Python学习笔记:Jupyter Notebook快速入门案例:学习时间与成绩的关系
源教程地址:https://www.bilibili.com/video/BV1Q4411H7fJ?p=2&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
是对新手很友好的入门教程,操作简单,容易上手
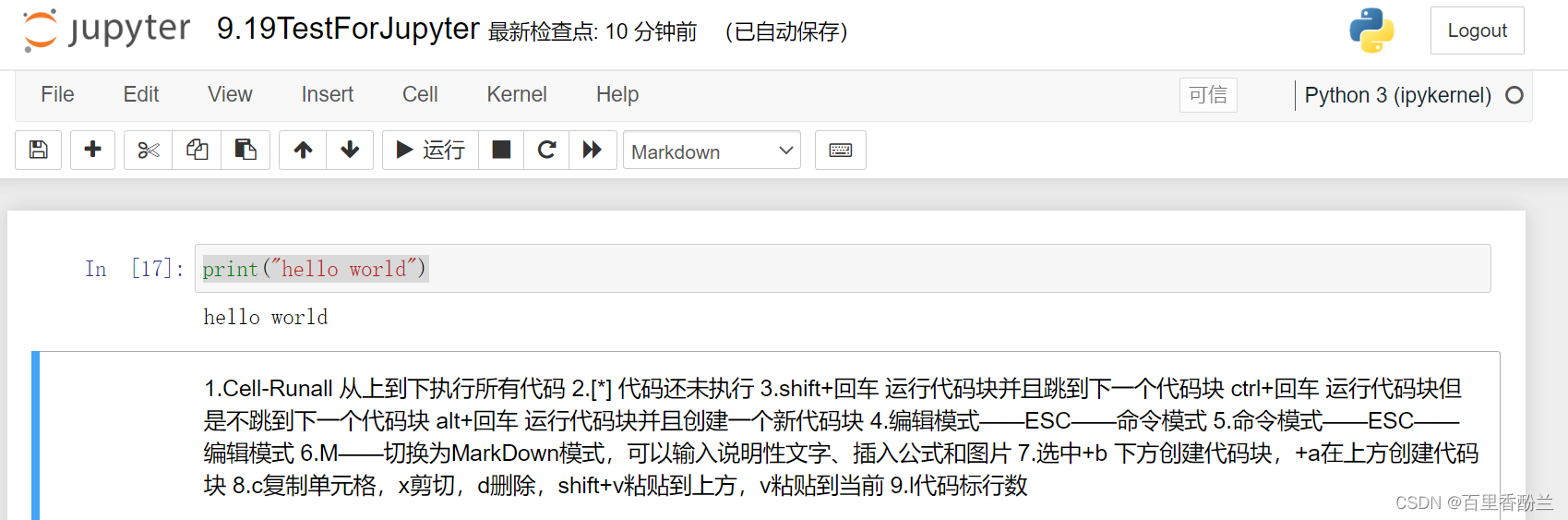
Jupyter Notebook常用快捷键:
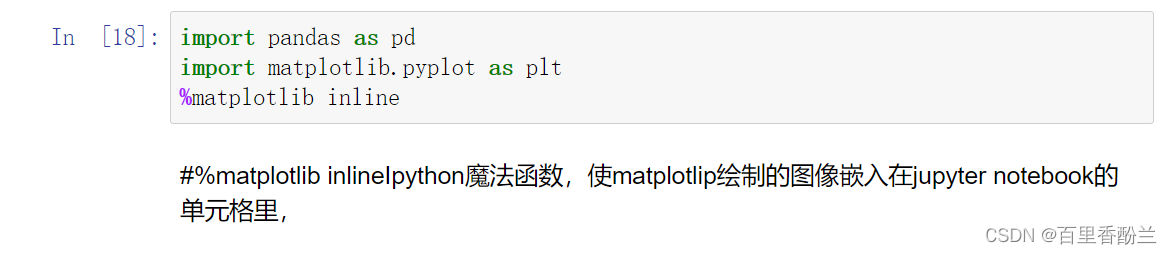
导入库
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
导入数据并且查看
dataset =pd.read_csv('D:StudyFilesJupyterzihaopython-masterdataForJupyterstudentScores/studentscores.csv')
dataset.head(10)

查看数据类型,二维表格
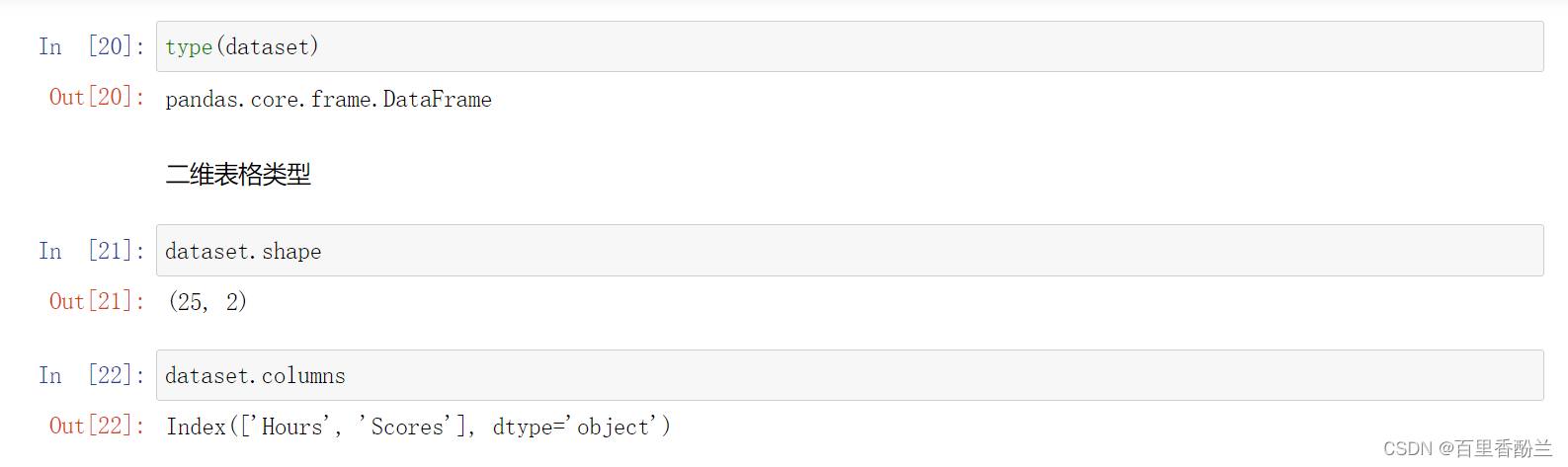
dataset.shape
dataset.columns
查看数据信息
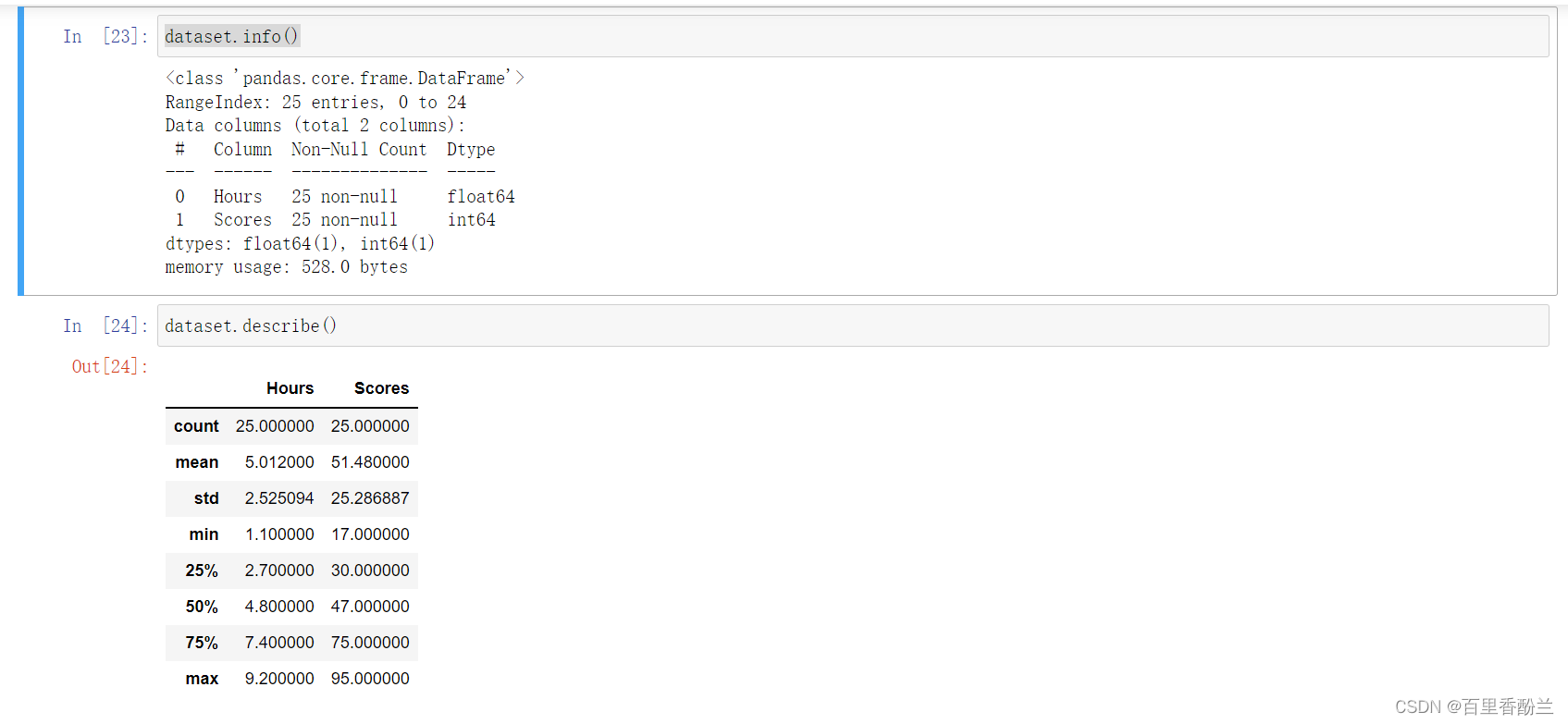
dataset.info()
dataset.describe()
提取数据特征

feature_columns=['Hours']
label_column=['Scores']
features=dataset[feature_columns]
label=dataset[label_column]
这里我感觉是和R语言类似,head(),tail()表示正序/逆序的前几个,一般有个默认值,R语言好像是6,这里看起来是5(即调用这俩函数的时候找出这组数据的最前5个或者最后5个)
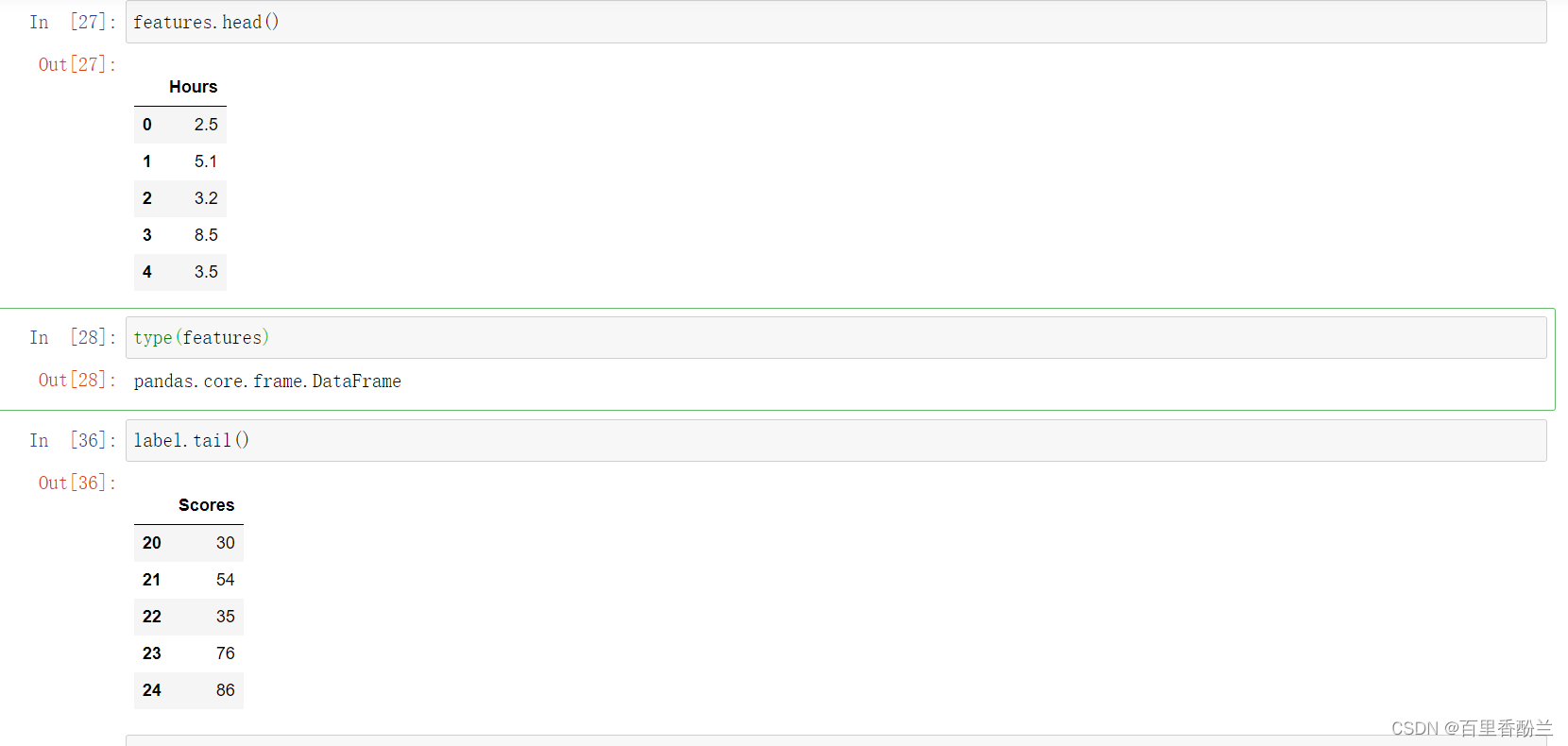
features.head()
type(features)
label.tail()
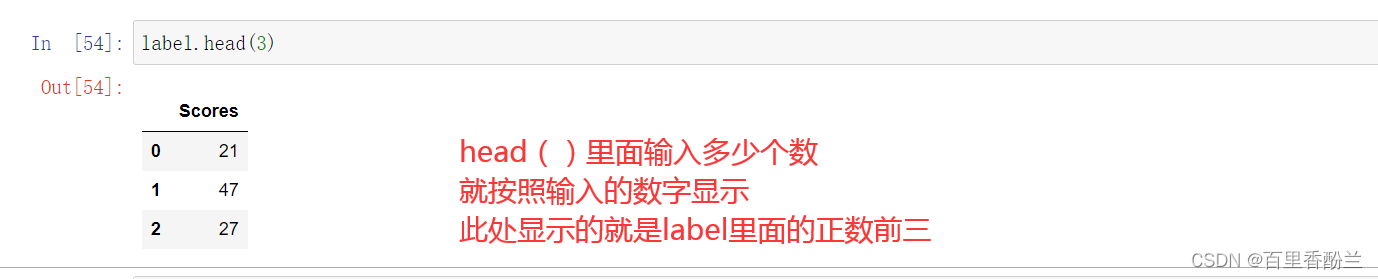
label.head(3)
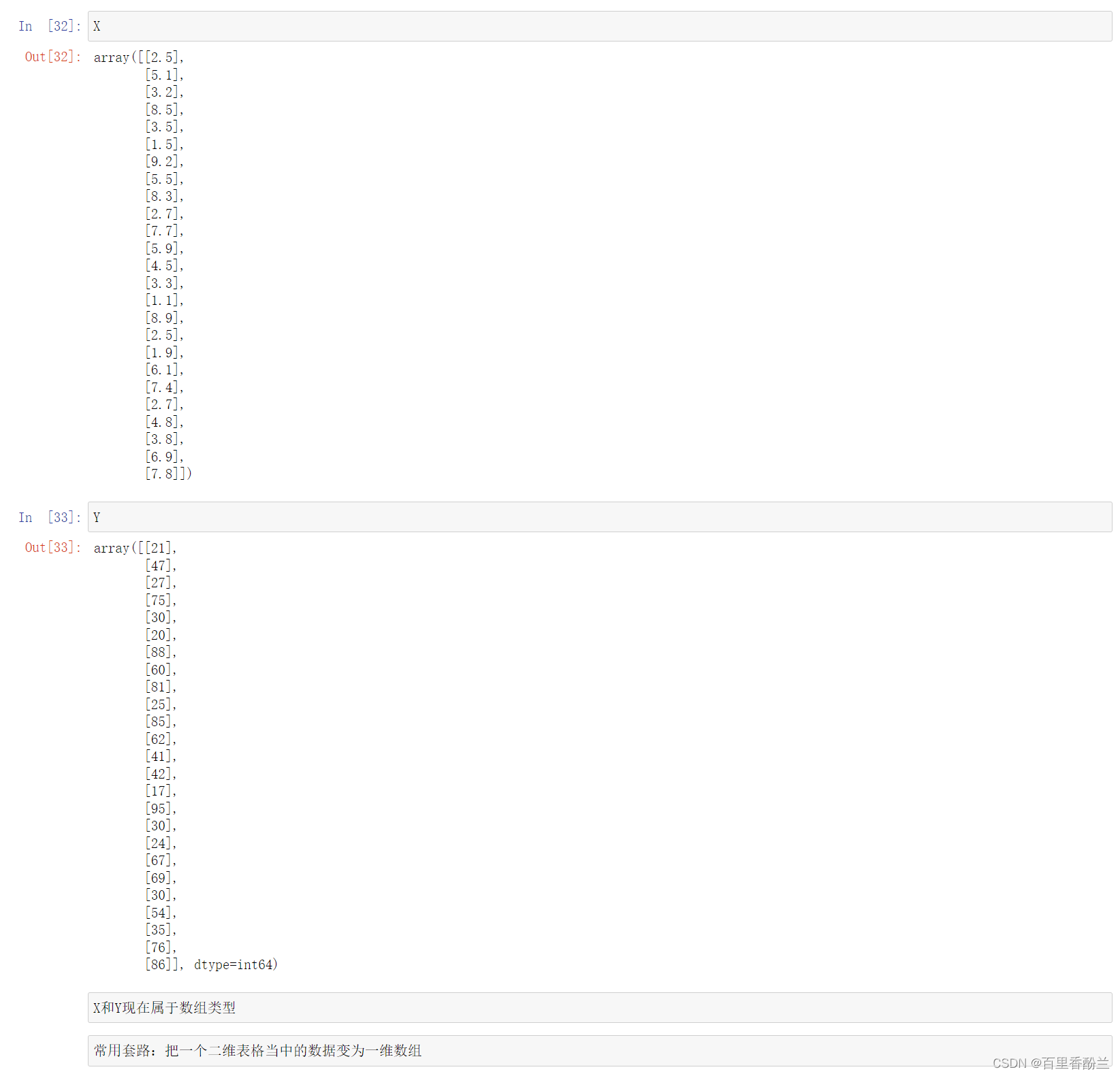
把提出的feature和label的值分别赋予X、Y
X=features.values
Y=label.values

输出X和Y的值看一下
这里使用的是一个很常用的办法,把拿到的二维表格数据分开成了俩个一维数组
X
Y
拆分训练集和测试集:
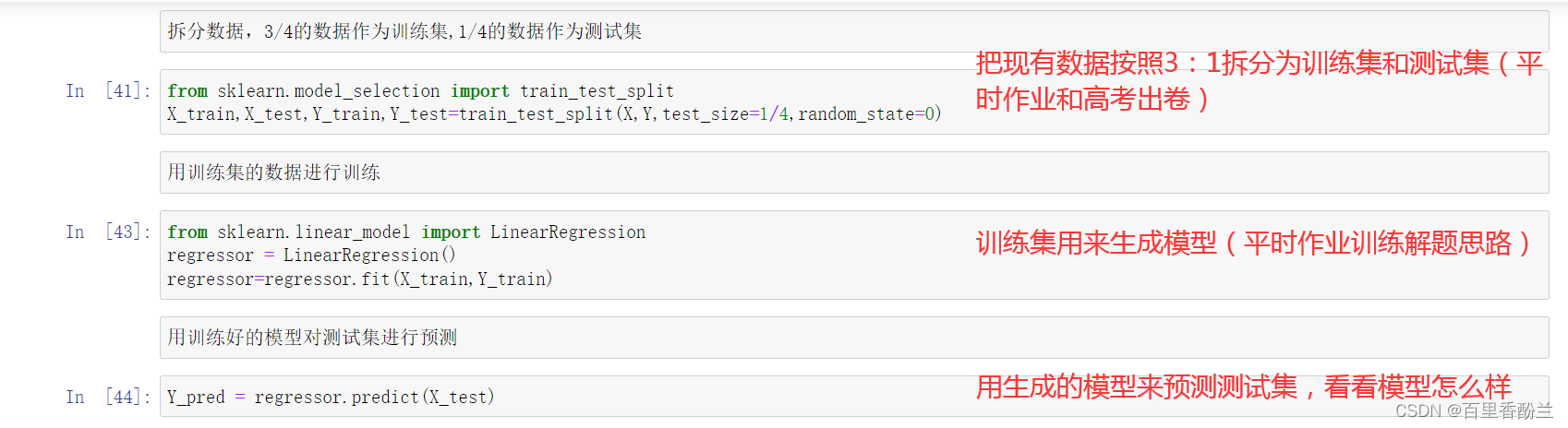
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=1/4,random_state=0)
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor=regressor.fit(X_train,Y_train)
Y_pred = regressor.predict(X_test)
将得到的结果可视化:
训练集:
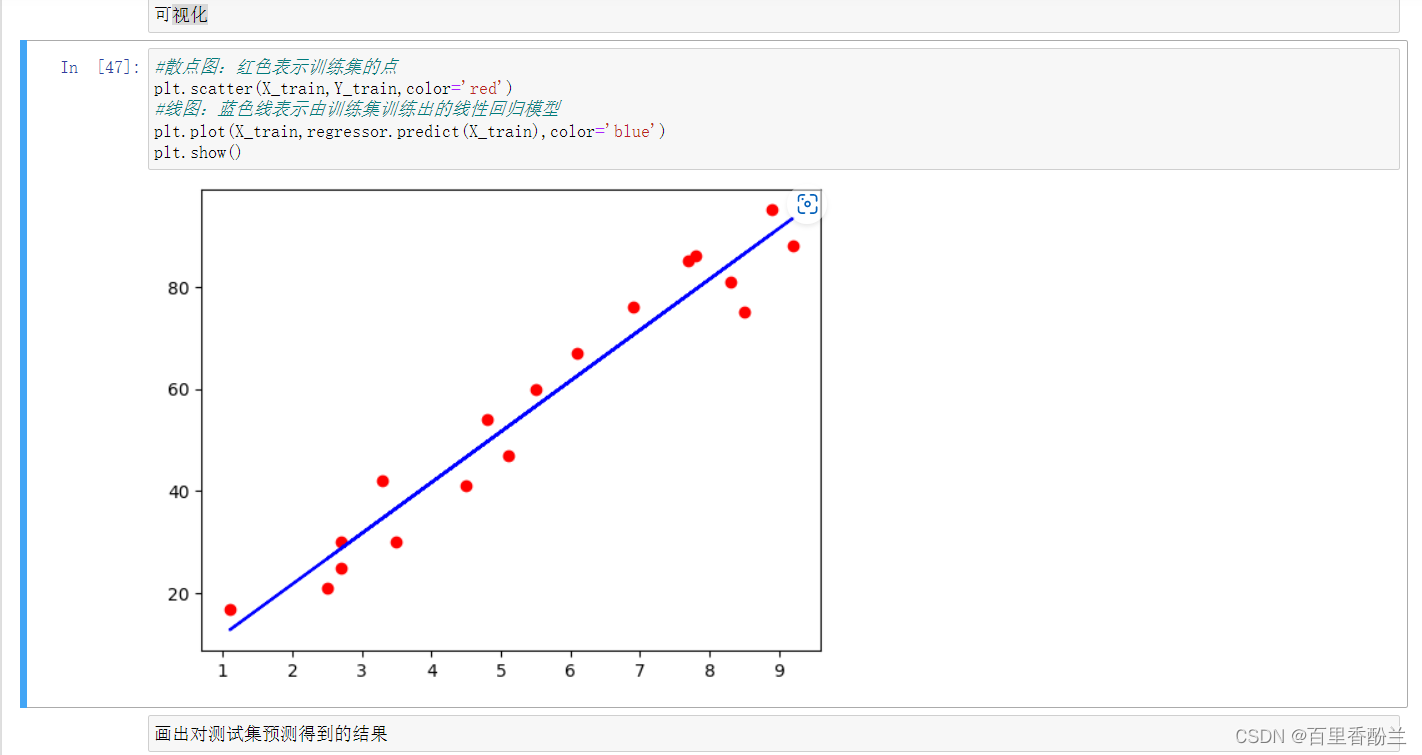
#散点图:红色表示训练集的点
plt.scatter(X_train,Y_train,color='red')
#线图:蓝色线表示由训练集训练出的线性回归模型
plt.plot(X_train,regressor.predict(X_train),color='blue')
plt.show()
红点是训练集的数据,根据现有数据,得到一个蓝线作为模型
测试集:
测试集得到的蓝线来看是否在训练集还适用,发现基本上能跟红点对上,而且红点大多均匀分布两侧,则说明这个模型比较成功
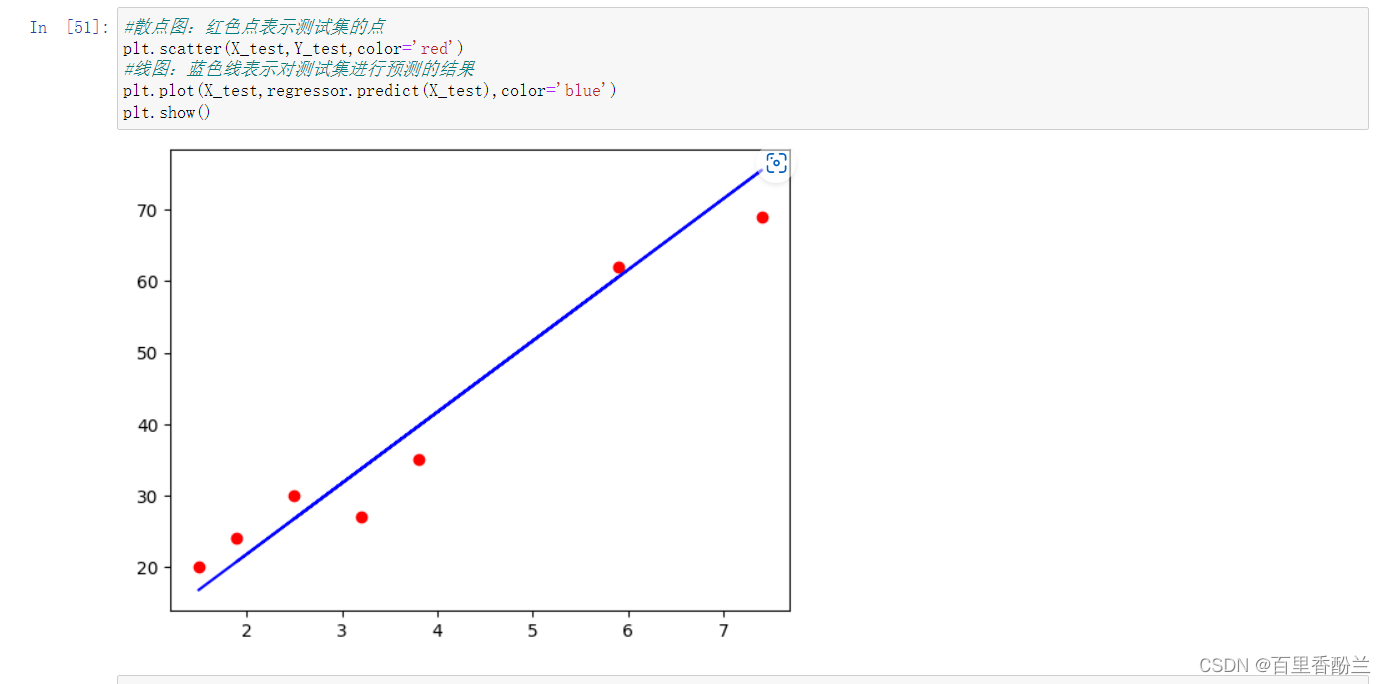
#散点图:红色点表示测试集的点
plt.scatter(X_test,Y_test,color='red')
#线图:蓝色线表示对测试集进行预测的结果
plt.plot(X_test,regressor.predict(X_test),color='blue')
plt.show()
最后是一些笔记:

另外,导出转PDF的时候直接选择“浏览器——打印”比安装那俩软件更加方便快捷,我安装完搜出来需要的俩软件之后,还是老样子Interval Server Error……但是看浏览器打印很方便效果也不错就没管了。
效果如图,PDF我也会上传CSDN
最后
以上就是狂野毛巾最近收集整理的关于Python学习笔记:Jupyter Notebook快速入门案例:学习时间与成绩的关系Python学习笔记:Jupyter Notebook快速入门案例:学习时间与成绩的关系的全部内容,更多相关Python学习笔记:Jupyter内容请搜索靠谱客的其他文章。








发表评论 取消回复