很多DBA配置“主从复制是否异常”的监控是依赖SHOW SLAVE STATUS
的输出,看如下两个值是否为Yes,若其中一个不为Yes,会认为复制状态异常。Slave_IO_Running: Yes
Slave_SQL_Running: Yes
但在一些场景下,可能会造成ro节点不知自己已经和主库失联了。现象和影响就是,复制状态正常,但从库的数据已经不对了。如一些容灾场景时,新的主库已经接管业务,并产生了新的binlog events
,但从库查不到也没有报错。
这种失联导致的复制假死场景,可能有很多,但可以围绕以下点来排查:主库自己挂了,没来得及通知从库。
主库Binlog Dump
线程不干活(比如挂了因为种种原因没拉起)。
Binlog Dump
想干活但是突然没网了,没法通知从库。
……
如果想模拟也比较简单,建立一个最简单的主从关系。给主库来个偷袭,不要讲武德,在主库OS上来一发:ifconfig eth0 down
此时在主库上写数据,从库会看起来一切正常。(如果配置了半同步,第一次写数据时,默认会等待10秒。rpl_semi_sync_master_timeout=10000
)。
这种情况在生产环境也是存在的,如网络环境极差。(需要考虑如何监控覆盖这种场景)。
直接原因很好理解,如上所说,从库节点的IO_Thread
不知道原主库已经挂了,还在憨等主库的Binlog Dump
线程的新推送。
相关配置:
对于这种情况,MySQL提供了几个超时参数可供配置:slave_net_timeout:
可接受的Binlog Dump
线程的无响应时间(秒)。超过这个时间,从库认为主库连接已经丢失连接,并尝试重新建立连接。默认3600秒。可以写在配置文件,其实它是一个全局参数。
master_connect_retry:
IO_Thraed
尝试重新建立连接失败后,再次尝试所间隔的时间(秒)。默认60秒。通过CHANGE MASTER
指定,存于master info
中。
master_retry_count:
最大尝试的次数。超过这个值后就不尝试重连了,并将Slave_IO_Running
设置为No,默认为86400次。通过CHANGE MASTER
指定,存于master info
中。
三个参数揉在一起就是:
超过slave_net_timeout
秒,如果没有新的binlog events
发送过来,从库认为已经和主库断开了连接,这时IO_Thread
尝试重新建立连接。
重连等待的时间取决于master_connect_retry
。
并且尝试次数不超过master_retry_count
。(如果明显知道连接已经断开,则该参数不生效。)
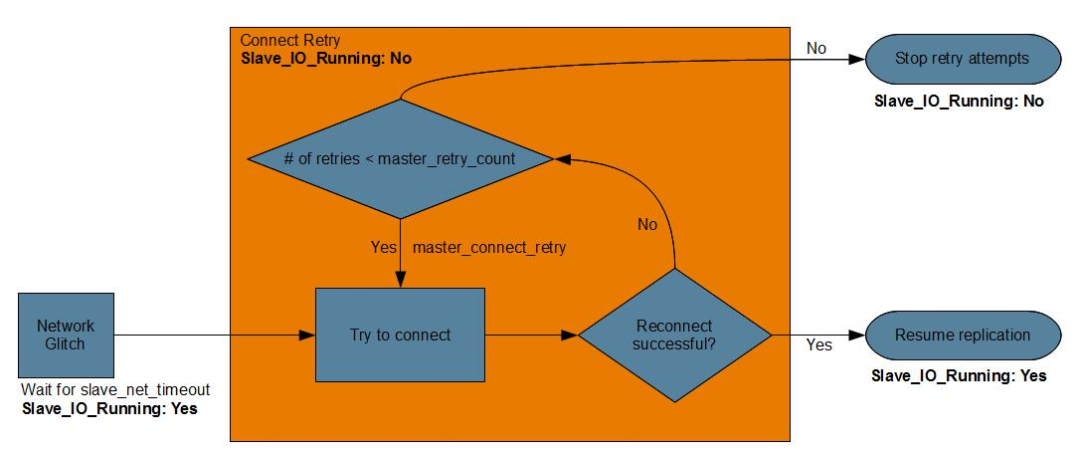
图源哪里我忘记了,可能是什么percona的博客,这个学习笔记其实是几年前写的。。最近才整理。
所以上面复制假死的问题,其实将@@slave_net_timeout
设置为一个较小的值就可以了,比如可以是60,可以是30,可以是10。这样从库可以很快发现自己或主库已经掉线了,即便是无法重连到正确的主库上,也可以很快将故障告出来,而不是表面上双Yes
。(修改好了记得重启IO线程)
该值默认是1个小时,所以也有一些从库监控上会看到延迟突增到1个小时,又缓慢降下来的情况。
那如果主库真的没有新增的binlog events
可以推送,从库等待@@slave_net_timeout
就要去尝试重连,岂不是有点僵?

还有个叫master_heartbeat_period
的家伙可供配置,该值也存于master info
中,默认是@@slave_net_timeout
的一半。作用和名字一样,主库向从库发送心跳包的间隔时间,这样从库就知道自己的主库不是挂了,或者只是没有新的binlog events
产生。
另,上面提到的master info
其实是指mysql.slave_master_info
(当master_info_repository=TABLE
时)
相关的监控:
5.55.6 可以通过SHOW GLOBAL STATUS LIKE '%heart%';
来查看相关状态:mysql> SHOW GLOBAL STATUS LIKE '%heart%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| Slave_heartbeat_period | 0.000 |
-- 表示心跳间隔时间的配置信息
| Slave_last_heartbeat | |
-- 5.6新增,表示最后一次收到心跳的时间
| Slave_received_heartbeats | 0 |
-- 表示总共收到的心跳次数
+---------------------------+-------+
3 rows in set (0.00 sec)
5.7+ 可以通过performance_schema.replication_connection_status
来检查这几个状态。mysql> SELECT * FROM performance_schema.replication_connection_statusG
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID:
THREAD_ID: NULL
SERVICE_STATE: CONNECTING
COUNT_RECEIVED_HEARTBEATS: 0
LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET:
LAST_ERROR_NUMBER: 2003
LAST_ERROR_MESSAGE: error connecting to master '1@1:3306'
- retry-time: 60 retries: 1
LAST_ERROR_TIMESTAMP: 2020-11-11 17:00:46
1 row in set (0.00 sec)
-- 这里是我的实验环境,随便配置了一个从库。
p.s. 但双YES且Seconds_Behind_Master=0
不一定是上面这种假死,还有很多其他的情况也会造成Seconds_Behind_Master=0
,但实际上主从数据不一致,这个是另一篇文章要写的了。
最后
以上就是奋斗蜻蜓最近收集整理的关于mysql 复制 假死_MySQL#复制 双Yes的假死故障造成主从不一致的全部内容,更多相关mysql内容请搜索靠谱客的其他文章。








发表评论 取消回复