目录
第二届中国移动“梧桐杯”大数据应用创新大赛 - 数智乡村
大赛背景
赛题描述
数据概述
数据分析的总体思路
赛题leak分析
未点明的分析思路
结尾
第二届中国移动“梧桐杯”大数据应用创新大赛 - 数智城市
大赛背景
赛题描述
数据概述
强特分析过程
结尾
推荐资料(附录)
开头
学机器学习快一年啦,得亏有ChallengeHub,Zlab实验室,包包算法笔记,Kaggle竞赛宝典,以及砍手豪等一系列的优质文章与比赛思路分享,让我这个从不会Python的小白也掌握了一系列数据挖掘的方法与思想。本文主要以数据分析的角度入手,对数智乡村“爱睡觉的歪歪猪”团队与数智城市“睁眼摸瞎”团队的TOP方案中的上分magic进行一系列的分享,希望各位大佬轻喷。
第二届中国移动“梧桐杯”大数据应用创新大赛 - 数智乡村
大赛背景
在乡村旅游需求不断扩大、人们追求美好生活和优质旅游的新时代,乡村旅游建设成为实施乡村振兴发展战略的首要任务。以坚持“乡村振兴”为目标,积极完善和健全乡村基础设施和公共服务设施和旅游交通设施,进一步完善乡村旅游景点连接线、步道、停车场和景区导赏系统等交通设施,构建一站式(管理、服务、营销)全域旅游生态圈。
另一方面,由于疫情防控形势严峻,乡村周末短途旅游也逐渐成为人们旅游方式的首选。随着智能手机和5G网络的普及,运营商积累了来自用户的海量数据,比如漫游、位置信令等。通过大数据和算法构建用户乡村旅游的出行偏好模型,希望参赛队伍能够挖掘数据背后丰富的内涵,通过模型预测,让用户能获得精准的乡村旅游产品推荐,同时帮助提高、旅游管理和服务的质量。
赛题描述
要求参赛者基于用户脱敏模拟数据,预测用户在下一连续时间内的乡村出游行为 。即用户有没有在下一阶段进行出游,为二分类的问题,评分标准为F1。
需要注意的一点是,主办方在初赛时提供了一种思路,即根据用户距离乡村景点的历史距离与停留时间来更好的辅助模型进行预测。可以理解为,离乡村景点足够近并且呆的足够久便可以视为出游。
数据概述
初赛提供数据包含两份,第一份为基础信息、通信信息、上网信息,第二份为轨迹信息。
基础信息表字段举例:
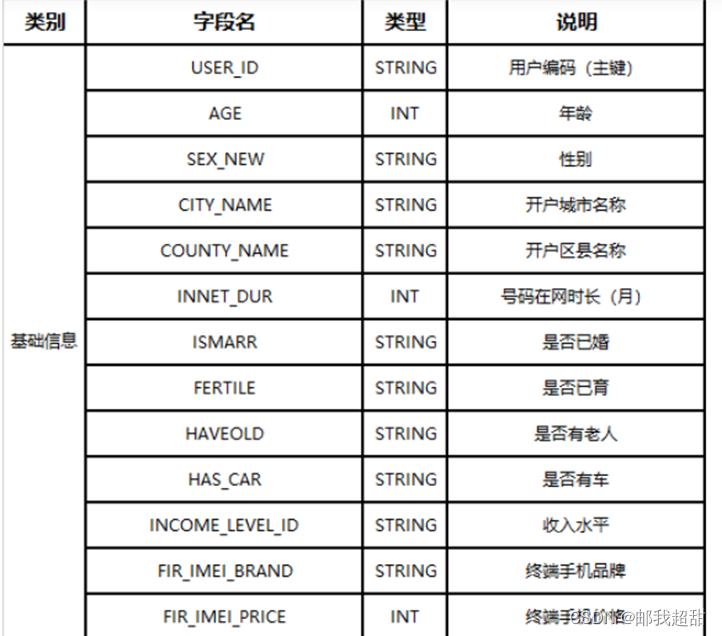
轨迹信息表字段举例: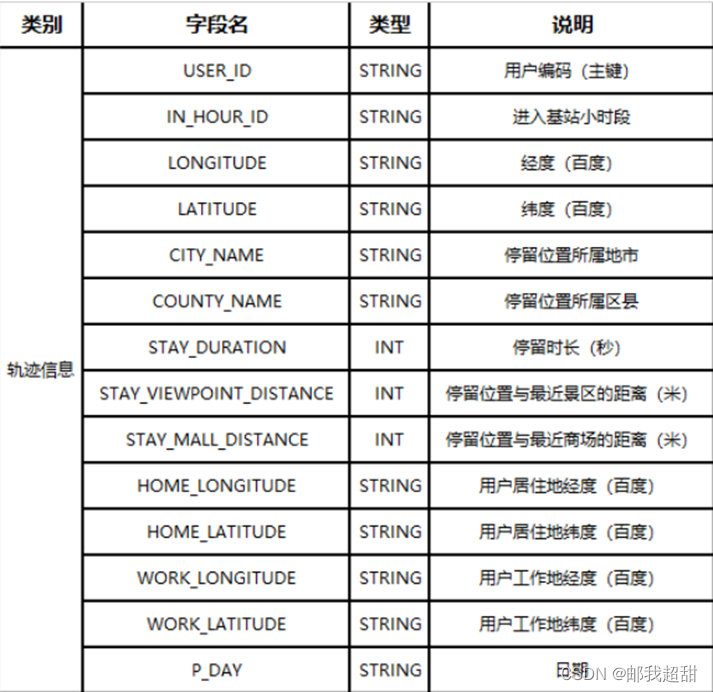
数据分析的总体思路
这里我首先会注意的点包括,数据表字段的大致含义与分布(我是否能理解该字段含义,训练集与测试集的分布是否吻合),原始字段数据的种类(文本,离散数据,连续数据,图像,字符串),数据集的标签分布(标签分布是否极端不平衡,是否能根据原始字段对标签进行人工预测),以及各个字段的缺失情况,以方便我进行后续的特征构建,数据集划分,模型选择与参数调整的工作。
在进行完基础信息表的大致查看后,我发现了三个点。
(1)‘ innet_dur ’字段存在明显的分布差异。进一步对其进行标签概率的分布查看,发现在训练集中‘innet_dur’字段中存在较多值偏大的样本,而这些样本90%都为正样本。并且测试集中‘innet_dur’字段值偏大的样本较少。因此,模型极易根据‘ innet_dur ’值进行标签的概率估值,具体表现为将测试集中'innet_dur'值偏大样本全部置1。
(2)数据集中标签的分布是5:1,并且赛题方说明了在测试集中的标签分布相同,而赛题的评分标准又为F1,因此在分类阈值划分后,若样本的预测个数小于并慢慢接近1/6,则说明该模型效果进一步增强,若样本预测个数大于1/6,则说明模型可能形成了明显的过拟合。
(3)通过数据集的缺失情况分析,我发现存在一部分用户同时缺少所有的家庭信息,该部分用户可能属于一个特殊的群体。
在进行完对数据的大致分析后,便可以进行对单个特征的查看。这里我首先会去查看与标签具有强关系的特征所对应的标签分布、类别特征的种类与数量、类别特征对标签强关联特征的聚合情况......
查看出游轨迹表,发现以下几点:
(1)用户所经过的区种类数量有限,且所在区与用户的出游倾向存在业务上的强关联,可以尝试进行更深的分析。
(2)用户离乡村景点最近的区可能可以反映他们旅游目的,以下将其称为旅游区。
(3)对各个旅游区中的出游用户进行分析,发现各个旅游区中用户的离景点最小距离具有明显差异,有的旅游区的平均最小距离为2000米,有的为7000米。
(4)发现该表为一个主键对应多行的情况,且该赛题中用户的出游轨迹对于用户的出游习惯具有业务上的强关联,因此之后进行时间序列上的分析。
赛题leak分析
在进行序列分析时,由于我队长直接将未经时间排序的序列直接进行特征提取,线下分数直接暴涨,发现数据中的原始轨迹存在泄露。
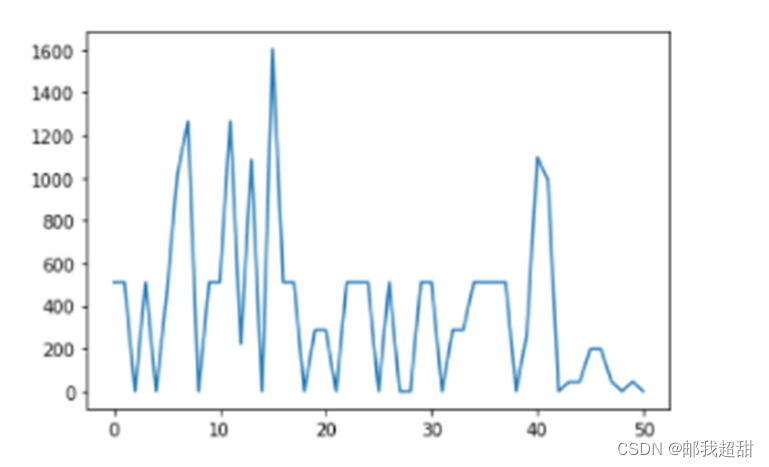
按照时间排序后的距离景点距离波动图:
按照表格顺序排序后的距离景点距离波动图:(上下两幅图非同一样本)
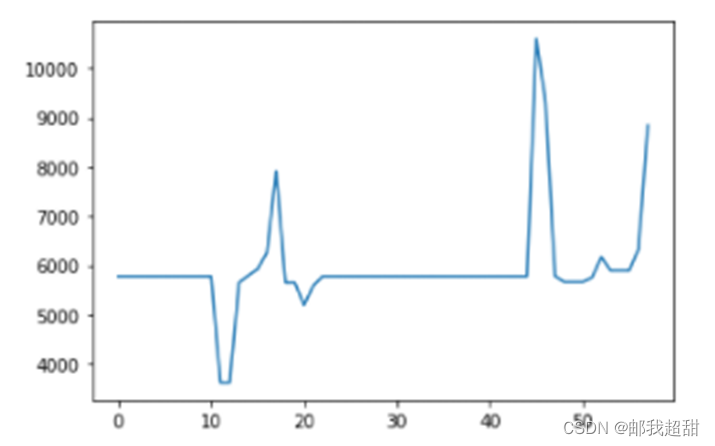
这里我们本想提取用户出行的距离波动,即根据用户单次移动的距离去判断用户是否进行大范围的运动,以辅助模型对用户是否出游的判断,而在我的预想中,该距离图应该具有用户周期性运动(例如上下班距离会出现相同振幅的多次波动),时间上会在周末与工作日轨迹出现不同(用户出游更可能出现在周末),距离序列发生异常性波动(用户忽然去了个较景点远或者近的地方),然后我通过对序列进行以上多个角度的观测再进行特征提取。
然而,通过以上的距离景点距离波动图分析,我就忽然明白了该顺序泄露对于标签预测的重要性了。原始数据顺序中的距离波动相比时间顺序的距离波动明显较少,用户在景点、在家的情况被该顺序明显的区分出来了。又由于用户出游次数肯定明显小于在家或者工作次数,此时进行整体的序列平移做差,将用户距离序列中平稳的一面全部抹去(抹去了经常在家的距景点距离的信息),将最可能的出游信息的波动完全凸显出了。那么如何根据这个泄露顺序进行多方面的特征提取呢?大家也可以思考下
未点明的分析思路
在进行数据分析前,其实可以先对分析结果进行一个假设,即你想从你的分析结果中得到什么结论,此时再针对数据分析的结论进行进一步分析。若与假设相符,则可以对该假设所蕴含的信息进行特征提取,若不符合假设,则进行假设失败原因的假设,进一步进行分析。
在进行分析时,我们更应该构建的是一个对于我们研究对象的总体性质研究,在该题中也可以理解为对用户进行各个角度的侧写。在该题中,可以观察到训练集中使用电子产品的时间明显多于测试集用户,那么是否可以说明训练集中年轻人更多一些呢?若是,我们则可以对于其反应年龄的字段进行组合,或者说在构建训练集时强行改变训练集的分布,选择分布相同的样本进行线下验证集的构建。进行完侧写的假设,并验证正确后,若模型缺少相应的信息,则可以手动增加特征或修改模型结构进行相应的补充了。在得到模型结果之后,便可以对模型预测失败的样本用以上的角度进行进一步分析。
也有机器学习入门的课程在说,对特征进行one-hot,归一化,分布转换这种来提取与转换特征。这样的方法比较基础,在一般的数据集与目前主流的GDBT模型中效用已经是微乎其微了。但是这种知识点是真的没用吗?可能也可以用在特征与样本选择,模型调优上呢。(详见附录)
结尾
以上提到的数据分析结论全部都是提分点,对于分析得到的结果,如何进行进一步分析、修正、特征提取也是一大关键。最终该赛道获得A榜第一。
第二届中国移动“梧桐杯”大数据应用创新大赛 - 数智城市
大赛背景
为打造数字抗疫、推动疫后城市复苏,湖北将数智城市作为经济回暖、城市高速发展的核心引擎。中国移动助力湖北建设集大数据、人工智能、区块链、物联网应用四大中枢为一体的城市大脑,持续开展基础数据归集和治理,为数智应用持续赋能。
近年来,湖北电信诈骗违法犯罪来势凶猛,诈骗人员更加职业,诈骗手段更加专业,存量诈骗用户逐月递增,严重影响广大居民生命财产安全。按照国家、省、市打防电诈工作部署要求,湖北移动积极配合政府开展反诈行动,运用“灵珑”电信反诈模型从普通用户中有效鉴别出电信诈骗人员,携手公安、银行等建立三方合作机制打击电信诈骗,实现诈骗窝点的精准识别,为维护社会秩序,保障广大居民生命财产安全,起到重要贡献。
本届竞赛将从真实场景和实际应用出发,在数智城市领域新增了更具挑战性、更加务实的任务,期待参赛选手们能在这些任务上相互切磋、共同进步。
赛题描述
要求参赛者运用模型从普通用户中有效鉴别出电信诈骗人员,携手公安、银行等建立三方合作机制打击电信诈骗,实现诈骗窝点的精准识别,为维护社会秩序贡献力量。
这道题的评价标准很有意思, 为TOP255的查准率(precision)。相当于只关注你预测头部的准确率。需要注意的一点是,该题曾出现过一个leak,即用户的入库时间格式,入库时间精确到分秒的大部分为违约用户,否则为正常用户。
数据概述
包含用户身份信息,用户通话行为,以及众多的二分类特征。部分字段列举如下:
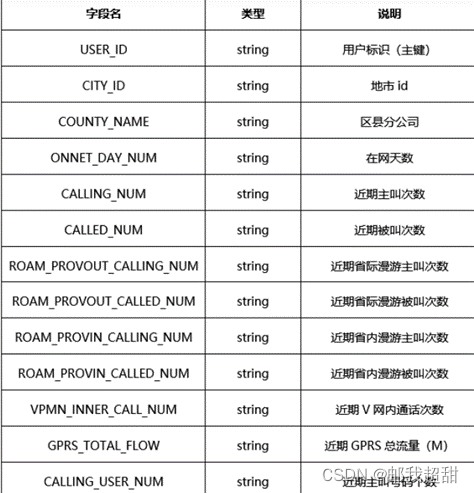
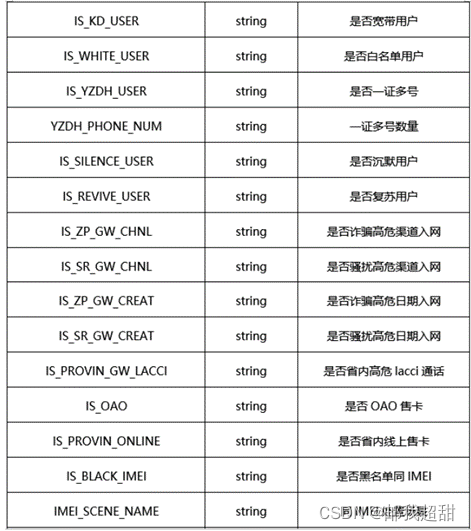
强特分析过程
该赛题主要存在两种强特。接下来按照发现的时间进行介绍。
首先进行总体的数据分析(过程方法类似上方的数智乡村赛道,一同服用效果更加),发现该数据标签分布极端不平衡,同时,数据集中存在大量和标签具有强业务相关的字段,比如是否诈骗高危渠道入网,是否黑名单同IMEI等等。
对该类字段进行进一步分析,发现该类字段几乎全部为二值类别特征,即值的种类为0、1。并且其中0或1的总体占比往往极低,并且其中往往有一类的标签概率明显较大。因此一个自然而然的思路出现下,我可以先针对具有高危特征的样本进行数据集划分,将具有高危特征的样本单独划分为一类数据集进行模型训练,这样或许可以改善样本分布的极端不平衡。并且我假设具有高危特征的用户与其他用户具有一些差异,由此构建的模型应该会具有差异度,也可以为我后面的模型融合提供一定的帮助。
在进行完成后,最终具有高危特征的样本只有原先的1/5,并且最终的诈骗用户也成功保留了2/3,可以说是相当成功的。在这之后进行了baseline模型训练,最终预测正确出100个左右的诈骗用户。在这之后我又对全部的数据集训练得到了个模型,最终正确预测出110个左右的诈骗用户。然而,这时候我的数据敏感性发挥了作用(数据敏感性见附录)。为啥数据集正负样本数量差异如此巨大的情况下,所预测出的诈骗用户数量却相差不多?接下来我对两次结果做了一个交叉,发现有90多个的诈骗用户呈现吻合,预测结果高度一致。于是,我的数据敏感性又发挥了作用。为啥剩下的诈骗用户就是预测不出来?剩下的不具有高危特征的用户群体预测出的诈骗用户为何寥寥无几?这时候思路进一步延伸,会不会不具有高危特征的用户群体里的诈骗用户隐藏的太好了,而和预测得出的诈骗用户特征相差的太远了,模型在训练过程中更容易拟合具有高危特征的那一部分用户,而导致对不具有高危特征的那一部分用户预测结果较差?
于是我在这之后做了对抗验证,发现预测对的诈骗用户、预测错的诈骗用户内部验证的AUC结果是50%左右,而两部分数据进行对抗验证,AUC结果为99%,说明模型可以明显的区分出这两类用户。于是,我们通过一定手段,将数据集分为两部分,容易预测出的诈骗用户做一个模型,难预测出的诈骗用户做一个模型,最终分数得到大幅提升。
然而,区分两部分诈骗用户,需要本身具有一个较好的模型。该部分我们尝试多次效果甚微,但排行榜上高分的人又众多。根据我和队友的讨论(这之后我做的就很少了,更多的是参与思路的讨论),缺少的信息可能来源于之前发生过泄露的入库时间特征。但问题是,为了最终的B榜,不能直接利用该时间的格式进行特征提取,而是要从其他的手段去利用该特征。这里我队友给出的方案是,根据入库时间为主键,对其他特征做一个groupby的排序特征。这一步根据入库时间,将包含入库时间的用户分为了不同群体,再进行rank排序特征的提取,可以凸显出同一批时间入库的用户中违约特征的头部排序,相比统计特征可以更好的凸显每批入库用户细粒度的信息。最终该特征的特征重要性也是遥遥领先于其他特征。
结尾
(最终我退出该团队选择了乡村赛道)。这个比赛的数据分析更偏向于数据集的划分与特征提取时对赛题任务与模型的思考。并且我们也尝试了easyesemble的模型,对于召回率的提高确实很到位,但召回之后的精确排序这里我们做的不是很多(时间不够了)。最终该赛题取得B榜第一。值得一提的是,这道题B榜第二与我们同分,可能还具有别的magic。
推荐资料(附录)
1、特征工程思路实操 全网特征工程实操最通透的...
2、算法工程师的术与道 算法工程师的术与道:从特征工程谈数据敏感性 - 知乎
3、从Kaggle史上看高阶特征工程 从Kaggle史上人数最多的比赛看高阶特征工程 - 知乎
4、 从Kaggle IG看机器学习的模型选择进阶 从Kaggle IG看机器学习的模型选择进阶 - 知乎
5、其他关于数据分析,baseline构建,常见特征工程的python代码可以看本作者其他的博客
最后
以上就是苗条毛巾最近收集整理的关于浅谈2022梧桐杯乡村、城市赛道双TOP1——从数据分析的角度的全部内容,更多相关浅谈2022梧桐杯乡村、城市赛道双TOP1——从数据分析内容请搜索靠谱客的其他文章。








发表评论 取消回复