人比较懒,关于背景直接截图说明,以下是整个网络结构。
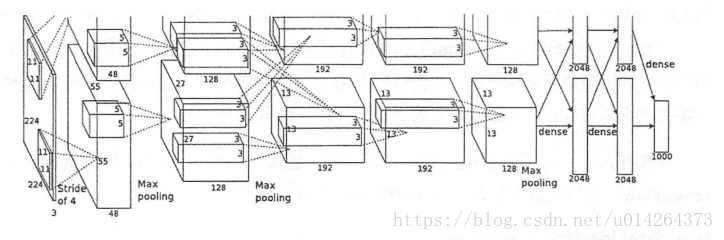
关于原始网络各层参数的设置,建议移步到以下作者去学习,比较详尽https://blog.csdn.net/zyqdragon/article/details/72353420
这篇主要是实现一个完整的AlexNet卷积神经网络,对其前向传播和反向传播进行速度测试。并没有加载原始数据进行训练。值得注意的是,这个代码在结构上和原始网络一样,但中间有很多细节是不一致的,比如卷积核的代大小步长等。但是它能很清楚的让你理解整个网络。不想看分解的可以先拉到文末复制所有代码运行一下,看看效果。什么都不用修改,直接运行哦。
----------------------------------------------------进入代码分解--------------------------------------
# 导入相应的系统库以及tensorflow
from datetime import datetime
import math
import time
import tensorflow as tf# 总共测试100组batch,每组32个
batch_size = 32
num_batches = 100# 定义一个用来显示每一卷积层或池化层的的名称以及输出尺寸
def print_activations(t):
print(t.op.name, '', t.get_shape().as_list())def inference(images):
'''
:param images: 输入图像尺寸32*224*244*3
:return: 最后一层pool5以及parameters
'''
parameters = []
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding = 'SAME')
# s = 4,"NHWC", the data is stored in the order of: [batch, height, width, channels]
biases = tf.Variable(tf.constant(0.0, shape = [64], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name = scope)
print_activations(conv1) # 输出conv1的名称和形状
parameters += [kernel, biases]
# 第一层卷积后使用局部响应归一化,提升泛化能力
# lrn1 = tf.nn.lrn(conv1, 4, bias = 1.0, alpha = 0.001 / 9, beta = 0.75, name = 'lrn1')
pool1 = tf.nn.max_pool(conv1, ksize = [1, 3, 3, 1], strides = [1, 2, 2, 1], padding = 'VALID', name = 'pool1')
print_activations(pool1)
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [192], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv2)
# lrn2 = tf.nn.lrn(conv2, 4, bias = 1.0, alpha = 0.001 / 9, beta = 0.75, name = 'lrn2')
pool2 = tf.nn.max_pool(conv2, ksize = [1, 3, 3, 1], strides = [1, 2, 2, 1], padding = 'VALID', name = 'pool2')
print_activations(pool2)
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [384], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv3)
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [256], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv4)
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [256], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv5)
pool5 = tf.nn.max_pool(conv5, ksize = [1, 3, 3, 1], strides = [1, 2, 2, 1], padding = 'VALID', name = 'pool5')
print_activations(pool5)
return pool5, parameters卷积过程结束,这里使用的LRN,其他文献已经放弃使用了,因为效果不明显,但这里使用后速度减低1/3,准确率的影响也不大。可使用可不使用。
接下来是时间测试函数。
def time_tensorflow_run(session, target, info_string):
'''
:param session: 创建的会话
:param target: 需要评测的运算算子
:param info_string: 测试的名称
:return:
'''
num_steps_burn_in = 10 # 让程序预热10轮,因为前几轮的运算有大量的显存加载时间,10轮以后再统计时间
total_duration = 0.0 # 统计总时间
total_duration_squared = 0.0 # 以及时间均方差
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches # 平均时间
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr) # 时间标准差
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %(datetime.now(), info_string, num_batches, mn, sd))主函数
# 主函数
def run_benchmark():
with tf.Graph().as_default(): # 定义默认图
# 这里不用imagenet,代替的是随机数进行训练
image_size = 224
images = tf.Variable(tf.random_normal([batch_size, image_size, image_size, 3], dtype = tf.float32, stddev = 1e-1))
pool5, parameters = inference(images)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 前向传播时间计算
time_tensorflow_run(sess, pool5, "Forward")
# 反向传播时间计算
objective = tf.nn.l2_loss(pool5)
grad = tf.gradients(objective, parameters)
time_tensorflow_run(sess, grad, "Forward-backward")如果要运行就一句话就行了
run_benchmark()需要注意的是,这个代码LRN被我注释掉了,如果想试试LRN的结果,在第一个卷积和第二个卷积处修改一下就好了。
我没用GPU,在CPU上的时间比黄文坚老师用GPU慢了很多,他是用了LRN前向0.26秒,我的对应是0.468秒。
结果应有三部分组成;
conv1 [32, 56, 56, 64] conv1/pool1 [32, 27, 27, 64] conv2 [32, 27, 27, 192] conv2/pool2 [32, 13, 13, 192] conv3 [32, 13, 13, 384] conv4 [32, 13, 13, 256] conv5 [32, 13, 13, 256] conv5/pool5 [32, 6, 6, 256] 2018-04-24 15:27:52.440312: step 0, duration = 0.467 2018-04-24 15:27:57.211732: step 10, duration = 0.516 2018-04-24 15:28:02.045221: step 20, duration = 0.467 2018-04-24 15:28:06.703669: step 30, duration = 0.464 2018-04-24 15:28:11.335167: step 40, duration = 0.461 2018-04-24 15:28:15.966167: step 50, duration = 0.465 2018-04-24 15:28:20.588067: step 60, duration = 0.464 2018-04-24 15:28:25.376623: step 70, duration = 0.462 2018-04-24 15:28:29.995012: step 80, duration = 0.459 2018-04-24 15:28:34.616423: step 90, duration = 0.461 2018-04-24 15:28:38.799483: Forward across 100 steps, 0.468 +/- 0.018 sec / batch 2018-04-24 15:29:09.741985: step 0, duration = 2.689 2018-04-24 15:29:37.293994: step 10, duration = 2.749 2018-04-24 15:30:04.358533: step 20, duration = 2.696 2018-04-24 15:30:31.860958: step 30, duration = 2.783 2018-04-24 15:30:58.855577: step 40, duration = 2.688 2018-04-24 15:31:25.696813: step 50, duration = 2.689 2018-04-24 15:31:52.615997: step 60, duration = 2.688 2018-04-24 15:32:20.105809: step 70, duration = 2.699 2018-04-24 15:32:47.139107: step 80, duration = 2.704 2018-04-24 15:33:14.350406: step 90, duration = 2.981 2018-04-24 15:33:39.250186: Forward-backward across 100 steps, 2.722 +/- 0.066 sec / batch
最后是所有代码:
# 这部分代码主要是建立一个完整的AlexNet卷积神经网络,对其前向传播和反向传播进行速度测试。并没有加载原始数据进行训练。
# 导入相应的系统库以及tensorflow
from datetime import datetime
import math
import time
import tensorflow as tf
# 总共测试100组batch,每组32个
batch_size = 32
num_batches = 100
# 定义一个用来显示每一卷积层或池化层的的名称以及输出尺寸
def print_activations(t):
print(t.op.name, '', t.get_shape().as_list())
def inference(images):
'''
:param images: 输入图像尺寸32*224*244*3
:return: 最后一层pool5以及parameters
'''
parameters = []
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding = 'SAME')
# s = 4,"NHWC", the data is stored in the order of: [batch, height, width, channels]
biases = tf.Variable(tf.constant(0.0, shape = [64], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name = scope)
print_activations(conv1) # 输出conv1的名称和形状
parameters += [kernel, biases]
# 第一层卷积后使用局部响应归一化,提升泛化能力
# lrn1 = tf.nn.lrn(conv1, 4, bias = 1.0, alpha = 0.001 / 9, beta = 0.75, name = 'lrn1')
pool1 = tf.nn.max_pool(conv1, ksize = [1, 3, 3, 1], strides = [1, 2, 2, 1], padding = 'VALID', name = 'pool1')
print_activations(pool1)
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [192], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv2)
# lrn2 = tf.nn.lrn(conv2, 4, bias = 1.0, alpha = 0.001 / 9, beta = 0.75, name = 'lrn2')
pool2 = tf.nn.max_pool(conv2, ksize = [1, 3, 3, 1], strides = [1, 2, 2, 1], padding = 'VALID', name = 'pool2')
print_activations(pool2)
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [384], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv3)
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [256], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv4)
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype = tf.float32, stddev = 1e-1), name = 'weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding = 'SAME')
biases = tf.Variable(tf.constant(0.0, shape = [256], dtype = tf.float32), trainable = True, name = 'biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name = scope)
parameters += [kernel, biases]
print_activations(conv5)
pool5 = tf.nn.max_pool(conv5, ksize = [1, 3, 3, 1], strides = [1, 2, 2, 1], padding = 'VALID', name = 'pool5')
print_activations(pool5)
return pool5, parameters
# 卷积过程结束,这里使用的LRN,其他文献已经放弃使用了,因为效果不明显,但这里使用后速度减低1/3,准确率的影响也不大。可使用可不使用,
def time_tensorflow_run(session, target, info_string):
'''
:param session: 创建的会话
:param target: 需要评测的运算算子
:param info_string: 测试的名称
:return:
'''
num_steps_burn_in = 10 # 让程序预热10轮,因为前几轮的运算有大量的显存加载时间,10轮以后再统计时间
total_duration = 0.0 # 统计总时间
total_duration_squared = 0.0 # 以及时间均方差
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches # 平均时间
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr) # 时间标准差
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %(datetime.now(), info_string, num_batches, mn, sd))
# 主函数
def run_benchmark():
with tf.Graph().as_default(): # 定义默认图
# 这里不用imagenet,代替的是随机数进行训练
image_size = 224
images = tf.Variable(tf.random_normal([batch_size, image_size, image_size, 3], dtype = tf.float32, stddev = 1e-1))
pool5, parameters = inference(images)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 前向传播时间计算
time_tensorflow_run(sess, pool5, "Forward")
# 反向传播时间计算
objective = tf.nn.l2_loss(pool5)
grad = tf.gradients(objective, parameters)
time_tensorflow_run(sess, grad, "Forward-backward")
run_benchmark()最后
以上就是英俊灰狼最近收集整理的关于tensorflow实现AlexNet-黄文坚版本的全部内容,更多相关tensorflow实现AlexNet-黄文坚版本内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复