好久没有更新了,这一次遇到一个单例模式造成的死锁,比较有代表性,这里做一个总结,分享给大家
起初,我们发现程序偶现死锁的问题,
按照解决deadlock的一般思路
是找到问题发生时,访问同一资源或者数据结构的可疑线程
OC和C有很多的基础类型都是线程不安全的,比如NSDictionary、array等,
结果一无所获????
看来问题没有这么简单????
那就找,问题发生时,访问同一个方法的可疑线程
经过几次的信息获取,合并同类项,终于发现了这几个死锁的共同特性(),
即总会同时出现以下两个堆栈:
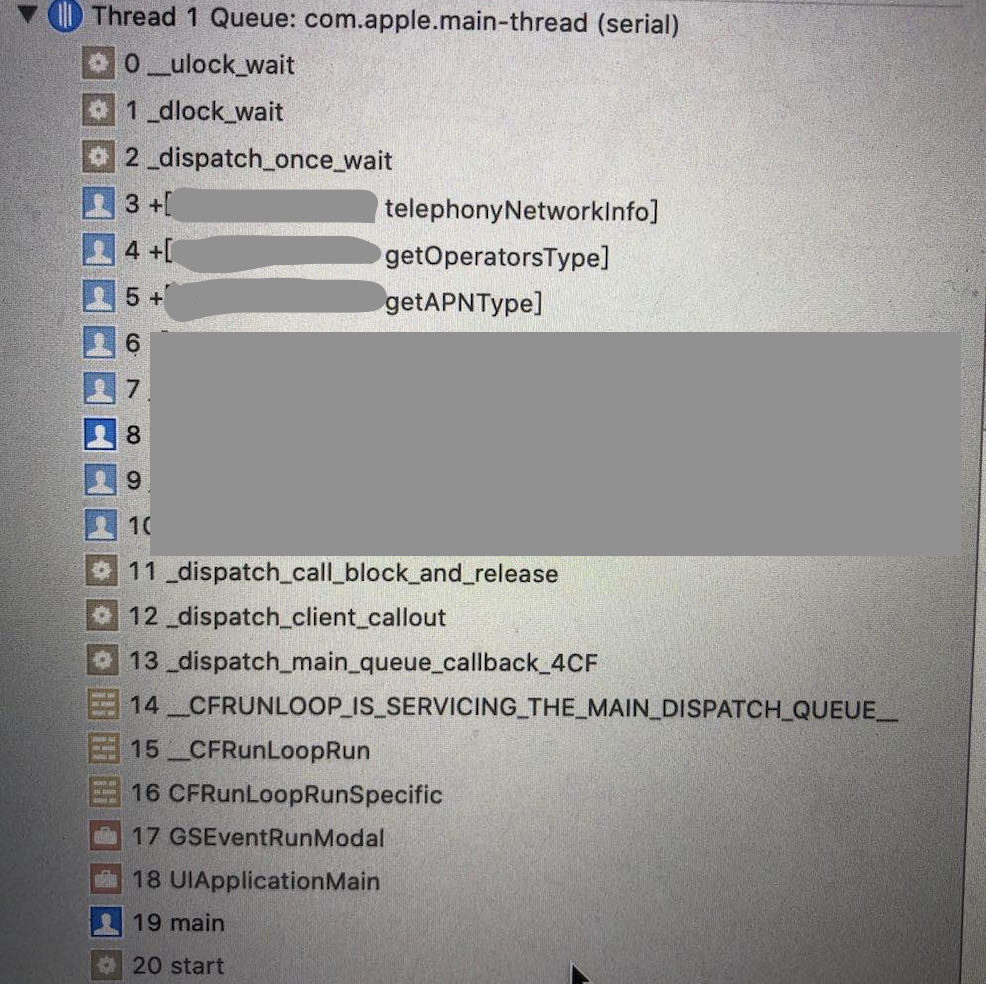
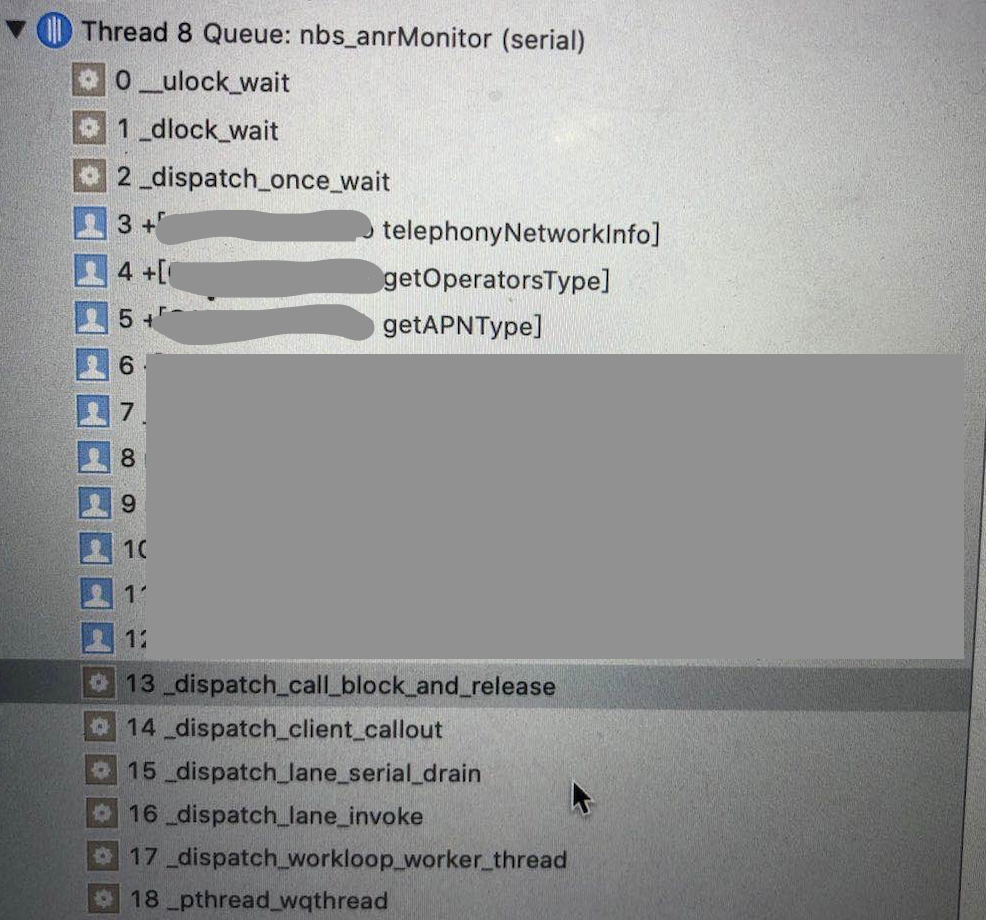
通过上图,我们可以看出,两个线程都对telephonyNetworkInfo进行了访问,一个是主线程,一个是子线程,会不会这里出现了问题,查看telephonyNetworkInfo问题

这段代码很简单,世界上的单例基本上都是这么写的????
那这里会不会有问题呢
这里有一个关键的信号量,dispatch_once,会对后面的任务进行堵塞
Apple对于dispatch_once的源码地址
简化实现的原理是:
1、dispatch_once不止是简单的执行一次,如果再次调用会进入非首次更改的模块,如果有未DONE的请求会被添加到链表中
2、所以dispatch_once本质上可以接受多次请求,会对此维护一个请求链表
3、如果在block执行期间,多次进入调用同类的dispatch_once函数(即单例函数),会导致整体链表增长。
看完这三点,找其中可能引起死锁的地方,大家可以先思考一下
????
????
????
首先想到:如果里面的方法再次调用dispatch_once是否会造成永久性死锁?
答案是肯定的,https://www.jianshu.com/p/58f5fb01ae4f这篇文章的例子就形象的说明了这个问题
但这并不是这次问题的原因,因为这个问题并没有循环调用
然后想到:后面进来的线程会被堵塞在这里,如果先进入的线程与后面堵塞的线程有一些交互,那会不会也造成永久性死锁?
答案也是肯定的,而且在实际业务中,绝大部分是这样的死锁。
https://www.jianshu.com/p/8b8abae1b32f这篇文章讲的就是一个典型的案例
再次回到这个问题,一个是主线程,一个是子线程,都是进行CTTelephonyNetworkInfo的初始化,如果子线程先进来,主线程在堵塞,那CTTelephonyNetworkInfo初始化时会不会与主线程交互呢?
经过相关资料的查找发现CTTelephonyNetworkInfo的初始化比较复杂
比如下面的堆栈:
0 __psynch_cvwait + 8
1 _pthread_cond_wait + 640
2 -[__NSOperationInternal _waitUntilFinished:] + 132
3 -[__NSObserver _doit:] + 232
4 __CFNOTIFICATIONCENTER_IS_CALLING_OUT_TO_AN_OBSERVER__ + 20
5 _CFXRegistrationPost + 400
6 ___CFXNotificationPost_block_invoke + 60
7 -[_CFXNotificationRegistrar find:object:observer:enumerator:] + 1504
8 _CFXNotificationPost + 376
9 -[NSNotificationCenter postNotificationName:object:userInfo:] + 68
10 -[CTTelephonyNetworkInfo queryDataMode] + 408
11 -[CTTelephonyNetworkInfo init] + 336
12 -[OTPolicyCenter init] (NWPolicyCenter.m:52)
13 __31+[NWPolicyCenter sharedInstance]_block_invoke (NWPolicyCenter.m:43)
14 _dispatch_client_callout + 16
15 dispatch_once_f + 56
16 +[OTPolicyCenter sharedInstance] (once.h:68)
17 +[OTUtils singletonObject:getter:] (OTUtils.m:271)
...
我们可以看到CTTelephonyNetworkInfo init时向主线程发出了操作: [__NSOperationInternal _waitUntilFinished:] 。如果主线程在阻塞中等待 onceToken ,所以主线程不能接收子线程的通知,于是子线程一直在等主线程接受通知,也不会去释放 onceToken ,死锁生成。
至于为什么 [NSNotificationCenter postNotificationName:object:userInfo:] 会同步等待主线程返回,猜测苹果自己在实现中接收通知是这样做的,要求接收通知的block在mainQueue上执行,比如:
[[NSNotificationCenter defaultCenter]
addObserverForName:NotificationName
object:nil
queue:[NSOperationQueue mainQueue]
usingBlock:^(NSNotification *ns) {
NSLog(@"Notification %@", ns);
}];问题找到了,解决方案也比较简单,无非两种,一种是不允许子线程访问CTTelephonyNetworkInfo方法,一种是不使用单例的方式,改成静态变量,这就涉及具体业务,我们选择了后者,一方面是因为业务上的限制,需要子线程调用,另外,该方法是一个基础服务方法,调用的地方比较多,走查代码工作量大,且有稳定性的隐患;另一方面从性能消耗的角度上讲,将单例模式改为静态变量,对于实时服务的代码来讲,性能消耗差不多。
问题解决!
参考资料:
https://blog.csdn.net/fishmai/article/details/72723677 dispatch_once造成的死锁----分析、解决与自动检测
https://www.jianshu.com/p/8b8abae1b32f 30行代码演示dispatch_once死锁
https://www.jianshu.com/p/58f5fb01ae4f 单例滥用 - dispatch_once死锁造成crash
拓展知识:
是否能在研发流程内避免这里问题或者提前发现这类的问题,笔者先抛砖引玉
关于发现问题
1.在线程申请加锁和解锁once token时,对线程打标记:
自己的代码中可以用宏定义改掉dispatch_once的实现,在其中对线程打标记,这个应该不难。
别人的代码中只能在运行时里面换出sharedInstance, defaultManager等方法来打标记。
2.找出子线程准备锁主线程的位置:
仅可以 hook objective-c 实现的同步方法,不能 hook GCD 的同步方法,所以仍要靠人肉review,而且只能review自己代码,不能review SDK。
3.制订子线程锁主线程强制CR和文档登记制度,从项目规则上避免问题的发生
最后
以上就是长情可乐最近收集整理的关于单例dispatch_once造成的死锁按照解决deadlock的一般思路的全部内容,更多相关单例dispatch_once造成内容请搜索靠谱客的其他文章。








发表评论 取消回复