DR(Disaster Recovery)系统容灾和BC(Business Continuity)业务连续性解决方案是业界基础架构Infrastructure方面的一个主要解决方案,各大存储硬件和软件公司都有自己的解决方案,总的来说,分为基于存储、服务器、以及软件应用三种方式或者相互组合。因为通常来说,容灾解决方案都会在业务系统已经投入运行一段时间后,由于重要性的不断增加才提上日程,所以建设一个容灾系统必须完善地考虑对现有系统的综合影响,仔细设计,否则会产生各种各样的麻烦和困难。下面就和大家分享一个真实的案例。
客户是一家在全球芯片行业排名靠前的外资企业,在中国拥有200mm和300mm两条生产线,每条生产线都有自己的MES(制造执行系统)系统。其中数据库MESDB是重中之重,采用
Oracle RAC来实现高可靠性,跑在两台满配的
HP rp7640上,后升级到
rp8640,存储系统也采取了HP高端的
XP12000。每个系统的两台主机通过自己的SAN连接到自己的XP12000上,两台XP12000通过CA(continuous access,类似
EMC的
SRDF)软件同步对方的MESDB数据库,防范万一XP12000故障,数据不丢失。系统架构图如下:
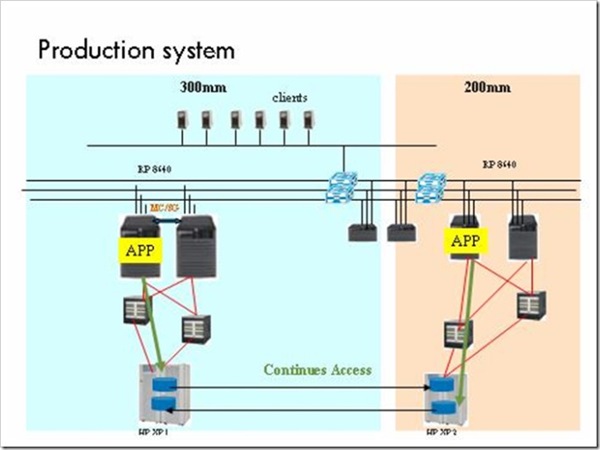
由于是芯片企业,系统可靠性是第一位的,一旦停机损失惨重(每小时的损失高达100万美金,主要是停产的产品销售额和高昂机器设备的折旧),所以在IT系统上是非常舍得投入的。虽然采用了RAC,但负载全部集中在其中一台机器上,采购两台一样配置的机器加RAC就是为了在down机时,能零时间切换到另外一台机器上。
从上图可以看出,200mm和300mm的MES系统互相隔离,两个SAN也没有连接起来。客户的应用部门认为,万一300mm的存储XP12000坏掉,虽然在200mm的XP12000系统上仍然有数据,但是应用并不能自动切换来访问,所以提出了系统容灾的项目。由于系统大部分是HP的,当然HP被邀请提交解决方案。另外客户在其他的系统上还使用了EMC的Symmetrix,有竞争才能获得更好的价格,同时EMC也对这样一个大客户虎视眈眈,所以EMC也参与了方案提交。最后总共提交了三个方案:
- solution 1:HP Campuscluster + RAC
- solution 2:HP Metrocluster+CA
- solution 3:Oracle data guard
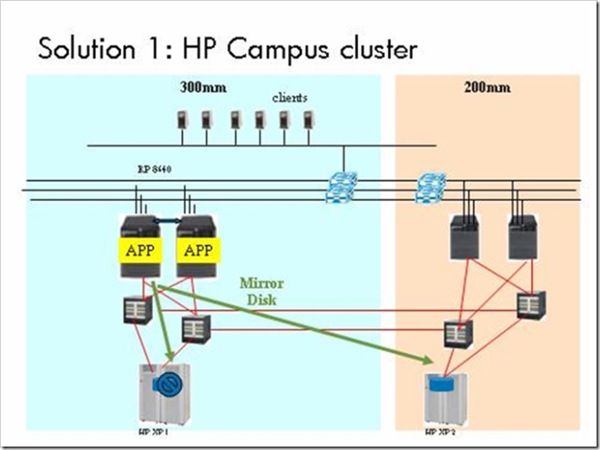
solution 1采用HP的Campuscluster来实现200mm和300mm两套系统的自动切换,利用Mirrordisk实现两个site的数据同步。该方案的系统架构图如下:
- solution 1的优点:支持Oracle RAC,可以实现在灾难时,零时间切换到另外一个site。实施不需要停机。
- solution 1的缺点:不支持CA,浪费现有投资;需要将两个SAN连接起来,让所有的Server可以访问两个存储,主机利用Mirrordisk同时写两边的存储,对主机的性能有影响。
本来这是一个不错的方案,但是由于XP在LUN上已经配置了条带化Strip(不知道是谁出的主意),Mirrordisk不支持,需要去掉strip,重新划卷,然后重新安装Oracle,从磁带备份恢复数据。这样不但需要停机1天以上,而且风险极大(客户的磁带备份重来没有做过恢复测试),万一数据无法恢复将变成一个大事故。
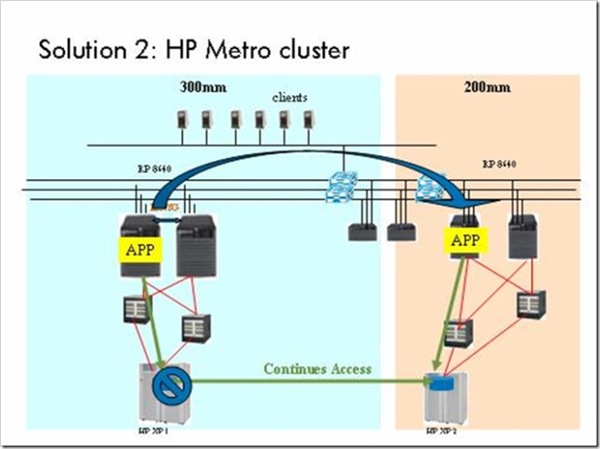
solution 2采用HP的Metrocluster来实现200mm和300mm两套系统的自动切换,利用CA实现两个site的数据同步。该方案的系统架构图如下:
- solution 2的优点:对于现有的硬件环境不需要调整,利用存储上的CA软件来实现数据同步对于服务器负载无影响。
- solution 2的缺点:由于Metrocluster不支持Oracle RAC,在两个site间发生切换时,MESDB数据库需要reboot。另外由于要去掉RAC,需要系统停机1~2小时。这两点客户都无法接受。
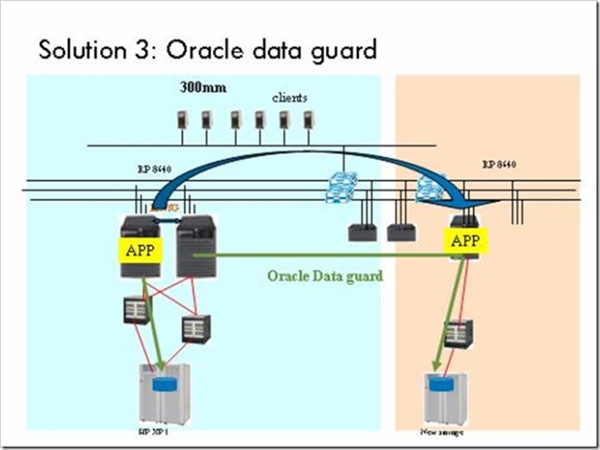
Solution 3是由EMC提出的方案。在一个HP的Installbase里要实现容灾方案,EMC只能采用基于应用的办法。具体办法是增加一台新的存储(当然是EMC的啦),然后利用Oracle的Data Guard来同步数据。Data Guard对存储没有要求,对于服务器要求是相同的OS和相同的Oracle版本,所以服务器还必须是HP的(EMC也没有服务器啦,当然不会眼红)。
- solution 3的优点:对于存储没有要求,厂商无关。
- solution 3的缺点:由于Data Guard的数据同步是基于Oracle的Redo Log或Arch Log,增加了主机的负载,而且要通过网络来传递数据,消耗了带宽;当灾难发生时,所有客户端必须重新连接备份站点的主机,会有中断影响;Data Guard运作有两种方式,同步或异步,同步模式对于主站点的性能影响大(主站点必须得到备份站点的肯定回复才能进行下一步操作),而异步模式可能在灾难切换时丢数据;在最初始的数据同步阶段,仍然需要系统停机,当两边数据一致之后备份站点才能基于日志进行更新。
综合分析上述三种方案,对于客户来说,停机都不可避免,不能满足客户不停机的硬指标。而且客户都需要不小的投资,获得的回报从上面的分析来看,都有很大不如意的地方,ROI不值。所以我们最后建议客户的方案是solution 4。
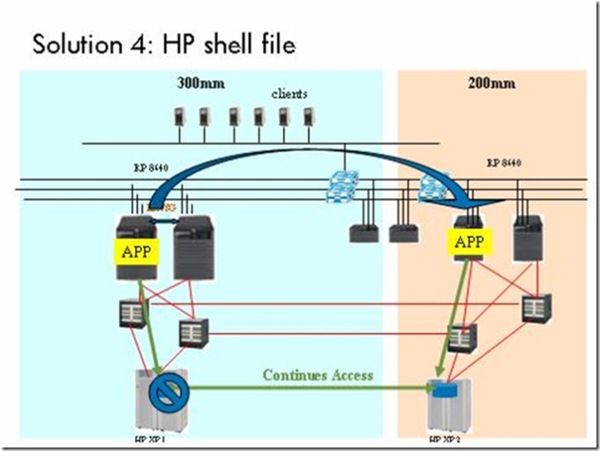
Solution 4主要是连通两个SAN,让主机都可以访问两个存储,然后在主机上写一个shell文件,在灾难发生时,系统管理员只需要one click执行该Shell文件就可以完成切换。该方案的架构图如下:
- solution 4的优点:不需要停机;投资最小。
- solution 4的缺点:仍然需要人工参与,不能做到100%自动化。
通过前面的具体分析,我们可以看到,一个DR方案设计需要全面细致的考虑,绝对不是靠厂商的售前技术力量用PPT就做出的方案,否则真到实施环节,就悔之晚矣(目标达不到,或投资打水漂)。
当然为什么在这个案例中,我们会碰到各种技术限制将我们陷入两难境地,最根本是客户的初始系统设计有很多不够完美的地方,不够灵活,投入运行后再要调整就有很多限制。主要的不完美地方如下,希望其他的客户在系统设计初期找对全系统真正专业的顾问一起参与:
- Oracle的RAC一个非常好的feature就是在提供高可靠性的同时,将负荷分担在cluster内的多台机器上,提高系统利用率,节省投资。该案例中客户在正常状态下,只使用了一台服务器的处理能力,实在浪费。后来由于rp7640的处理能力不够升级到两台同配置的rp8640,浪费更大。采用分担负载的方案凭空增加一倍的处理能力也许就不需要升级主机了。当然作为芯片行业,可能会担心采用分担负载的方式,一旦故障发生,负载全部切换到一台机器时,处理能力不足造成连锁down机(据说某电力客户就发生过该情况,不过是否是RAC的缺陷不确定),不过完全可以将200mm和300mm两套系统组成一个大的RAC,正常情况下,每个应用的负载各自运行在一台主机上,这样三台主机构成的RAC就可以实现同样的高可靠性,相比生产环境,节省了一台主机。
- 生产环境两个SAN互相隔离,冠冕堂皇的理由是系统安全,可是造成的存储孤岛限制了系统架构的灵活性。在同一个机房中还用昂贵的CA来同步数据,实在是不经济的做法。同一个机房也完全不能达到容灾的要求(真有火灾等天灾还不是一毁全毁)。
- XP12000已经是企业级的高端存储,所有的部件都是双份的,不存在单点故障,无需采用两套XP,而且采用CA来同步数据,对于每一个XP来说,只有一半的磁盘容量是服务于业务系统的,数据冗余太大。
- MES也是一个典型的OLTP应用,每次写入的数据并不会太多。而XP存储作为企业级的高端存储,完全用VG就可以将数据分散到多个控制器下的多个盘中,实现I/O的并发,再横向加上Strip条带化完全没有必要(主要原因是一开始设计系统时,对于某些应用的负载估计不足,XP上分配的主机端口不足造成性能不好,没有找到根本原因之前,想用Strip的方式提高并发,结果瓶颈不在于此,最后还是增加主机端口解决,但Strip加上后要撤销可不容易)
- 整个系统设计中有很多点似乎被厂商忽悠而增大投资的嫌疑:4台主机两两RAC;用昂贵的CA在一个50米不到的距离内来实现数据同步,而且冗余一半的XP磁盘等。
转载于:https://blog.51cto.com/64239/172209
最后
以上就是耍酷棉花糖最近收集整理的关于容灾设计真实案例分析的全部内容,更多相关容灾设计真实案例分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复