作者:邵可佳
笔者一直对颜值评测领域问题感兴趣,而该领域的公开数据集有限,很难取得大规模的高质量标注数据,如何设计一套无需标注数据的颜值评测模型,一直是困扰笔者很久的问题。
而近期,笔者使用无监督技术在这方面做了一个小小的尝试,有了一点收获,在这里分享给大家,希望给大家在模型训练领域带来新思路,也有错漏或可以改进的地方希望大家不吝赐教。
众所周知,目前机器学习主要还是通过监督学习或半监督学习来实现模型训练,进而解决现实业务问题。而这就导致目前的机器学习模型必须严重依赖于高质量的标注数据,一旦数据出了问题,模型的效果也就变差。
笔者一直对颜值评测领域问题感兴趣,而该领域的公开数据集有限,很难取得大规模的高质量标注数据,如何设计一套无需标注数据的颜值评测模型,一直是困扰笔者很久的问题
而近期,笔者使用无监督技术在这方面做了一个小小的尝试,有了一点收获,在这里分享给大家,希望给大家在模型训练领域带来新思路,也有错漏或可以改进的地方希望大家不吝赐教。
0.结果预览
首先给心急的朋友上一下结果,以免浪费大家的时间:

上图可以明显看出,皮肤按照不同的色泽和光滑程度,聚类到了一起,效果还算可以
1.数据准备

目前已知的公开数据集就是华南理工大学开源的人脸评分数据集了:
https://github.com/HCIILAB/SCUT-FBP5500-Database-Release
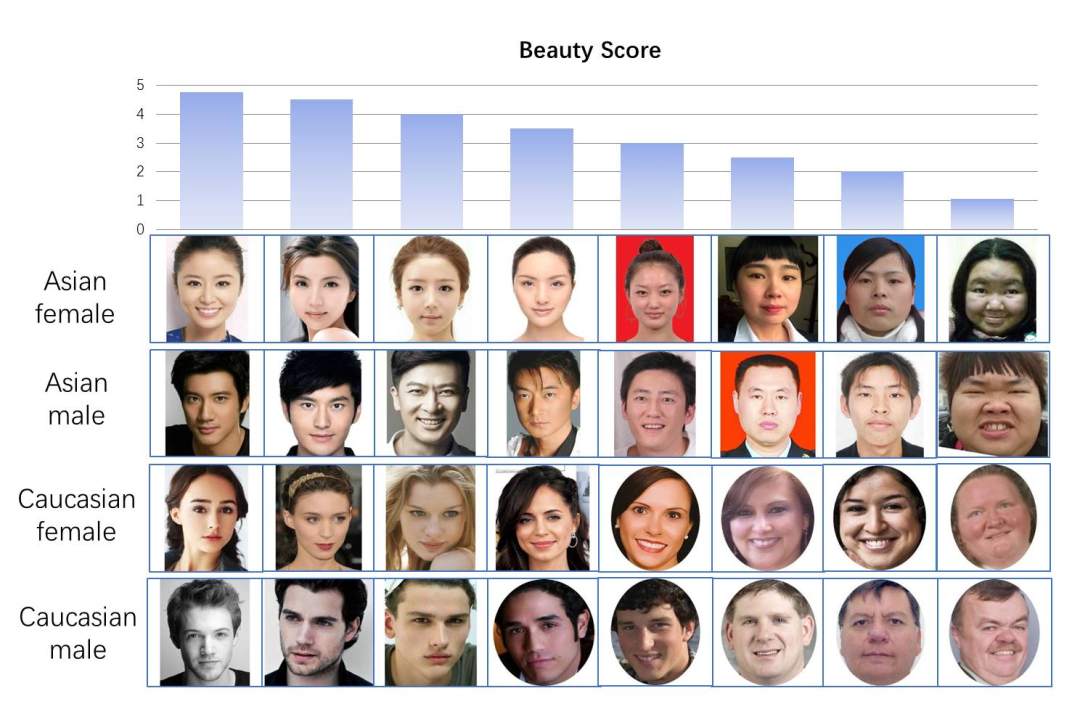
该数据集包括5k多张整理好的评分人脸,得分从0-5分之间分布。
该数据集能很方便的做颜值评测模型,
然而,落到细节上,如果想做皮肤检测,好像就没办法使用了?
再想想,好像也不是不可以,只需要把人脸上的皮肤部分提取出来,使用knn,umap等算法自动聚类,似乎也能搞定这个问题?
好吧,说干就干,想太多不如动手试试:
(1)先想办法切分人脸:
笔者到github上搜刮一番,找到这么一款人脸分割的项目:
https://github.com/zllrunning/face-parsing.PyTorch
分割效果看起来挺炫酷的:

然而实际使用,切分出来的结果却是这样:
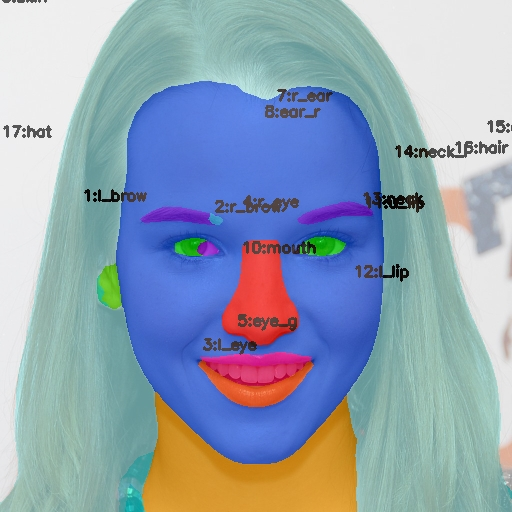
作者回复说是索引没有对齐,不过我按照新的索引对齐后,发现头发脖子等部分切分出来的还是不太对,看起来没办法可靠的应用。
于是又想到dlib的人脸关键点,通过利用68个人脸关键点,倒是可以很好的分割人脸,且准确率和可靠度都很好,那么就是它了。
切割出来的效果还可以,想想就脸颊部分的皮肤最多,就先用脸颊部分吧:
虽然还有点点不完美,但聊胜于无,至少有了可以训练的数据,以后还可以慢慢往精细化方面改进嘛。
2. 模型选择
接下来就得考虑使用什么样的无监督模型了,于是乎又搜刮了一番。
以下是在github上搜到的几种无监督学习模型框架,当然还有其他一些框架,看代码都是不太靠谱的这里就不罗列了:
(1).IIC
https://github.com/xu-ji/IIC
算法原理:

通过不断变换数据,挖掘图像中的不变特征,进行聚类。
取舍原因:
挖掘、训练时间过长,1周的GPU时间都未能完成。
(2).SCAN
https://github.com/wvangansbeke/Unsupervised-Classification
算法原理:
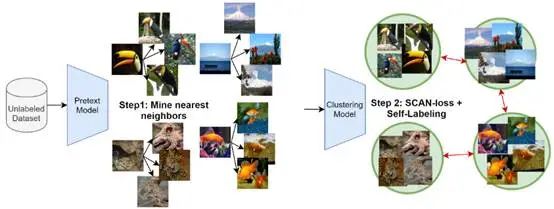
分两步走,首先聚类挖掘最近邻,然后假设最近邻为一类打上标签后,训练分类模型。
取舍原因:
在验证阶段需要使用标签调优,否则最后效果不能保证,目前数据条件不允许。
(3). solo-learn
https://github.com/vturrisi/solo-learn
solo-learn集成了多种无监督学习的算法,不断的权衡取舍后,选用了BYOL。
因为从solo-learn公开的测试结果来看,BYOL在相似的领域图片数据集上Top5的表现是最好的(皮肤也是相似的领域图片数据):
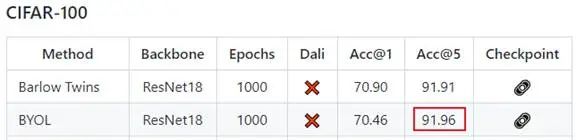
而Barlow Twins虽然结构简单,但在算力资源上并未带来太大的节省,所以BYOL目前来看是最好的选择。
算法原理:
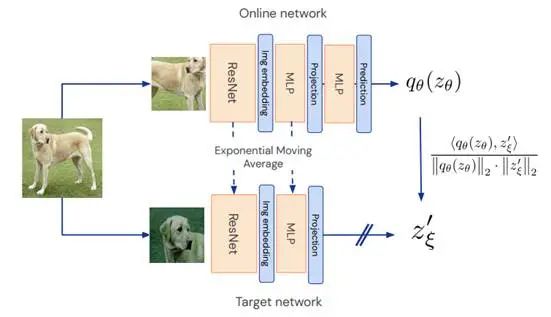
通过建立两个神经网络,最小化两个网络的相似度损失,实现图像的聚类。
取舍原因:
通过比较测试结果,目前这种结构鲁棒性较好,准确率也较高,对算力的消耗也不算大。
3.模型训练
使用 solo-learn训练果然比较简单,也没有那么多烦心事,按照安装说明,一顿操作,直接就跑起来了,不到两个小时,模型训练结束:
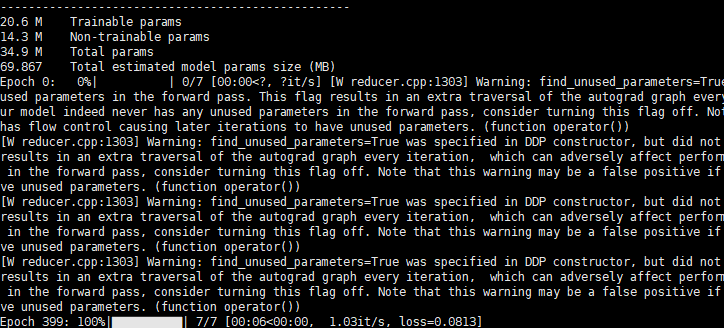
然后就是迫不及待的测试模型效果,但结果却让人感到匪夷所思:
模型每次输出的结果都不一样!
难道是无意之中增加了一些随机操作?
一顿检查加询问才发现,目前这样训练得到的结果只是一个模型骨架(backbones),这样训练出来的模型只能输出一堆抽象特征,而每次预测时生成一个linear model会随机初始化骨架外层的网络权重,导致每次结果都不同!??
理解了这一点,接下来就是如何利用backbones产生的特征来得到真正的结果了
目前又面临着如下取舍:
使用何种聚类模型得到最终的结果呢?
看起来,工作似乎又回到了起点?一顿复杂操作之后,结果只是对图像特征进行了降维打击!晕...
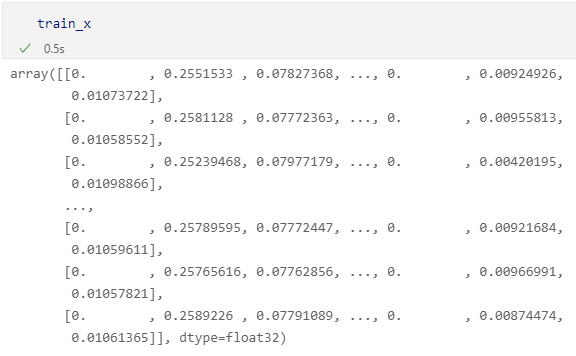
但换个角度想想,这样的降维操作还是有用的,直接用复杂的图像数据聚类模型极有可能跑偏,甚至得到一个平凡解
看到这样的特征数据,笔者首先想到的不是KNN,而是LDA(隐狄利克雷模型),这样的数据结构看着太相似了,虽然LDA用于NLP自然语言中的主题挖掘,但目前生成的抽象特征,不也正好可以看做主题词向量库数据吗?
于是 github 搜刮器再次搞起,不看不知道,还真有人做了这方面的研究:
https://github.com/rmsander/spatial_LDA
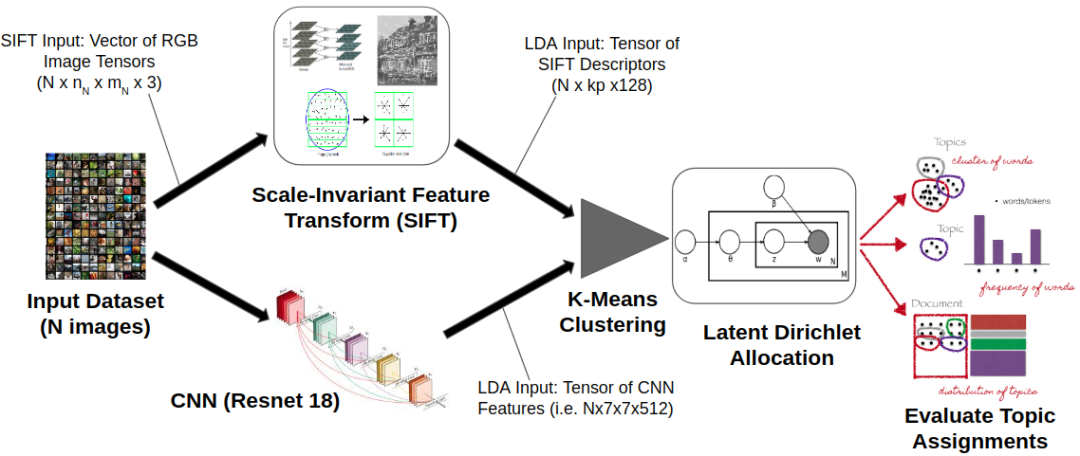
如上图所示,spatial_LDA直接将神经网络输出的特征输入到了LDA模型,嘿嘿,这个思路还真的很一致。
那还等什么呢?代码撸起来:
lda = LatentDirichletAllocation(n_components=class_num, random_state=0)
lda.fit(train_x)
这就是LDA聚类的关键代码了,是不是看起来很简单清爽?
唯一需要考虑的就是叫预先假设分类(主题)个数!
但人脸皮肤到底有多少分类,笔者也不清楚呀?这该如何是好?
首先拍脑袋取个概数吧:如果人脸能划5个分数,每个分数区间按肤色又能划出5种程度,再考虑到5种粗糙程度,那就是125。
给算法留点余地,那就先设置200看看效果如何:
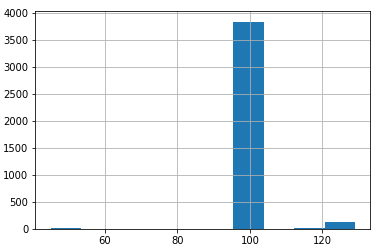
如上图所示,目前的训练样本预测结果,还真的有了明显的区分度,数据的真实类别在130左右
4.效果评估
这样做出来的结果到底怎么样呢?既然没有标签,也没办法计算复杂度。
我们只能从这些分类里抽取部分样本观察下,效果预览如下:

发现上述结果,每类之间的人脸皮肤确实显著不同,这是一个较为满意的初步结果
5.后记
虽然,模型成功从无标签的数据中做出了较好的预测,但还有许多细节,模型没有把握住:
1.皮肤的粗糙程度好像还没有完全的体现出来;
2.皮肤上的一些缺陷没有挖掘出来;
后继还应该往这些方面改进:
1.更加精细化的样本数据(可以去掉脸颊上的眼袋、鼻子边缘等细节),预期模型会有提升;
2.更加智能化的分类识别过程(目前的分类是拍脑袋决定的,还有很大的科学空间);
3.更加复杂的模型训练过程(目前选用的backbones是resnet18,还可以尝试resnet50等);
尽管目前做出了一个算是“合理”的模型,但离实际应用还有距离,笔者后继还会继续努力的优化模型思路,寻找更合适的模型结构。
上述工作均已开源,有兴趣的朋友可以访问:https://gitee.com/knifecms/beauty
行文仓促,难免错漏,希望大家多多批评指正,共同进步!
最后
以上就是魔幻保温杯最近收集整理的关于AI | 一次无监督学习的尝试(皮肤分类)的全部内容,更多相关AI内容请搜索靠谱客的其他文章。








发表评论 取消回复