctl.get()) > corePoolSize)
interruptIdleWorkers();
else if (delta > 0) {
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}6.3.2、setMaximumPoolSize:动态设置核心线程数
通过修改this.maximumPoolSize来替换核心线程数
这个和上一个方法类似,都需要在新线程数小于当前线程数的情况下,中断多于线程。
public void setMaximumPoolSize(int maximumPoolSize) {
if (maximumPoolSize <= 0 || maximumPoolSize < corePoolSize)
throw new IllegalArgumentException();
this.maximumPoolSize = maximumPoolSize;
if (workerCountOf(ctl.get()) > maximumPoolSize)
interruptIdleWorkers();
}6.4、动态设置队列容量
队列容量比较有趣, 以LinkedBlockingDeque为例,这个队列的长度是不可变化的,但实际上,我们可以重新创建一个新的队列或是重写原本的队列,只需要将这个队列的capacity重新赋值,并且判断队列长度是否大于当前队列的任务个数,如果大于,就调用signalNotFull来唤醒阻塞的生产者。
7、线程监控
想要实现对线程池的监控,需要自己实现线程池。
继承ThreadPoolExecutor 类,实现构造线程池的方法,可以将beforeExecute执行前方法,afterExecute执行后方法进行重写,在这两个方法内进行线程池内容的监控。
public class ThreadPoolSelf extends ThreadPoolExecutor {
public ThreadPoolSelf(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void shutdown() {
super.shutdown();
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
//重写方法
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("初始线程数:"+this.getPoolSize());
System.out.println("核心线程数:"+this.getCorePoolSize());
System.out.println("正在执行的任务数量"+this.getActiveCount());
System.out.println("已经执行的任务数量"+this.getCompletedTaskCount());
System.out.println("任务总数"+this.getTaskCount());
}
}ExecutorsSelf 类似于Executors,可以建立自定义线程池。
public class ExecutorsSelf {
public static ExecutorService newThreadPoolSelf(int nThreads) {
return new ThreadPoolSelf(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
}调用实现如下
public class ThreadPool implements Runnable{
public static void main(String[] args) {
ThreadPoolExecutor executorService = (ThreadPoolExecutor)ExecutorsSelf.newThreadPoolSelf(3);
//预热所有核心线程数
executorService.prestartAllCoreThreads();
IntStream.range(1,100).forEach(i-> {
executorService.execute(new ThreadPool());
});
executorService.shutdown();
}
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}最后
以上就是忐忑星月最近收集整理的关于java多线程进阶(十)线程池1、线程存在的问题 2、池化技术3、线程池4、Java中的线程池5、线程池的原理6、计算线程池的线程数7、线程监控的全部内容,更多相关java多线程进阶(十)线程池1、线程存在内容请搜索靠谱客的其他文章。








发表评论 取消回复