
参考:https://www.cnblogs.com/zhenyuyaodidiao/p/4635458.html http://shift-alt-ctrl.iteye.com/blog/2266908
MySQLReplication实现原理

MySQL的复制(replication)是一个异步的复制,从一个MySQLinstace(称之为Master)复制到另一个MySQLinstance(称之Slave)。整个复制操作主要由三个进程完成的,其中两个进程在Slave(Sql进程和IO进程),另外一个进程在Master(IO进程)上。
要实施复制,首先必须打开Master端的binarylog(bin-log)功能,否则无法实现。因为整个复制过程实际上就是Slave从Master端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。复制的基本过程如下:
(1)Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
(2)Master接收到来自Slave的IO进程的请求后,通过负责复制的IO进程根据请求信息读取指定日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;
(3)Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log的某个位置开始往后的日志内容,请发给我”;
(4)Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
复制实现级别 MySQL的复制有三种模式:Statement Level、Row Level、Mixed Level。复制级别的不同,会导致Master端二进制日志文件的生成形式的不同。
1 Statement Level复制
该模式是最早的复制模式,主要的流程是Master端将每一条会修改数据的Query记录下来,Slave端在复制的时候会根据二进制文件重新执行相同的Query。这种模式的优点是Master端不需要记录每一行数据的变化,二进制日志文件量小,IO成本低,速度快。
相应的,该模式存在的缺点如下:由于记录的是执行语句,就需要额外的知道每条语句执行的上下文信息,以保证该相同的操作在Slave端执行时能够得到和Master同样的结果。但由于MySQL功能的不断增多,这种复制模式需要考虑的情况也就越来越多,出现bug的几率也就也大。从MySQL 5.0开始,MySQL复制解决了大量的之前版本中出现的无法复制或复制错误的问题,但随着MySQL的发展,这种挑战将会日趋严峻。
2 Row Level复制
MySQL开发人员意识到Statement Level存在的问题,于5.1.5开始提供Row Level模式。该模式的主要流程是,MySQL二级制日志文件会将每一行数据修改都记录下来,然后在Slave端进行同样的修改。这种模式的优点是:日志文件不会将SQL语句执行的上下文记录下来,只是记录哪一条数据修改了,修改成什么样子了;这样做可以避免如某些特定情况下存储过程、trigger的调用和触发没有被正确执行等复制问题。
同样,该模式也存在缺点:日质量的成倍增加。例如:执行alter table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。这样就大增加了复制过程的IO成本,导致速度下降、性能下降。
3 Mixed Level复制
MySQL从5.1.8开始,提供Mixed Level。该模式结合了之前两种模式的优点,规避了二者的缺点。在该模式下,MySQL会根据执行的每一条语句来区分记录日志文件的格式。举例说明,当涉及到复杂的存储过程时,采用Row Level,规避Statement Level存在的某些场景无法复制的问题;当涉及到Alter table等操作时,采用Statement Level来规避Row Level带来的日志量巨大的问题。
一,ms主从 (m 103 s 109)
1,slave是通过mysql 连接登陆到master上来读取二进制日志的,因此需要在master上给slave配置权限 GRANT REPLICATION SLAVE ON *.* to 'mysync'@'slaveip' identified by '123456'; flash privileges;在slave上登陆master测试:mysql -hmasterip -uxx -pxx
2, 在mster上打开二进制日志,并标示server-id,用于标示主机
vi /etc/my.cnf
[mysqld]
log-bin
binlog-format=row 增加事务性,
sync-binlog=1
server-id=1
service mysql restart
3,在slave初始同步,因为bin-log同步会比较慢

innodbackup在备份的时候会产生一个log文件,会纪录master执行的position号,在之后开启slave同步功能就可以从这个position号开始同步
4 service mysql stop 覆盖数据目录
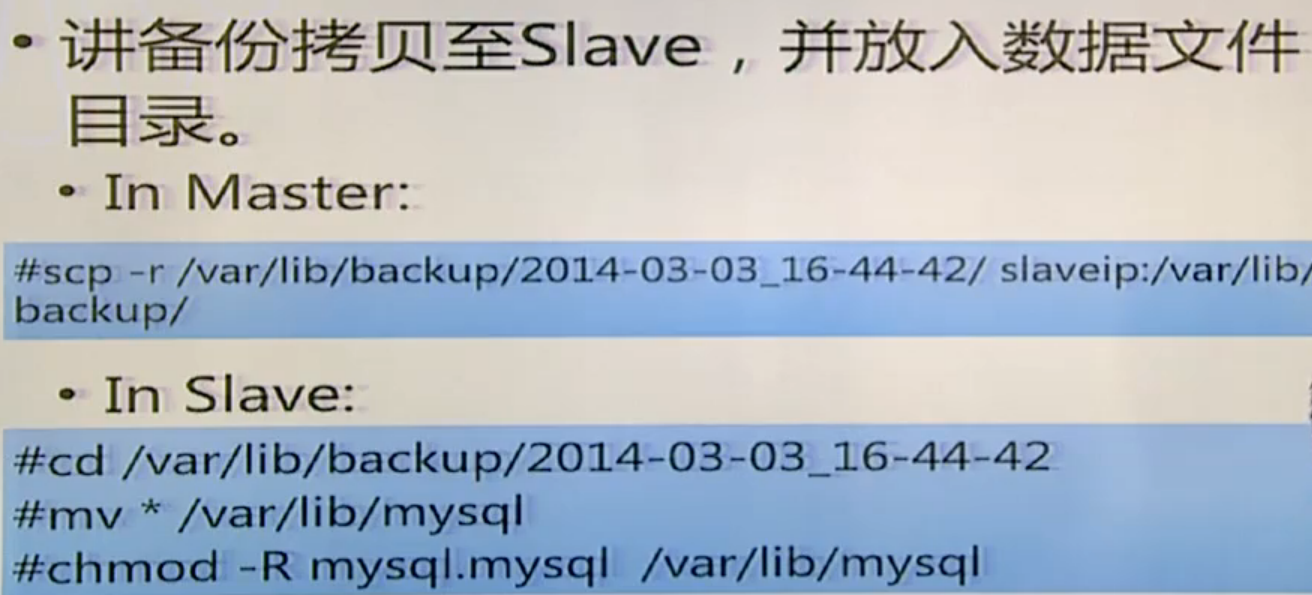
service mysql start
5, 在slave 上配置server-id =2 service mysql restart
6,

7告诉slave master在那里,log文件
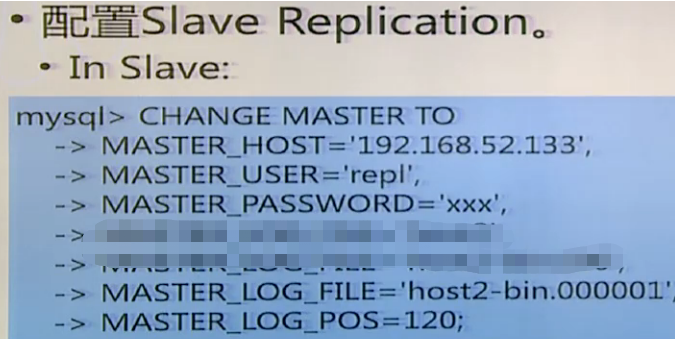
8

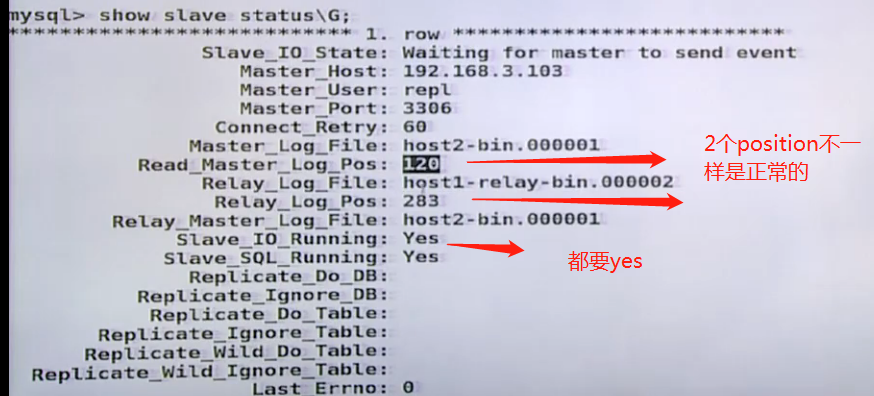
查看状态slave 一个是中继log的position和bin log的不一定是相同的 ,两个yes是io 和sql线程
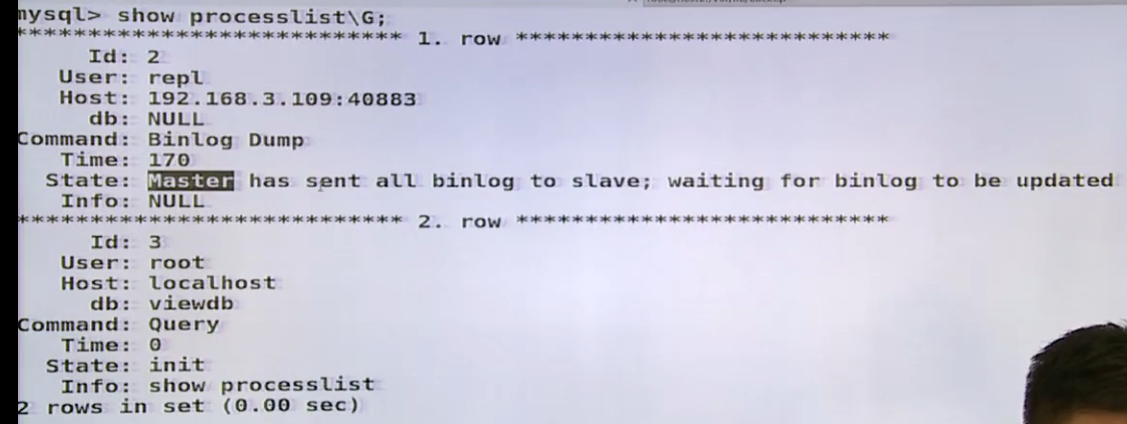
在master上看,slave也可以
二,
*** m-s-s 使用一台slave作中继,分担master的压力,中继需要开启二进制log,并配置 log-slave-updates,参数的作用是将master同步到中继上后作操作后生成bin-log,后面的slave同步这个bin-log,可以将中继服务器设置(blackhoou ) 黑洞存储引擎只纪录log而不操作dml语句,
*** m-m 不好,增加负载
*** m multi-slave master负载大
*** m-m-m 不建议使用、
*** s- muti-master 官方不建议
M-S-S 搭建 host2 是master (103) host1 (109) host3 是slave(3.64)
1,在中继slave上开启bin-log 然后重启
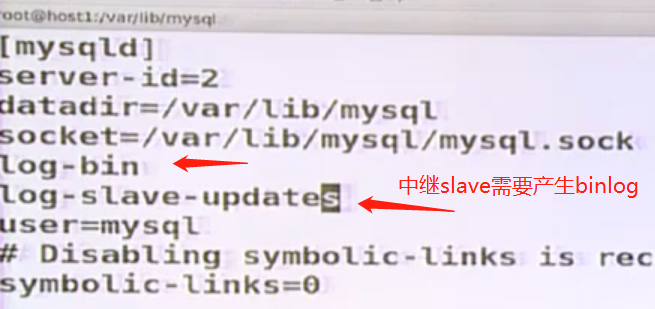
2,到host3 第三台机器slave 上设置server-id=3
并且也需要有和中继slave2上的初始同步数据,然后重启
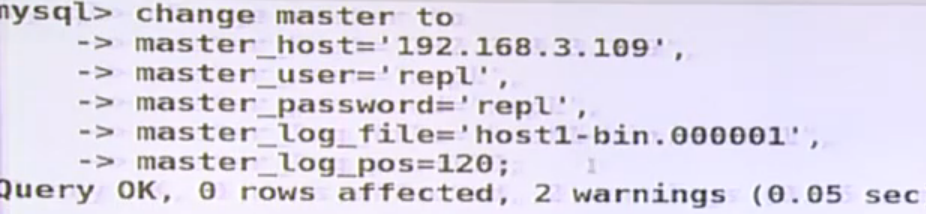
在109(slave2)上授权给64 (slave3)
grant replecation slve on *.* on repl@64 identified by 'aaa'; flush privileges;
在64(slave3)上 start slave; show slave status;
3,测试,在master上insert 1
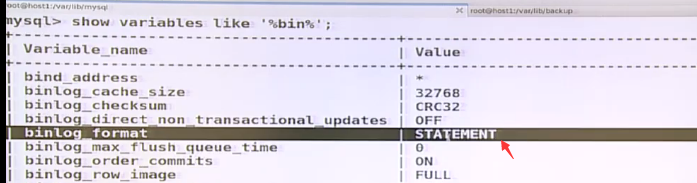
master上是row格式要转换程statement,不能实现,所以更改成row格式
发现不能在中继slave上过来,showslave status; show variables like '%bin%';看到中继slave的日志格式不是row格式的(statment), set binlog_format=ROW; set gloabe_format=ROW;
在配置文件上写日志格式 binlog-format=row
执行命令stop slave start slave 问题解决
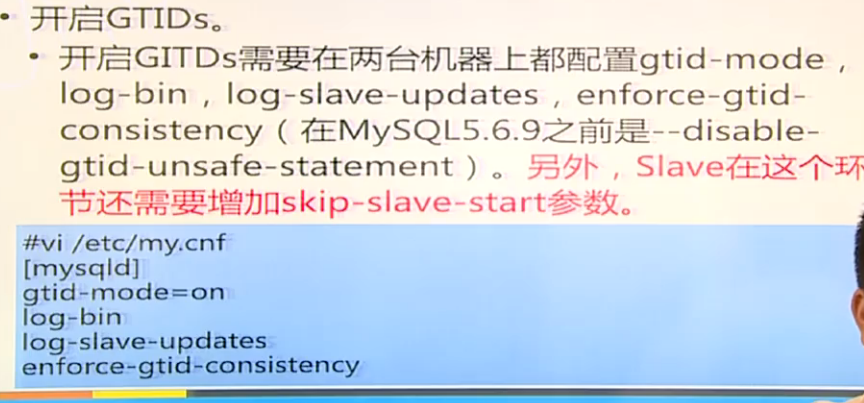
三,基于GTIDs的replications

***使用GTID的一些限制
1) 不支持myisam,这可能导致多个gtid分配给同一个事物。
2)create table 。。。select语句不支持
3)create/drop temporary table 语句不支持
4)必须使用enforce-gtid-consistency参数
5)sql-slave-skip-counter不支持,因为它是对position号
6)mysql5.6.9之后使用mysqldump备份,不能使用gtids
7)在mysql 5.6.7之前,不能使用mysql_upgrade命令。
使用gtid最大的好处是可以随意切换指定slave为master而不需要考虑position号问题(master down机了,master有些数据没有同步完,切换到slave上,需要人工找到position号对应没有同步过来的数据),mysql内部会记录同步到next position 。不像传统的ab 复制需要找到对应的position号。
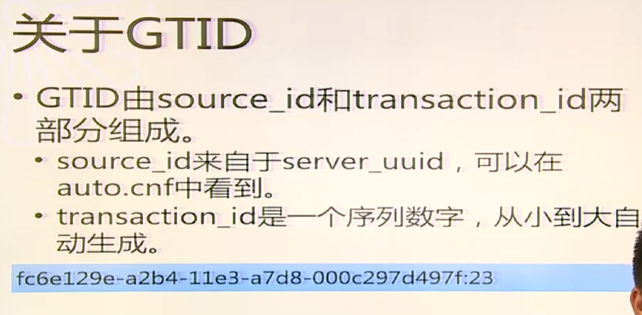
GITDs(global trasaction identifiers),使用GITDs,无论在master上提交事务还是在slave上应用,每一个事物都可以被识别并跟踪。添加新的slave或者发生故障需要将MASTER身份迁移到SLAVE上时,都不需要考虑哪一个二进制日志以及哪一个position。这极大地简化了操作。完全基于事务,所以不支持MYISAM存储引擎

在已有的mysql replication上升及 (把slave3改成基于host2(master)的slave)
2,改变slave3的身份
在host2(master)上给slave3授权

在host3(slave3)上 先stop slave在change master 在start slave
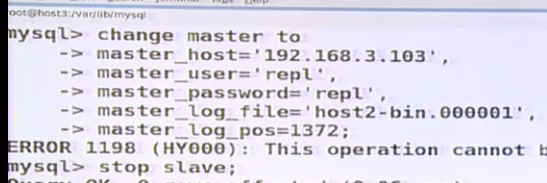

所有机器service mysql stop
3
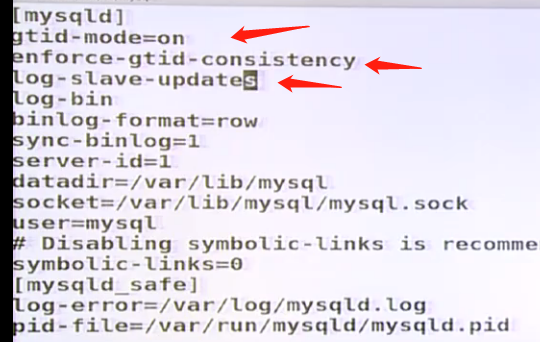
1)在master上操作
2)在slave1上操作 slave3上
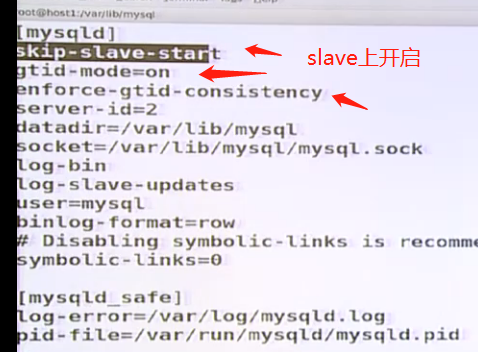
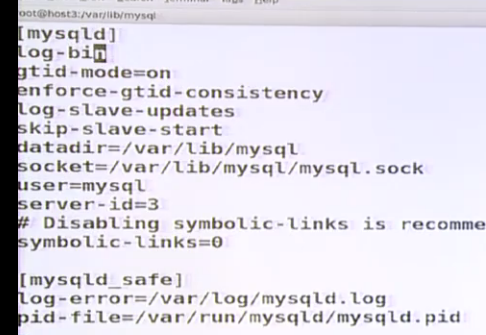
skip-slave-start参数是mysql启动后先不开启复制功能,不要这个参数
4

在host1 host3上操作并测试(insert)没问题
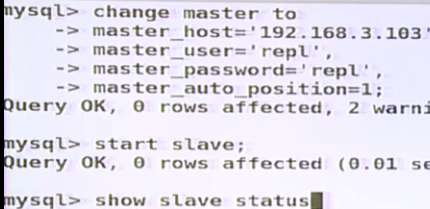
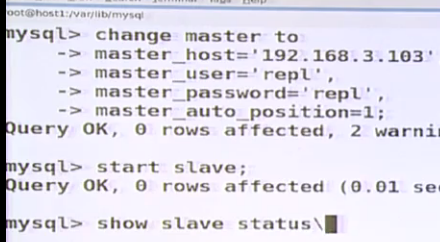
5,如果要改变host3(slave3)的master为host1(slave1),只需要一条命令,至于sql执行到那里全部由GTID功能自动完成(不需要像前面的手动指定position文件,和position号)
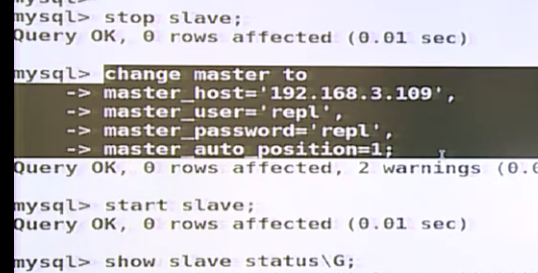
***延迟的问题







skip_counter基于position号,不支持gtid


四,提升replication 的性能
replication监控及故障切换,当master发生故障,slave接管成为master
1)从dev.mysql.com/dowloads 下载mysql监控软件(mysql utilities)(connects/python)

2)配置m-s-s环境(上面的环境就好),
3)监控机需要权限


后面两个参数是数据库角色等信息保存到文件中,重启数据库可以定位角色(slave3还是slave3),两个表需要修改为innodb引擎,否则会出错(5.6以后是innodb)
4)启动监控

5)测试,可以看到mster挂了,监控会自动选一台slave为master其他slave就同步新的master
当把之前挂的master重新启动后,需要手动设置为slave向新的master上同步数据,由于是基于gtids,所以会自动同步中间故障数据。
**下面是读写分离
最后
以上就是紧张月光最近收集整理的关于mysql replication 监控_mysql replication详解的全部内容,更多相关mysql内容请搜索靠谱客的其他文章。








发表评论 取消回复