Capsule介绍
Hinton在《Dynamic Routing Between Capsules》中提出了capsule,以神经元向量代替了从前的单个神经元节点,以dynamic routing的方式去训练这种全新的神经网络。又在第二篇论文《Matrix Capsules With EM Routing》中以神经元矩阵代替了神经元向量,我们以em routing的方式进行训练。本文分析第一篇capsule论文《Dynamic Routing Between Capsules》。
CNN的工作原理
- 浅层的卷积层会检测一些简单的特征,例如边缘和颜色渐变。
- 更高层就会将简单的特征加权合并到更复杂的特征中,在这种设置中,简单特征之间的关系(平移和旋转)构成了更高级的特征。CNN在这里会使用到max pooling,保留重要的特征同时丢弃一些它所认为不重要的特征,增加高层神经元的视野。
- 最后,网络顶部的网络层会结合这些非常高级的特征去做分类预测。
CNN有两个重大的问题:
- CNN只关注要检测的目标是否存在,而不关注这些组件之间的位置和相对的空间关系。如卡戴珊的例子(我并没有黑她,真的没有),CNN判断人脸只需要检测出它是否存在两个眼睛,两个眉毛,一个鼻子和一个嘴唇,现在我们把右眼和嘴巴换个位置,CNN依然认为这是个人。
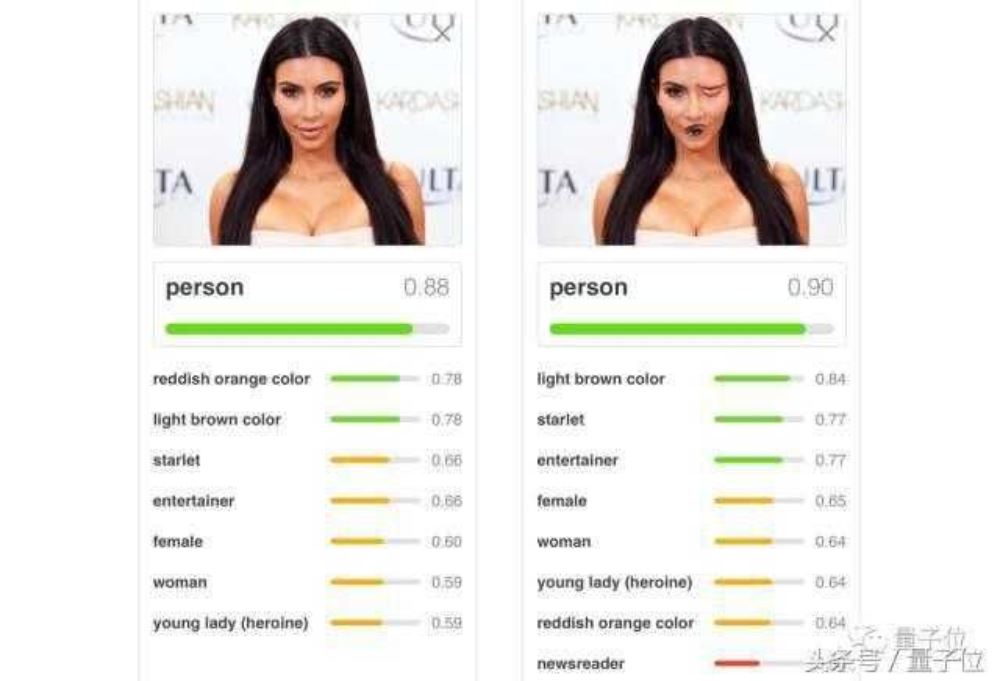
- CNN对旋转不具备不变性,学习不到3D空间信息。例如下面的自由女神,我们只看自由女神的一张照片,我们可能没有看过其它角度的照片,还是能分辨出这些旋转后的照片都是自由女神,也就是说,图像的内部表征不取决于我们的视角。但是CNN做这个事情很困难,因为它无法理解3D空间。

- 另外,神经网络一般需要学习成千上万个例子。人类学习数字,可能只需要看几十个个例子,最多几百个,就能区别数字。但是CNN需要成千上万个例子才能达到比较好的效果,强制去学习。并且关于前面的旋转不变性,CNN可以通过增强数据的手段去改善,但是这也就需要用到大量的数据集。
虽然max pooling在很多任务上提高了原始CNN的准确率,但是我们也可以看到max pooling丢失了很多有价值的信息,并没有很好地理解内容,比如对畸形脸的判定,之所以测试集上准确率高,是因为我们没有畸形脸的训练数据与测试数据。
因此Hinton认为:max pooling工作得这么好其实是一个大灾难。
The pooling operation used in convolution neural networks is a big mistake and the fact that it works so well is a disaster.
就算你不使用max pooling,传统CNN依然存在这样的关键问题,学习不到简单与复杂对象之间的重要的空间层次特征:
Internal data representation of a convolution neural network does not take into account important spatial hierarchies between simple and complex objects.
所以Capsule尝试去解决这些问题:
- Capsule可以学习到物体之间的位置关系,例如它可以学习到眉毛下面是眼睛,鼻子下面是嘴唇,可以减轻前面的目标组件乱序问题。
- Capsule可以对3D空间的关系进行明确建模,capsule可以学习到上面和下面的图片是同一个类别,只是视图的角度不一样。Capsule可以更好地在神经网络的内部知识表达中建立层次关系。

- Capsule只使用CNN数据集的一小部分,就能达到很好的结果,更加接近人脑的思考方式,高效学习,并且能学到更好的物体表征。
小结:这一节引用了capsule的概念,可以用于深度学习,更好地在神经网络的内部知识表达中建立层次关系,并用不同的方法去训练这样一个神经网络。
capsule的内部工作
- Capsule是一个神经元向量(activity vector)
- 这个向量的模长表示某个entity存在的概率,entity可以理解为比如鼻子,眼睛,或者某个类别,因为用vector的模长去表示概率,所以我们要对vector进行压缩,把vector的模长压缩到小于1,并且不改变orientation,保证属性不变化。
- 这个向量的方向表示entiry的属性(orientation),或者理解为这个vector除了长度以外的不同形态的instantiation parameter,比如位置,大小,角度,形态,速度,反光度,颜色,表面的质感等等。
Capsule和普通神经元的比较
这张图展示了capsule和传统神经元的计算区别:

- 它们的不同之处在于计算单位的不同,传统神经网络以单个神经元作为单位,capsule以一组神经元作为单位,传统神经网络可以把一个神经元的输入看成一个向量,涉及到向量操作,而capsule可以把一个capsule的输入看成一个矩阵,涉及到矩阵操作。
- 相同之处在于,传统神经网络中神经元与神经元之间的连接,capsNet中capsule与capsule之间的连接,其实都是通过对输入进行加权的方式。
传统神经元的计算步骤:(如下右图)
-
计算输入标量xi的标量权重wi
-
对输入标量xi进行加权求和
-
通过非线性激活函数,进行标量与标量之间的变换,得到新标量hj
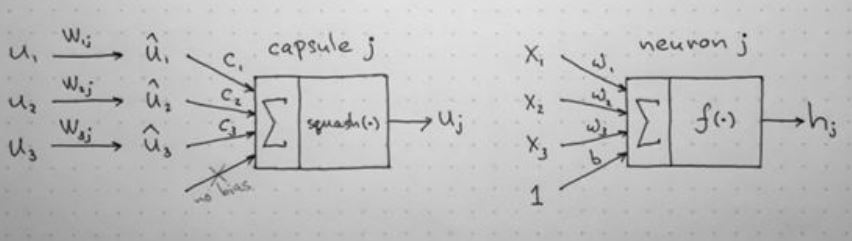
Capsule的计算步骤:
我们把这个过程分为四部分:
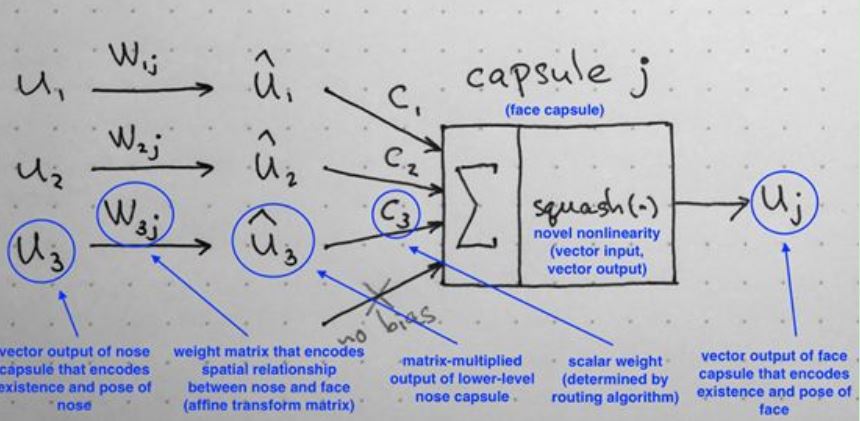
1. 输入向量ui的W矩阵乘法
- 首先假设较低层次的Capsule ui分别检测眼睛、嘴巴和鼻子这三个低层次特征,那么下一层的Capsule uj检测的是面部高层次特征。
- ui乘以相应的权重矩阵W得到prediction vector(注意这个图里只画了一个predictionvector,也就是ui_hat,因为这里只对应了一个capsule输出,如果下一层有j个capusles,ui就会生成j个prediction vectors)
- W编码了重要的空间和其他低层次特征以及高层次特征之间的关系。
例如,矩阵W2j可以对鼻子和面部的关系进行编码:面部以鼻子为中心,其大小是鼻子的10倍,而在空间上的方向与鼻子的方向一致。矩阵W1j和W3j也是类似的。经过矩阵相乘之后,我们可以得到更高层次特征的预测位置。比如,u1hat根据眼睛预测人脸位置,u2hat根据嘴巴预测人脸位置,u3hat根据鼻子预测人脸位置。最后如果这3个低层次特征的预测指向面部的同一个位置和状态,那么我们判断这是一张脸:

2. 输入向量ui的标量权重c
- 前面提到的普通神经元在这一步对输入进行加权,这些权重是在反向传播过程中得到的,但Capsule是通过dynamic routing的方式进行交流的。在这一步,低层次capsule需要决定怎么把自己的输出分配给高层次capsule。

- 在这张图片中,我们现在有一个低层次的已经被激活的capsule,它对下层每个capsule会生成一个prediction vector,所以这个低层次capsule现在有两个prediction vector,对这两个prediction vectors分配权重分别输入到高层次capsule J和K中。(注意:这里是由低层次capsule对自己的prediction vectors分配权重,而不是由高层次capsule对自己的input vectors分配权重)
- 现在,更高层次的capsule已经从其他低层次的capsule中获得了许多输入向量,也就是图片中的点,标红的部分是聚集的点,当这些聚集点意味着较低层次的capsule的预测是相互接近的。
- 低层次capsule希望找到高一层中合适的capsule,把自己更多的vector托付给它。低层次capsule通过dynamic routing的方式去调整权重c。
例如,如果低层次capsule的prediction vector远离capsule J中“correct”预测的红色集群,并且接近capsule K 中的“true”预测的红色集群,那么低层次capsule就会调高capsule K对应的权重,降低capsule J对应的权重。最后,如果高层次capsule接收到的这些prediction都agree这个capsule,那么这个capsule就会被激活,处于active状态,这就叫Routing by agreement。
3. 加权输入向量的总和
高层次capsule根据前面计算的权重c,对所有低层次capsule的prediction vectors进行加权,得到一个向量。
4. 向量到向量的非线性变换
Squashing是一种新的激活函数,我们对前面计算得到的向量施加这个激活函数,把这个向量的模长压缩到1以下,同时不改变向量方向,这样我们就可以利用模长去预测概率,并且保证属性不变化。

这个公式的左边是变换尺度,右边是单位向量。
小结:这一节介绍了capsule的基本概念,capsule把单个神经元扩展到神经元向量,有更强大的特征表征能力,并且引入矩阵权重来对不同layer特性之间的重要层次关系进行编码,结果说明了以下两种性质:
- Invariance 不变性:物体表示不随变换变化,例如空间的 Invariance,是对物体平移之类不敏感(物体不同的位置不影响它的识别)
- Equivariance同变性:用变换矩阵进行转换后,物体表示依旧不变,这是对物体内容的一种变换。
Dynamic Routing算法详解
这个算法的核心思想在于:
Lower level capsule will send its input to the higher level capsule that “agrees” with its input. This is the essence of the dynamic routing algorithm.
其算法流程如下:

下面我们逐行讲解这个伪代码:
- 算法的输入是第L层capsule i关于第L+1层capsule j的prediction vectors,也就是u_hat,routing迭代次数设置为r,
- 初始化b_ij为0,b_ij是用于计算c_ij
- 对接下来4-6行代码迭代r次,计算第L+1层capsule j的output
- 在第L层,每个capsule i对b_ij做softmax得到c_ij,c_ij是第L层capsule i给第L+1层capsule j分配的权重。在第一次迭代的时候,所有的b_ij都初始化为0,所以这里得到的c_ij都是相等的概率,当然后面迭代多次后,c_ij的值会有更新。
- 在第L+1层,每个capsule j利用c_ij对u_j|i_hat进行加权求和,得到输出向量s_j
- 在第L+1层,使用squash激活函数对s_j做尺度的变换,压缩其模长不大于1
- 我们在这一步更新参数,对所有的L层capsule i和L+1层capsule j,迭代更新b_ij,更新b_ij为旧b_ij + capsule j的输入和输出的点乘,这个点乘是为了衡量这个capsule的输入和输出的相似度,低层capsule会把自己的输出分给跟它相似的高层capsule。
经过r次循环,高层capsule可以确定低层分配的权重以及计算其输出,前向传播可以继续连接到下一个网络层。这个r一般推荐设置为3,次数太多了可能会过拟合。
为了便于理解,我画了个从2个capsule到3个capsule的routing过程图:
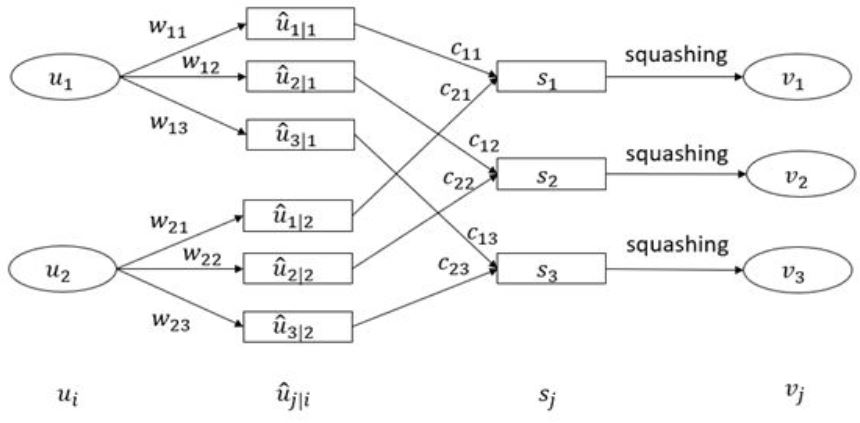
下面这个例子更加直观地展示了权重更新的过程:
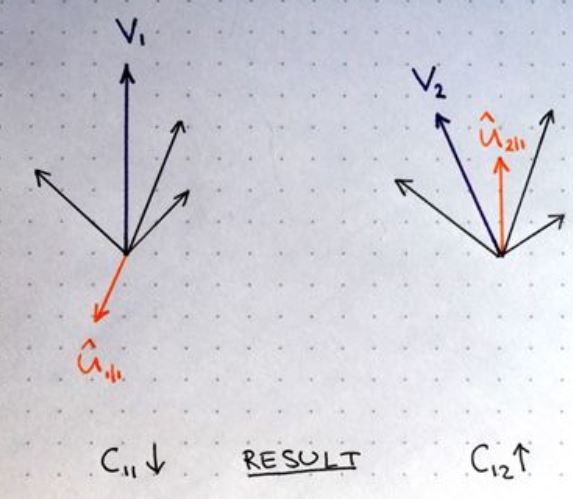
- 假设有两个高层capsule,紫色向量v1和v2分别是这两个capsule的输出,橙色向量是来自低层中某个capsule的输入,黑色向量是低层其它capsule的输入。
- 左边的capsule,橙色u_hat跟v1方向相反,也就是这两个向量不相似,它们的点乘就会为负,更新的时候会减小对应的c_11数值。右边的capsule,橙色u_hat跟v2方向相近,更新的时候就会增大对应的c_12数值。
- 那么经过多次迭代更新,所有的routing权重c都会更新到这样一种程度:对低层capsule的输出与高层capsule的输出都进行了最佳匹配。
小结:这节介绍了dynamic routing algorithm by agreement的方式去训练capsNet,主要idea是通过点乘去衡量两个capsule输出的相似度,并且更新routing的权重参数。
Part 4:CapsNet结构
论文给出了一个简单的CapsNet模型,第一层是个普通的conv层,第两层也结合了conv操作去构建初始的capsule,再通过routing的方式和第三层的DigitCaps交流,最后利用DigitCaps的capsule去做分类。
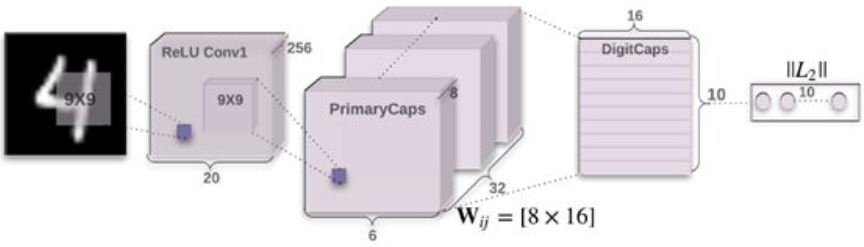
- ReLI Conv1,这是一个普通的卷积层,这里使用256个99的卷积核,对图像进行卷积,得到2020*256的输出。
- PrimaryCaps,这里构建了32个channel的capsules,每一个map都使用8个99的卷积核对前面的图像特征做卷积,得到668的输出,也就是每个map都有66个8维的capsules,不同的map表示不同的entity的type,同一个map里面的capsules表示不同的位置。最后得到66832的输出,也就是326*6=1152个capsules
- DigiCaps,对前面1152个capules进行传播与routing更新,输入是1152个capsules,输出是10个capules,表示10个数字类别,最后我们用这10个capules去做分类。
CapsNet的损失函数
在Routing过程中我们更新了c_ij参数,其余参数是通过后向传播进行更新,这里对于每一个capsule k我们都计算它的 Margin loss损失函数L_k:
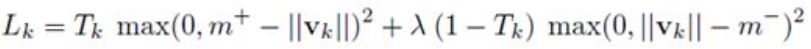
- k是分类类别,如果类别k存在(即样本属于类别k),设置Tk=1,否则令Tk=0
- 如果Tk=1,设置m+=0.9,优化拉近vk和m+的距离,因为如果vk接近m+,说明这个类别概率很大,那么这个类别就是正的。
- 如果Tk=0,设置m-=0.1,拉近负例vk和m-的距离。
- Landa参数设置为0.5,这是为了防止负例减小了所有capsule向量的模长。
DigitCaps重构图像
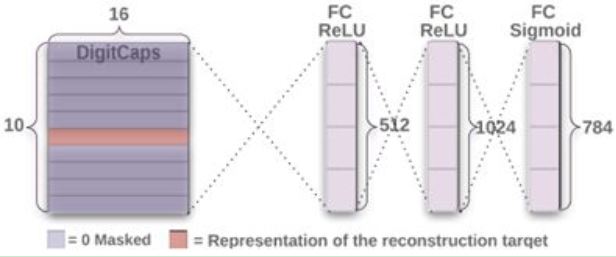
最后增加了一个额外的task,利用DigitCaps重构图像:
- 这里会mask掉一些capsule,用有代表性的capsule去重构图像,通过几层全连接层得到784维的输出,也就是原始图像的像素点个数,以这个输出跟原始像素点的欧几里得距离作为重构损失函数。
CapsNet与CNN的联系
- 相同之处:CNN可以上下左右平移在图像上进行扫描,也就是它在这个地方学到的东西可以用到下一个地方,可以有效识别图片的内容,所以capsule也采用了convolution的特点,最后一层只用capsule
- 不同之处:capsule不采用max pooling的做法,因为Max pooling只保留了区域内最好的特征,而忽视了其它的特征,routing并不会丢失这些信息,它可以高效处理高度层叠的例子。浅层capsule会把位置信息通过place-coded的方式记录在激活的capsule中,高层的capsule会通过rate-coded的方式记录在capsule vector的值当中。
Capsules做分类的优点
- 适合输出有多个类别的多分类问题,softmax只适合只有一个输出的多分类问题,因为softmax会提高某一类的概率,而压低其余所有类别的概率。
- 另外,我们也可以用k sigmoid去代替softmax,把多分类任务转换成K个二分类任务。
小结:这节介绍了capsNet,目前capsNet在小数据集上达到了state of art的分类效果,但是在大数据集中训练得比较慢,后面应该会改进routing的过程,在更困难的数据集和不同的域上良好地运行。
参考知乎莫大神,搬过来方便看:
浅析第一篇Capsule:Dynamic Routing Between Capsules
最后
以上就是失眠小蚂蚁最近收集整理的关于Capsule:Dynamic Routing Between Capsules的全部内容,更多相关Capsule:Dynamic内容请搜索靠谱客的其他文章。








发表评论 取消回复