1.Principal components analysis(主成分分析)
应用:
降维就是一种对高维度特征数据预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
降维具有如下一些优点:
- 使得数据集更易使用。
- 降低算法的计算开销。
- 去除噪声。
- 使得结果容易理解。
降维的算法有很多,比如奇异值分解(SVD)、主成分分析(PCA)、张量分解(TD)
1.1Principal components analysis 基本原理
首先我们先来看主成分分析的步骤:
假设我们有P个n维数据样本D,样本的值为[V1,V2,…,Vn]要把他们降维到m维(m<n)
(1)求出所有数据样本的平均值
S
‾
=
1
/
n
∑
i
=
1
n
V
i
overline S=1/nsum_{i=1}^{n}V_i
S=1/n∑i=1nVi,对所有数据进行中心化
X
i
=
X
i
−
S
‾
X_i=X_i-overline S
Xi=Xi−S
(2)计算数据样本的协方差矩阵
C
o
v
(
x
1
,
x
2
,
.
.
.
,
x
n
)
=
X
X
T
=
[
c
o
v
(
x
1
,
x
2
)
.
.
.
c
o
v
(
x
1
,
x
n
)
.
.
.
.
.
.
.
.
.
c
o
v
(
x
n
,
x
1
)
.
.
.
c
o
v
(
x
n
,
x
n
)
]
(
n
∗
n
维
)
Cov(x_1 ,x_2,...,x_n)=XX^T= left[begin{matrix} cov(x_1,x_2)&...&cov(x_1,x_n)\...&...&...\cov(x_n,x_1)&...&cov(x_n,x_n) end{matrix} right](n*n维)
Cov(x1,x2,...,xn)=XXT=⎣⎡cov(x1,x2)...cov(xn,x1).........cov(x1,xn)...cov(xn,xn)⎦⎤(n∗n维)
c
o
n
v
(
X
,
Y
)
=
E
(
X
−
E
X
)
(
Y
−
E
Y
)
=
1
/
n
−
1
∑
i
=
1
n
(
x
i
−
x
‾
)
(
y
i
−
y
‾
)
conv(X,Y)=E(X-EX)(Y-EY)=1/n-1sum_{i=1}^n(x_i-overline x)(y_i-overline y)
conv(X,Y)=E(X−EX)(Y−EY)=1/n−1∑i=1n(xi−x)(yi−y)
协方差为正时,说明X和Y是正相关关系;协方差为负时,说明X和Y是负相关关系;协方差为0时,说明X和Y是相互独立。Cov(X,X)就是X的方差。当样本是n维数据时,它们的协方差实际上是协方差矩阵(对称方阵).
(3)对协方差矩阵
X
X
T
XX^T
XXT进行特征分解
(4)取出最大的m个特征值并求出相应的特征向量组成W
(
w
1
,
w
2
,
.
.
.
,
w
m
)
(w_1,w_2,...,w_m)
(w1,w2,...,wm),将W矩阵单位化后形成特征向量矩阵W
(5)对P个样本转化为
P
n
e
w
P_{new}
Pnew,
P
n
e
w
P_{new}
Pnew=
W
⊙
P
W odot P
W⊙P
W = [ w 1 , w 2 , . . . , w m ] W=left[begin{matrix}w_1,w_2,...,w_m end{matrix} right] W=[w1,w2,...,wm], 维度信息:” ( m , n ) × ( n , 1 ) = ( m , 1 ) (m,n) times (n,1)=(m,1) (m,n)×(n,1)=(m,1)
(6)得到P个m维新的数据样本
1.2 Example
**假设我们的数据集有10个二维数据(2.5,2.4), (0.5,0.7), (2.2,2.9), (1.9,2.2), (3.1,3.0), (2.3, 2.7), (2, 1.6), (1, 1.1), (1.5, 1.6), (1.1, 0.9),需要用PCA降到1维特征。
首先我们对样本中心化,这里样本的均值为(1.81, 1.91),所有的样本减去这个均值后,即中心化后的数据集为(0.69, 0.49), (-1.31, -1.21), (0.39, 0.99), (0.09, 0.29), (1.29, 1.09), (0.49, 0.79), (0.19, -0.31), (-0.81, -0.81), (-0.31, -0.31), (-0.71, -1.01)。
现在我们开始求样本的协方差矩阵,由于我们是二维的,则协方差矩阵为:
XXT=(cov(x1,x1)cov(x2,x1)cov(x1,x2)cov(x2,x2))
对于我们的数据,求出协方差矩阵为:
XXT=(0.6165555560.6154444440.6154444440.716555556)
求出特征值为(0.0490833989, 1.28402771),对应的特征向量分别为:(0.735178656,0.677873399)T(−0.677873399,−0.735178656)T,由于最大的k=1个特征值为1.28402771,对于的k=1个特征向量为(−0.677873399,−0.735178656)T. 则我们的W=(−0.677873399,−0.735178656)T
我们对所有的数据集进行投影z(i)=WTx(i),得到PCA降维后的10个一维数据集为:(-0.827970186, 1.77758033, -0.992197494, -0.274210416, -1.67580142, -0.912949103, 0.0991094375, 1.14457216, 0.438046137, 1.22382056) **
1.3 PCA的优缺点
1.优点:
(1)PCA分析仅仅需要在数据集内计算平均值,方差等信息,不受数据集外任何条件的约束。
(2)PCA分析各主成分之间是相互正交的,可消除成分之间信息的影响。
(3)PCA保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
2.缺点:
(1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
(2)方差小的特征也可能含有样本差异的重要信息,直接降维丢弃很可惜。
1.4 PCA的Python实现
import numpy as np
def pca(X,k):#k is the components you want
#mean of each feature
n_samples, n_features = X.shape
mean=np.array([np.mean(X[:,i]) for i in range(n_features)])
#normalization
norm_X=X-mean
#scatter matrix
scatter_matrix=np.dot(np.transpose(norm_X),norm_X)
#Calculate the eigenvectors and eigenvalues
eig_val, eig_vec = np.linalg.eig(scatter_matrix)
eig_pairs = [(np.abs(eig_val[i]), eig_vec[:,i]) for i in range(n_features)]
# sort eig_vec based on eig_val from highest to lowest
eig_pairs.sort(reverse=True)
# select the top k eig_vec
feature=np.array([ele[1] for ele in eig_pairs[:k]])
#get new data
data=np.dot(norm_X,np.transpose(feature))
return data
X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
print(pca(X,1))
代码原文链接
2.Singular Value Decomposition(奇异值分解)
2.1 Singular Value Decomposition 基本原理
1.首先先说一下用到的基本线代基础:
(1)对n阶方阵A,如果可以找到可逆矩阵P使得
P
−
1
A
P
=
Λ
P^{-1}AP=Lambda
P−1AP=Λ,那么我们就可以说A矩阵可以相似对角化
1>. A有n个不同的特征值.
2>.A的
t
i
t_i
ti重特征值对应的线性无关的特征向量
(2)矩阵相似对角化为
Λ
Lambda
Λ可以简化矩阵之间的运算并且通过特征值和特征向量可以反求出矩阵A
(3)一般我们会把W的这n个特征向量标准化,即满足||wi||2=1, 或者说wTiwi=1,此时W的n个特征向量为标准正交基,满足WTW=I,即WT=W−1, 也就是说W为正交矩阵
(4)注意到要进行特征分解,矩阵A必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了
2.进入SVD正题:
SVD也是矩阵分解的一种方式但是它并不要求分解矩阵必须为方阵
S
V
D
:
A
=
U
Λ
V
T
SVD:A=ULambda V^T
SVD:A=UΛVT
**
其
中
U
矩
阵
维
度
为
m
×
m
其中U矩阵维度为 m times m
其中U矩阵维度为m×m,
Λ
的
维
度
为
m
×
n
Lambda 的维度为mtimes n
Λ的维度为m×n,
V
T
的
维
度
为
n
×
n
V^T的维度为ntimes n
VT的维度为n×n,其中U,V均为正交矩阵表示为
U
U
T
=
E
,
V
V
T
=
E
UU^T=E,VV^T=E
UUT=E,VVT=E,如下图所示:
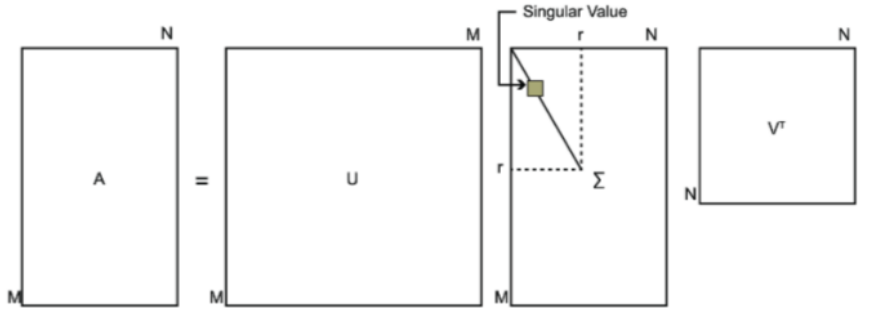
1.首先我们从A矩阵中要得到一个方阵
A
A
T
AA^T
AAT,既然已经得到方阵我们可以对方阵进行特征分解满足
A
A
T
v
i
=
λ
i
v
i
AA^T v_i = lambda _iv_i
AATvi=λivi 就得到了
A
A
T
AA^T
AAT的特征值和特征向量.
2.特征值对应的特征向量拼成了矩阵V,一般我们将V中的每个特征向量叫做A的左奇异向量
3.首先我们从A矩阵中要得到一个方阵
A
T
A
A^TA
ATA,既然已经得到方阵我们可以对方阵进行特征分解满足
A
T
A
v
i
=
λ
i
v
i
A^TA v_i = lambda _iv_i
ATAvi=λivi 就得到了
A
T
A
A^TA
ATA的特征值和特征向量.
4.特征值对应的特征向量拼成了矩阵U,一般我们将U中的每个特征向量叫做A的右奇异向量
5.接下来就是奇异值矩阵了
A
=
U
Λ
V
T
,
A
V
=
U
Λ
,
A
v
i
=
u
i
Λ
,
Λ
=
A
⊙
v
i
/
u
i
A=ULambda V^T ,AV=ULambda ,Av_i=u_iLambda ,Lambda=Aodot v_i/u_i
A=UΛVT,AV=UΛ,Avi=uiΛ,Λ=A⊙vi/ui
其实奇异值矩阵就是左奇异值和右奇异值的开根号,
Λ
=
[
v
1
v
2
.
.
.
u
i
]
Lambda=left[begin{matrix} sqrt{v_1}&&&\&sqrt{v_2} &&\&&...&&\&&&sqrt{u_i}end{matrix}right]
Λ=⎣⎢⎢⎡v1v2...ui⎦⎥⎥⎤
(1) 求 A A T AA^T AAT的特征值和特征向量,用单位化的特征向量构成 U。
(2) 求 A A T AA^T AAT的特征值和特征向量,用单位化的特征向量构成 V。
(3) 将 A A T AA^T AAT或者 A T A A^TA ATA的特征值求平方根,然后构成 Λ Lambda Λ。
2.2 Example

2.3 SVD,PCA的区别和类似
1. SVD可以获取另一个方向上的主成分,而PCA只能获得单个方向上的主成分
2.隐语义索引(Latent semantic indexing,简称LSI)通常建立在SVD的基础上,通过低秩逼近达到降维的目的。
3.PCA也能达到降维的目的,但是PCA需要进行零均值化,且丢失了矩阵的稀疏性
4.通过SVD可以得到PCA相同的结果,但是SVD通常比直接使用PCA更稳定。因为PCA需要计算X⊤X的值,对于某些矩阵,求协方差时很可能会丢失一些精度。
5.SVD一般是用来诊断两个场的相关关系的,而PCA是用来提取一个场的主要信息的(即主分量)
6.为什么使用PCA而不是SVD:转成协方差矩阵,是对称矩阵,特征值分解比SVD奇异值分解的计算量小的多
3.张量分解
3.1 Tensor Decomposition
**1.由于高阶张量的性质和应用需求,我们使用张量特征值和张量分解,使用张量分解可以保持数据内在结构不仅可以避免损失重要的信息也是解决实际问题的需要。
2.张量分解可以保持数据集中的对方差贡献的最大特征同时减少数据的维度,张量分解是矩阵奇异值分解在多重线性代数的高阶推广.
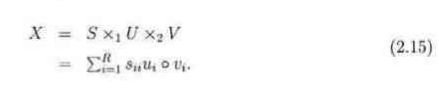
3.式子2.15表示一个张量X分解为一个对角核张量和两个正交矩阵U,V的1模式和2模式的乘积但是高阶张量不能保证同时有对角核张量和正交矩阵以至于全部分解为2.15的格式所以有了CP分解和Tucker分解.
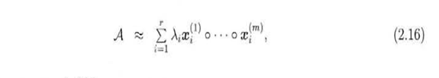
4.CP分解保持了核张量的对角性将m阶张量分解为r个秩1张量的线性组合。||Xi||=1。
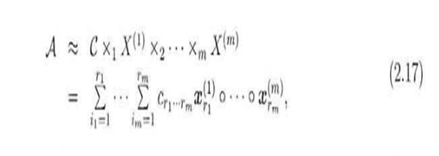
5.Trucker分解保持了因子的正交性。当r1,r2,…,rm相等时并且因子矩阵是对角化Trucker分解就可以表示为特殊的CP分解.
6.张量分解在信号处理和数据统计等领域有非常重要的作用,他可以保持数据集中的对 方差贡献最大特征同时减少数据的维数,对复杂数据分析意义重大,张量分解是矩阵奇异值分解的推广**
最后
以上就是时尚斑马最近收集整理的关于PCA,SVD,TD 张量分解的原理区别联系1.Principal components analysis(主成分分析)2.Singular Value Decomposition(奇异值分解)3.张量分解的全部内容,更多相关PCA,SVD,TD内容请搜索靠谱客的其他文章。







![[QT] 无边框窗体改变大小 完美实现](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)
发表评论 取消回复