田海立@CSDN 2020-11-07
PyTorch 1.3中发布Pytorch Mobile,其支持情况如何,能否与TensorFlow Lite一较高下呢?本文试分析之。PyTorch Mobile的宣传显得要么诚意不足要么对行业领悟不够。目前只能说是有Mobile这个路在而已,与TFLite比不可同日而语,至少目前的实现是。相对于Google移动端的即有Android生态布局,Facebook有其苦衷,要坚守其生态底线又要放弃次要考量去适配NNAPI才是其捷径。
一、历史
Facebook历史上,在Caffe2中号称设计之初就为移动部署考虑的,笔者也跟踪了几年,发现Caffe2对NNAPI的支持就是3年前提交过代码,也只是对几个最常用算子做了适配,几乎是无所作为,当然显然Caffe2目前也基本是被废弃的状态。现在PyTorch实现Mobile支持,特别是PyTorch作为训练(模型)框架,已占主导地位,当然也应关注其在移动领域的表现。
关注AI移动领域的读者应该有所了解,其实TensorFlow最初对移动的支持是通过TensotFlow Mobile,之后才是重新实现了TensorFlow Lite,而TensorFlow Mobile也终究是被放弃的。
二、PyTorch Mobile
据PyTorch Mobile网站介绍,处在Beta阶段,待API稳定之后,很快会推出稳定版。Feature包括:
- 为ios,Android,Linux提供支持;
- 提供API,涵盖将 ML 集成到移动应用中所需的常见预处理和集成任务;
- 通过TorchScript IR支持tracing与scripting;
- 支持 XNNPACK为ARM CPU上执行浮点运算;
- 集成QNNPACK 支持INT8量化内核库,可支持per-channel量化、动态量化以及其他方式;
- 根据用户的应用需求进行构建级别的优化和选择性编译,也就是根据应用如用的模型里的算子可定制选择算子从而改变最终编译出目标程序的尺寸;
- GPU/DSP/NPU等backends会在后续支持。
典型工作流程:
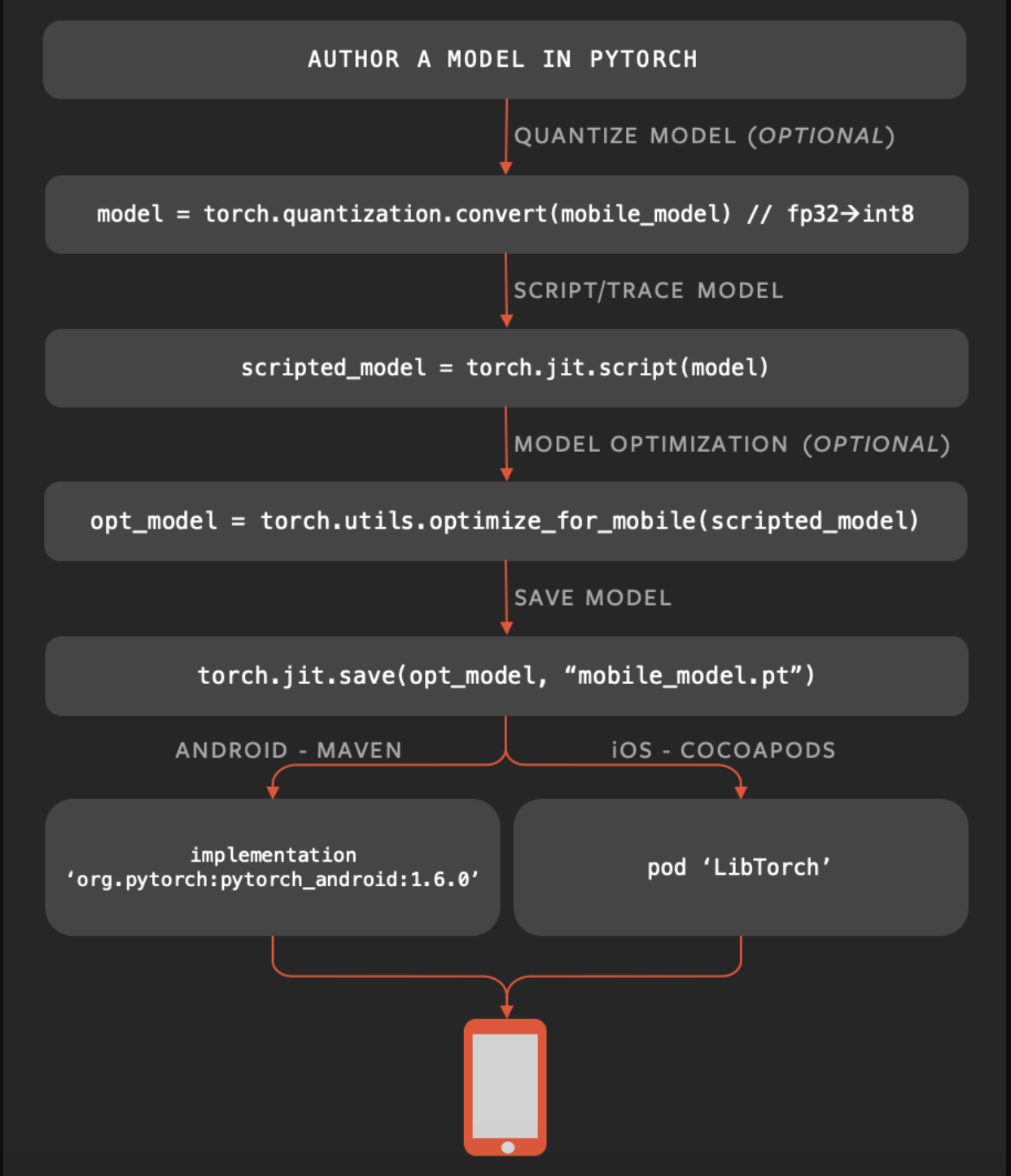
与别的推理框架其实并没大的差别:
- 把训练出的模型进行量化(可选)
- 模型转换:pt(TorchScript)
- 优化(可选)
- 保存
- 部署到终端上执行
只是,上述1~4步骤中在Host上完成;步骤5在手机或别的端侧设备上部署。别的方案把这些都明白的交代清楚了而已。
三、PyTorch Mobile前景分析
PyTorch Mobile目前发布的信息可以说是没什么特别的新意,本来就在移动端落后了TensorFlow Lite很多,第一次发布这种情况也可以理解。
不过,有些说法就让人觉得要么真的跟产业离的太远,不知道端侧设备的痛点在哪,要么诚意不足!
看Facebook所宣传的PyTorch Mobile的“卖点”:
- No new framework
- No model conversion
- No operator porting
No new framework:都已经转换了模型了,在端侧设备上执行pt模型了还说是没有新的Framework,应该是有一个端侧Runtime的东西在运行,什么量级的才叫Framework呢?刻意隐藏不告诉普通开发者而已。
No model conversion:变成pt TorchScript模型了不是模型转换吗?而且将来有NPU/GPU/DSP支持没有模型转换或编译的存在才怪。也还是偷换概念。
No operator porting:这点还没有深入看实现,不好说做没做。不过知道TensorFlow Mobile到TensorFlow Lite发展变化历程的读者应该都知道,这可能不是卖点,而是还没get到痛点。之前TensorFlow Mobile是挑选了一些TF的算子做了个c++的推理,但是尺寸和运行速度都是端上设备最关注的,所以后来才全部重写算子,重新实现而成的TFLite,TensorFlow Mobile也被放弃了,后来者可能连TF Mobile的名字都没听说过。当然,可能PyTorch Mobile也是重写了的,只是不宣传,隐藏起来而号称的算子一样而已。
目前PyTorch Mobile只能说是有Mobile这个路在而已,与TFLite的现状不可同日而语,至少目前的现状是。
端侧设备更关注的是Latency、功耗、隐私等,所以对加速器的支持更重要:
- TFLite里对GPU通过Delegate机制(OpenCL/OpenGL ES)支持;
- TFLite对Qualcomm Hexagon提供Delegate机制支持;
- TFLite对通过NNAPI Delegate对所有NN Device(GPU/DSP/NPU)提供支持
当然对Arm CPU浮点计算今年7月也提供了XNNPACK delegate方式,加上之前Neon/dotproduct的INT计算支持等,基本上对CPU和加速器(NPU/GPU/DSP)的支持是完备的。
PyTorch Mobile到目前还没看到这部分的实现,公开场合也没看到具体计划。
四、总结
显然与Google不会加入ONNX一样,Facebook的PyTorch也不会提供模型转换或适配的方式转换到Google的TensorFlow生态。而是守住自己生态内的这条底线的情况下,尽量支持端侧设备。
Google手里有Android,并耕耘了这么多年,对移动设备的理解和生态布局不是Facebook所能比拟的。PyTorch Mobile如果把竞争对手瞄准TensorFlow Lite,不要针对AndroidNN(NNAPI),积极拥抱去适配NNAPI,倒是推动AI设备支持的捷径。AndroidNN诞生之初的定位本就是与上层ML Framework配合,不假定上层ML Framework一定是TFLite,这也刚好契合。
最后
以上就是忧郁小蘑菇最近收集整理的关于PyTorch Mobile在端侧可堪大用?能否与TensorFlow Lite一较高下一、历史二、PyTorch Mobile三、PyTorch Mobile前景分析四、总结的全部内容,更多相关PyTorch内容请搜索靠谱客的其他文章。








发表评论 取消回复