Zookeeper——数据结构
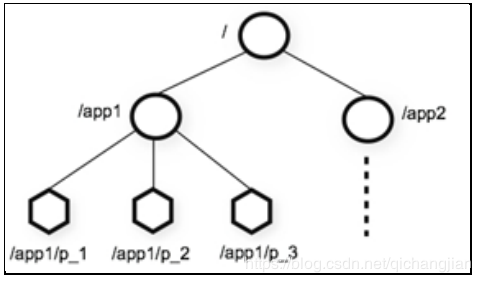
嵌套表示:模仿文件系统的父子关系,即利用路径/决定父子关系的方式来实现节点的树形数据结构;
节点类型:
(1)永久节点----一般是某个操作的根节点一定是永久节点,用于集成管理所有临时节点;
(2)临时节点----客户端和Zookeeper断开连接后,该节点被删除;统计在线机器,以及实现分布式锁,因为临时节点会话结束另一个就可以获取锁了;
(3)序号节点----会被标记序号存入Zookeeper,比如抢购时候的,先到先得到;
本质概述:
zookeeper中就是用路径作为key去找到node对应的数据;所有node的父子关系又有路径嵌套包含去表示;
事件类型(znode节点相关):
①EventType.NodeCreated:节点创建
②EventType.NodeDataChanged:节点数据变更
③EventType.NodeChildrenChanged:子节点变更
④EventType.NodeDeleted:节点删除
状态类型(客户端实例相关):
①KeeperState.Disconnected:未连接
②KeeperState.SyncConnected:已连接
③KeeperState.AuthFailed:认证失败
④KeeperState.Expired:会话失效
Znode类型:
①PERSISTENT:持久化目录节点; 客户端与zookeeper断开连接后,该节点依旧存在
②PERSISTENT_SEQUENTIAL:持久化顺序目录编号节点;客户端与zookeeper断开连接后,该节点依旧存在,zookeeper给该节点名称进行顺序编号
③EPHEMERAL-:临时目录节点; 客户端与zookeeper断开连接后,删除该节点
④EPHEMERAL_SEQUENTIAL:临时顺序编号目录节点;zookeeper给该节点名称进行顺序编号,客户端与zookeeper断开连接后,删除该节点
Zookeeper——应用场景(X)
命名服务
直接利用zk,key与value的对应关系,将服务信息注册Zookeeper,命名对应服务器ip地址和其他元数据完成这个功能;
配置管理
多个应用对于zookeeper上的节点进行监听,然后拉取这个数据实现动态刷新应用内的bean
分布式锁
不断的针对在一个key创建节点,不能重复创建(只能有一人获得),且临时节点连接断了就会消失,手动实现,来实现分布式锁
读写锁
1、读写约定法:value一个是write,一个read
2、尾部判断法: 所有读锁下面可以增加节点,所有写锁下面不能增加节点,因此只需要判断尾部是不是写锁即可;
3、监听上一个节点代码:写锁或者读锁监测到最后一个读的时候就添加监听,从效率来讲,如果一个写锁解放后同时通知一千个节点,那么就会造成性能损耗判断太多;因此等待队列中利用链表监听更实际,只监听上一个节点是否成功写入;
Zookeeper——工作原理
集群强一致性原理
Zookeeper内部利用全局事务机制,决定了一个创建节点的请求,要么全部成功,要么全部失败,最后返回给客户端创建节点失败最终强一致性的表现性;
消息广播模式:
(1.1)事务咨询:leader所有参与者是否可以参与事务,所有follower通ack回应
(1.2)分发数据:然后生成事务id此时再将同步块数据分发给所有follower,完成同步后再回应给leader
(1.3)决议事务:leader根据所有follower反馈的结果决定此次事务是否成功,不成功则利用id完成回滚或作废,成功则返回创建节点成功
崩溃恢复模式:
(2.1)leader选举,leader挂掉后所有首先follower进入looking状态,然后选举新的leader;
(2.2)重启事务,新上任的leader根据事务id先回滚所有follower,然后再重新开始事务流程,完成数据同步并反馈给客户端
集群高可用性原理
Zookeeper各个服务节点在上线时,会利用自身的通讯机制选举出三种角色的节点来保证高可用;
Leader领导者:
1、存储所有节点的数据副本,并帮助新加入或重启的子节点恢复数据
2、处理不同类型请求
(1)PING请求是指Learner的心跳信息;
(2)REQUEST请求,是Follower发送的提议请求,包括写请求及同步请求;
(3)ACK请求,是 Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间
Follower跟随者:
(1)接收Client的请求,如果为写请求,发送给Leader进行投票;如果为读请求,则进行负载均衡;
(2)接收Leader消息并进行处理,消息循环处理机制;
————(2.1)PROPOSAL消息:Leader发起的提案,要求Follower投票
————(2.2)SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新
————(2.3)REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
(3)参与新的leader的选举
Observer观察者:
Follower太多的时候会导致投票选举影响性能,所以声明部分子节点是观察者则不会导致这个问题;
集群选举原理
zookeeper默认的算法是FastLeaderElection 采用投票数大于半数则胜出;
以下是集群选举的三个因素;
集群选举因素——服务器id:.比如有三台服务器,编号分别为1,2,3;编号越大在选择算法中的权重越大
集群选举因素——数据ID:服务器中存放的最新数据version;值越大说明数据越新,在选举算法中数据越大权重越大;
集群选举因素——逻辑时钟:1.逻辑时钟也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的;2.每投完一次票这个数据就会增加,然后与接受到的其他服务器返回的投票信息中的数值相比;根据不同的值做出不同的判断;
全新集群选举:一个zookeeper集群刚刚搭建起来,没有任何数据,他的选举,就叫全新集群选举;集群过半时,选择3号为leader;
非全新集群选举:中途有机器down掉,需要重新选举时,选举过程中就需要加入数据id;
(1)逻辑时钟小的选举结果被忽略,重新投票
(2)同一逻辑时钟后,数据id大的胜出
(3)数据id相同的情况下,服务器id大的胜出
Zookeeper——节点管理(Linux)
【基本操作】
进入客户端:bin/zkCli.sh
查看子节点 :ls / ls /crm
历史记录:history
redo 10 执行history中某个的命令、
【增加/删除/更改/监听】
创建节点:
created /zkPro myData(默认是永久节点)
created /zkPro/username myData
created /zkPro/password myData
created -e /zkPro/password (顺序节点)
created -s /zkPro/password (临时节点)
获取节点:get /zkPro
更新节点:set /zkPro zhuge
删除节点:delete /zkPro
监听节点:
get /crm/fuck watach
【限制操作】
限制节点:setquota -n 3 /crm设置子节点最大路径,超过只会警告
查看限制:listquota /crm
删除限制:delquota -n /crm
【节点状态】
通过,get /mynode1 拿到
dataVersion:数据版本号
eversion:子节点版本号,子节点变化时会+1
aclVersion:ACL版本号
cZxid:Znode创建的时候,生成的事务id
mZxid:Znode更新的时候,生成的事务Id
ctime:节点更新时的时间戳
ephemeralOwner:为0则不是临时节点,绑定了客户端的sessionID
dataLength = 0 #节点数据的字节数
numChildren = 1 #子节点的个数
Zookeeper——节点管理(Java)
maven:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
连接与监听回调
/**
* @连接与监听回调
* 可以根据监听类型、状态、路径来执行回调函数
*/
ZooKeeper zk = new ZooKeeper("192.168.25.8:2181", 3000, new Watcher() {
@Override
public void process(WatchedEvent event) {
String path = event.getPath(); //负责监听的路径
Event.KeeperState state = event.getState();//负责监听的状态
/**
* None(-1) 成功连接回调
* NodeCreated(1)成功创建回调
* NodeDeleted(2)成功删除糊掉
* NodeDataChanged(3)成功修改回调
* NodeChildrenChanged(4)子节点发生变化回调
*/
Event.EventType type = event.getType(); //负责监听类型
}
});
创建节点
/**
* @创建节点
* key
* 数据
* 权限
* 节点类型
*/
zk.create("/a1", "yangxinlei".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);//持久、
zk.create("/c1", "yangxinlei123".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);//持久序列
zk.create("/b1", "yangxinlei12".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
zk.create("/b1", "yangxinlei12".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
删除节点
/**
* @删除节点
* version参数指定要更新的数据的版本, 如果version和真实的版本不同, 更新操作将失败. 指定version为-1则忽略版本检查
*/
zk.delete("/a1",-1);
修改节点
/**
* @修改节点
* version参数指定要更新的数据的版本, 如果version和真实的版本不同, 更新操作将失败. 指定version为-1则忽略版本检查
* 更新利用版本号实现安全
*/
zk.setData("/b1","testUpdate".getBytes(),-1);
获取数据
/**
* @获取数据,可以注册监听器,,stat可以针对性拿到状态数据
*/
byte[] data = zk.getData("/c1", true, null);
获取子节点
/**
* @获取子节点(同步)
* fasle标识不需要监听,否则需要放回调函数接受
*/
List<String> childrenList = zk.getChildren("/test", false);
/**
* @获取子节点(异步)
*/
zk.getChildren("/test", true, new AsyncCallback.Children2Callback() {
public void processResult(int i, String s, Object o, List<String> list, Stat stat) {
}
}, null);
Zookeeper——节点管理(工具类封装)
@Configuration
public class ZookeeperConfig {
private static final Logger logger = LoggerFactory.getLogger(ZookeeperConfig.class);
@Value("${zookeeper.address}")
private String connectString;
@Value("${zookeeper.timeout}")
private int timeout;
@Bean(name = "zkClient")
public ZooKeeper zkClient(){
ZooKeeper zooKeeper=null;
try {
final CountDownLatch countDownLatch = new CountDownLatch(1);
//连接成功后,会回调watcher监听,此连接操作是异步的,执行完new语句后,直接调用后续代码
// 可指定多台服务地址 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
zooKeeper = new ZooKeeper(connectString, timeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
if(Event.KeeperState.SyncConnected==event.getState()){
//如果收到了服务端的响应事件,连接成功
countDownLatch.countDown();
}
}
});
countDownLatch.await();
logger.info("【初始化ZooKeeper连接状态....】={}",zooKeeper.getState());
}catch (Exception e){
logger.error("初始化ZooKeeper连接异常....】={}",e);
}
return zooKeeper;
}
}
————————————————
版权声明:本文为CSDN博主「codeing_doc」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010391342/article/details/100404588
@Component
public class ZkApi {
private static final Logger logger = LoggerFactory.getLogger(ZkApi.class);
@Autowired
private ZooKeeper zkClient;
/**
* 判断指定节点是否存在
* @param path
* @param needWatch 指定是否复用zookeeper中默认的Watcher
* @return
*/
public Stat exists(String path, boolean needWatch){
try {
return zkClient.exists(path,needWatch);
} catch (Exception e) {
logger.error("【断指定节点是否存在异常】{},{}",path,e);
return null;
}
}
/**
* 检测结点是否存在 并设置监听事件
* 三种监听类型: 创建,删除,更新
*
* @param path
* @param watcher 传入指定的监听类
* @return
*/
public Stat exists(String path,Watcher watcher ){
try {
return zkClient.exists(path,watcher);
} catch (Exception e) {
logger.error("【断指定节点是否存在异常】{},{}",path,e);
return null;
}
}
/**
* 创建持久化节点
* @param path
* @param data
*/
public boolean createNode(String path, String data){
try {
zkClient.create(path,data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
return true;
} catch (Exception e) {
logger.error("【创建持久化节点异常】{},{},{}",path,data,e);
return false;
}
}
/**
* 修改持久化节点
* @param path
* @param data
*/
public boolean updateNode(String path, String data){
try {
//zk的数据版本是从0开始计数的。如果客户端传入的是-1,则表示zk服务器需要基于最新的数据进行更新。如果对zk的数据节点的更新操作没有原子性要求则可以使用-1.
//version参数指定要更新的数据的版本, 如果version和真实的版本不同, 更新操作将失败. 指定version为-1则忽略版本检查
zkClient.setData(path,data.getBytes(),-1);
return true;
} catch (Exception e) {
logger.error("【修改持久化节点异常】{},{},{}",path,data,e);
return false;
}
}
/**
* 删除持久化节点
* @param path
*/
public boolean deleteNode(String path){
try {
//version参数指定要更新的数据的版本, 如果version和真实的版本不同, 更新操作将失败. 指定version为-1则忽略版本检查
zkClient.delete(path,-1);
return true;
} catch (Exception e) {
logger.error("【删除持久化节点异常】{},{}",path,e);
return false;
}
}
/**
* 获取当前节点的子节点(不包含孙子节点)
* @param path 父节点path
*/
public List<String> getChildren(String path) throws KeeperException, InterruptedException{
List<String> list = zkClient.getChildren(path, false);
return list;
}
/**
* 获取指定节点的值
* @param path
* @return
*/
public String getData(String path,Watcher watcher){
try {
Stat stat=new Stat();
byte[] bytes=zkClient.getData(path,watcher,stat);
return new String(bytes);
}catch (Exception e){
e.printStackTrace();
return null;
}
}
/**
* 测试方法 初始化
*/
@PostConstruct
public void init(){
String path="/zk-watcher-2";
logger.info("【执行初始化测试方法。。。。。。。。。。。。】");
createNode(path,"测试");
String value=getData(path,new WatcherApi());
logger.info("【执行初始化测试方法getData返回值。。。。。。。。。。。。】={}",value);
// 删除节点出发 监听事件
deleteNode(path);
}
}
————————————————
版权声明:本文为CSDN博主「codeing_doc」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010391342/article/details/100404588
当然了Zookeeper将数据发往java英语的时候,我们也不知道数据时效性,因此zookeeper对外提供version让我们自己利用乐观锁实现这个并发原子性问题
最后
以上就是专注香氛最近收集整理的关于【互联网代理方案】——Zookeeper的全部内容,更多相关【互联网代理方案】——Zookeeper内容请搜索靠谱客的其他文章。








发表评论 取消回复