写在前面
为了实现服务的高可用,一般我们都会考虑通过集群方式来实现,当一台服务提供者出现问题时,还有其他的服务提供者failover,保证系统正常使用,为了能够更好的观察服务信息,我们通过dubbo-amin来查看,关于dubbo-admin搭建可以参考dubbo之dubbo admin搭建 一文。
1:测试
服务提供者 , 服务消费者 。
以下依赖于此进行测试!
1.1:启动服务提供者实例
启动后查看dubbo-admin:

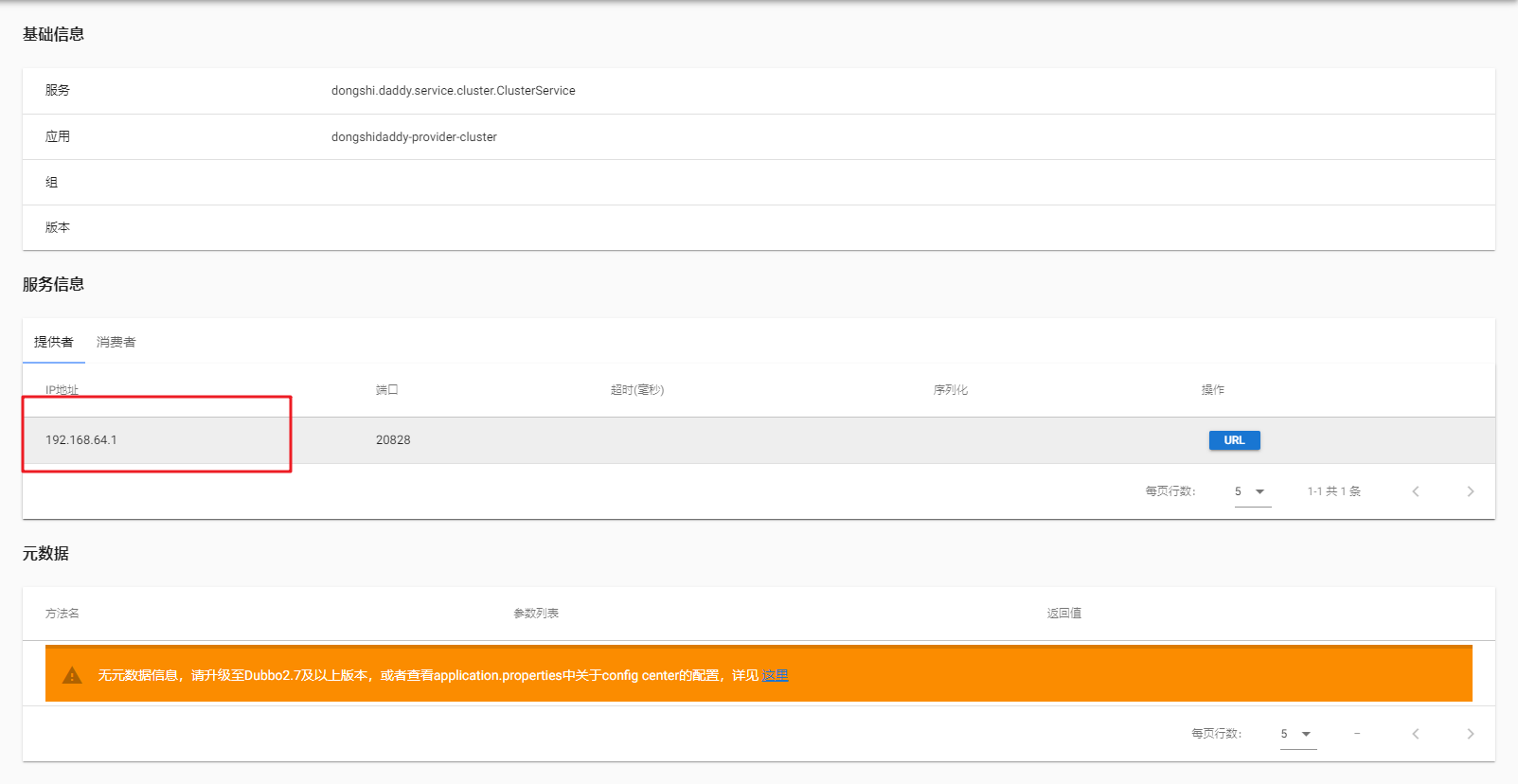
可以看到当前已经有一个服务提供者实例了,再启动一个,查看:
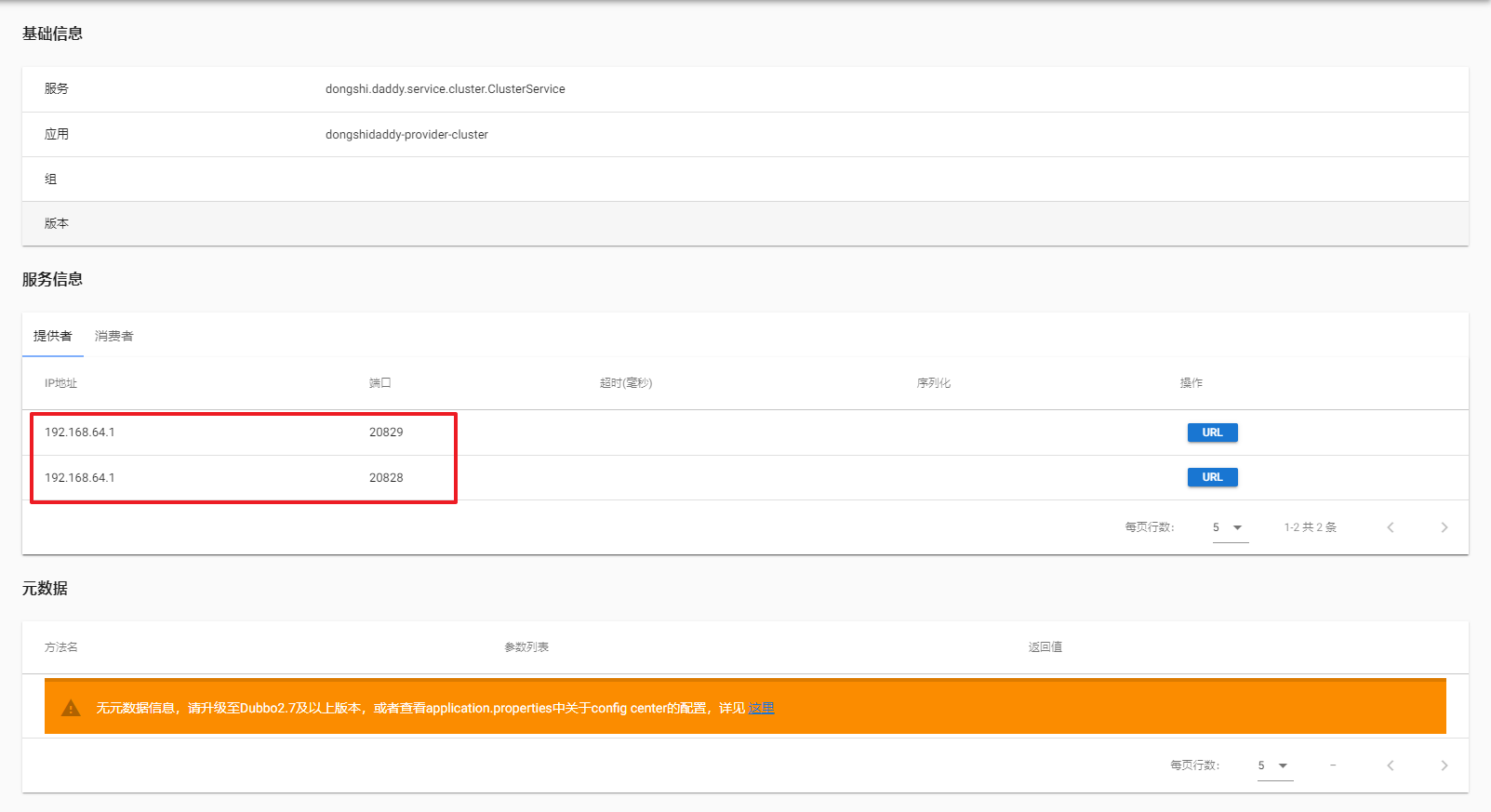
此时就有两个服务提供者实例了。
再来看下服务消费者此时还没有任何实例:
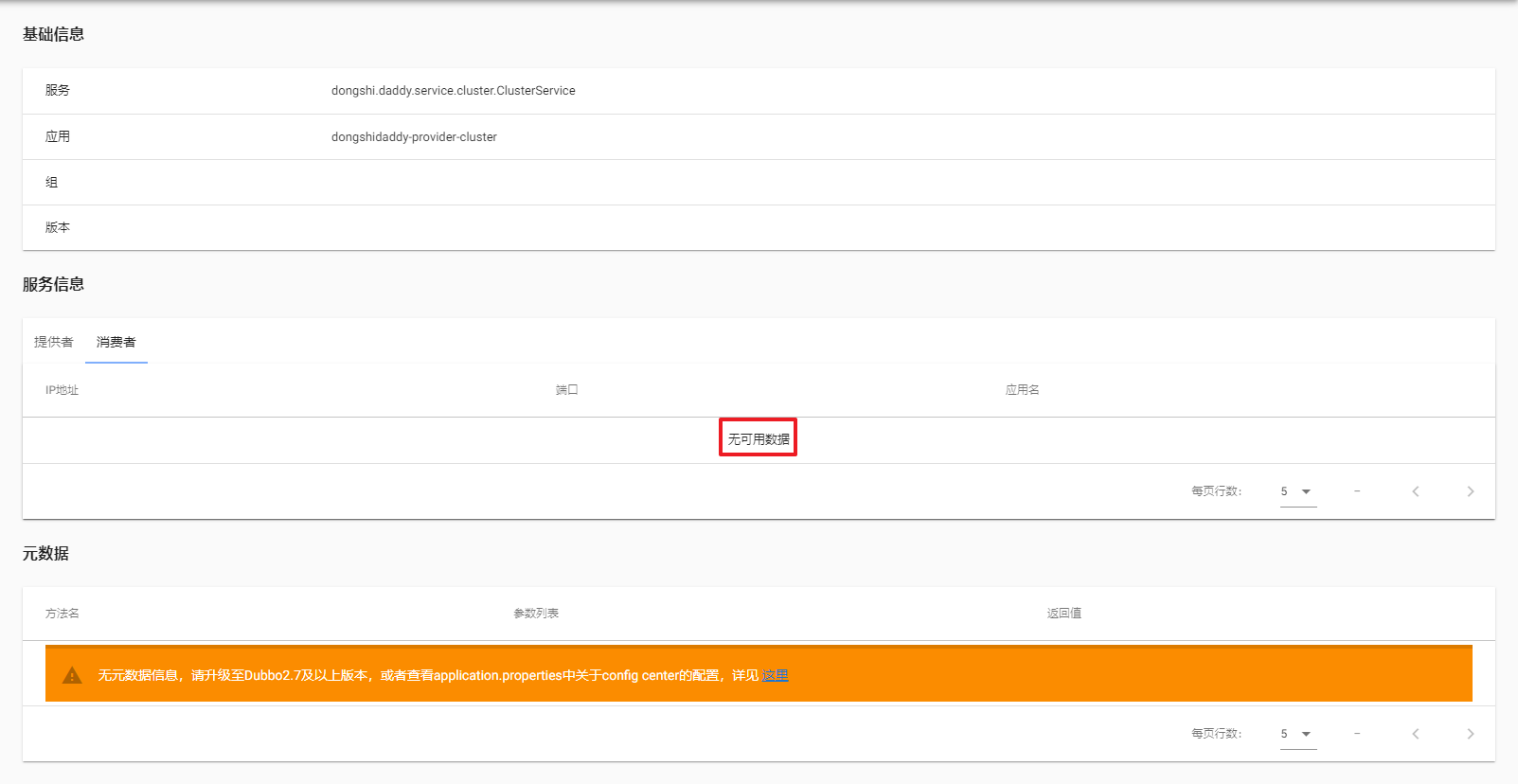
1.2:启动服务消费者实例
启动一个:
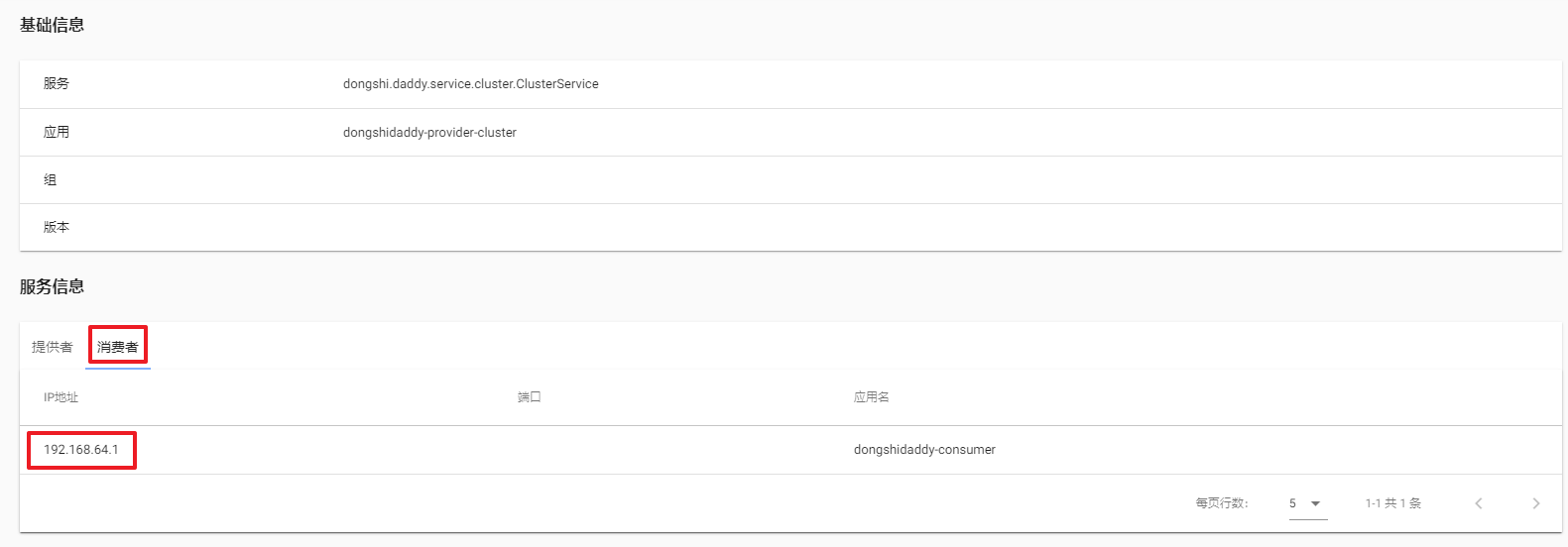
再启动一个:
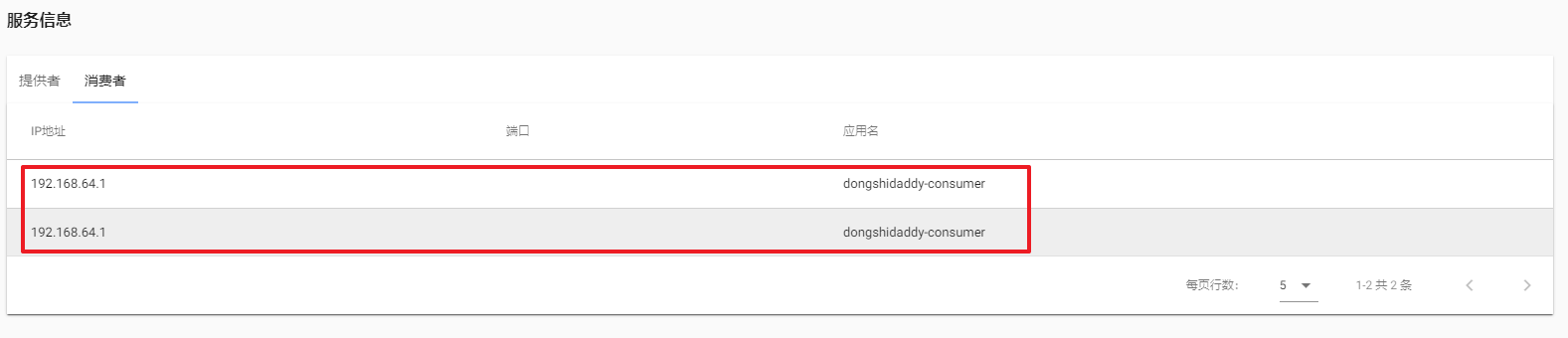
1.3:测试
启动消费者,可以正常访问:

停止一个服务提供者当前2个服务提供者:
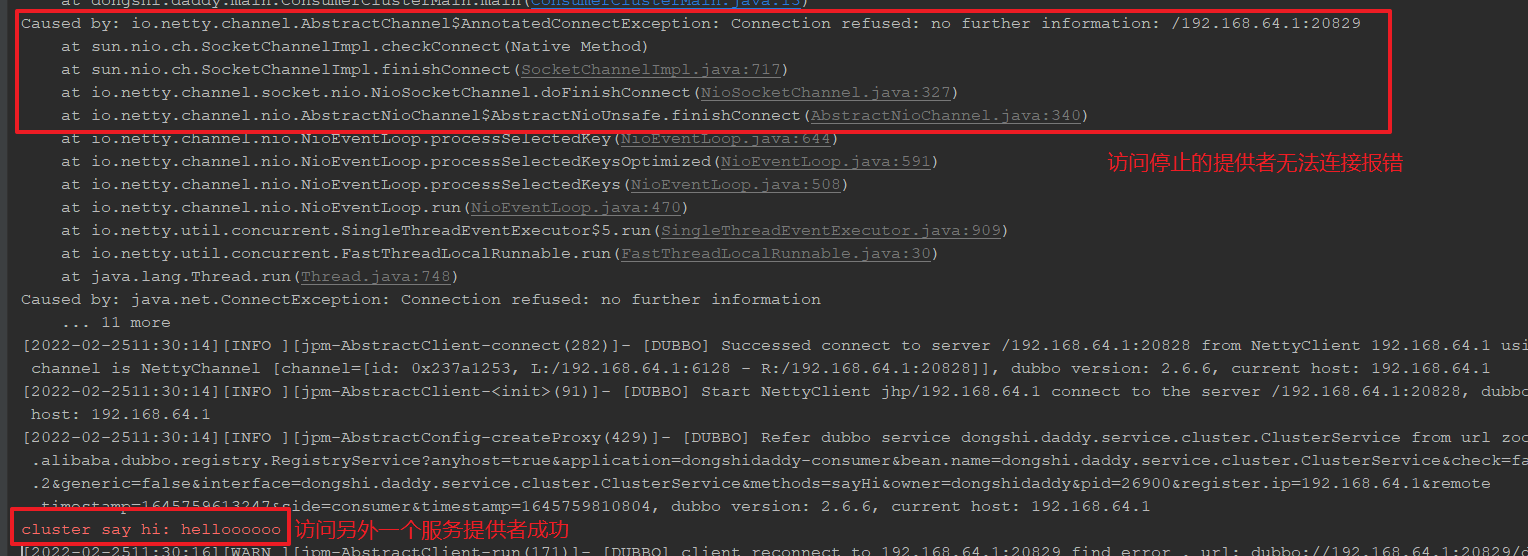
可以看到,最终还是可以正常访问服务提供者,接下来停止第2个服务提供者实例:
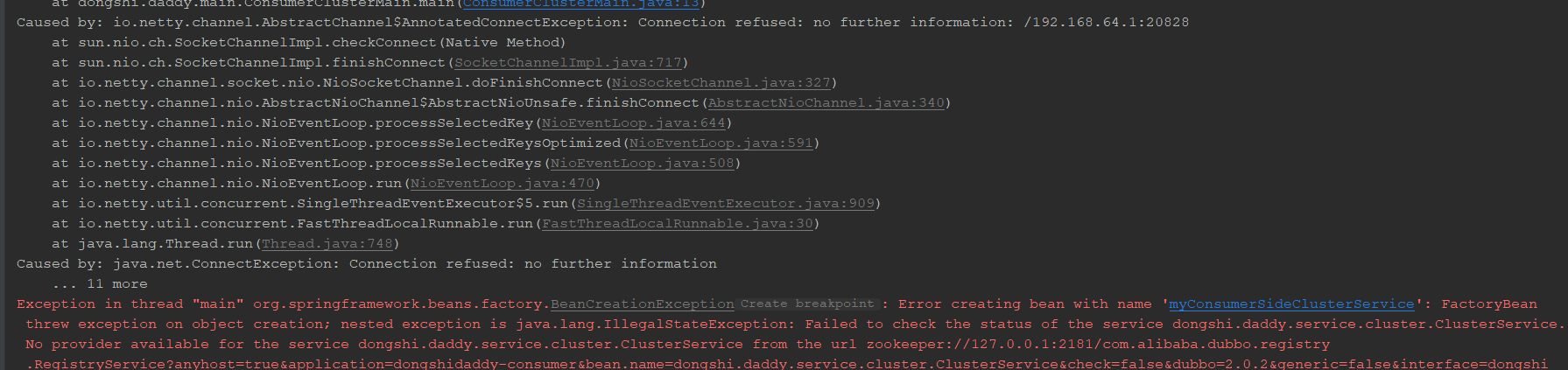
此时就报错无法正常访问了!
在上述的测试中,当只保留一个服务提供者时,虽然开始出现了请求失败的情况,但是最终还是请求成功了,这是因为默认的集群容错模式是Failover,即一个服务器出现错误时,直接切换到其他机器继续尝试,接下来我们通过2:集群容错模式详细看下。
2:集群容错模式
当前dubbo支持的集群容错模式有如下的几种:
failover:失败自动切换。
failfast:只发起一次调用,失败立即报错,通常用于非幂等性的写操作。
failsafe:出现异常时直接忽略,通常用于写入审计日志等操作。
failback:失败自动恢复,后台记录失败请求,定时重发,一般用于消息通知等场景。
forking:并行调用多个服务,只要一个成功即返回,用于对实时性要求较高的读操作,但是需要浪费更多的服务器资源。
broadcast:每个服务挨个调用,只要一个失败则认为失败,一般用于更新服务提供者端状态的场景。
设置如下:
failover:<dubbo:reference ... cluster="failover"/>。
failfast:<dubbo:reference ... cluster="failfast"/>。
failsafe:<dubbo:reference ... cluster="failsafe"/>。
failback:<dubbo:reference ... cluster="failback"/>。
forking:<dubbo:reference ... cluster="forking"/>。
broadcast:<dubbo:reference ... cluster="broadcast"/>。
写在后面
参考文章列表:
Dubbo之——Dubbo服务集群
最后
以上就是务实蜜蜂最近收集整理的关于dubbo之集群配置的全部内容,更多相关dubbo之集群配置内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复