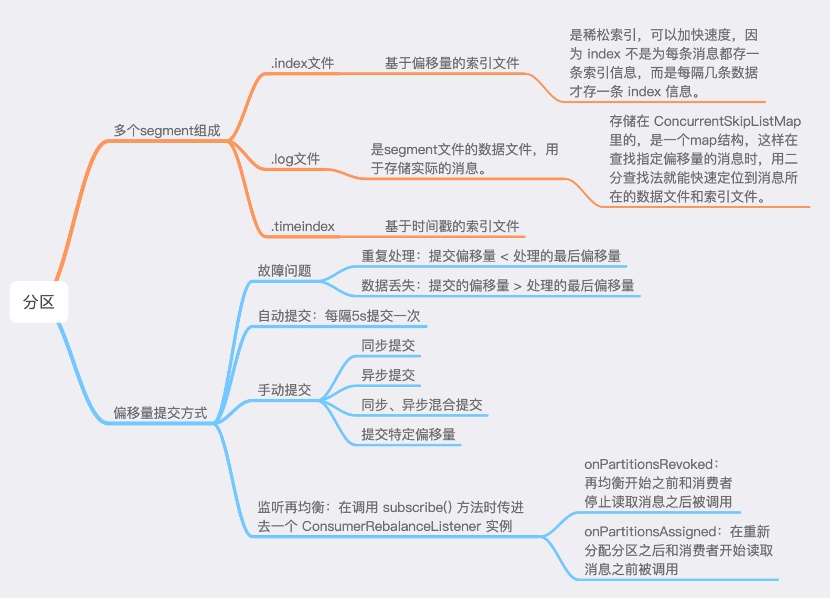
【分区、片段、偏移量】
1. 每个分区是由多个Segment组成,当Kafka要写数据到一个partition时,它会写入到状态为active的segment中。如果该segment被写满,则一个新的segment将会被新建,然后变成新的“active” segment。
2. 偏移量:分区中的每一条消息都会被分配的一个连续的id值,该值用于唯一标识分区中的每一条消息。
3. 每个segment中则保存了真实的消息数据。每个Segment对应于一个索引文件与一个日志文件。segment文件的生命周期是由Kafka Server的配置参数所决定的。比如说,server.properties文件中的参数项log.retention.hours=168就表示7天后删除老的消息文件。
4. 每个segment有以下3种数据文件:
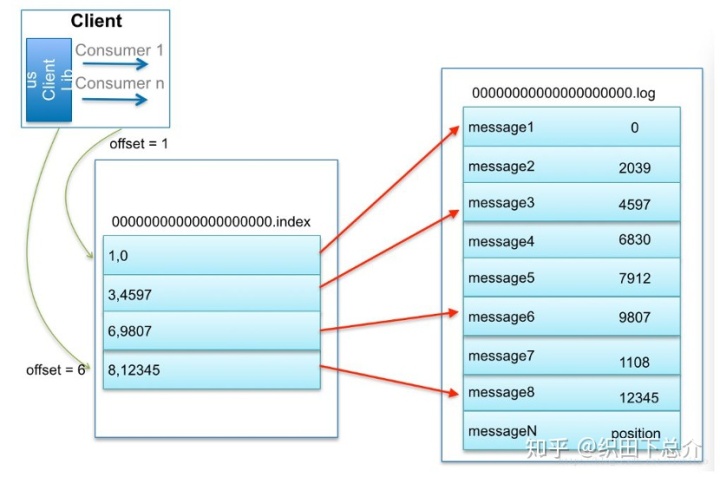
00000000000000000000.index:基于偏移量的索引文件,存放着消息的offset和其对应的物理位置,是稀松索引。
00000000000000000000.log:它是segment文件的数据文件,用于存储实际的消息。该文件是二进制格式的。log文件是存储在 ConcurrentSkipListMap 里的,是一个map结构,key是文件名(offset),value是内容,这样在查找指定偏移量的消息时,用二分查找法就能快速定位到消息所在的数据文件和索引文件。
00000000000000000000.timeindex:基于时间戳的索引文件。
命名规则:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。没有数字则用0填充。
[稀松索引]:稀松索引可以加快速度,因为 index 不是为每条消息都存一条索引信息,而是每隔几条数据才存一条 index 信息,这样 index 文件其实很小。kafka在写入日志文件的时候,同时会写索引文件(.index和.timeindex)。默认情况下,有个参数log.index.interval.bytes限定了在日志文件写入多少数据,就要在索引文件写一条索引,默认是4KB,写4kb的数据然后在索引里写一条索引。
5. 为什么要分多个segment?
新数据加在文件的末尾(调用内部方法),不论文件多大,该操作的时间复杂度都是O(1),但是在查找某个 offset 的时候,是顺序查找,如果文件很大的话,查找的效率就会很低。
6. 如何通过 offset 查找 message
通过二分查找文件列表,快速定位到具体的segment文件,再以对应的.index作为索引在.log中查找具体的消息。
【偏移量提交方式】
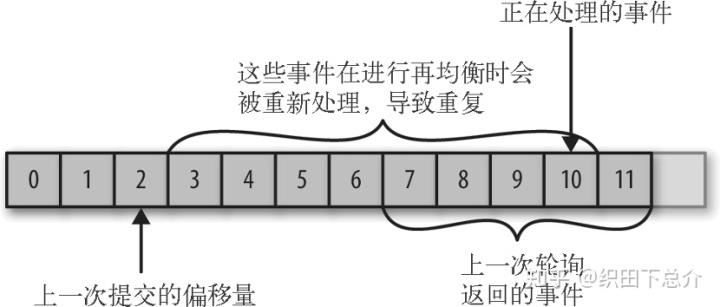
数据重复:如果提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
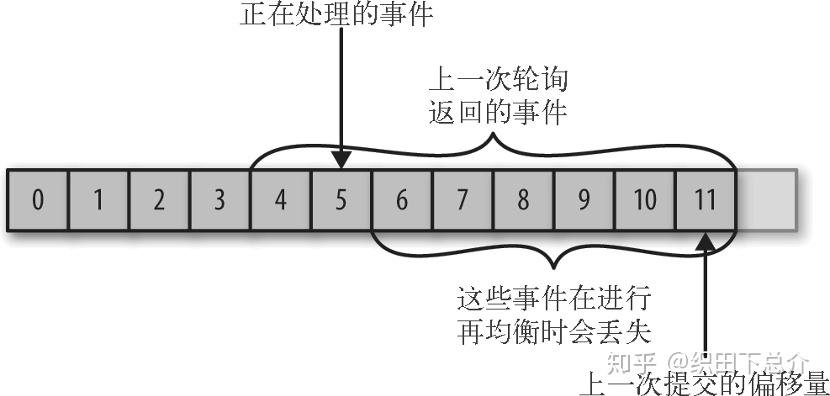
数据丢失:如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么助于两个偏移量之间的消息会丢失。
所以,处理偏移量的方式对客户端有很大影响。KafkaConsumer API提供了很多中方式来提交偏移量
l 自动提交:当 enable.auto.commit 属性被设为 true,那么每过 5s,消费者会自动把从 poll()方法接收到的最大偏移量提交上去。这是因为提交时间间隔由 auto.commit.interval.ms 控制,默认值是 5s。自动提交是在轮询里进行的。容易出现数据重复。
l 手动提交:auto.commit.offset 设为 false。包括同步、异步、混合提交和提交特定偏移量。
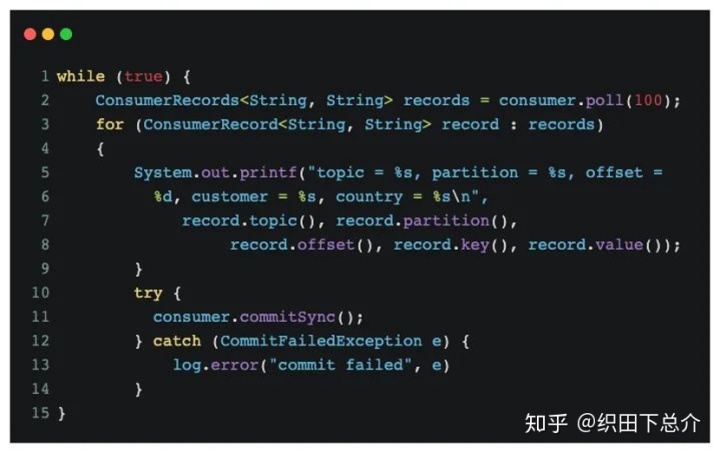
A. 同步提交:
使用 commitSync()会提交由 poll() 方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。在处理完所有记录后要确保调用了 commitSync(),否则还是会有丢失消息的风险。如果发生了再均衡,从最近一批消息到发生再均衡之间的所有消息都将被重复处理。
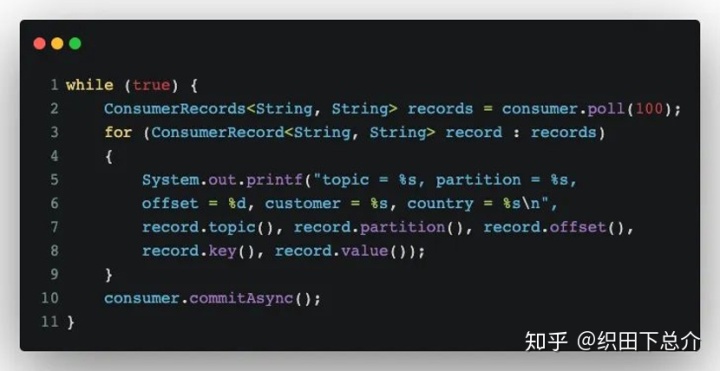
B. 异步提交:
同步提交有一个不足之处,在broker对提交请求作出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量。使用异步提交,只管发送提交请求,无需等待broker响应。在成功提交或遇到无法恢复的错误之前,commitSync()会一直重试,而commitAsync()不会重试,因为避免提交了一个较旧版本的偏移量覆盖了最新的偏移量。
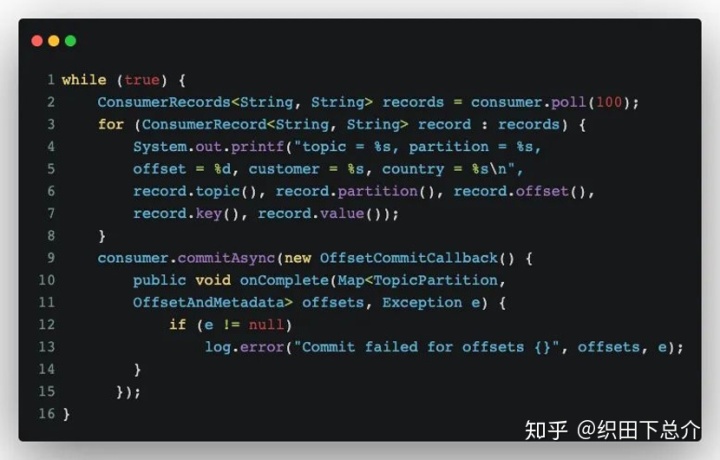
commitAsync() 也支持回调,在 broker 作出响应时会执行回调。回调经常被用于记录提交错误或生成度量指标。如果要用它来进行重试,则一定要注意提交的顺序(可使用一个单调递增的序列号维护异步提交顺序)
C. 同步和异步混合提交:
在程序正常运行过程中,我们使用 commitAsync 方法来进行提交,这样的运行速度更快,而且就算当前提交失败,下次提交成功也可以。如果直接关闭消费者,就没有所谓的“下一次提交”了,因为不会再调用poll()方法。使用 commitSync() 方法会一直重试,直到提交成功或发生无法恢复的错误。
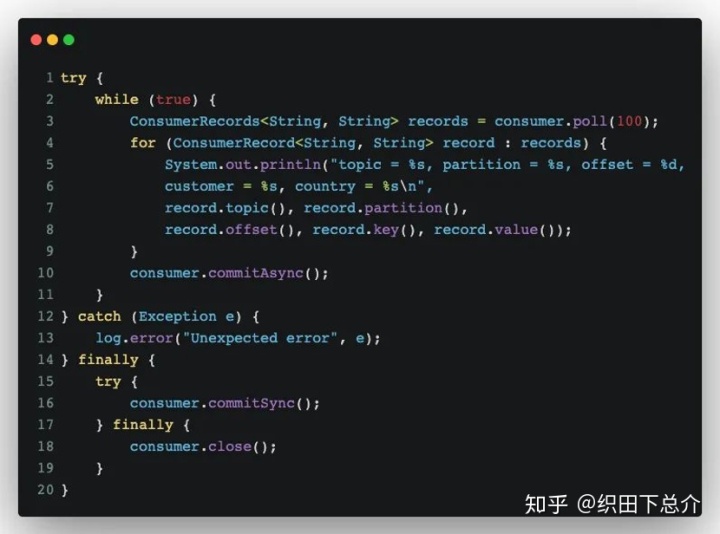
D. 提交特定的偏移量(操作复杂):
一般提交偏移量的频率和处理消息批次的频率是一样的。如果 poll() 方法返回一大批数据,为了避免再均衡引发的重复处理整批消息,消费者 API 允许调用 commitSync() 和 commitAsync() 方法时传入希望提交的分区和偏移量的 map。不过因为消费者可能不只读取一个分区,你需要跟踪所有分区的偏移量,所以特定偏移量的提交会使得代码更加复杂。
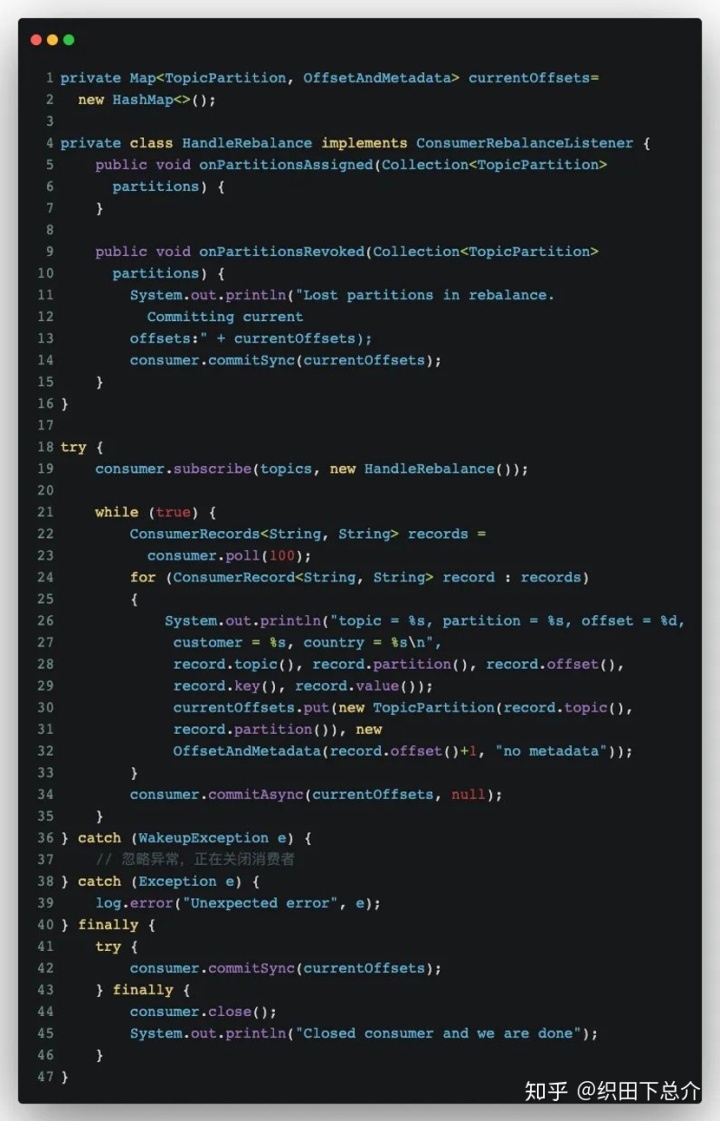
[监听再均衡]
如果 Kafka 触发了再均衡,我们需要在消费者失去对一个分区的所有权之前提交最后一个已处理记录的偏移量,可能还需要关闭文件句柄、数据库连接等。
因此在为消费者分配新分区或移除分区时,可以通过消费者 API 执行一些代码:在调用 subscribe() 方法时传入一个 ConsumerRebalanceListener 实例。
ConsumerRebalanceListener 有两个需要实现的方法:
1.public void onPartitionsRevoked ( Collection<TopicPartition> partitions ) 方法会在消费者停止读取消息之后和再均衡开始之前被调用。如果在这里提交偏移量,下一个接管分区的消费者就会知道从哪里开始读取消息。
2.public void onPartionsAssigned ( Collection<TopicPartition> partitions ) 方法会在重新分配分区之后和消费者开始读取消息之前被调用。
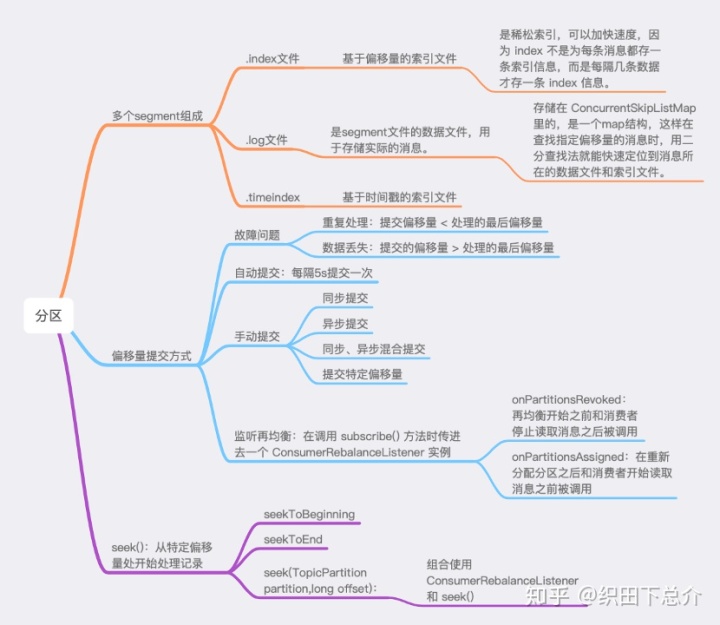
【从特定偏移量处开始处理记录】
1. 从分区起始位置开始读取消息:
seekToBeginning(Collection<TopicPartition> tp)
2. 从分区末尾位置开始读取消息:
seekToEnd(Collection<TopicPartition> tp)
3. public void seek(TopicPartition partition,long offset):
从指定分区的指定位置开始读取消息。
4. seek()方法只能重置消费者在分配到的分区上的消费位置,而分区的分配是在poll()方法的调用过程中实现的。也就是说在执行seek()方法之前需要先执行一次poll()方法等到分配到分区之后才可以重置消费位。
5. 避免数据丢失与数据重复,我们可以把记录和偏移量都保存到数据库中,他们要么都成功提交,要么都没有。seek() 方法可以查找保存在数据库里的偏移量。因此,组合使用 ConsumerRebalanceListener 和seek() 可以从数据库里保存的偏移量所指定的位置开始处理消息。
笔记内容主要参考自:
kafka权威指南及
Kafka 事务之偏移量的提交对数据的影响mp.weixin.qq.com
本笔记内容综合整理自多方资料、书籍、官网及源码,争取以最简约完整方式呈现知识方便记忆,只用于非盈利内容分享,如有侵权,请联系删除。
最后
以上就是激动饼干最近收集整理的关于kafka权威指南_Kafka-分区、片段、偏移量的全部内容,更多相关kafka权威指南_Kafka-分区、片段、偏移量内容请搜索靠谱客的其他文章。








发表评论 取消回复