我是靠谱客的博主 大力灰狼,这篇文章主要介绍王爽 汇编语言第三版 第8章( 寻址方式 ) --- 数据处理的两个问题第八章 数据处理的两个基本问题8.6 综合应用8.7 div 指令 ( 除法 指令 )8.8 伪指令 dd ( 定义 双字 )8.9 dup 指令 ( 数据的重复 )实验 7,现在分享给大家,希望可以做个参考。
第八章 数据处理的两个基本问题



8.6 综合应用



示例代码 1:
assume cs:codesg,ds:datasg
datasg segment
db 1024 dup (0)
datasg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
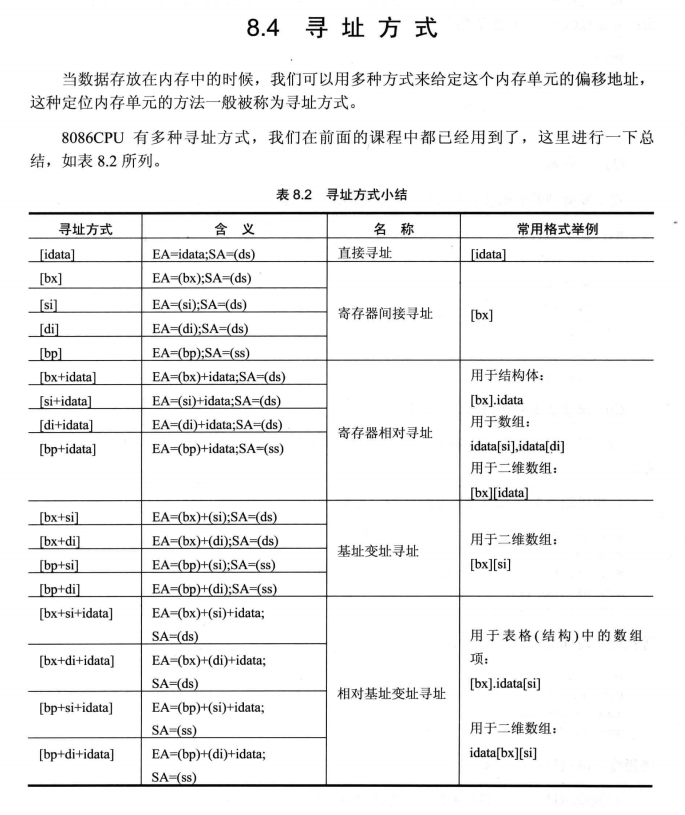
mov bx,60h ; 确定记录地址 ds:bx
mov word ptr [bx+0ch],38 ; 排名字段改为 38
add word ptr [bx+0eh],70 ; 收入字段增加 70
mov si,0
mov byte ptr [bx+10h+si], 'V' ;用 si 来定位产品字符串中的字符
inc si
mov byte ptr [bx+10h+si], 'A'
inc si
mov byte ptr [bx+10h+si], 'X'
mov ax,4c00h
int 21h
codesg ends
end startdebug 的 反汇编结果截图:
示例代码 2( 使用 C 语言风格 ):
assume cs:codesg,ds:datasg
datasg segment
db 1024 dup (0)
datasg ends
codesg segment
start:
mov ax,codesg
mov ds,ax
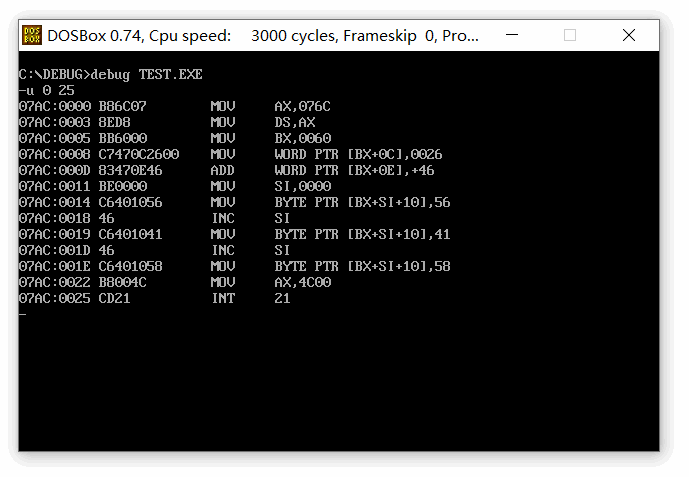
mov bx,60h ;记录首地址
mov word ptr [bx].0ch, 38 ; 排名字段改为 38, 相当于 C 中的 dec.pm = 38
add word ptr [bx].0eh, 70 ; 收入字段增加 70, 相当于 C 中的 dec.sr = dec.sr + 38
mov si,0 ; 相当于 C 中的 i = 0
mov byte ptr [bx].10h[si], 'V' ; dec.cp[i] = 'V'
inc si ; i++
mov byte ptr [bx].10h[si], 'A' ; dec.cp[i] = 'A'
inc si ; i++
mov byte ptr [bx].10h[si], 'X' ; dec.cp[i] = 'X'
mov ax,4c00h
int 21h
codesg ends
end startdebug 的 反汇编结果截图:
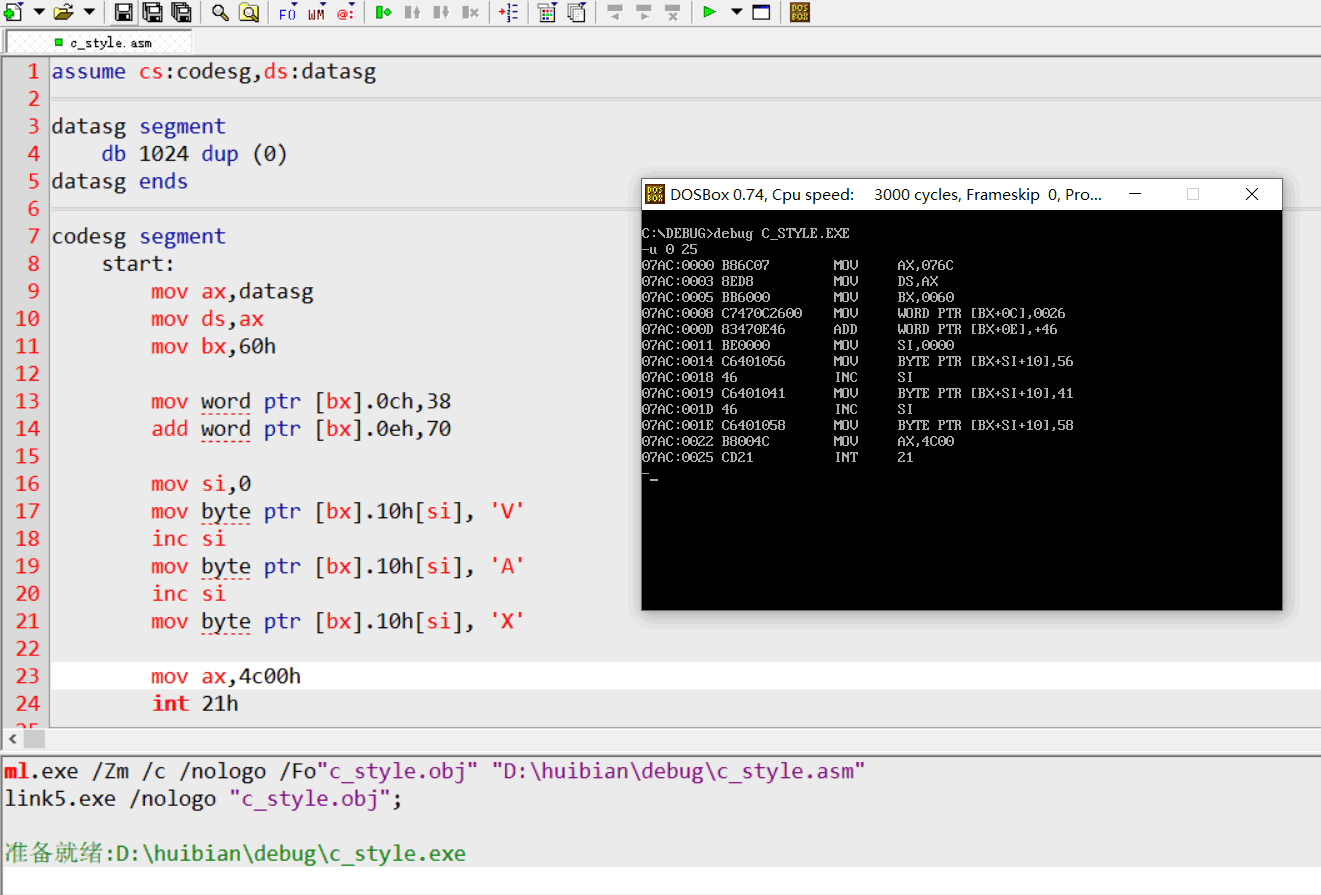
可以看到反汇编结果和上面的结果是一样的。
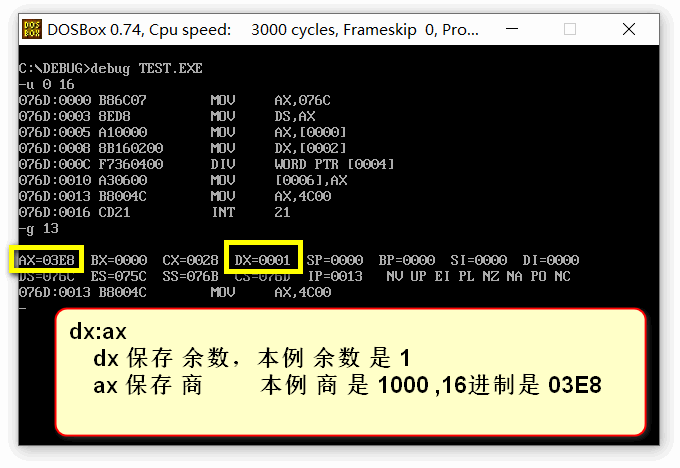
8.7 div 指令 ( 除法 指令 )

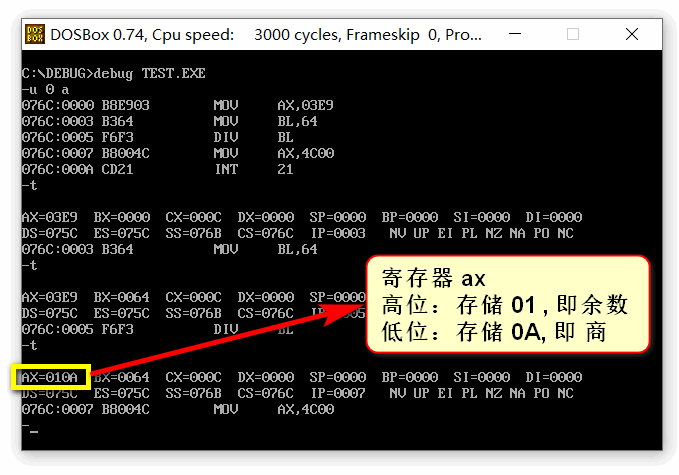
运行截图:
8.8 伪指令 dd ( 定义 双字 )

8.9 dup 指令 ( 数据的重复 )

实验 7

示例代码 1( 使用绝对定位 ):
assume cs:codesg,ds:data
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;84字节。总共 21 个年份,一个年份4个字节,总共 84 字节
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;84字节
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;通过计算得到每一个代码段相对于起始的偏移量
data ends
table segment
db 21 dup('year summ ne ?? ')
table ends
codesg segment
start:
mov ax,data
mov ds,ax
;mov ax,table
;mov es,ax
sub bx,bx ; mov bx,0
sub di,di ; mov di,0
mov cx,21
;日期导入
write_data:
mov ax,ds:[di]
mov ds:[bx+224],ax ; 224为从data段起始跳到table起始
add di,2 ; 日期为四个字节一组,而16位寄存器最大只能存两个字节,所以每次加二
mov ax,ds:[di]
mov ds:[bx+226],ax
add di,2
add bx,16 ;在table字段里换行输入日期
loop write_data
sub bx,bx
mov cx,21
;收入导入
wite_salary:
mov ax,ds:[di] ;此di是上段循环最后的di,没有重置
mov ds:[bx+229],ax ;229为从data段起始跳到table段收入输入的起始
add di,2 ;收入为四个字节一组,而16位寄存器最大只能存两个字节,所以每次加二
mov ax,ds:[di]
mov ds:[bx+231],ax
add di,2
add bx,16 ;在table字段里换行输入收入
loop wite_salary
sub bx,bx
mov cx,21
;雇员数导入
write_employees:
mov ax,ds:[di] ;此di是上段循环最后的di,没有重置
mov ds:[bx+234],ax ;234为从data段起始跳到table雇员数输入的起始
add di,2
add bx,16 ;在table字段里换行输入雇员数
loop write_employees
sub di,di ;数据来源不再是数据段的顺序读取
sub bx,bx
sub si,si
mov cx,21
;人均收入导入
write_average:
mov ax,ds:[di+84] ;定位到收入起始,将收入数据导入ax,dx中
mov dx,ds:[di+86]
div word ptr ds:[si+168] ;定位到雇员数起始
mov ds:[bx+237],ax ;将算数结果存入table的人均收入位置
add di,4
add si,2
add bx,16 ;在table字段里换行输入人均收入
loop write_average
mov ax,4c00h
int 21h
codesg ends
end start
示例代码 2:( 使用相对定位 )
assume cs:codesg,ds:datasg
datasg segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;84字节。总共 21 个年份,一个年份4个字节,总共 84 字节
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;84字节。收入总共 21 个字段,每个字段4个字节,总共 84 字节
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;通过计算得到每一个代码段相对于起始的偏移量
datasg ends
tablesg segment
db 21 dup('year summ ne ?? ')
tablesg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
mov ax,tablesg
mov es,ax
; bx 指示 table 段中每一行首地址,因为每一行都占16个字节,所以bx步长是16
sub bx,bx ; mov bx,0 bx置为0,指向 tablesg 头
sub di,di ; mov di,0
mov cx,21
;日期导入
write_date:
mov ax,ds:[di]
mov es:[bx][0],ax
add di,2 ; 日期为四个字节一组,而16位寄存器最大只能存两个字节,所以每次加二
mov ax,ds:[di]
mov es:[bx][2],ax
add di,2
add bx,16 ; 在table字段里换行输入日期
loop write_date
sub bx,bx ;bx置为0,指向 tablesg 头
mov cx,21
;收入导入
wite_salary:
mov ax,ds:[di] ;此di是上段循环最后的di,没有重置
mov es:[bx+5],ax ;table段收入输入的起始
add di,2 ;收入为四个字节一组,而16位寄存器最大只能存两个字节,所以每次加二
mov ax,ds:[di]
mov es:[bx+7],ax
add di,2
add bx,16 ;在table字段里换行输入收入
loop wite_salary
sub bx,bx ;bx置为0,指向 tablesg 头
mov cx,21
;雇员数导入
write_employees:
mov ax,ds:[di] ;此di是上段循环最后的di,没有重置
mov es:[bx+10],ax ;雇员数的起始地址
add di,2
add bx,16 ;在table字段里换行输入雇员数
loop write_employees
sub di,di ;数据来源不再是数据段的顺序读取
sub bx,bx
sub si,si
mov cx,21
;人均收入导入
write_average:
mov ax,es:[bx][5] ;定位到收入起始,将收入数据导入ax,dx中
mov dx,es:[bx][7]
div word ptr es:[bx][10] ;定位到雇员数起始
mov es:[bx][13],ax ;将算数结果存入table的人均收入位置
add bx,16 ;在table字段里换行输入人均收入
loop write_average
mov ax,4c00h
int 21h
codesg ends
end start
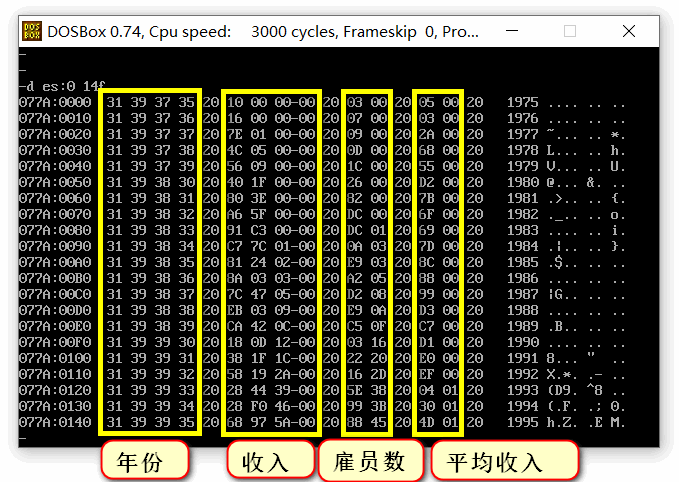
第一个循环执行年份输入,第二个收入输入,第三个雇员数输入,第四个人均收入输入,在人均收入的数据获取时使用div除法运算得到数据源
运行截图:
示例代码 3( 使用一次循环 ):
assume cs:codesg
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;84字节。总共 21 个年份,一个年份4个字节,总共 84 字节
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;84字节
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;通过计算得到每一个代码段相对于起始的偏移量
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
codesg segment
start: mov ax,data ;取得数据段
mov ds,ax
mov ax,table
mov es,ax
mov cx,21
mov si,0
mov di,0
mov bx,0
s: ;把年份送到table中
mov ax,ds:[bx]
mov es:[di+0],ax
mov ax,ds:[bx+2]
mov es:[di+2],ax
;把收入送到table中
mov ax,ds:[bx+84]
mov es:[di+5],ax
mov ax,ds:[bx+86]
mov es:[di+7],ax
;转移雇员人数
mov ax,ds:[168+si]
mov es:[di+10],ax
;计算人均收入并把其送到table中
mov ax,ds:[84+bx]
mov dx,ds:[86+bx]
div WORD ptr ds:[168+si]
mov es:[di+13],ax
add si,2 ; 数据段中 雇员人数是 2 字节偏移量
add bx,4 ; 数据段中 年份 和 收入都是 4字节偏移量
add di,16 ; table 表中行偏移量
loop s
mov ax,4c00h
int 21h
codesg ends
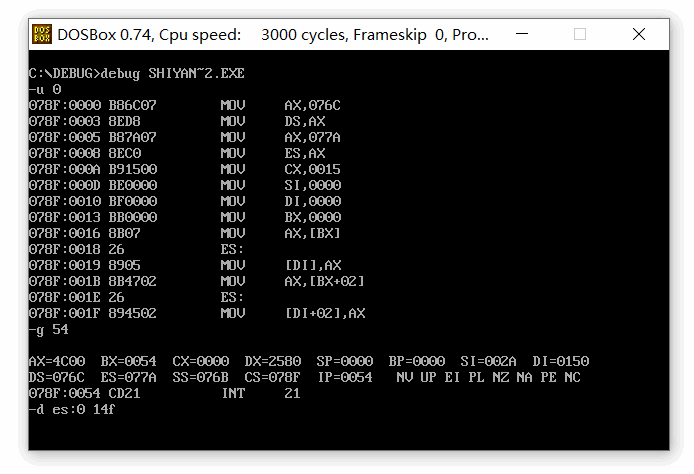
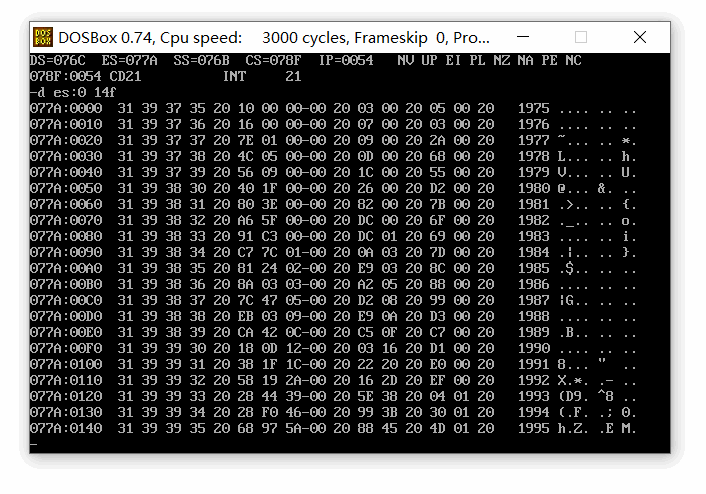
end start截图( 注意看编译后可执行程序的文件名,masm编译汇编程序的时候,其源文件名不能超过8位,超过8位时,会自动编译成不知道什么名称,我的源文件名是 shiyan_7_2.asm,已经超过8位,生成的可执行程序名是 shiyan~2.exe ):
最后
以上就是大力灰狼最近收集整理的关于王爽 汇编语言第三版 第8章( 寻址方式 ) --- 数据处理的两个问题第八章 数据处理的两个基本问题8.6 综合应用8.7 div 指令 ( 除法 指令 )8.8 伪指令 dd ( 定义 双字 )8.9 dup 指令 ( 数据的重复 )实验 7的全部内容,更多相关王爽内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复